Машинное обучение - Machine learning
| Часть серии по |
| Машинное обучение и сбор данных |
|---|
Площадки для машинного обучения |
Машинное обучение (ML) - это изучение компьютерных алгоритмов, которые автоматически улучшаются по мере накопления опыта.[1] Это рассматривается как подмножество искусственный интеллект. Алгоритмы машинного обучения создают модель на основе выборочных данных, известных как "данные обучения ", чтобы делать прогнозы или решения, не будучи явно запрограммированными на это.[2] Алгоритмы машинного обучения используются в самых разных приложениях, таких как фильтрация электронной почты и компьютерное зрение, где сложно или невозможно разработать традиционные алгоритмы для выполнения необходимых задач.
Подмножество машинного обучения тесно связано с вычислительная статистика, который ориентирован на создание прогнозов с помощью компьютеров; но не все машинное обучение - это статистическое обучение. Изучение математическая оптимизация предоставляет методы, теорию и прикладные области в области машинного обучения. Сбор данных является смежной областью обучения, уделяя особое внимание разведочный анализ данных через обучение без учителя.[4][5] В своем применении к бизнес-задачам машинное обучение также называется прогнозная аналитика.
Обзор
Машинное обучение предполагает, что компьютеры обнаруживают, как они могут выполнять задачи, не будучи явно запрограммированными на это. Он включает в себя обучение компьютеров на предоставленных данных для выполнения определенных задач. Для простых задач, возложенных на компьютеры, можно запрограммировать алгоритмы, сообщающие машине, как выполнять все шаги, необходимые для решения данной проблемы; со стороны компьютера никакого обучения не требуется. Для более сложных задач человеку может быть сложно вручную создать необходимые алгоритмы. На практике может оказаться более эффективным помочь машине разработать свой собственный алгоритм, чем заставлять программистов указывать каждый необходимый шаг.[6]
В дисциплине машинного обучения используются различные подходы к обучению компьютеров выполнению задач, для которых не существует полностью удовлетворительного алгоритма. В случаях, когда существует огромное количество возможных ответов, один из подходов - пометить некоторые правильные ответы как действительные. Затем их можно использовать в качестве обучающих данных для компьютера, чтобы улучшить алгоритм (ы), которые он использует для определения правильных ответов. Например, чтобы обучить систему задаче распознавания цифровых символов, MNIST часто использовался набор рукописных цифр.[6]
Подходы к машинному обучению
Подходы к машинному обучению традиционно делятся на три широкие категории в зависимости от характера «сигнала» или «обратной связи», доступного системе обучения:
- Контролируемое обучение: Компьютеру представлены примеры входных данных и желаемых выходных данных, данные «учителем», и цель состоит в том, чтобы усвоить общее правило, которое карты входы к выходам.
- Обучение без учителя: Алгоритму обучения не присваиваются метки, он сам может найти структуру во входных данных. Обучение без учителя может быть самоцелью (обнаружение скрытых закономерностей в данных) или средством достижения цели (особенности обучения ).
- Обучение с подкреплением: Компьютерная программа взаимодействует с динамической средой, в которой она должна выполнять определенную цель (например, вождение автомобиля или играя в игру против соперника). При перемещении по проблемному пространству программа получает обратную связь, аналогичную вознаграждениям, которые она пытается максимизировать.[3]
Были разработаны другие подходы, которые не вписываются в эту тройную категоризацию, и иногда в одной и той же системе машинного обучения используется несколько. Например тематическое моделирование, уменьшение размерности или же мета-обучение.[7]
По состоянию на 2020 год глубокое обучение стал доминирующим подходом для продолжающейся работы в области машинного обучения.[6]
История и связь с другими областями
Период, термин машинное обучение был придуман в 1959 году Артур Сэмюэл, американец IBMer и пионер в области компьютерные игры и искусственный интеллект.[8][9] Типичной книгой исследований машинного обучения в 1960-х годах была книга Нильссона об обучающих машинах, посвященная в основном машинному обучению для классификации шаблонов.[10] Интерес, связанный с распознаванием образов, сохранялся и в 1970-х годах, как описали Дуда и Харт в 1973 году.[11] В 1981 году был представлен отчет об использовании обучающих стратегий, согласно которым нейронная сеть учится распознавать 40 символов (26 букв, 10 цифр и 4 специальных символа) с компьютерного терминала.[12]
Том М. Митчелл предоставил широко цитируемое, более формальное определение алгоритмов, изучаемых в области машинного обучения: «Считается, что компьютерная программа учится на собственном опыте. E относительно некоторого класса задач Т и показатель эффективности п если его производительность при выполнении задач в Т, как измерено п, улучшается с опытом E."[13] Такое определение задач, связанных с машинным обучением, предлагает принципиально Рабочее определение вместо того, чтобы определять эту область в когнитивных терминах. Это следует Алан Тьюринг предложение в его газете "Вычислительная техника и интеллект », в котором вопрос« Могут ли машины мыслить? »заменен вопросом« Могут ли машины делать то, что мы (как мыслящие сущности) можем? ».[14]
Искусственный интеллект


Как научное направление машинное обучение выросло из поиска искусственного интеллекта. В первые дни ИИ как Академическая дисциплина, некоторые исследователи были заинтересованы в том, чтобы машины учились на данных. Они пытались подойти к проблеме с помощью различных символических методов, а также того, что тогда называлось "нейронные сети "; в основном это были перцептроны и другие модели позже выяснилось, что это переизобретения обобщенные линейные модели статистики.[17] Вероятностный рассуждения также использовались, особенно в автоматизированных медицинский диагноз.[18]:488
Однако все больший упор на логический, основанный на знаниях подход вызвал разрыв между ИИ и машинным обучением. Вероятностные системы страдали от теоретических и практических проблем сбора и представления данных.[18]:488 К 1980 г. экспертные системы стал доминировать над ИИ, и статистика была в немилости.[19] Работа над символическим / основанным на знаниях обучением продолжалась в рамках ИИ, что привело к индуктивное логическое программирование, но более статистические исследования теперь выходили за рамки собственно ИИ, в распознавание образов и поиск информации.[18]:708–710; 755 Исследования нейронных сетей были прекращены ИИ и Информатика примерно в то же время. Эта линия также была продолжена за пределами поля AI / CS, как "коннекционизм "исследователями из других дисциплин, включая Hopfield, Румельхарт и Хинтон. Их главный успех пришелся на середину 1980-х годов, когда они заново открыли обратное распространение.[18]:25
Машинное обучение (ML), реорганизованное в отдельную область, начало процветать в 1990-х годах. Область изменила свою цель с создания искусственного интеллекта на решение решаемых проблем практического характера. Он сместил фокус с символические подходы он унаследовал от ИИ, а также методы и модели, заимствованные из статистики и теория вероятности.[19]
