Репликация (вычисления) - Replication (computing)
Эта статья включает в себя список общих Рекомендации, но он остается в основном непроверенным, потому что ему не хватает соответствующих встроенные цитаты. (Октябрь 2012 г.) (Узнайте, как и когда удалить этот шаблон сообщения) |
Репликация в вычисление включает обмен информацией, чтобы обеспечить согласованность между избыточными ресурсами, такими как программного обеспечения или же аппаратное обеспечение компоненты для повышения надежности, Отказоустойчивость, или доступность.
Терминология
Репликация в вычислительной технике может относиться к:
- Репликация данных, где одни и те же данные хранятся на нескольких устройства хранения данных
- Репликация вычислений, где одна и та же вычислительная задача выполняется много раз. Вычислительные задачи могут быть:
- Тиражируется в космосе, где задачи выполняются на отдельных устройствах
- Тиражируется во времени, где задачи выполняются повторно на одном устройстве
Репликация в пространстве или во времени часто связана с алгоритмами планирования.[1]
Доступ к реплицированному объекту обычно унифицирован с доступом к одному нереплицированному объекту. Сама репликация должна быть прозрачный внешнему пользователю. В случае отказа аварийное переключение реплик должны быть максимально скрыты относительно качество обслуживания.[2]
Ученые-компьютерщики далее описывают репликацию как:
- Активная репликация, который выполняется обработкой одного и того же запроса на каждой реплике
- Пассивная репликация, который включает обработку каждого запроса на одной реплике и передачу результата на другие реплики.
Когда одна лидерная реплика обозначена через выборы лидера для обработки всех запросов система использует первичный резервный или господин-раб схема, преобладающая в кластеры высокой доступности. Для сравнения, если какая-либо реплика может обрабатывать запрос и распространять новое состояние, система использует многоосновный или мультимастер схема. В последнем случае некоторая форма распределенный контроль параллелизма должны использоваться, например, распределенный менеджер блокировок.
Балансировка нагрузки отличается от репликации задач, поскольку распределяет нагрузку различных вычислений по машинам и позволяет отбросить одно вычисление в случае сбоя. Однако для балансировки нагрузки иногда используется репликация данных (особенно репликация с несколькими мастерами ) внутри, чтобы распределить свои данные между машинами.
Резервный отличается от репликации тем, что сохраненная копия данных остается неизменной в течение длительного периода времени.[3] С другой стороны, реплики часто обновляются и быстро теряют историческое состояние. Репликация - одна из старейших и важнейших тем в общей области распределенные системы.
И репликация данных, и репликация вычислений требуют, чтобы процессы обрабатывали входящие события. Процессы репликации данных пассивны и работают только для поддержания сохраненных данных, ответа на запросы чтения и применения обновлений. Репликация вычислений обычно выполняется для обеспечения отказоустойчивости и берет на себя операцию в случае отказа одного из компонентов. В обоих случаях основные потребности заключаются в обеспечении того, чтобы реплики видели одни и те же события в эквивалентном порядке, чтобы они оставались в согласованных состояниях, и любая реплика могла отвечать на запросы.
Модели репликации в распределенных системах
Существуют три широко цитируемые модели репликации данных, каждая из которых имеет свои собственные свойства и производительность:
- Транзакционная репликация: используется для репликации транзакционные данные, например, база данных. В сериализуемость в одну копию используется модель, которая определяет действительные результаты транзакции на реплицированных данных в соответствии с общей КИСЛОТА (атомарность, согласованность, изоляция, долговечность) свойства, которые транзакционные системы стремятся гарантировать.
- Репликация конечного автомата: предполагает, что реплицированный процесс является детерминированный конечный автомат и это атомная трансляция любого события возможно. Он основан на распределенный консенсус и имеет много общего с моделью репликации транзакций. Иногда это ошибочно используется как синоним активной репликации. Репликация конечного автомата обычно реализуется посредством реплицированного журнала, состоящего из нескольких последующих циклов Алгоритм Паксоса. Это было популяризировано системой Google Chubby, и это ядро системы с открытым исходным кодом. Хранилище данных пространства ключей.[4][5]
- Виртуальная синхронность: включает группу процессов, которые взаимодействуют для копирования данных в памяти или для координации действий. Модель определяет распределенную сущность, называемую группа процессов. Процесс может присоединиться к группе, и ему предоставляется контрольная точка, содержащая текущее состояние данных, реплицируемых членами группы. Затем процессы могут отправлять многоадресная рассылка группе и будут видеть входящие многоадресные рассылки в том же порядке. Изменения членства обрабатываются как специальная многоадресная рассылка, которая доставляет новое «представление членства» процессам в группе.
