Межотраслевой стандартный процесс интеллектуального анализа данных - Cross-industry standard process for data mining
Межотраслевой стандартный процесс интеллектуального анализа данных, известный как CRISP-DM,[1] является открытый стандарт модель процесса, которая описывает общие подходы, используемые сбор данных эксперты. Это наиболее широко используемый аналитика модель.[2]
В 2015 г. IBM выпустила новую методологию под названием Единый метод аналитических решений для интеллектуального анализа данных / прогнозной аналитики[3][4] (также известный как ASUM-DM), который уточняет и расширяет CRISP-DM.
История
CRISP-DM был задуман в 1996 году и стал проектом Европейского Союза в рамках ESPRIT Инициатива по финансированию в 1997 году. Проект возглавляли пять компаний: Integral Solutions Ltd (ISL), Терадата, Daimler AG, Корпорация NCR и OHRA, страховая компания.
Этот основной консорциум привнес в проект различный опыт: ISL, позже приобретенный и объединенный с SPSS. Компьютерный гигант NCR Corporation произвел Teradata хранилище данных и собственное программное обеспечение для интеллектуального анализа данных. У Daimler-Benz была значительная команда по анализу данных. OHRA только начинало изучать потенциальное использование интеллектуального анализа данных.
Первая версия методологии была представлена на 4-м семинаре CRISP-DM SIG в Брюсселе в марте 1999 г.[5] и опубликован в качестве пошагового руководства по интеллектуальному анализу данных позже в том же году.[6]
Между 2006 и 2008 годами была сформирована группа CRISP-DM 2.0 SIG, и велись дискуссии об обновлении модели процесса CRISP-DM.[7] Текущий статус этих усилий неизвестен. Однако исходный сайт crisp-dm.org, цитируемый в обзорах,[8][9] и веб-сайт CRISP-DM 2.0 SIG[7] оба больше не активны.
Хотя многие специалисты по интеллектуальному анализу данных не из IBM используют CRISP-DM,[10][11][12] IBM - основная корпорация, которая в настоящее время использует модель процесса CRISP-DM. Это делает некоторые старые документы CRISP-DM доступными для загрузки.[6] и он включил это в свою SPSS Modeler товар.
Основываясь на текущих исследованиях, CRISP-DM является наиболее широко используемой формой модели интеллектуального анализа данных из-за ее различных преимуществ, которые решают существующие проблемы в отраслях интеллектуального анализа данных. Некоторые из недостатков этой модели - то, что она не выполняет действия по управлению проектами. Факт успеха CRISP-DM заключается в том, что он не зависит от отрасли, инструментов и приложений.[13]
Основные этапы
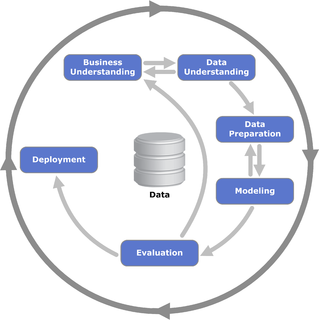
CRISP-DM нарушает процесс сбор данных на шесть основных этапов:[14]
- Деловое понимание
- Понимание данных
- Подготовка данных
- Моделирование
- Оценка
- Развертывание
Последовательность фаз не является строгой и перемещается между различными фазами, как это всегда требуется. Стрелки на диаграмме процесса указывают на наиболее важные и частые зависимости между фазами. Внешний круг на диаграмме символизирует циклический характер самого интеллектуального анализа данных. Процесс интеллектуального анализа данных продолжается после развертывания решения. Уроки, извлеченные в ходе этого процесса, могут вызвать новые, часто более конкретные бизнес-вопросы, а последующие процессы интеллектуального анализа данных выиграют от опыта предыдущих.