По состоянию на 2020 год многие источники продолжают утверждать, что машинное обучение остается под областью ИИ.[20][21][22] Основное разногласие заключается в том, является ли машинное обучение частью ИИ, поскольку это будет означать, что любой, кто использует машинное обучение, может утверждать, что использует ИИ. Другие считают, что не все машинное обучение является частью ИИ.[23][24][25] где только «интеллектуальное» подмножество машинного обучения является частью ИИ.[26]
На вопрос, в чем разница между ML и AI, отвечает Жемчужина Иудеи в Книга Почему.[27] Соответственно, машинное обучение учится и предсказывает на основе пассивных наблюдений, тогда как ИИ подразумевает, что агент взаимодействует с окружающей средой, чтобы учиться и предпринимать действия, которые увеличивают его шансы на успешное достижение своих целей.[30]
Сбор данных
Машинное обучение и сбор данных часто используют одни и те же методы и значительно перекрывают друг друга, но в то время как машинное обучение фокусируется на прогнозировании, на основе известен свойства, полученные из обучающих данных, сбор данных фокусируется на открытие из (ранее) неизвестный свойства в данных (это этап анализа открытие знаний в базах данных). В интеллектуальном анализе данных используется множество методов машинного обучения, но с разными целями; с другой стороны, машинное обучение также использует методы интеллектуального анализа данных как «обучение без учителя» или как этап предварительной обработки для повышения точности обучения. Большая часть путаницы между этими двумя исследовательскими сообществами (которые часто имеют отдельные конференции и отдельные журналы, ECML PKDD является серьезным исключением) исходит из основных допущений, с которыми они работают: в машинном обучении производительность обычно оценивается по способности воспроизводить известные знаний, в то время как в области обнаружения знаний и интеллектуального анализа данных (KDD) ключевой задачей является обнаружение ранее неизвестный знание. Неинформированный (неконтролируемый) метод, оцениваемый на основе известных знаний, будет легко уступать другим контролируемым методам, в то время как в типичной задаче KDD контролируемые методы не могут использоваться из-за недоступности обучающих данных.
Оптимизация
Машинное обучение также тесно связано с оптимизация: многие проблемы обучения формулируются как минимизация некоторых функция потерь на обучающем наборе примеров. Функции потерь выражают несоответствие между прогнозами обучаемой модели и фактическими экземплярами проблемы (например, при классификации нужно присвоить экземплярам метку, а модели обучены правильно предсказывать заранее назначенные метки набора Примеры). Разница между этими двумя полями проистекает из цели обобщения: в то время как алгоритмы оптимизации могут минимизировать потери в обучающей выборке, машинное обучение занимается минимизацией потерь в невидимых выборках.[31]
Статистика
Машинное обучение и статистика являются тесно связанными областями с точки зрения методов, но разными по своей основной цели: статистика привлекает население выводы из образец, в то время как машинное обучение находит обобщенные модели прогнозирования.[32] В соответствии с Майкл И. Джордан, идеи машинного обучения, от методологических принципов до теоретических инструментов, имеют долгую предысторию в статистике.[33] Он также предложил термин наука о данных как заполнитель для вызова всего поля.[33]
Лео Брейман выделили две парадигмы статистического моделирования: модель данных и алгоритмическую модель,[34] где «алгоритмическая модель» в большей или меньшей степени означает алгоритмы машинного обучения, такие как Случайный лес.
Некоторые статистики переняли методы машинного обучения, что привело к созданию комбинированной области, которую они называют статистическое обучение.[35]
Теория
Основная цель учащегося - обобщить свой опыт.[3][36] Обобщение в этом контексте - это способность обучающейся машины точно выполнять новые, невидимые примеры / задачи после изучения набора обучающих данных. Примеры обучения берутся из некоторого, как правило, неизвестного распределения вероятностей (которое считается репрезентативным для пространства вхождений), и обучающийся должен построить общую модель этого пространства, которая позволит ему производить достаточно точные прогнозы в новых случаях.
Вычислительный анализ алгоритмов машинного обучения и их производительности является отраслью теоретическая информатика известный как теория вычислительного обучения. Поскольку обучающие наборы конечны, а будущее неопределенно, теория обучения обычно не дает гарантий производительности алгоритмов. Вместо этого довольно распространены вероятностные границы производительности. В декомпозиция смещения – дисперсии это один из способов количественной оценки обобщения ошибка.
Для наилучшей производительности в контексте обобщения сложность гипотезы должна соответствовать сложности функции, лежащей в основе данных. Если гипотеза менее сложна, чем функция, то модель не соответствует данным. Если сложность модели увеличивается в ответ, то ошибка обучения уменьшается. Но если гипотеза слишком сложна, то модель подлежит переоснащение и обобщение будет хуже.[37]
Помимо пределов производительности, теоретики обучения изучают временную сложность и осуществимость обучения. В теории вычислительного обучения вычисление считается выполнимым, если оно может быть выполнено в полиномиальное время. Есть два вида временная сложность полученные результаты. Положительные результаты показывают, что определенный класс функций можно изучить за полиномиальное время. Отрицательные результаты показывают, что некоторые классы нельзя изучить за полиномиальное время.
Подходы
Типы алгоритмов обучения
Типы алгоритмов машинного обучения различаются по своему подходу, типу данных, которые они вводят и выводят, и типу задачи или проблемы, для решения которых они предназначены.
Контролируемое обучение

Алгоритмы контролируемого обучения создают математическую модель набора данных, который содержит как входные, так и желаемые выходы.[38] Данные известны как данные обучения, и состоит из набора обучающих примеров. Каждый обучающий пример имеет один или несколько входов и желаемый выход, также известный как контрольный сигнал. В математической модели каждый обучающий пример представлен множество или вектор, иногда называемый вектором признаков, а обучающие данные представлены матрица. Через итеративная оптимизация из целевая функция алгоритмы контролируемого обучения изучают функцию, которую можно использовать для прогнозирования выходных данных, связанных с новыми входными данными.[39] Оптимальная функция позволит алгоритму правильно определять выходные данные для входных данных, которые не были частью обучающих данных. Говорят, что алгоритм, который со временем повышает точность своих выходных данных или прогнозов, научился выполнять эту задачу.[13]
Типы алгоритмов контролируемого обучения включают: активное изучение, классификация и регресс.[40] Алгоритмы классификации используются, когда выходные данные ограничены ограниченным набором значений, а алгоритмы регрессии используются, когда выходы могут иметь любое числовое значение в пределах диапазона. Например, для алгоритма классификации, который фильтрует электронные письма, входом будет входящее электронное письмо, а выходом будет имя папки, в которую будет сохранено электронное письмо.