Репликация базы данных
База данных репликация может использоваться на многих системы управления базами данных (СУБД), обычно с господин-раб связь между оригиналом и копиями. Мастер регистрирует обновления, которые затем передаются подчиненным. Каждое ведомое устройство выводит сообщение об успешном получении обновления, что позволяет отправлять последующие обновления.
В репликация с несколькими мастерами, обновления могут быть отправлены на любой узел базы данных, а затем перенаправлены на другие серверы. Это часто желательно, но приводит к значительному увеличению затрат и сложности, что может сделать это непрактичным в некоторых ситуациях. Наиболее распространенной проблемой при репликации с несколькими мастерами является предотвращение или разрешение конфликтов транзакций. Большинство решений для синхронной (или активной) репликации выполняют предотвращение конфликтов, в то время как асинхронные (или ленивые) решения должны выполнять разрешение конфликтов. Например, если одна и та же запись изменяется на двух узлах одновременно, система активной репликации обнаружит конфликт до подтверждения фиксации и прервет одну из транзакций. А ленивая репликация Система позволит обеим транзакциям выполнить фиксацию и запустить разрешение конфликта во время повторной синхронизации.[6] Разрешение такого конфликта может быть основано на отметке времени транзакции, на иерархии исходных узлов или на гораздо более сложной логике, которая принимает согласованные решения для всех узлов.
Репликация базы данных становится более сложной, когда она масштабируется по горизонтали и вертикали. Горизонтальное масштабирование включает больше реплик данных, а вертикальное масштабирование - реплики данных, расположенные на больших физических расстояниях. Проблемы, возникающие при горизонтальном масштабировании, могут быть решены с помощью многоуровневого протокола доступа с несколькими представлениями. Ранние проблемы вертикального масштабирования в значительной степени решались за счет повышения надежности и производительности Интернета.[7][8]
Когда данные реплицируются между серверами баз данных, так что информация остается согласованной во всей системе базы данных, и пользователи не могут сказать или даже знать, какой сервер в СУБД они используют, считается, что система демонстрирует прозрачность репликации.
Репликация дискового хранилища
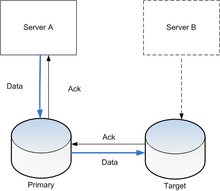
Активная (в реальном времени) репликация хранилища обычно реализуется путем распространения обновлений блочное устройство нескольким физическим жесткие диски. Таким образом, любой файловая система при поддержке Операционная система можно реплицировать без изменений, так как код файловой системы работает на уровне выше уровня драйвера блочного устройства. Реализуется либо аппаратно (в контроллер дискового массива ) или в программном обеспечении (в драйвер устройства ).
Самый простой метод - зеркальное отображение диска, что характерно для локально подключенных дисков. Индустрия хранения сужает определения, поэтому зеркальное отображение это местная (ближняя) операция. Репликация распространяется на компьютерная сеть, так что диски могут быть расположены в физически удаленных местах, и обычно применяется модель репликации базы данных главный-подчиненный. Целью репликации является предотвращение повреждений в результате сбоев или бедствия это может произойти в одном месте - или, если такие события действительно происходят, для улучшения возможности восстановления данных. Для репликации задержка является ключевым фактором, поскольку она определяет либо расстояние между сайтами, либо тип репликации, которую можно использовать.
Основная характеристика такой межсайтовой репликации - это то, как обрабатываются операции записи - посредством асинхронной или синхронной репликации; синхронная репликация должна ждать ответа целевого сервера в любой операции записи, тогда как асинхронная репликация этого не делает.
Синхронный репликация гарантирует «нулевую потерю данных» за счет атомный операции записи, при которых операция записи не считается завершенной, пока не будет подтверждена как локальным, так и удаленным хранилищем. Большинство приложений ожидают завершения транзакции записи, прежде чем продолжить работу, поэтому общая производительность значительно снижается. По сути, производительность падает, как минимум, пропорционально расстоянию. задержка продиктовано скорость света. На расстоянии 10 км максимально быстрое прохождение туда и обратно занимает 67 мкс, в то время как вся локальная кэшированная запись завершается примерно за 10–20 мкс.
В Асинхронный При репликации операция записи считается завершенной, как только локальное хранилище ее подтверждает. Удаленное хранилище обновлено небольшим отставание. Производительность значительно увеличивается, но в случае сбоя локального хранилища не гарантируется, что удаленное хранилище будет иметь текущую копию данных (самые свежие данные могут быть потеряны).
