Агрегат (хранилище данных) - Aggregate (data warehouse)
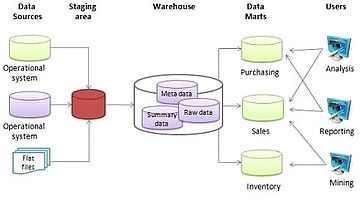
Агрегаты используются в размерные модели из хранилище данных чтобы оказать положительное влияние на время, необходимое для запроса больших наборов данные. В простейшем виде совокупность представляет собой простую сводную таблицу, которую можно получить, выполнив Группа по SQL-запрос. Чаще всего агрегаты используют для измерение и измените степень детализации этого измерения. При изменении степени детализации измерения факт таблица должна быть частично резюмирована, чтобы соответствовать новому зерно нового измерение, тем самым создавая новые размерный и таблицы фактов, соответствующие этому новому уровню детализации. Агрегаты иногда называют предварительно вычисленными итоговыми данными, поскольку агрегаты обычно представляют собой предварительно вычисленные частично обобщенные данные, которые хранятся в новых агрегированных таблицах. Когда факты агрегируются, это делается либо путем исключения размерности, либо путем связывания фактов со свернутым измерением. Свернутые измерения должны быть уменьшенными версиями измерений, связанных с гранулированными базовыми фактами. Таким образом, агрегированные таблицы измерений должны соответствовать базовым таблицам измерений.[1] Таким образом, причина, по которой агрегаты могут значительно повысить производительность хранилища данных, заключается в уменьшении количества строк, к которым нужно получить доступ при ответе на запрос.[2]
Ральф Кимбалл, который широко известен как один из первых архитекторов хранилищ данных, говорит:[3]
Единственный наиболее существенный способ повлиять на производительность в большом хранилище данных - это предоставить правильный набор агрегированных (сводных) записей, которые сосуществуют с первичными базовыми записями. Агрегаты могут очень сильно влиять на производительность, в некоторых случаях ускоряя запросы в сто или даже тысячу раз. Других способов добиться таких впечатляющих результатов не существует.
Наличие агрегатов и атомарных данных увеличивает сложность размерной модели. Эта сложность должна быть прозрачной для пользователей хранилища данных, таким образом, когда делается запрос, хранилище данных должно возвращать данные из таблицы с правильной степенью детализации. Поэтому, когда выполняются запросы к хранилищу данных, должна быть реализована функция агрегированного навигатора, чтобы помочь определить правильную таблицу с правильной степенью детализации. Количество возможных агрегатов определяется всеми возможными комбинациями гранулярностей измерений. Поскольку построение всех возможных агрегатов приведет к большим накладным расходам, рекомендуется выбрать подмножество таблиц для агрегирования. Лучший способ выбрать это подмножество и решить, какие агрегаты строить, - это отслеживать запросы и разрабатывать агрегаты в соответствии с шаблонами запросов.[4]
Наличие агрегированных данных в размерной модели делает среду более сложной. Чтобы сделать эту дополнительную сложность прозрачной для пользователя, используется функция, известная как агрегированная навигация, для запроса таблиц измерений и фактов с правильным уровнем детализации. Сводная навигация по существу исследует запрос, чтобы увидеть, можно ли ответить на него с помощью сводной таблицы меньшего размера.[5]
Реализации агрегатных навигаторов можно найти в ряде технологий:
- OLAP двигатели
- Материализованные представления
- Реляционный OLAP (ROLAP ) Сервисы
- БИ серверы приложений или инструменты запросов
Обычно рекомендуется использовать любую из первых трех технологий, поскольку преимущества в последнем случае ограничиваются одним интерфейсом. БИ инструмент[6]
Проблемы / проблемы
- Поскольку размерные модели выигрывают от агрегатов только для больших наборов данных, с какого размера наборов данных следует начинать рассматривать использование агрегатов?
- Аналогичным образом, всегда ли хранилище данных обрабатывает наборы данных, которые слишком велики для прямых запросов, или иногда рекомендуется опускать агрегированные таблицы при запуске нового проекта хранилища данных? Таким образом, упростит ли исключение агрегатов на первом этапе построения нового хранилища данных структуру размерной модели?
Рекомендации
- ^ Ральф Кимбалл; Марджи Росс (2002). Набор инструментов хранилища данных: полное руководство по размерному моделированию (Второе изд.). Wiley Computer Publishing. п. 356. ISBN 0-471-20024-7.
- ^ Кристофер Адамсон, Освоение агрегатов хранилища данных: решения для повышения производительности звездообразной схемы, Wiley Publishing, Inc., 2006 г. ISBN 978-0-471-77709-0, Стр. 23
- ^ «Сводная навигация без (почти) метаданных». 1995-08-15. Архивировано из оригинал на 2010-12-11. Получено 2010-11-22.
- ^ Набор инструментов Kimball & Data Warehouse, п. 355.
- ^ Набор инструментов Kimball & Data Warehouse, п. 137.
- ^ Набор инструментов Kimball & Data Warehouse, п. 354.