Smoothsort - Smoothsort
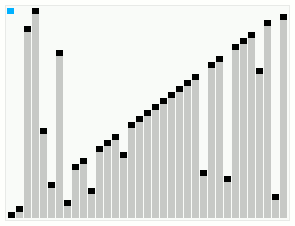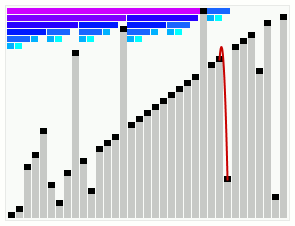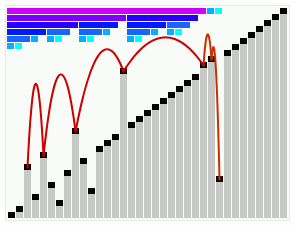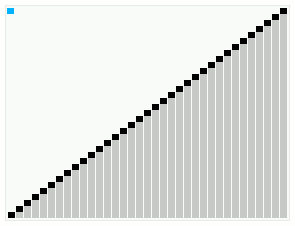 Smoothsort работает с массивом, который в основном в порядке. Полосы вверху показывают древовидную структуру. | |
| Учебный класс | Алгоритм сортировки |
|---|---|
| Структура данных | Множество |
| Худший случай спектакль | О(п бревно п) |
| Лучший случай спектакль | О(п) |
| Средний спектакль | О(п бревно п) |
| Худший случай космическая сложность | О(п) общий, О(1) вспомогательный |
В Информатика, гладкая сортировка это на основе сравнения алгоритм сортировки. Вариант heapsort, это было изобретено и издано Эдсгер Дейкстра в 1981 г.[1] Как и heapsort, smoothsort - это алгоритм на месте с верхней границей О (п бревноп),[2] но это не стабильная сортировка.[3][самостоятельно опубликованный источник? ][4] Преимущество плавной сортировки в том, что она приближается к О(п) время, если ввод уже отсортирован до некоторой степени, в то время как heapsort усредняет О(п бревноп) независимо от исходного состояния сортировки.
Обзор
Нравиться heapsort, smoothsort сначала преобразует входной массив в скрытый структура данных кучи (a куча -упорядоченный неявный двоичное дерево ), затем создает отсортированный массив, многократно извлекая самый большой из оставшихся элементов, расположение которого определяется структурой кучи, а затем восстанавливает структуру для оставшихся элементов.
Heapsort отображает дерево в массив, используя обход дерева сверху вниз в ширину; массив начинается с корня дерева, затем с двух его дочерних элементов, затем с четырех внуков и так далее. Каждый элемент имеет четко определенную глубину ниже корня дерева, и каждый элемент, кроме корня, имеет своего родителя раньше в массиве. Однако его высота над листьями зависит от размера массива. Это имеет недостаток, заключающийся в том, что каждый элемент должен быть перемещен как часть процесса сортировки: он должен пройти через корень, прежде чем быть перемещенным в свое окончательное положение.
Smoothsort использует другое сопоставление, восходящее - сначала в глубину. обход после заказа. За левым дочерним элементом следует поддерево, имеющее корень у его брата, а за правым дочерним элементом следует его родитель. Каждый элемент имеет четко определенную высоту над листьями, и каждый элемент, не являющийся листом, имеет свою дети ранее в массиве. Однако его глубина ниже корня зависит от размера массива. Алгоритм организован таким образом, что корень находится в конце кучи, и в момент извлечения элемента из кучи он уже находится в своем конечном месте и его не нужно перемещать. Кроме того, отсортированный массив уже является допустимой кучей, а многие отсортированные интервалы являются действительными упорядоченными в куче поддеревьями.
Более формально каждая позиция я является корнем уникального поддерева, узлы которого занимают непрерывный интервал, заканчивающийся на я. Начальным префиксом массива (включая весь массив) может быть такой интервал, соответствующий поддереву, но в целом он распадается как объединение ряда последовательных таких интервалов поддерева, которые Дейкстра называет «растяжками». Любое поддерево без родителя (т. Е. С корнем в позиции, родительский элемент которой лежит за рассматриваемым префиксом) дает растяжение в разложении этого интервала, поэтому такое разложение уникально. Когда к префиксу добавляется новый узел, происходит один из двух случаев: либо позиция является листом и добавляет отрезок длины 1 к разложению, либо он объединяется с двумя последними отрезками, становясь родителем их соответствующих корней, таким образом заменяя два отрезка новым отрезком, содержащим их объединение плюс новую (корневую) позицию.