Полусинхронная репликация обычно считает операцию записи завершенной, когда она подтверждена локальным хранилищем и получена или зарегистрирована удаленным сервером. Фактическая удаленная запись выполняется асинхронно, что приводит к повышению производительности, но удаленное хранилище будет отставать от локального хранилища, поэтому нет гарантии долговечности (то есть полной прозрачности) в случае сбоя локального хранилища.[нужна цитата ]
Репликация на определенный момент времени создает периодические снимки которые реплицируются вместо основного хранилища. Это предназначено для репликации только измененных данных, а не всего тома. Поскольку с помощью этого метода реплицируется меньше информации, репликация может происходить по менее дорогостоящим каналам связи, таким как iSCSI или T1, вместо оптоволоконных линий.
Реализации
Много распределенные файловые системы используйте репликацию, чтобы обеспечить отказоустойчивость и избежать единой точки отказа.
Многие коммерческие системы синхронной репликации не зависают, когда удаленная реплика выходит из строя или теряет соединение - поведение, которое гарантирует нулевую потерю данных, - но продолжают работать локально, теряя желаемый ноль. цель точки восстановления.
Методы оптимизация глобальной сети (WAN) может применяться для устранения ограничений, налагаемых задержкой.
Репликация на основе файлов
Репликация на основе файлов выполняет репликацию данных на логическом уровне (т.е. отдельных файлов данных), а не на уровне блока хранения. Есть много разных способов сделать это, которые почти полностью зависят от программного обеспечения.
Захват с драйвером ядра
А драйвер ядра (в частности драйвер фильтра ) может использоваться для перехвата вызовов функций файловой системы, фиксируя любую активность по мере ее возникновения. При этом используется тот же тип технологии, что и для активных антивирусных программ в реальном времени. На этом уровне фиксируются логические файловые операции, такие как открытие, запись, удаление файла и т. Д. Драйвер ядра передает эти команды другому процессу, обычно по сети на другую машину, которая имитирует операции исходной машины. Как и репликация хранилища на уровне блоков, репликация на уровне файлов допускает как синхронный, так и асинхронный режимы. В синхронном режиме операции записи на исходном компьютере задерживаются и не могут выполняться, пока конечный компьютер не подтвердит успешную репликацию. Синхронный режим менее распространен в продуктах репликации файлов, хотя существует несколько решений.
Решения репликации на уровне файлов позволяют принимать обоснованные решения о репликации в зависимости от местоположения и типа файла. Например, могут быть исключены временные файлы или части файловой системы, не имеющие никакой коммерческой ценности. Передаваемые данные также могут быть более детализированными; если приложение записывает 100 байт, передаются только 100 байт вместо полного блока диска (обычно 4096 байт). Это существенно снижает объем данных, отправляемых с исходного компьютера, и нагрузку на хранилище на целевом компьютере.
К недостаткам этого программного решения относятся требования к внедрению и обслуживанию на уровне операционной системы, а также повышенная нагрузка на вычислительную мощность машины.
Репликация журнала файловой системы
Аналогично базе данных журналы транзакций, много файловые системы иметь возможность журнал их деятельность. Журнал можно отправлять на другой компьютер периодически или в режиме реального времени посредством потоковой передачи. На стороне реплики журнал можно использовать для воспроизведения изменений файловой системы.
Одна из примечательных реализаций - Microsoft с System Center Data Protection Manager (DPM), выпущенный в 2005 году, который выполняет периодические обновления, но не предлагает репликацию в реальном времени.[нужна цитата ]
Пакетная репликация
Это процесс сравнения исходной и конечной файловых систем и проверки того, что место назначения совпадает с источником. Главное преимущество в том, что такие решения обычно бесплатны или недороги. Обратной стороной является то, что процесс их синхронизации является довольно ресурсоемким для системы, и, следовательно, этот процесс обычно выполняется нечасто.
Одна из примечательных реализаций - rsync.
Эта секция нуждается в расширении. Вы можете помочь добавляя к этому. (Ноябрь 2018) |
Другой пример использования репликации представлен в распределенная разделяемая память системы, в которых многие узлы системы используют одни и те же страница памяти. Обычно это означает, что каждый узел имеет отдельную копию (реплику) этой страницы.
Первичное резервное копирование и множественная первичная репликация
Многие классические подходы к репликации основаны на модели первичного резервного копирования, в которой одно устройство или процесс имеет односторонний контроль над одним или несколькими другими процессами или устройствами. Например, первичный может выполнять некоторые вычисления, передавая журнал обновлений в резервный (резервный) процесс, который затем может взять на себя его выполнение в случае отказа основного. Этот подход является обычным для репликации баз данных, несмотря на риск того, что если часть журнала будет потеряна во время сбоя, резервная копия может оказаться в состоянии, отличном от состояния первичной, и тогда транзакции могут быть потеряны.