Опросы
Опросы, проведенные на том же веб-сайте (KDNuggets) в 2002, 2004, 2007 и 2014 годах, показывают, что это была ведущая методология, которую использовали отраслевые майнеры данных, которые решили ответить на опрос.[10][11][12][15] Единственный другой подход к интеллектуальному анализу данных, названный в этих опросах, был СЕММА. Однако институт SAS четко заявляет, что SEMMA - это не методология интеллектуального анализа данных, а, скорее, «логическая организация функционального набора инструментов SAS Enterprise Miner». Обзор и критика моделей процессов интеллектуального анализа данных в 2009 году назвал CRISP-DM «стандартом де-факто для разработки проектов интеллектуального анализа данных и поиска знаний».[нужна цитата ] Другие обзоры CRISP-DM и моделей процессов интеллектуального анализа данных включают обзор Кургана и Мусилека за 2006 г.[8] и сравнение CRISP-DM и SEMMA 2008 года Азеведо и Сантосом.[9] Усилия по обновлению методологии начались в 2006 г., но по состоянию на 30 июня 2015 г.[Обновить] не привела к новой версии, и ответственная за это "Группа по интересам" (SIG) вместе с сайтом давно исчезла (см. История CRISP-DM ).
Рекомендации
- ^ Ширер К., Модель CRISP-DM: новый план интеллектуального анализа данных, J Data Warehousing (2000); 5: 13—22.
- ^ Что ИТ-специалистам необходимо знать о процессе интеллектуального анализа данных Опубликовано Forbes, 29 июля 2015 г., данные получены 24 июня 2018 г.
- ^ Вы видели АСУМ-ДМ?, Автор Джейсон Хаффар, 16 октября 2015 г., SPSS Predictive Analytics, IBM В архиве 8 марта 2016 г. Wayback Machine
- ^ Единый метод аналитических решений - внедрение на принципах гибкой разработки Опубликовано IBM, 1 марта 2016 г., получено 5 октября 2018 г.
- ^ Пит Чепмен (1999); Руководство пользователя CRISP-DM.
- ^ а б Пит Чепмен, Джулиан Клинтон, Рэнди Кербер, Томас Хабаза, Томас Рейнарц, Колин Ширер и Рюдигер Вирт (2000); CRISP-DM 1.0 Пошаговые инструкции по интеллектуальному анализу данных.
- ^ а б Колин Ширер (2006); Проведен первый семинар по CRISP-DM 2.0
- ^ а б Лукаш Курган и Петр Мусилек (2006); Обзор моделей процессов обнаружения знаний и интеллектуального анализа данных. Обзор инженерии знаний. Том 21, выпуск 1, март 2006 г., стр. 1-24, Cambridge University Press, Нью-Йорк, Нью-Йорк, США doi: 10.1017 / S0269888906000737.
- ^ а б Азеведо А. и Сантос М. Ф. (2008); KDD, SEMMA и CRISP-DM: параллельный обзор. В материалах Европейской конференции IADIS по интеллектуальному анализу данных, 2008 г., стр. 182–185.
- ^ а б Григорий Пятецкий-Шапиро (2002); Опрос по методологии KDnuggets
- ^ а б Григорий Пятецкий-Шапиро (2004); Опрос по методологии KDnuggets
- ^ а б Григорий Пятецкий-Шапиро (2007); Опрос по методологии KDnuggets
- ^ Марискаль Г., Марбан О., Фернандес К. «Обзор моделей и методологий процесса интеллектуального анализа данных и обнаружения знаний». Обзор инженерии знаний. Дои:10.1017 / S0269888910000032.CS1 maint: несколько имен: список авторов (связь)
- ^ Харпер, Гэвин; Стивен Д. Пикетт (август 2006 г.). «Методы добычи данных HTS». Открытие наркотиков сегодня. 11 (15–16): 694–699. Дои:10.1016 / j.drudis.2006.06.006. PMID 16846796.
- ^ Григорий Пятецкий-Шапиро (2014); Опрос по методологии KDnuggets