Катастрофическое вмешательство - Википедия - Catastrophic interference
Катастрофическое вмешательство, также известный как катастрофическое забывание, это тенденция искусственная нейронная сеть полностью и резко забыть ранее изученную информацию при изучении новой информации.[1][2] Нейронные сети - важная часть сетевой подход и коннекционистский подход к наука о мышлении. С помощью этих сетей человеческие способности, такие как память и обучение, можно смоделировать с помощью компьютерного моделирования. Катастрофические помехи - важная проблема, которую следует учитывать при создании коннекционистских моделей памяти. Первоначально он был доведен до сведения научного сообщества исследованиями Макклоски и Коэна (1989),[1] и Рэтклифф (1990).[2] Это радикальное проявление дилеммы «чувствительность-стабильность».[3] или дилемма «стабильность-пластичность».[4] В частности, эти проблемы относятся к задаче создания искусственной нейронной сети, которая чувствительна к новой информации, но не нарушается ею. Таблицы поиска и коннекционистские сети лежат на противоположных сторонах спектра устойчивости и пластичности.[5] Первый остается полностью стабильным при наличии новой информации, но не имеет возможности обобщать, т.е. вывести общие принципы из новых входных данных. С другой стороны, коннекционистские сети, такие как стандартная сеть обратного распространения могут быть обобщены на невидимые входные данные, но они очень чувствительны к новой информации. Модели обратного распространения можно считать хорошими моделями человеческая память поскольку они отражают человеческую способность обобщать[согласно кому? ][нужна цитата ] но эти сети часто менее стабильны, чем человеческая память. Примечательно, что эти сети обратного распространения информации подвержены катастрофическим помехам. Это проблема при моделировании человеческой памяти, потому что, в отличие от этих сетей, люди обычно не проявляют катастрофического забывания.[нужна цитата ].
История катастрофического вмешательства
Термин «катастрофическая интерференция» был первоначально введен Макклоски и Коэном (1989), но также был привлечен вниманием научного сообщества в результате исследования Ратклиффа (1990).[2]
Проблема последовательного обучения: Макклоски и Коэн (1989)
Макклоски и Коэн (1989) отметили проблему катастрофических помех во время двух различных экспериментов с моделированием нейронной сети с обратным распространением.
- Эксперимент 1: Изучение фактов сложения единиц и двоек
В своем первом эксперименте они обучили стандартную нейронную сеть обратного распространения на одном обучающем наборе, состоящем из 17 задач с однозначными числами (то есть от 1 + 1 до 9 + 1 и от 1 + 2 до 1 + 9) до тех пор, пока сеть не сможет представлять и правильно ответить на все из них. Ошибка между фактическим и желаемым выходными данными неуклонно снижалась на протяжении сеансов обучения, что отражало то, что сеть научилась лучше представлять целевые выходные данные в ходе испытаний. Затем они обучили сеть на единственном обучающем наборе, состоящем из 17 задач с однозначными числами (т. Е. От 2 + 1 до 2 + 9 и от 1 + 2 до 9 + 2) до тех пор, пока сеть не сможет представлять, правильно реагировать на все их. Они отметили, что их процедура была похожа на то, как ребенок узнает свои факты сложения. После каждого испытания по изучению двух фактов сеть проверялась на знание фактов сложения единиц и двоек. Как и факты об одних, сеть легко узнала о двух фактах. Тем не менее, Макклоски и Коэн отметили, что сеть больше не могла правильно отвечать на задачи сложения единиц даже после одного пробного обучения задачам сложения двоек. Шаблон вывода, создаваемый в ответ на единичные факты, часто напоминал шаблон вывода для неправильного числа больше, чем шаблон вывода для правильного числа. Это считается серьезной ошибкой. Более того, задачи 2 + 1 и 2 + 1, которые были включены в оба набора тренировок, даже показали резкое нарушение во время первых испытаний фактов двойки.