Изучение подобия - это область контролируемого машинного обучения, тесно связанная с регрессией и классификацией, но цель состоит в том, чтобы учиться на примерах с использованием функции сходства, которая измеряет, насколько похожи или связаны два объекта. Он имеет приложения в рейтинг, системы рекомендаций, визуальное отслеживание личности, проверка лица и проверка говорящего.
Обучение без учителя
Алгоритмы неконтролируемого обучения берут набор данных, который содержит только входные данные, и находят структуру в данных, такую как группировка или кластеризация точек данных. Следовательно, алгоритмы учатся на тестовых данных, которые не были помечены, классифицированы или категоризированы. Вместо того, чтобы реагировать на обратную связь, алгоритмы неконтролируемого обучения выявляют общие черты в данных и реагируют на наличие или отсутствие таких общих черт в каждой новой части данных. Центральное применение обучения без учителя находится в области оценка плотности в статистика, например, поиск функция плотности вероятности.[41] Хотя обучение без учителя охватывает другие области, включающие обобщение и объяснение функций данных.
Кластерный анализ - это разделение набора наблюдений на подмножества (называемые кластеры), так что наблюдения в одном кластере похожи по одному или нескольким заранее заданным критериям, тогда как наблюдения, полученные из разных кластеров, не похожи. Различные методы кластеризации делают разные предположения о структуре данных, часто определяемые некоторыми показатель сходства и оценивается, например, внутренняя компактность, или сходство между членами одного кластера, и разделение, разница между кластерами. Остальные методы основаны на расчетная плотность и графическое соединение.
Полу-контролируемое обучение
Полу-контролируемое обучение находится между обучение без учителя (без помеченных данных обучения) и контролируемое обучение (с полностью размеченными данными обучения). В некоторых обучающих примерах отсутствуют обучающие метки, но многие исследователи машинного обучения обнаружили, что немаркированные данные при использовании в сочетании с небольшим количеством помеченных данных могут значительно повысить точность обучения.
В обучение без учителя, метки обучения шумные, ограниченные или неточные; однако эти метки часто дешевле получить, что приводит к более эффективным обучающим выборкам.[42]
Обучение с подкреплением
Обучение с подкреплением - это область машинного обучения, касающаяся того, как программные агенты должен взять действия в среде, чтобы максимизировать некоторое понятие кумулятивного вознаграждения. Из-за своей общности эта область изучается во многих других дисциплинах, таких как теория игры, теория управления, исследование операций, теория информации, оптимизация на основе моделирования, мультиагентные системы, рой интеллект, статистика и генетические алгоритмы. В машинном обучении среда обычно представлена как Марковский процесс принятия решений (MDP). Многие алгоритмы обучения с подкреплением используют динамическое программирование техники.[43] Алгоритмы обучения с подкреплением не предполагают знания точной математической модели MDP и используются, когда точные модели невозможны. Алгоритмы обучения с подкреплением используются в автономных транспортных средствах или при обучении игре против человеческого противника.
Самостоятельное обучение
Самообучение как парадигма машинного обучения была представлена в 1982 году вместе с нейронной сетью, способной к самообучению, названной поперечный адаптивный массив (CAA).[44] Это обучение без внешнего вознаграждения и без совета внешнего учителя. Алгоритм самообучения CAA перекрестным образом вычисляет как решения о действиях, так и эмоции (чувства) в отношении последствий ситуаций. Система управляется взаимодействием познания и эмоций.[45]Алгоритм самообучения обновляет матрицу памяти W = || w (a, s) || таким образом, что на каждой итерации выполняется следующая процедура машинного обучения:
В ситуации s выполнить действие a; Получите последствие ситуации s '; Вычислить эмоцию пребывания в ситуации последствия v (s ’); Обновить память перекладины w ’(a, s) = w (a, s) + v (s’).
Это система только с одним входом, ситуацией s и только одним выходом, действием (или поведением) a. Нет ни отдельного подкрепления, ни совета из среды. Ценность обратного распространения (вторичное подкрепление) - это эмоция по отношению к ситуации последствий. CAA существует в двух средах: одна - это поведенческая среда, в которой он ведет себя, а другая - генетическая среда, откуда он изначально и только один раз получает начальные эмоции по поводу ситуаций, с которыми он может столкнуться в поведенческой среде. После получения вектора генома (видов) из генетической среды CAA обучается целенаправленному поведению в среде, которая содержит как желательные, так и нежелательные ситуации.[46]
Особенности обучения
Несколько алгоритмов обучения направлены на обнаружение лучшего представления входных данных, предоставляемых во время обучения.[47] Классические примеры включают анализ основных компонентов и кластерный анализ. Алгоритмы изучения функций, также называемые алгоритмами обучения представлению, часто пытаются сохранить информацию во входных данных, но также преобразовать ее таким образом, чтобы сделать ее полезной, часто в качестве этапа предварительной обработки перед выполнением классификации или предсказаний. Этот метод позволяет реконструировать входные данные, поступающие из неизвестного распределения, генерирующего данные, при этом не обязательно сохраняя верность конфигурациям, которые неправдоподобны для этого распределения. Это заменяет руководство разработка функций, и позволяет машине как изучать функции, так и использовать их для выполнения определенной задачи.
Изучение функций может быть контролируемым или неконтролируемым. При обучении с учителем функции изучаются с использованием помеченных входных данных. Примеры включают искусственные нейронные сети, многослойные персептроны, и под наблюдением изучение словаря. При неконтролируемом обучении функций функции изучаются с помощью немаркированных входных данных. Примеры включают изучение словаря, независимый компонентный анализ, автокодеры, матричная факторизация[48] и различные формы кластеризация.[49][50][51]
Множественное обучение алгоритмы пытаются сделать это при ограничении, что изученное представление является низкоразмерным. Разреженное кодирование алгоритмы пытаются сделать это с ограничением, что изученное представление является разреженным, что означает, что математическая модель имеет много нулей. Мультилинейное подпространственное обучение алгоритмы нацелены на изучение низкоразмерных представлений непосредственно из тензор представления многомерных данных без преобразования их в многомерные векторы.[52] Глубокое обучение алгоритмы обнаруживают несколько уровней представления или иерархию функций с более высокоуровневыми, более абстрактными функциями, определенными в терминах (или генерирующих) функций более низкого уровня. Утверждалось, что интеллектуальная машина - это машина, которая изучает представление, которое выделяет основные факторы вариации, объясняющие наблюдаемые данные.[53]
Функциональное обучение мотивировано тем фактом, что задачи машинного обучения, такие как классификация, часто требуют ввода, который математически и вычислительно удобно обрабатывать. Однако реальные данные, такие как изображения, видео и сенсорные данные, не поддались попыткам алгоритмического определения конкретных характеристик. Альтернативой является тщательное изучение таких функций или представлений, не полагаясь на явные алгоритмы.