Дейкстра отметил[1] что очевидным правилом было бы комбинировать отрезки тогда и только тогда, когда они имеют равный размер, и в этом случае все поддеревья будут идеальными двоичными деревьями размера 2k−1. Однако он выбрал другое правило, которое дает больше возможных размеров деревьев. Это то же самое асимптотическая эффективность,[2] но получает небольшой постоянный коэффициент эффективности, требуя меньшего количества растяжек для покрытия каждого интервала.
Правило, которое использует Дейкстра, состоит в том, что последние два отрезка комбинируются тогда и только тогда, когда их размеры являются последовательными. Числа Леонардо L(я+1) и L(я) (в этом порядке), числа которых определяются рекурсивно, аналогично Числа Фибоначчи, в качестве:
- L(0) = L(1) = 1
- L(k+2) = L(k+1) + L(k) + 1
Как следствие, размер любого поддерева - это число Леонардо. Последовательность размеров растяжек, разлагающих первую п позиции, для любых п, можно найти жадно: первый размер - это наибольшее число Леонардо, не превышающее п, а остаток (если есть) раскладывается рекурсивно. Размеры растяжек уменьшаются, строго так, за исключением, возможно, двух окончательных размеров 1 и избегания последовательных чисел Леонардо, за исключением, возможно, двух последних размеров.
В дополнение к тому, что каждый участок является деревом с упорядоченной кучей, корни деревьев поддерживаются в отсортированном порядке. Это эффективно добавляет третьего ребенка (которого Дейкстра называет «пасынок») к каждому корню, связывая его с предыдущим корнем. Это объединяет все деревья в одну глобальную кучу. с глобальным максимумом в конце.
Хотя местоположение пасынка каждого узла фиксировано, ссылка существует только для корней дерева, а это означает, что ссылки удаляются при объединении деревьев. Это отличается от обычных дочерних элементов, которые связаны, пока существует родительский элемент.
На первом этапе сортировки (рост кучи) все большая начальная часть массива реорганизуется так, что поддерево для каждого из его участков представляет собой максимальную кучу: запись в любой позиции, не являющейся конечной, имеет размер не менее записи в позициях, которые являются его дочерними элементами. К тому же все корни по размеру не меньше их пасынков.
На втором этапе (сжатие кучи) максимальный узел отсоединяется от конца массива (без необходимости его перемещать), и инварианты кучи восстанавливаются среди его дочерних узлов. (В частности, среди новоиспеченных пасынков.)
На практике часто требуется вычисление чисел Леонардо. L(k). Дейкстра предлагает умный код, который использует фиксированное количество целочисленных переменных для эффективного вычисления значений, необходимых в то время, когда они необходимы. В качестве альтернативы, если существует конечная оценка N по размеру сортируемых массивов предварительно вычисленную таблицу чисел Леонардо можно сохранить в О(бревноN) Космос.
Операции
Хотя две фазы процедуры сортировки противоположны друг другу в том, что касается развития структуры «последовательность куч», они реализуются с использованием одного базового примитива, что эквивалентно операции «отсеивания» в двоичном max- куча.
Отсеивание
Основная операция по отсеиванию (которую Дейкстра называет "побрякушки ") восстанавливает инвариант кучи, если он, возможно, нарушен только в корневом узле. Если корневой узел меньше любого из его дочерних узлов, он заменяется его самым большим дочерним узлом, и процесс повторяется с корневым узлом в его новом поддереве.
Разница между гладкой сортировкой и двоичной максимальной кучей состоит в том, что корень каждого участка должен быть упорядочен по отношению к третьему «пасынку»: корню предыдущего участка. Таким образом, процедура отсеивания начинается с серии четырехсторонних сравнений (корневой узел и три дочерних элемента) до тех пор, пока пасынок не станет максимальным элементом, затем серия трехсторонних сравнений (корень плюс два дочерних элемента) до тех пор, пока не будет корень. узел находит свой последний дом, и инварианты восстанавливаются.
