Быстрый выбор - Quickselect
Эта статья нужны дополнительные цитаты для проверка. (август 2013) (Узнайте, как и когда удалить этот шаблон сообщения) |
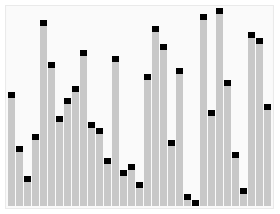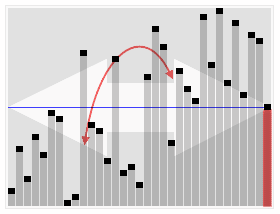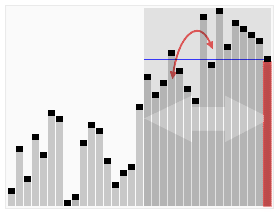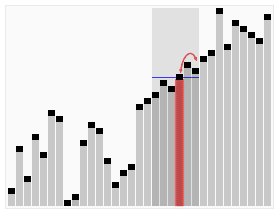 Анимированная визуализация алгоритма быстрого выбора. Выбор 22-го наименьшего значения. | |
| Учебный класс | Алгоритм выбора |
|---|---|
| Структура данных | Множество |
| Худший случай спектакль | О (п2) |
| Лучший случай спектакль | О (п) |
| Средний спектакль | O (п) |
В Информатика, быстрый выбор это алгоритм выбора найти k-й наименьший элемент в неупорядоченном списке. Это связано с быстрая сортировка алгоритм сортировки. Как и quicksort, он был разработан Тони Хоар, и поэтому также известен как Алгоритм выбора Хора.[1] Как и быстрая сортировка, он эффективен на практике и имеет хорошую производительность в среднем случае, но имеет низкую производительность в худшем случае. Quickselect и его варианты - это алгоритмы выбора, наиболее часто используемые в эффективных реальных реализациях.
Быстрый выбор использует тот же самый общий подход, как сортировки, выбирая один элемент в качестве оси поворота и разбиение данных на две части на основе поворота, соответственно, как меньше или больше, чем стержень. Однако вместо рекурсии в обе стороны, как в быстрой сортировке, quickselect рекурсивно выполняет только одну сторону - сторону с элементом, который он ищет. Это снижает среднюю сложность с O (п бревно п) к O (п), с худшим случаем O (п2).
Как и в случае с быстрой сортировкой, quickselect обычно реализуется как алгоритм на месте, и помимо выбора kth элемент, он также частично сортирует данные. Видеть алгоритм выбора для дальнейшего обсуждения связи с сортировкой.
Алгоритм
В быстрой сортировке есть подпроцедура, называемая раздел который может за линейное время сгруппировать список (начиная с индексов оставили к верно) на две части: те, которые меньше определенного элемента, и те, которые больше или равны элементу. Вот псевдокод, который выполняет раздел об элементе список [pivotIndex]:
функция раздел (список, левый, правый, сводный индекс) является pivotValue: = list [pivotIndex] список подкачки [pivotIndex] и список [справа] // Перемещаем точку поворота в конец storeIndex: = left за я из оставили к справа - 1 делать если список [я]тогда список подкачки [storeIndex] и list [i] увеличивают список подкачки storeIndex [справа] и список [storeIndex] // Перемещаем точку поворота в последнее место возвращаться storeIndex
Это известно как Схема разбиения Ломуто, что проще, но менее эффективно, чем Оригинальная схема разделения Хора.