- Эксперимент 2: Копия исследования Барнса и Андервуда (1959).[6] В своей второй коннекционистской модели Макклоски и Коэн попытались воспроизвести исследование ретроактивного вмешательства у людей, проведенное Барнсом и Андервудом (1959). Они обучили модель спискам A-B и A-C и использовали шаблон контекста во входном векторе (шаблон ввода), чтобы различать списки. В частности, сеть была обучена реагировать правильным ответом B, когда показан стимул A и шаблон контекста A-B, и отвечать правильным ответом C, когда показан стимул A и шаблон контекста A-C. Когда модель обучалась одновременно на элементах A-B и A-C, сеть легко узнала все ассоциации правильно. При последовательном обучении сначала обучался список A-B, а затем список A-C. После каждого представления списка A-C производительность измерялась как для списков A-B, так и для списков A-C. Они обнаружили, что количество тренировок в списке A-C в исследовании Барнса и Андервуда, которое приводит к 50% правильных ответов, приводит к почти 0% правильных ответов сети обратного распространения. Кроме того, они обнаружили, что сеть, как правило, показывала ответы, похожие на шаблон ответа C, когда сети предлагалось предоставить шаблон ответа B. Это указывало на то, что список A-C, по-видимому, перезаписал список A-B. Это можно сравнить с изучением слова «собака», с последующим изучением слова «стул» и последующим обнаружением, что вы не можете хорошо распознать слово «кошка», а вместо этого думайте о слове «стул», когда вам предлагается слово «собака».
Макклоски и Коэн пытались уменьшить помехи с помощью ряда манипуляций, включая изменение количества скрытых единиц, изменение значения параметра скорости обучения, перетренированность в списке AB, замораживание определенных весов соединений, изменение целевых значений 0 и 1 вместо 0,1 и 0,9 . Однако ни одна из этих манипуляций не уменьшила в достаточной степени катастрофические помехи, создаваемые сетями.
В целом Макклоски и Коэн (1989) пришли к выводу, что:
- по крайней мере, некоторое вмешательство будет происходить всякий раз, когда новое обучение изменяет задействованные веса, представляющие
- чем больше объем нового обучения, тем сильнее разрушаются старые знания
- интерференция была катастрофической в сетях обратного распространения, когда обучение было последовательным, но не одновременным
Ограничения, накладываемые обучением и забыванием функций: Рэтклифф (1990)
Рэтклифф (1990) использовал несколько наборов моделей обратного распространения, применяемых к стандартным процедурам распознавания памяти, в которых элементы были последовательно изучены.[2] Изучив модели производительности распознавания, он обнаружил две основные проблемы:
- Хорошо изученная информация была катастрофически забыта, поскольку новая информация была изучена как в малых, так и в больших сетях обратного распространения.
Даже одно испытание с использованием новой информации привело к значительной потере старой информации, что соответствует выводам Макклоски и Коэна (1989).[1] Ратклифф также обнаружил, что результирующие выходные данные часто представляют собой смесь предыдущего и нового входных данных. В более крупных сетях элементы, изученные в группах (например, AB, затем CD), были более устойчивы к забыванию, чем элементы, изученные по отдельности (например, A, затем B, затем C…). Однако забвение предметов, изученных в группах, по-прежнему было большим. Добавление новых скрытых блоков в сеть не уменьшило помех.
- Дискриминация между изучаемыми предметами и ранее невидимыми предметами уменьшалась по мере того, как сеть узнавала больше.
Этот результат противоречит исследованиям человеческой памяти, которые показали, что дискриминация увеличивается с обучением. Рэтклифф попытался решить эту проблему, добавив «узлы ответа», которые выборочно реагировали бы на старые и новые входные данные. Однако этот метод не работал, поскольку эти ответные узлы становились активными для всех входов. Модель, в которой использовался шаблон контекста, также не смогла увеличить различие между новыми и старыми элементами.
Предлагаемые решения
Основная причина катастрофических помех, по-видимому, заключается в перекрытии представлений на скрытом слое распределенных нейронных сетей.[7][8][9] В распределенном представлении каждый вход имеет тенденцию создавать изменения в весах многих узлов. Катастрофическое забывание происходит из-за того, что при изменении многих весов, в которых «хранятся знания», маловероятно, что прежние знания останутся нетронутыми. Во время последовательного обучения входные данные становятся смешанными, при этом новые входные данные накладываются поверх старых.[8] Другой способ концептуализировать это - визуализировать обучение как движение через пространство веса.[10] Это пространство весов можно сравнить с пространственным представлением всех возможных комбинаций весов, которыми может обладать сеть. Когда сеть впервые учится представлять набор шаблонов, она находит точку в пространстве весов, которая позволяет ей распознавать все эти шаблоны.[9] Однако, когда сеть затем изучает новый набор шаблонов, она переместится в место в пространстве весов, для которого единственной заботой является распознавание новых шаблонов.[9] Чтобы распознать оба набора паттернов, сеть должна найти место в весовом пространстве, подходящее для распознавания как новых, так и старых паттернов.