Каждое дерево - это полное двоичное дерево: каждый узел имеет двух детей или ни одного. Нет необходимости иметь дело с частным случаем одного дочернего элемента, который встречается в стандартном неявном двоичная куча. (Но особый случай ссылки пасынка более чем компенсирует эту экономию.)
Потому что есть О(бревноп) растяжки, каждый из которых представляет собой дерево глубины О(бревноп), время выполнения каждой операции отсеивания ограничено О(бревноп).
Увеличение области кучи за счет включения элемента справа
Когда дополнительный элемент рассматривается для включения в последовательность участков (список непересекающихся структур кучи), он либо образует новый одноэлементный участок, либо объединяет два крайних правых участка, становясь родителем обоих их корней и формируя новый участок. который заменяет два в последовательности. Что из двух произойдет, зависит только от размеров имеющихся в настоящее время участков (и, в конечном итоге, только от индекса добавленного элемента); Дейкстра оговорил, что растяжки комбинируются тогда и только тогда, когда их размеры равны L(k+1) и L(k) для некоторых k, т.е. последовательные числа Леонардо; новый участок будет иметь размер L(k+2).
В любом случае новый элемент должен быть отсортирован до его правильного места в структуре кучи. Даже если новый узел является одноэлементным растяжением, он все равно должен быть отсортирован относительно корня предыдущего растяжения.
Оптимизация
Алгоритм Дейкстры экономит работу, замечая, что полный инвариант кучи требуется в конце фазы роста, но не требуется на каждом промежуточном этапе. В частности, требование, чтобы элемент был больше, чем его пасынок, важно только для элементов, которые являются конечными корнями дерева.
Следовательно, когда элемент добавлен, вычислите позицию его будущего родителя. Если это находится в пределах диапазона оставшихся значений для сортировки, действуйте так, как будто нет пасынка, и просеивайте только в пределах текущего дерева.
Уменьшение области кучи путем отделения от нее самого правого элемента
Во время этой фазы форма последовательности растяжек претерпевает изменения фазы роста в обратном порядке. При отделении листового узла не требуется никакой работы, но для нелистового узла два его дочерних узла становятся корнями новых участков, и их необходимо переместить на свое место в последовательности корней участков. Этого можно добиться, дважды применив sift-down: сначала для левого ребенка, а затем для правого ребенка (чей пасынок был левым ребенком).
Поскольку половина всех узлов в полном двоичном дереве являются листьями, в среднем выполняется одна операция отсеивания на узел.
Оптимизация
Уже известно, что вновь обнаженные корни правильно упорядочены по отношению к своим нормальным потомкам; Речь идет только об упорядочивании их пасынков. Таким образом, при уменьшении кучи первый шаг просеивания можно упростить до единственного сравнения с пасынком. Если происходит свопинг, на последующих шагах должно выполняться полное четырехстороннее сравнение.
Анализ
Smoothsort принимает О(п) время обработать предварительно отсортированный массив, О(п бревно п) в худшем случае и обеспечивает почти линейную производительность на многих почти отсортированных входах. Однако он не обрабатывает все почти отсортированные последовательности оптимально. Используя количество инверсий как меру несортированности (количество пар индексов я и j с я < j и А[я] > А[j]; для произвольно отсортированного ввода это примерно п2/4) возможны входные последовательности с О(п бревноп) инверсии, которые заставляют его принимать Ω (п бревноп) время, тогда как другие адаптивная сортировка алгоритмы могут решить эти случаи в О(п журнал журналп) время.[2]
Алгоритм плавной сортировки должен иметь возможность хранить в памяти размеры всех деревьев в куче Леонардо. Поскольку они отсортированы по порядку, и все заказы различны, это обычно делается с помощью битовый вектор указывая, какие заказы присутствуют. Более того, поскольку наибольший заказ не более О(бревноп)эти биты можно закодировать в О(1) машинные слова, предполагая трансдихотомическая модель машины.
Обратите внимание, что О(1) машинные слова - это не то же самое, что один машинное слово. 32-битного вектора будет достаточно только для размеров меньше, чем L(32) = 7049155. 64-битный вектор подходит для размеров меньше, чем L(64) = 34335360355129 ≈ 245. В общем, требуется 1 / журнал2(φ ) ≈ 1.44 бит вектора на бит размера.