В быстрой сортировке мы рекурсивно сортируем обе ветви, что в лучшем случае приводит к O (п бревно п) время. Однако при выполнении выбора мы уже знаем, в каком разделе находится желаемый элемент, поскольку точка поворота находится в своей окончательной отсортированной позиции со всеми предшествующими ей в несортированном порядке и всеми последующими в несортированном порядке. Таким образом, один рекурсивный вызов находит нужный элемент в правильном разделе, и мы опираемся на это для быстрого выбора:
// Возвращает k-й наименьший элемент списка в пределах left.. right включительно// (т.е. left <= k <= right).функция выберите (список, влево, вправо, k) является если left = right тогда // Если список содержит только один элемент, возвращаться список [слева] // возвращаем этот элемент pivotIndex: = ... // выбираем pivotIndex между левым и правым, // например, left + floor (rand ()% (right - left + 1)) pivotIndex: = partition (list, left, right, pivotIndex) // точка поворота находится в последней отсортированной позиции если k = pivotIndex тогда возвращаться список [k] иначе если kтогда возвращаться select (list, left, pivotIndex - 1, k) еще возвращаться select (list, pivotIndex + 1, right, k)
Обратите внимание на сходство с быстрой сортировкой: так же, как алгоритм выбора на основе минимума является сортировкой частичного выбора, это частичная быстрая сортировка, генерирующая и разделяющая только O (log п) его O (п) перегородки. Эта простая процедура имеет ожидаемую линейную производительность и, как и быстрая сортировка, имеет довольно хорошую производительность на практике. Это также алгоритм на месте, требуя только постоянных накладных расходов на память, если хвостовой зов доступна оптимизация, или если исключить хвостовая рекурсия с петлей:
функция выберите (список, влево, вправо, k) является петля если left = right тогда возвращаться список [слева] pivotIndex: = ... // выбираем pivotIndex между левым и правым pivotIndex: = раздел (список, слева, справа, pivotIndex) если k = pivotIndex тогда возвращаться список [k] иначе если kтогда справа: = pivotIndex - 1 еще слева: = pivotIndex + 1
Сложность времени
Как и quicksort, quickselect имеет хорошую среднюю производительность, но чувствителен к выбранной оси. Если выбраны хорошие опорные точки, то есть такие, которые последовательно уменьшают поисковый набор на заданную долю, тогда поисковый набор уменьшается в размере экспоненциально и индукцией (или суммированием геометрическая серия ) видно, что производительность линейна, поскольку каждый шаг линейен, а общее время постоянно умножается на это (в зависимости от того, насколько быстро сокращается поисковый набор). Однако, если плохие точки поворота выбираются последовательно, например, уменьшается каждый раз только на один элемент, тогда производительность в худшем случае будет квадратичной: O (п2). Это происходит, например, при поиске максимального элемента набора с использованием первого элемента в качестве стержня и сортировки данных.
Варианты
Самое простое решение - выбрать случайную точку опоры, которая дает почти наверняка линейное время. Детерминистически можно использовать стратегию поворота по медиане из трех (как в быстрой сортировке), которая дает линейную производительность для частично отсортированных данных, что является обычным явлением в реальном мире. Однако надуманные последовательности могут вызывать сложность в худшем случае; Дэвид Массер описывает последовательность «убийств в среднем из трех», которая позволяет атаковать эту стратегию, что было одной из причин его интроселект алгоритм.
Можно гарантировать линейную производительность даже в худшем случае, используя более сложную стратегию разворота; это делается в медиана медиан алгоритм. Однако накладные расходы на вычисление поворота велики, и поэтому на практике это обычно не используется. Можно комбинировать базовый быстрый выбор с медианной медианой в качестве запасного варианта, чтобы получить как быструю производительность в среднем случае, так и линейную производительность в худшем случае; это делается в интроселект.
Более точные вычисления средней временной сложности дают наихудший случай для случайных точек поворота (в случае медианы; другие k быстрее).[2] Константу можно улучшить до 3/2 с помощью более сложной стратегии поворота, что дает Алгоритм Флойда – Ривеста, который имеет среднюю сложность для медианы, с другими k быть быстрее.


Смотрите также
Рекомендации
- ^ Хоар, К.А.Р. (1961). «Алгоритм 65: Найти». Comm. ACM. 4 (7): 321–322. Дои:10.1145/366622.366647.
- ^ Анализ Quickselect в стиле Блюма, Дэвид Эппштейн, 9 октября 2007 г.