Ниже приводится ряд методов, которые имеют эмпирическую поддержку в успешном снижении катастрофических помех в нейронных сетях обратного распространения:
Ортогональность
Многие из ранних методов уменьшения репрезентативного перекрытия включали создание либо входных векторов, либо шаблонов активации скрытых единиц. ортогональный для другого. Левандовски и Ли (1995)[11] отметили, что интерференция между последовательно изученными шаблонами сводится к минимуму, если входные векторы ортогональны друг другу. Входные векторы называются ортогональными друг другу, если сумма попарного произведения их элементов по двум векторам равна нулю. Например, шаблоны [0,0,1,0] и [0,1,0,0] называются ортогональными, потому что (0 × 0 + 0 × 1 + 1 × 0 + 0 × 0) = 0. Один из методов, который может создавать ортогональные представления на скрытых слоях, включает биполярное кодирование признаков (т. Е. Кодирование с использованием -1 и 1 вместо 0 и 1).[9] Ортогональные узоры, как правило, создают меньше помех друг другу. Однако не все проблемы обучения могут быть представлены с использованием этих типов векторов, и некоторые исследования сообщают, что степень интерференции по-прежнему проблематична для ортогональных векторов.[2]
Техника заточки узлов
Согласно French (1991),[7] катастрофическое вмешательство возникает в прямая связь сети обратного распространения из-за взаимодействия активаций узлов или перекрытия активаций, которое происходит в распределенных представлениях на скрытом уровне. Нейронные сети которые используют очень локализованные представления, не показывают катастрофических помех из-за отсутствия перекрытия на скрытом слое. Поэтому Френч предположил, что уменьшение значения перекрытия активаций на скрытом уровне уменьшит катастрофические помехи в распределенных сетях. В частности, он предположил, что это может быть сделано путем изменения распределенных представлений на скрытом уровне на «полураспределенные» представления. «Полураспределенное» представление имеет меньшее количество активных скрытых узлов и / или более низкое значение активации для этих узлов для каждого представления, что приведет к меньшему перекрытию представлений различных входных данных на скрытом уровне. Френч рекомендовал, чтобы это можно было сделать с помощью «повышения резкости активации», техники, которая немного увеличивает активацию определенного количества наиболее активных узлов в скрытом слое, немного снижает активацию всех других узлов, а затем изменяет входное значение. - веса скрытого слоя для отражения этих изменений активации (аналогично обратному распространению ошибок).
Правило новизны
Кортге (1990)[12] предложил правило обучения для обучения нейронных сетей, называемое «правилом новизны», чтобы помочь уменьшить катастрофические помехи. Как следует из названия, это правило помогает нейронной сети изучать только те компоненты нового входа, которые отличаются от старого входа. Следовательно, правило новизны изменяет только веса, которые ранее не были выделены для хранения информации, тем самым уменьшая перекрытие представлений в скрытых единицах. Чтобы применить правило новизны, во время обучения шаблон ввода заменяется вектором новизны, который представляет компоненты, которые различаются. Когда правило новизны используется в стандартной сети обратного распространения, не происходит или уменьшается забвение старых элементов, когда новые элементы представлены последовательно.[12] Однако ограничение состоит в том, что это правило можно использовать только с автокодировщиком или с автоассоциативными сетями, в которых целевой отклик для выходного слоя идентичен входному шаблону.
Сети предварительного обучения
Макрей и Хетерингтон (1993)[8] утверждал, что люди, в отличие от большинства нейронных сетей, не берут на себя новые учебные задачи со случайным набором весов. Скорее, люди склонны привносить в задачу обширные предварительные знания, и это помогает избежать проблемы вмешательства. Они показали, что, когда сеть предварительно обучается на случайной выборке данных перед запуском задачи последовательного обучения, эти предварительные знания естественным образом ограничивают способ включения новой информации. Это могло произойти, потому что случайная выборка данных из домена, который имеет высокую степень внутренней структуры, например, английский язык, обучение будет фиксировать закономерности или повторяющиеся шаблоны, обнаруженные в этом домене. Поскольку домен основан на закономерностях, новый изученный элемент будет иметь тенденцию быть похожим на ранее полученную информацию, что позволит сети включать новые данные с небольшим вмешательством в существующие данные. В частности, входной вектор, который следует тому же шаблону закономерностей, что и ранее обученные данные, не должен вызывать кардинально другой шаблон активации на скрытом слое или радикально изменять веса.