Скудное изучение словаря
Изучение разреженного словаря - это метод изучения функций, в котором обучающий пример представлен как линейная комбинация базисные функции, и предполагается разреженная матрица. Метод сильно NP-жесткий и сложно решить приблизительно.[54] Популярный эвристический Методом редкого изучения словаря является К-СВД алгоритм. Редкое изучение словаря применялось в нескольких контекстах. При классификации проблема состоит в том, чтобы определить класс, к которому принадлежит ранее невидимый обучающий пример. Для словаря, в котором каждый класс уже создан, новый обучающий пример связан с классом, который лучше всего редко представлен соответствующим словарем. Редкое изучение словаря также применялось в уменьшение шума изображения. Ключевая идея состоит в том, что чистый фрагмент изображения может быть редко представлен словарем изображений, а шум - нет.[55]
Обнаружение аномалий
В сбор данных, обнаружение аномалий, также известное как обнаружение выбросов, - это идентификация редких элементов, событий или наблюдений, вызывающих подозрения, поскольку они значительно отличаются от большинства данных.[56] Обычно аномальные предметы представляют собой такую проблему, как банковское мошенничество, структурный дефект, проблемы со здоровьем или ошибки в тексте. Аномалии называются выбросы, новинки, шумы, отклонения и исключения.[57]
В частности, в контексте обнаружения злоупотреблений и сетевых вторжений интересными объектами часто являются не редкие объекты, а неожиданные всплески бездействия. Этот шаблон не соответствует общему статистическому определению выброса как редкого объекта, и многие методы обнаружения выбросов (в частности, неконтролируемые алгоритмы) не работают с такими данными, если они не были агрегированы надлежащим образом. Вместо этого алгоритм кластерного анализа может обнаруживать микрокластеры, образованные этими шаблонами.[58]
Существуют три широкие категории методов обнаружения аномалий.[59] Методы неконтролируемого обнаружения аномалий обнаруживают аномалии в немаркированном наборе тестовых данных в предположении, что большинство экземпляров в наборе данных являются нормальными, путем поиска экземпляров, которые кажутся наименее подходящими для остальной части набора данных. Для контролируемых методов обнаружения аномалий требуется набор данных, который был помечен как «нормальный» и «ненормальный», и включает обучение классификатора (ключевым отличием от многих других задач статистической классификации является несбалансированный характер обнаружения выбросов). Методы полууправляемого обнаружения аномалий создают модель, представляющую нормальное поведение из заданного набора данных для нормального обучения, а затем проверяют вероятность создания тестового экземпляра моделью.
Обучение роботов
В развивающая робототехника, обучение роботов алгоритмы генерируют свою собственную последовательность обучения, также известную как учебная программа, для совокупного приобретения новых навыков посредством самостоятельного исследования и социального взаимодействия с людьми. Эти роботы используют такие механизмы наведения, как активное обучение, созревание, моторная синергия и имитация.
Правила ассоциации
Изучение правил ассоциации - это машинное обучение на основе правил метод обнаружения взаимосвязей между переменными в больших базах данных. Он предназначен для выявления строгих правил, обнаруженных в базах данных, с использованием некоторой степени «интересности».[60]
Машинное обучение на основе правил - это общий термин для любого метода машинного обучения, который определяет, изучает или развивает «правила» для хранения, манипулирования или применения знаний. Определяющей характеристикой алгоритма машинного обучения на основе правил является идентификация и использование набора реляционных правил, которые в совокупности представляют знания, полученные системой. Это контрастирует с другими алгоритмами машинного обучения, которые обычно определяют особую модель, которую можно универсально применить к любому экземпляру, чтобы сделать прогноз.[61] Подходы к машинному обучению на основе правил включают обучающие системы классификаторов, обучение правил ассоциации и искусственная иммунная система.
Основываясь на концепции строгих правил, Ракеш Агравал, Томаш Имелиньски и Арун Свами представил правила ассоциации для обнаружения закономерностей между продуктами в данных крупномасштабных транзакций, записанных торговая точка (POS) системы в супермаркетах.[62] Например, правило Данные о продажах в супермаркете указывают на то, что, если покупатель покупает лук и картофель вместе, он, вероятно, также купит мясо для гамбургеров. Такая информация может использоваться в качестве основы для принятия решений о маркетинговых мероприятиях, например о рекламных ценообразование или же размещение продуктов. В добавление к анализ корзины, правила ассоциации используются сегодня в прикладных областях, включая Майнинг использования Интернета, обнаружения вторжений, непрерывное производство, и биоинформатика. По сравнению с последовательная добыча при изучении правил ассоциации обычно не учитывается порядок элементов ни внутри транзакции, ни между транзакциями.

Системы обучающих классификаторов (LCS) - это семейство алгоритмов машинного обучения на основе правил, которые объединяют компонент обнаружения, обычно генетический алгоритм, с обучающим компонентом, выполняя либо контролируемое обучение, обучение с подкреплением, или же обучение без учителя. Они стремятся определить набор контекстно-зависимых правил, которые коллективно хранят и применяют знания в кусочно манера делать прогнозы.[63]
Индуктивное логическое программирование (ILP) - это подход к изучению правил с использованием логическое программирование как единообразное представление исходных примеров, базовых знаний и гипотез. Учитывая кодировку известных фоновых знаний и набор примеров, представленных в виде логической базы данных фактов, система ILP будет выводить гипотетическую логическую программу, которая влечет за собой все положительные и без отрицательных примеров. Индуктивное программирование - это связанная область, которая рассматривает любой язык программирования для представления гипотез (а не только логическое программирование), например функциональные программы.
Индуктивное логическое программирование особенно полезно в биоинформатика и обработка естественного языка. Гордон Плоткин и Эхуд Шапиро заложил начальную теоретическую основу индуктивного машинного обучения в логической среде.[64][65][66] Шапиро построил свою первую реализацию (систему вывода моделей) в 1981 году: программу на языке Prolog, которая индуктивно выводила логические программы из положительных и отрицательных примеров.[67] Период, термин индуктивный здесь относится к философский индукции, предлагая теорию для объяснения наблюдаемых фактов, а не математическая индукция, доказывая свойство для всех членов упорядоченного множества.