Тополь сорт
Более простой алгоритм, вдохновленный плавной сортировкой, - тополь сорт.[5] Назван в честь рядов деревьев уменьшающегося размера, которые часто встречаются на голландском языке. польдеры, он выполняет меньше сравнений, чем плавная сортировка, для входных данных, которые в основном не отсортированы, но не может достичь линейного времени для отсортированных входных данных.
Существенное изменение, внесенное сортом тополя, состоит в том, что корни различных деревьев нет хранятся в отсортированном порядке; нет звеньев "пасынок", связывающих их в одну кучу. Вместо этого каждый раз, когда куча уменьшается на втором этапе, выполняется поиск в корнях, чтобы найти максимальную запись.
Потому что есть п усаживающиеся ступени, каждый из которых должен искать О(бревноп) корни деревьев для максимума, наилучшее время выполнения для сортировки тополя О(п бревноп).
Авторы также предлагают использовать совершенные бинарные деревья, а не деревья Леонардо, чтобы обеспечить дальнейшее упрощение, но это менее значительное изменение.
Такая же структура была предложена в качестве универсального приоритетная очередь под именем куча после заказа,[6] достижение О(1) амортизированный время вставки в структуру проще, чем неявный биномиальная куча.
Приложения
В мусл Библиотека C использует гладкую сортировку для реализации qsort ().[7][8]
Рекомендации
- ^ а б Дейкстра, Эдсгер В. 16 августа 1981 г. (EWD-796a) (PDF). E.W. Dijkstra Archive. Центр американской истории, Техасский университет в Остине.
Можно также задать вопрос, почему я не выбрал в качестве доступных длин растяжек: ... 63 31 15 7 3 1, что кажется привлекательным, поскольку каждое растяжение затем можно рассматривать как последующий обход сбалансированного двоичного дерева. Кроме того, рекуррентное соотношение было бы проще. Но я знаю, почему выбрал числа Леонардо:
(транскрипция ) - ^ а б c Хертель, Стефан (13 мая 1983 г.). "Поведение Smoothsort на предварительно отсортированных последовательностях" (PDF). Письма об обработке информации. 16 (4): 165–170. Дои:10.1016/0020-0190(83)90116-3.
- ^ Браун, Крейг (21 января 2013 г.). «Самая быстрая стабильная сортировка на месте». Код проекта.[самостоятельно опубликованный источник ]
- ^ Эйзенстат, Дэвид (13 сентября 2020 г.). "Где используется алгоритм плавной сортировки?". Переполнение стека. Получено 2020-10-28.
Smoothsort нестабилен, и стабильность часто более желательна, чем на практике
- ^ Брон, Коэнрад; Хесселинк, Вим Х. (13 сентября 1991 г.). "Повторное посещение Smoothsort". Письма об обработке информации. 39 (5): 269–276. Дои:10.1016 / 0020-0190 (91) 90027-Ф.
- ^ Харви, Николас Дж. А .; Затлукал, Кевин (26–28 мая 2004 г.). Куча после заказа. Третья международная конференция по развлечениям с алгоритмами (FUN 2004). Эльба, Италия.
- ^ Фелкер, Рич (30 апреля 2013 г.). «Как разные языки реализуют сортировку в своих стандартных библиотеках?». Переполнение стека. Получено 2020-10-28.
- ^ Фелкер, Рич; Нойкирхен, Лия (11 августа 2017 г.). "src / stdlib / qsort.c". musl - реализация стандартной библиотеки для систем на базе Linux. Получено 2020-10-28.
внешняя ссылка
- Прокомментированная транскрипция EWD796a, 16 августа 1981 г.
- Подробное современное объяснение Smoothsort
- викиучебники: Реализация алгоритмов / Сортировка / Сглаживание
- Описание и пример реализации Poplar heap
- Ношита, Кохей; Накатани, Ёсинобу (апрель 1985 г.). «О структуре вложенной кучи в Smoothsort». Математические основы информатики и их приложения (Японский: 数 理 解析 研究所 講究 録). 556: 1–16.