Репетиция
Робинс (1995)[13] описали, что катастрофическое забывание можно предотвратить с помощью репетиционных механизмов. Это означает, что при добавлении новой информации нейронная сеть переобучается на некоторой ранее изученной информации. Однако в целом ранее усвоенная информация может быть недоступна для такого переподготовки. Решением для этого является «псевдо-репетиция», при которой сеть переобучается не на фактических предыдущих данных, а на их представлениях. На этом общем механизме основано несколько методов.
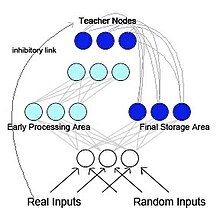
Псевдорекуррентные сети
French (1997) предложил сеть псевдорекуррентного обратного распространения (см. Рисунок 2).[5] В этой модели сеть разделена на две функционально различные, но взаимодействующие подсети. Эта модель вдохновлена биологией и основана на исследованиях McClelland et al. (1995)[14] Макклелланд и его коллеги предположили, что гиппокамп и неокортекс действуют как отдельные, но дополняющие друг друга системы памяти, при этом гиппокамп для краткосрочная память хранилище и неокортекс для Долгосрочная память место хранения. Информация, изначально хранящаяся в гиппокампе, может быть «перенесена» в неокортекс посредством реактивации или воспроизведения. В псевдорекуррентной сети одна из подсетей действует как область ранней обработки, похожая на гиппокамп, и функционирует для изучения новых шаблонов ввода. Другая подсеть действует как область окончательного хранения, похожая на неокортекс. Однако, в отличие от McClelland et al. (1995), область окончательного хранения отправляет внутренне созданное представление обратно в область ранней обработки. Это создает повторяющуюся сеть. Френч предположил, что это чередование старых представлений с новыми представлениями является единственным способом уменьшить радикальное забывание. Поскольку у мозга, скорее всего, не будет доступа к исходным входным паттернам, паттерны, которые будут возвращены в неокортекс, будут внутренне генерируемыми представлениями, называемыми псевдо-паттерны. Эти псевдо-шаблоны являются приближениями предыдущих входных данных.[13] и они могут чередоваться с изучением новых входных данных.
Самообновляющаяся память
Анс и Руссе (1997)[15] также предложил двухсетевую искусственную нейронную архитектуру с самообновление памяти который преодолевает катастрофические помехи, когда задачи последовательного обучения выполняются в распределенных сетях, обученных методом обратного распространения. Принцип заключается в чередовании, в то время, когда изучаются новые внешние шаблоны, те, которые должны быть изучены, новые внешние шаблоны с внутренне сгенерированными псевдонимами или «псевдо-воспоминаниями», которые отражают ранее изученную информацию. Что главным образом отличает эту модель от моделей, использующих классический псевдореплекс в многослойных сетях с прямой связью, так это то, что реверберирующий процесс[требуется дальнейшее объяснение ] который используется для генерации псевдошаблонов. После ряда повторных инъекций активности из одного случайного начального числа этот процесс стремится перейти к нелинейной сети. аттракторы.
Генеративное воспроизведение
В последние годы псевдорепетиции снова приобрели популярность благодаря прогрессу в возможностях глубоких репетиций. генеративные модели. Когда такие глубокие генеративные модели используются для генерации «псевдоданных», которые нужно репетировать, этот метод обычно называется генеративным воспроизведением.[16] Такое генеративное воспроизведение может эффективно предотвратить катастрофическое забывание, особенно когда воспроизведение выполняется в скрытых слоях, а не на уровне ввода.[17][18]
Скрытое обучение
Скрытое обучение - метод, используемый Gutstein & Stump (2015)[19] для смягчения катастрофических помех за счет использования передача обучения. Этот подход пытается найти оптимальные кодировки для любых новых классов, которые должны быть изучены, чтобы они с наименьшей вероятностью катастрофически повлияли на существующие ответы. Учитывая сеть, которая научилась различать один набор классов с помощью выходных кодов с исправлением ошибок (ECOC)[20] (в отличие от 1 горячие коды ) оптимальные кодировки для новых классов выбираются путем наблюдения за средними откликами сети на них. Поскольку эти средние ответы возникли при изучении исходного набора классов без знакомства с новыми классами, они называются «запаздывающими кодировками». Эта терминология заимствована из концепции Скрытое обучение, представленный Толменом в 1930 году.[21] Фактически, этот метод использует переносное обучение, чтобы избежать катастрофических помех, делая ответы сети на новые классы как можно более согласованными с существующими ответами на уже изученные классы.