Слабость схем первичного резервного копирования заключается в том, что только одна из них фактически выполняет операции. Повышается отказоустойчивость, но идентичная система резервного копирования удваивает затраты. По этой причине, начиная c. 1985сообщество исследователей распределенных систем начало изучать альтернативные методы репликации данных. Результатом этой работы стало появление схем, в которых группа реплик могла взаимодействовать, причем каждый процесс действовал как резервный, а также обрабатывал часть рабочей нагрузки.
Специалист в области информатики Джим Грей проанализировал схемы репликации с несколькими первичными репликациями в рамках транзакционной модели и опубликовал широко цитируемую статью, в которой скептически относился к подходу «Опасности репликации и решение».[9][10] Он утверждал, что если данные не разделяются каким-то естественным образом, так что базу данных можно рассматривать как п п несвязанные суббазы, конфликты управления параллелизмом приведут к серьезному снижению производительности, и группа реплик, вероятно, будет замедляться в зависимости от п. Грей предположил, что наиболее распространенные подходы могут привести к деградации, которая масштабируется как O (н³). Его решение, заключающееся в разделении данных, жизнеспособно только в ситуациях, когда данные действительно имеют естественный ключ разделения.
В 1985–1987 гг. виртуальная синхронность была предложена и стала широко принятым стандартом (она использовалась в Isis Toolkit, Horus, Transis, Ensemble, Totem, Распространять, C-Ensemble, Phoenix и Quicksilver и является основой для CORBA стандарт отказоустойчивых вычислений). Виртуальная синхронизация допускает многоцелевой подход, при котором группа процессов взаимодействует для распараллеливания некоторых аспектов обработки запросов. Схема может использоваться только для некоторых форм данных в памяти, но может обеспечить линейное ускорение в размере группы.
Ряд современных продуктов поддерживает подобные схемы. Например, Spread Toolkit поддерживает ту же модель виртуальной синхронизации и может использоваться для реализации схемы репликации с несколькими первичными источниками; таким же образом можно было бы использовать C-Ensemble или Quicksilver. WANdisco разрешает активную репликацию, когда каждый узел в сети является точной копией или репликой, и, следовательно, каждый узел в сети активен одновременно; эта схема оптимизирована для использования в Глобальная сеть (WAN).
Смотрите также
- Сбор данных об изменениях
- Отказоустойчивая компьютерная система
- Доставка журналов
- Репликация с несколькими мастерами
- Оптимистичная репликация
- Репликация конечного автомата
- Виртуальная синхронность
Рекомендации
- ^ Мансури, Наджме, Голам, Хосейн Дастгайбифард и Эхсан Мансури. «Комбинация алгоритма репликации данных и планирования для повышения доступности данных в Data Grids», Журнал сетевых и компьютерных приложений (2013)
- ^ В. Андронику, К. Мамурас, К. Церпес, Д. Кириазис, Т. Варваригу, "Динамическая репликация данных с учетом QoS в грид-средах", Компьютерные системы будущего поколения Elsevier - Международный журнал грид-вычислений и электронной науки, 2012
- ^ «Резервное копирование и репликация: в чем разница?». Зерто. 6 февраля 2012 г.
- ^ Мартон Тренчени, Аттила Гассо (2009). «Пространство ключей: постоянно реплицируемое, высокодоступное хранилище ключей и значений». Получено 2010-04-18.
- ^ Майк Берроуз (2006). «Служба Chubby Lock для слабосвязанных распределенных систем». Архивировано из оригинал на 2010-02-09. Получено 2010-04-18.
- ^ "Решение конфликта". ITTIA. Получено 21 октября 2016.
- ^ Драган Симич; Сречко Ристич; Слободан Обрадович (апрель 2007 г.). «Измерение достигнутых уровней производительности веб-приложений с помощью распределенной реляционной базы данных» (PDF). Электроника и энергетика. Facta Universitatis. п. 31–43. Получено 30 января 2014.
- ^ Mokadem Riad; Хамерлен Абделькадер (декабрь 2014 г.). «Стратегии репликации данных с целевой производительностью в системах Data Grid: обзор» (PDF). Внутренний журнал сетевых и коммунальных вычислений. Издатель Underscience. п. 30–46. Получено 18 декабря 2014.
- ^ «Опасности репликации и решение»
- ^ Материалы Международной конференции ACM SIGMOD по управлению данными 1999 г.: SIGMOD '99, Филадельфия, Пенсильвания, США; 1–3 июня 1999 г., том 28; п. 3.