Модели
Машинное обучение предполагает создание модель, который обучается на некоторых обучающих данных, а затем может обрабатывать дополнительные данные для создания прогнозов. Для систем машинного обучения использовались и исследовались различные типы моделей.
Искусственные нейронные сети

Искусственные нейронные сети (ИНС), или коннекционист системы, вычислительные системы смутно вдохновлены биологические нейронные сети которые составляют животное мозги. Такие системы «учатся» выполнять задачи, рассматривая примеры, обычно без программирования каких-либо правил для конкретных задач.
ИНС - это модель, основанная на наборе связанных блоков или узлов, называемых "искусственные нейроны ", которые свободно моделируют нейроны в биологическом мозг. Каждое соединение, как и синапсы в биологическом мозг, может передавать информацию, «сигнал», от одного искусственного нейрона к другому. Искусственный нейрон, который получает сигнал, может обработать его, а затем передать сигнал дополнительным искусственным нейронам, подключенным к нему. В обычных реализациях ИНС сигнал на соединении между искусственными нейронами представляет собой настоящий номер, и выходной сигнал каждого искусственного нейрона вычисляется некоторой нелинейной функцией суммы его входов. Связи между искусственными нейронами называются «ребрами». Искусственные нейроны и края обычно имеют масса который корректируется по мере обучения. Вес увеличивает или уменьшает силу сигнала в соединении. Искусственные нейроны могут иметь такой порог, что сигнал отправляется только в том случае, если совокупный сигнал пересекает этот порог. Обычно искусственные нейроны объединяются в слои. Разные слои могут выполнять разные виды преобразований на своих входах. Сигналы проходят от первого слоя (входной) до последнего (выходного) слоя, возможно, после многократного прохождения слоев.
Первоначальная цель подхода ИНС состояла в том, чтобы решать проблемы так же, как человеческий мозг бы. Однако со временем внимание переключилось на выполнение конкретных задач, что привело к отклонениям от биология. Искусственные нейронные сети использовались для решения множества задач, в том числе компьютерное зрение, распознавание речи, машинный перевод, социальная сеть фильтрация, играть в настольные и видеоигры и медицинский диагноз.
Глубокое обучение состоит из нескольких скрытых слоев в искусственной нейронной сети. Этот подход пытается смоделировать то, как человеческий мозг обрабатывает свет и звук в зрение и слух. Некоторые успешные применения глубокого обучения: компьютерное зрение и распознавание речи.[68]
Деревья решений
В обучении дерева решений используется Древо решений как прогнозная модель для перехода от наблюдений за предметом (представленных в ветвях) к заключениям о целевом значении предмета (представленных на листьях). Это один из подходов к прогнозному моделированию, используемых в статистике, интеллектуальном анализе данных и машинном обучении. Модели деревьев, в которых целевая переменная может принимать дискретный набор значений, называются деревьями классификации; в этих древовидных структурах, листья представляют метки классов, а ветви представляют союзы функций, которые ведут к этим меткам классов. Деревья решений, в которых целевая переменная может принимать непрерывные значения (обычно действительные числа ) называются деревьями регрессии. При анализе решений дерево решений может использоваться для визуального и явного представления решений и принимать решение. В интеллектуальном анализе данных дерево решений описывает данные, но результирующее дерево классификации может быть входом для принятия решения.
Опорные векторные машины
Машины опорных векторов (SVM), также известные как сети опорных векторов, представляют собой набор связанных контролируемое обучение методы, используемые для классификации и регрессии. Учитывая набор обучающих примеров, каждый из которых помечен как принадлежащий к одной из двух категорий, алгоритм обучения SVM строит модель, которая предсказывает, попадает ли новый пример в одну или другую категорию.[69] Алгоритм обучения SVM не являетсявероятностный, двоичный, линейный классификатор, хотя такие методы, как Масштабирование Платта существуют, чтобы использовать SVM в настройке вероятностной классификации. Помимо выполнения линейной классификации, SVM могут эффективно выполнять нелинейную классификацию, используя то, что называется трюк с ядром, неявно отображают свои входные данные в пространственные объекты большой размерности.

Регрессивный анализ
Регрессионный анализ включает в себя большое количество статистических методов для оценки взаимосвязи между входными переменными и связанными с ними характеристиками. Наиболее распространенная форма - линейная регрессия, где нарисована одна линия, которая наилучшим образом соответствует заданным данным в соответствии с математическим критерием, таким как обыкновенный метод наименьших квадратов. Последнее часто расширяется регуляризация (математика) методы для смягчения переобучения и смещения, как в регресс гребня. При решении нелинейных задач к моделям относятся: полиномиальная регрессия (например, используется для подгонки линии тренда в Microsoft Excel[70]), логистическая регрессия (часто используется в статистическая классификация ) или даже регрессия ядра, который вводит нелинейность за счет использования преимущества трюк с ядром для неявного отображения входных переменных в многомерное пространство.
Байесовские сети
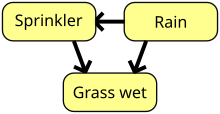
Байесовская сеть, сеть убеждений или направленная ациклическая графическая модель - это вероятностная графическая модель что представляет собой набор случайные переменные и их условная независимость с ориентированный ациклический граф (DAG). Например, байесовская сеть может представлять вероятностные отношения между болезнями и симптомами. Учитывая симптомы, сеть может использоваться для вычисления вероятности наличия различных заболеваний. Существуют эффективные алгоритмы, которые работают вывод и обучение. Байесовские сети, моделирующие последовательности переменных, например речевые сигналы или же белковые последовательности, называются динамические байесовские сети. Обобщения байесовских сетей, которые могут представлять и решать задачи принятия решений в условиях неопределенности, называются диаграммы влияния.
Генетические алгоритмы
Генетический алгоритм (ГА) - это алгоритм поиска и эвристический техника, имитирующая процесс естественный отбор, используя такие методы, как мутация и кроссовер для создания новых генотипы в надежде найти хорошие решения данной проблемы. В машинном обучении генетические алгоритмы использовались в 1980-х и 1990-х годах.[71][72] И наоборот, методы машинного обучения использовались для повышения производительности генетических и эволюционные алгоритмы.[73]
Тренировочные модели
Обычно модели машинного обучения требуют большого количества данных, чтобы они работали хорошо. Обычно при обучении модели машинного обучения необходимо собрать большую репрезентативную выборку данных из обучающей выборки. Данные из обучающего набора могут быть такими же разнообразными, как корпус текста, набор изображений и данные, собранные от отдельных пользователей службы. Переоснащение следует остерегаться при обучении модели машинного обучения. Обученные модели, полученные на основе предвзятых данных, могут приводить к искаженным или нежелательным прогнозам. Алгоритмический уклон является потенциальным результатом неполной подготовки данных для обучения.