Упругое уплотнение веса
Киркпатрик и др. (2017)[22] предложила эластичную консолидацию веса (EWC), метод последовательного обучения одной искусственной нейронной сети нескольким задачам. Этот метод предполагает, что некоторые веса обученной нейронной сети более важны для ранее изученных задач, чем другие. Во время обучения нейронной сети новой задаче изменения весов сети становятся менее вероятными, чем больше их важность. Для оценки важности сетевых весов EWC использует вероятностные механизмы, в частности информационную матрицу Фишера, но это можно сделать и другими способами.[23][24]
Рекомендации
- ^ а б c Макклоски, Майкл; Коэн, Нил Дж. (1989). Катастрофическое вмешательство в коннекционистские сети: проблема последовательного обучения. Психология обучения и мотивации. 24. С. 109–165. Дои:10.1016 / S0079-7421 (08) 60536-8. ISBN 978-0-12-543324-2.
- ^ а б c d е Рэтклифф, Роджер (1990). «Коннекционистские модели памяти распознавания: ограничения, накладываемые функциями обучения и забывания». Психологический обзор. 97 (2): 285–308. Дои:10.1037 / 0033-295x.97.2.285. PMID 2186426.
- ^ Хебб, Дональд Олдинг (1949). Организация поведения: нейропсихологическая теория. Вайли. ISBN 978-0-471-36727-7. OCLC 569043119.[страница нужна ]
- ^ Карпентер, Гейл А .; Гроссберг, Стивен (1 декабря 1987 г.). «ART 2: самоорганизация устойчивых кодов распознавания категорий для аналоговых входных шаблонов». Прикладная оптика. 26 (23): 4919–4930. Bibcode:1987ApOpt..26.4919C. Дои:10.1364 / AO.26.004919. PMID 20523470.
- ^ а б Френч, Роберт М. (декабрь 1997 г.). «Псевдорекуррентные коннекционистские сети: подход к дилемме« чувствительность-стабильность »». Связь Наука. 9 (4): 353–380. Дои:10.1080/095400997116595.
- ^ Барнс, Жан М .; Андервуд, Бентон Дж. (Август 1959 г.). "'Судьба ассоциаций первого списка в теории переноса ». Журнал экспериментальной психологии. 58 (2): 97–105. Дои:10,1037 / ч0047507. PMID 13796886.
- ^ а б Френч, Роберт М. (1991). Использование полураспределенных представлений для преодоления катастрофического забвения в сетях коннекционистов (PDF). Труды 13-й ежегодной конференции общества когнитивных наук. Нью-Джерси: Лоуренс Эрлбаум. С. 173–178. CiteSeerX 10.1.1.1040.3564.
- ^ а б c «Катастрофические помехи устранены в предварительно обученных сетях». Труды пятнадцатой ежегодной конференции Общества когнитивных наук: 18–21 июня 1993 г., Институт когнитивных наук, Университет Колорадо-Боулдер. Психология Press. 1993. С. 723–728. ISBN 978-0-8058-1487-3.
- ^ а б c d French, R (1 апреля 1999 г.). «Катастрофическое забывание в коннекционистских сетях». Тенденции в когнитивных науках. 3 (4): 128–135. Дои:10.1016 / S1364-6613 (99) 01294-2. PMID 10322466. S2CID 2691726.
- ^ Левандовски, Стефан (1991). «Постепенное разучивание и катастрофическое вмешательство: сравнение распределенных архитектур». В Hockley, William E .; Левандовски, Стефан (ред.). Связь теории и данных: очерки человеческой памяти в честь Беннета Б. Мердока. Психология Press. С. 445–476. ISBN 978-1-317-76013-9.
- ^ Левандовски, Стефан; Ли, Шу-Чен (1995). «Катастрофические помехи в нейронных сетях». Вмешательство и торможение познания. С. 329–361. Дои:10.1016 / B978-012208930-5 / 50011-8. ISBN 978-0-12-208930-5.
- ^ а б Кортге, К. А. (1990). Эпизодическая память в коннекционистских сетях. В: Двенадцатая ежегодная конференция Общества когнитивных наук, (стр. 764-771). Хиллсдейл, Нью-Джерси: Лоуренс Эрлбаум.
- ^ а б Робинс, Энтони (июнь 1995 г.). «Катастрофическое забывание, репетиция и псевдорепетиция». Связь Наука. 7 (2): 123–146. Дои:10.1080/09540099550039318.
- ^ McClelland, James L .; McNaughton, Bruce L .; О'Рейли, Рэндалл С. (июль 1995 г.). «Почему существуют дополнительные системы обучения в гиппокампе и неокортексе: выводы из успехов и неудач коннекционистских моделей обучения и памяти». Психологический обзор. 102 (3): 419–457. Дои:10.1037 / 0033-295X.102.3.419. PMID 7624455.
- ^ Анс, Бернард; Руссе, Стефан (декабрь 1997 г.). «Как избежать катастрофического забывания за счет соединения двух реверберирующих нейронных сетей». Comptes Rendus de l'Académie des Sciences - Серия III - Sciences de la Vie. 320 (12): 989–997. Bibcode:1997CRASG.320..989A. Дои:10.1016 / S0764-4469 (97) 82472-9.
- ^ Мокану, Дечебал Константин; Торрес Вега, Мария; Итон, Эрик; Стоун, Питер; Лиотта, Антонио (18 октября 2016 г.). «Онлайн-контрастное расхождение с генеративным воспроизведением: воспользуйтесь воспроизведением без сохранения данных». arXiv:1610.05555 [cs.LG ].
- ^ Шин, Ханул; Ли, Чон Квон; Ким, Джэхон; Ким, Дживон (декабрь 2017 г.). Непрерывное обучение с глубоким генеративным воспроизведением. НИПС'17: Материалы 31-й Международной конференции по системам обработки нейронной информации. Curran Associates. С. 2994–3003. ISBN 978-1-5108-6096-4.
- ^ van de Ven, Gido M .; Siegelmann, Hava T .; Толиас, Андреас С. (13 августа 2020 г.). «Вдохновленный мозгом повтор для непрерывного обучения с помощью искусственных нейронных сетей». Nature Communications. 11 (1): 4069. Bibcode:2020НатКо..11,4069В. Дои:10.1038 / s41467-020-17866-2. ЧВК 7426273. PMID 32792531.
- ^ Гутштейн, Стивен; Стамп, Итан (2015). «Уменьшение катастрофического забывания с помощью трансферного обучения и троичных кодов вывода». 2015 Международная совместная конференция по нейронным сетям (IJCNN). С. 1–8. Дои:10.1109 / IJCNN.2015.7280416. ISBN 978-1-4799-1960-4. S2CID 18745466.
- ^ Dietterich, T. G .; Бакири, Г. (1 января 1995 г.). «Решение проблем многоклассового обучения с помощью выходных кодов с исправлением ошибок». Журнал исследований искусственного интеллекта. 2: 263–286. Дои:10.1613 / jair.105. S2CID 47109072.
- ^ Толман, E.C .; Honzik, C.H. (1930). "'Понимание крыс ». Публикации по психологии. Калифорнийский университет. 4: 215–232.
- ^ Киркпатрик, Джеймс; Паскану, Разван; Рабиновиц, Нил; Венесс, Джоэл; Дежарден, Гийом; Русу, Андрей А .; Милан, Киран; Куан, Джон; Рамальо, Тьяго; Грабска-Барвинска, Агнешка; Хассабис, Демис; Клопат, Клаудиа; Кумаран, Дхаршан; Хадселл, Райя (14 марта 2017 г.). «Преодоление катастрофического забывания в нейронных сетях». Труды Национальной академии наук. 114 (13): 3521–3526. Дои:10.1073 / pnas.1611835114. ЧВК 5380101. PMID 28292907.
- ^ Зенке, Фридеманн; Пул, Бен; Гангули, Сурья (2017). «Непрерывное обучение с помощью синаптического интеллекта». Труды исследования машинного обучения. 70: 3987–3995. arXiv:1703.04200. ЧВК 6944509. PMID 31909397.
- ^ Альджунди, Рахаф; Вавилони, Франческа; Эльхосейни, Мохамед; Рорбах, Маркус; Туйтелаарс, Тинне (2018). «Синапсы, осознающие память: учимся, что (не) забывать». Компьютерное зрение - ECCV 2018. Конспект лекций по информатике. 11207. С. 144–161. arXiv:1711.09601. Дои:10.1007/978-3-030-01219-9_9. ISBN 978-3-030-01218-2. S2CID 4254748.