Федеративное обучение
Федеративное обучение - это адаптированная форма распределенный искусственный интеллект для обучения моделей машинного обучения, которые децентрализует процесс обучения, позволяя сохранять конфиденциальность пользователей, не отправляя их данные на централизованный сервер. Это также повышает эффективность за счет децентрализации процесса обучения на многих устройствах. Например, Gboard использует федеративное машинное обучение для обучения моделей прогнозирования поисковых запросов на мобильных телефонах пользователей без необходимости отправлять отдельные запросы обратно на Google.[74]
Приложения
Есть много приложений для машинного обучения, в том числе:
- сельское хозяйство
- Анатомия
- Адаптивные сайты
- Аффективные вычисления
- Банковское дело
- Биоинформатика
- Интерфейсы мозг-машина
- Хеминформатика
- Гражданская наука
- Компьютерная сеть
- Компьютерное зрение
- Мошенничество с кредитными картами обнаружение
- Качество данных
- Последовательность ДНК классификация
- Экономика
- Финансовый рынок анализ[75]
- Общая игра
- Распознавание почерка
- Поиск информации
- Страхование
- Интернет-мошенничество обнаружение
- Лингвистика
- Управление машинным обучением
- Машинное восприятие
- Машинный перевод
- Маркетинг
- Медицинский диагноз
- Обработка естественного языка
- Понимание естественного языка
- Он-лайн реклама
- Оптимизация
- Рекомендательные системы
- Передвижение робота
- Поисковые системы
- Анализ настроений
- Последовательный майнинг
- Программная инженерия
- Распознавание речи
- Структурный мониторинг здоровья
- Распознавание синтаксических образов
- Телекоммуникации
- Доказательство теорем
- Прогнозирование временных рядов
- Аналитика поведения пользователей
В 2006 году провайдер медиа-услуг Netflix провел первый "Приз Netflix "соревнование по поиску программы, которая лучше прогнозирует предпочтения пользователей и повышает точность существующего алгоритма рекомендаций фильмов Cinematch как минимум на 10%. Совместная команда, состоящая из исследователей из AT&T Labs -Исследования в сотрудничестве с командами Big Chaos и Pragmatic Theory создали ансамблевая модель выиграть Гран-при в 2009 году на сумму 1 миллион долларов.[76] Вскоре после присуждения приза Netflix осознал, что рейтинги зрителей не являются лучшими показателями их моделей просмотра («все является рекомендацией»), и соответствующим образом изменили свой механизм рекомендаций.[77] В 2010 году The Wall Street Journal писала о компании Rebellion Research и их использовании машинного обучения для прогнозирования финансового кризиса.[78] В 2012 году соучредитель Sun Microsystems, Винод Хосла, предсказал, что 80% рабочих мест врачей будет потеряно в следующие два десятилетия из-за автоматизированного программного обеспечения для медицинской диагностики с машинным обучением.[79] В 2014 году сообщалось, что алгоритм машинного обучения был применен в области истории искусства для изучения картин изобразительного искусства и что он, возможно, выявил ранее неизвестное влияние на художников.[80] В 2019 г. Springer Nature опубликовал первую исследовательскую книгу, созданную с помощью машинного обучения.[81]
Мобильные приложения на основе машинного обучения:
Мобильные приложения, основанные на машинном обучении, меняют и влияют на многие аспекты нашей жизни.
- Архитектура приложений
- Облачный вывод без обучения [84] Мобильное приложение отправляет запрос в облако через интерфейс прикладного программирования (API) вместе с новыми данными, и служба возвращает прогноз.
- И логический вывод, и обучение в облаке [85]
- Логический вывод на устройстве с предварительно обученными моделями [86]
- И вывод, и обучение на устройстве
- Гибридная архитектура
Ограничения
Хотя машинное обучение способствовало преобразованию в некоторых областях, программы машинного обучения часто не дают ожидаемых результатов.[87][88][89] Причин тому множество: отсутствие (подходящих) данных, отсутствие доступа к данным, предвзятость данных, проблемы с конфиденциальностью, плохо выбранные задачи и алгоритмы, неправильные инструменты и люди, нехватка ресурсов и проблемы с оценкой.[90]
В 2018 году беспилотный автомобиль от Убер Не удалось обнаружить пешехода, погибшего в результате столкновения.[91] Попытки использовать машинное обучение в здравоохранении с IBM Watson Система не сработала даже после многих лет и миллиардов вложенных долларов.[92][93]
Предвзятость
В частности, подходы к машинному обучению могут страдать от различных искажений данных. Система машинного обучения, обученная только текущим клиентам, может быть не в состоянии предсказать потребности новых групп клиентов, которые не представлены в данных обучения. При обучении на данных, созданных человеком, машинное обучение, вероятно, улавливает те же конституционные и бессознательные предубеждения, которые уже присутствуют в обществе.[94] Было показано, что языковые модели, полученные на основе данных, содержат человеческие предубеждения.[95][96] Было обнаружено, что системы машинного обучения, используемые для оценки криминального риска, предвзято относятся к чернокожим.[97][98] В 2015 году на фотографиях Google чернокожих людей часто называли гориллами,[99] и в 2018 году эта проблема все еще не была решена, но, как сообщается, Google все еще использовал обходной путь для удаления всех горилл из данных обучения и, таким образом, вообще не мог распознать настоящих горилл.[100] Подобные проблемы с распознаванием небелых людей были обнаружены во многих других системах.[101] В 2016 году Microsoft протестировала чат-бот который узнал из Twitter, и он быстро приобрел расистские и сексистские выражения.[102] Из-за таких проблем эффективное использование машинного обучения может занять больше времени, чтобы внедрить его в других областях.[103] Забота о справедливость в машинном обучении, то есть снижение предвзятости в машинном обучении и продвижение его использования на благо человека все чаще выражается учеными, занимающимися искусственным интеллектом, в том числе Фэй-Фэй Ли, который напоминает инженерам: «В ИИ нет ничего искусственного ... Он вдохновлен людьми, он создан людьми и, что наиболее важно, влияет на людей. Это мощный инструмент, который мы только начинаем понимать, и это глубокая ответственность ».[104]
Оценка модели
Классификация моделей машинного обучения может быть подтверждена такими методами оценки точности, как противник , который разделяет данные на обучающий и тестовый набор (обычно 2/3 обучающего набора и 1/3 обозначение набора тестов) и оценивает производительность обучающей модели на тестовом наборе. Для сравнения, K-кратный-перекрестная проверка Метод случайным образом разбивает данные на K подмножеств, а затем выполняется K экспериментов, каждый, соответственно, рассматривает 1 подмножество для оценки и оставшиеся K-1 подмножества для обучения модели. В дополнение к методам удержания и перекрестной проверки, бутстрап, который выбирает n экземпляров с заменой из набора данных, можно использовать для оценки точности модели.[105]
Помимо общей точности, следователи часто сообщают чувствительность и специфичность означает истинно положительную ставку (TPR) и истинно отрицательную ставку (TNR) соответственно. Точно так же следователи иногда сообщают о ложноположительный рейтинг (FPR), а также ложноотрицательная ставка (ФНР). Однако эти коэффициенты представляют собой коэффициенты, которые не раскрывают своих числителей и знаменателей. В общая рабочая характеристика (TOC) - эффективный метод выражения диагностических возможностей модели. TOC показывает числители и знаменатели ранее упомянутых ставок, таким образом, TOC предоставляет больше информации, чем обычно используемые рабочая характеристика приемника (ROC) и связанная с ROC площадь под кривой (AUC).[106]
Этика
Машинное обучение создает множество этические вопросы. Системы, которые обучены на наборах данных, собранных с ошибками, могут демонстрировать эти смещения при использовании (алгоритмический уклон ), оцифровывая культурные предрассудки.[107] Например, использование данных о найме на работу в фирме с расистской политикой приема на работу может привести к тому, что система машинного обучения будет дублировать предвзятость, сравнивая кандидатов на работу с аналогичностью с предыдущими успешными кандидатами.[108][109] Ответственный сбор данных Таким образом, документирование алгоритмических правил, используемых системой, является важной частью машинного обучения.
Развитие систем искусственного интеллекта вызывает множество вопросов в области этики и морали. ИИ может быть хорошо оснащен для принятия решений в определенных областях, таких как научные и технические, которые в значительной степени полагаются на данные и историческую информацию. Эти решения основаны на объективности и логической аргументации.[110] Поскольку человеческие языки содержат предубеждения, машины обучены языку корпус обязательно также узнает об этих предубеждениях.[111][112]
Другие формы этических проблем, не связанные с личными предубеждениями, чаще встречаются в сфере здравоохранения. Специалисты в области здравоохранения опасаются, что эти системы могут быть разработаны не в интересах общества, а как машины, приносящие доход. Это особенно верно в Соединенных Штатах, где существует давняя этическая дилемма улучшения здравоохранения, но также и увеличения прибыли. Например, алгоритмы могут быть разработаны для предоставления пациентам ненужных тестов или лекарств, доли в которых принадлежат владельцам алгоритмов. Машинное обучение в здравоохранении обладает огромным потенциалом, чтобы предоставить профессионалам отличный инструмент для диагностики, лечения и даже планирования путей выздоровления для пациентов, но этого не произойдет, пока личные предубеждения, упомянутые ранее, и эти предубеждения "жадности" не будут устранены.[113]
Аппаратное обеспечение
С 2010-х годов достижения как в алгоритмах машинного обучения, так и в компьютерном оборудовании привели к появлению более эффективных методов обучения глубоких нейронных сетей (особая узкая подобласть машинного обучения), которые содержат множество слоев нелинейных скрытых единиц.[114] К 2019 году графические процессоры (GPU ), часто с улучшениями, специфичными для ИИ, вытеснили ЦП как доминирующий метод обучения крупномасштабного коммерческого облачного ИИ.[115] OpenAI оценили объем аппаратных вычислений, используемых в крупнейших проектах глубокого обучения от AlexNet (2012 г.) до AlphaZero (2017 г.), и обнаружил, что объем требуемых вычислений увеличился в 300 000 раз, а график тренда времени удвоения составляет 3,4 месяца.[116][117]
Программного обеспечения
Программные комплексы содержащие различные алгоритмы машинного обучения, включают следующее:
Бесплатное программное обеспечение с открытым исходным кодом
Проприетарное программное обеспечение с бесплатными версиями и версиями с открытым исходным кодом
Проприетарное программное обеспечение
- Машинное обучение Amazon
- Angoss ЗнаниеСТУДИЯ
- Машинное обучение Azure
- Аясди
- IBM Watson Studio
- Google Prediction API
- IBM SPSS Modeler
- KXEN Modeler
- LIONsolver
- Mathematica
- MATLAB
- Нейронный дизайнер
- NeuroSolutions
- Oracle Data Mining
- Облачная служба Oracle AI Platform
- RCASE
- SAS Enterprise Майнер
- SequenceL
- Splunk
- СТАТИСТИКА Майнер данных
Журналы
- Журнал исследований в области машинного обучения
- Машинное обучение
- Природа Машинный интеллект
- Нейронные вычисления
Конференции
- Ассоциация компьютерной лингвистики (ACL)
- Европейская конференция по машинному обучению и принципам и практике обнаружения знаний в базах данных (ECML PKDD)
- Международная конференция по машинному обучению (ICML)
- Международная конференция по обучающим представительствам (ICLR)
- Международная конференция по интеллектуальным роботам и системам (IROS)
- Конференция по открытию знаний и интеллектуальному анализу данных (KDD)
- Конференция по нейронным системам обработки информации (NeurIPS)
Смотрите также
- Автоматизированное машинное обучение - Автоматизированное машинное обучение или AutoML - это процесс автоматизации сквозного процесса машинного обучения.
- Большое количество данных - Информационные активы, характеризующиеся таким большим объемом, скоростью и разнообразием, что требуют определенных технологий и аналитических методов для их преобразования в ценность
- Список важных публикаций по машинному обучению
- Список наборов данных для исследования машинного обучения
Рекомендации
- ^ Митчелл, Том (1997). Машинное обучение. Нью-Йорк: Макгроу Хилл. ISBN 0-07-042807-7. OCLC 36417892.
- ^ Определение «без явного программирования» часто приписывают Артур Сэмюэл, который ввел термин "машинное обучение" в 1959 г., но эта фраза не встречается дословно в этой публикации и может быть парафраз что появилось позже. Confer "Перефразируя Артура Сэмюэля (1959), возникает вопрос: как компьютеры могут научиться решать проблемы, не будучи явно запрограммированными?" в Коза, Джон Р .; Bennett, Forrest H .; Андре, Дэвид; Кин, Мартин А. (1996). Автоматизированное проектирование топологии и размера аналоговых электрических цепей с использованием генетического программирования. Искусственный интеллект в дизайне-96. Спрингер, Дордрехт. С. 151–170. Дои:10.1007/978-94-009-0279-4_9.
- ^ а б c Бишоп, К.М. (2006), Распознавание образов и машинное обучение, Спрингер, ISBN 978-0-387-31073-2
- ^ Машинное обучение и распознавание образов «можно рассматривать как две стороны одной области».[3]:vii
- ^ Фридман, Джером Х. (1998). «Интеллектуальный анализ данных и статистика: какая связь?». Вычислительная техника и статистика. 29 (1): 3–9.
- ^ а б c Этхем Алпайдин (2020). Введение в машинное обучение (Четвертое изд.). Массачусетский технологический институт. С. xix, 1–3, 13–18. ISBN 978-0262043793.
- ^ Павел Браздил, Кристоф Жиро Каррие, Карлос Соареш, Рикардо Вилалта (2009). Metalearning: приложения для интеллектуального анализа данных (Четвертое изд.). Springer Science + Business Media. стр. 10–14, пассим. ISBN 978-3540732624.CS1 maint: использует параметр авторов (связь)
- ^ Самуэль, Артур (1959). «Некоторые исследования машинного обучения с использованием игры в шашки». Журнал исследований и разработок IBM. 3 (3): 210–229. CiteSeerX 10.1.1.368.2254. Дои:10.1147 / rd.33.0210.
- ^ Р. Кохави и Ф. Провост, "Словарь терминов", Машинное обучение, т. 30, нет. 2–3, с. 271–274, 1998.
- ^ Нильссон Н. Обучающие машины, McGraw Hill, 1965.
- ^ Дуда Р., Харт П. Распознавание образов и анализ сцены, Wiley Interscience, 1973
- ^ С. Бозиновски "Учебное пространство: концепция представления для классификации адаптивных образов" Технический отчет COINS № 81-28, Департамент компьютерных и информационных наук, Массачусетский университет в Амхерсте, Массачусетс, 1981. https://web.cs.umass.edu/publication/docs/1981/UM-CS-1981-028.pdf
- ^ а б Митчелл, Т. (1997). Машинное обучение. Макгроу Хилл. п. 2. ISBN 978-0-07-042807-2.
- ^ Харнад, Стеван (2008), "Игра с аннотациями: о Тьюринге (1950) о вычислениях, машинах и интеллекте", в Эпштейне, Роберт; Питерс, Грейс (ред.), Справочник по тесту Тьюринга: философские и методологические вопросы в поисках мыслящего компьютера, Kluwer, стр. 23–66, ISBN 9781402067082
- ^ "ЭМПИРИЧЕСКОЕ НАУЧНОЕ ИССЛЕДОВАНИЕ БИОИНФОРМАТИКИ В МАШИННОМ ОБУЧЕНИИ - Журнал". Получено 28 октября 2020. Цитировать журнал требует
| журнал =(помощь) - ^ "rasbt / stat453-deep-learning-ss20" (PDF). GitHub.
- ^ Сарл, Уоррен (1994). «Нейронные сети и статистические модели». CiteSeerX 10.1.1.27.699.
- ^ а б c d Рассел, Стюарт; Норвиг, Питер (2003) [1995]. Искусственный интеллект: современный подход (2-е изд.). Прентис Холл. ISBN 978-0137903955.
- ^ а б Лэнгли, Пэт (2011). «Меняющаяся наука о машинном обучении». Машинное обучение. 82 (3): 275–279. Дои:10.1007 / s10994-011-5242-у.
- ^ Гарбаде, доктор Майкл Дж. (14 сентября 2018 г.). «Устранение путаницы: ИИ против машинного обучения против различий в глубоком обучении». Середина. Получено 28 октября 2020.
- ^ «ИИ против машинного обучения против глубокого обучения против нейронных сетей: в чем разница?». www.ibm.com. Получено 28 октября 2020.
- ^ "ЭМПИРИЧЕСКОЕ НАУЧНОЕ ИССЛЕДОВАНИЕ БИОИНФОРМАТИКИ В МАШИННОМ ОБУЧЕНИИ - Журнал". Получено 28 октября 2020. Цитировать журнал требует
| журнал =(помощь) - ^ «Глава 1: Введение в машинное обучение и глубокое обучение». Д-р Себастьян Рашка. 5 августа 2020. Получено 28 октября 2020.
- ^ Август 2011 г., Dovel Technologies in (15 мая 2018 г.). «Не все машинное обучение - это искусственный интеллект». CTOvision.com. Получено 28 октября 2020.
- ^ «Подкаст AI Today № 30: Интервью с профессором Массачусетского технологического института Луисом Перес-Бревой - противоположные взгляды на ИИ и машинное обучение». Cognilytica. 28 марта 2018 г.. Получено 28 октября 2020.
- ^ "rasbt / stat453-deep-learning-ss20" (PDF). GitHub. Получено 28 октября 2020.
- ^ Перл, Иудея; Маккензи, Дана. Книга почему: новая наука о причине и следствии (Ред., 2018). Основные книги. ISBN 9780465097609. Получено 28 октября 2020.
- ^ Пул, Макворт и Гебель, 1998 г., п. 1.
- ^ Рассел и Норвиг, 2003 г., п. 55.
- ^ Определение ИИ как исследования интеллектуальные агенты: * Пул, Макворт и Гебель (1998), который предоставляет версию, используемую в этой статье. Эти авторы используют термин «вычислительный интеллект» как синоним искусственного интеллекта.[28] * Рассел и Норвиг (2003) (которые предпочитают термин «рациональный агент») и пишут: «В настоящее время в этой области широко применяется взгляд на весь агент».[29] * Нильссон 1998 * Легг и Хаттер 2007
- ^ Ле Ру, Николя; Бенхио, Йошуа; Фитцгиббон, Эндрю (2012). «Улучшение + методов + первого + и + + второго порядка + путем + моделирования + неопределенности & pg = PA403« Улучшение методов + первого и второго порядка + путем моделирования неопределенности ». В Шри, Суврит; Новозин, Себастьян; Райт, Стивен Дж. (Ред.). Оптимизация для машинного обучения. MIT Press. п. 404. ISBN 9780262016469.
- ^ Бздок, Данило; Альтман, Наоми; Кшивинский, Мартин (2018). «Статистика против машинного обучения». Методы природы. 15 (4): 233–234. Дои:10.1038 / nmeth.4642. ЧВК 6082636. PMID 30100822.
- ^ а б Майкл И. Джордан (2014-09-10). «статистика и машинное обучение». Reddit. Получено 2014-10-01.
- ^ Библиотека Корнельского университета. «Брейман: Статистическое моделирование: две культуры (с комментариями и репликой автора)». Получено 8 августа 2015.
- ^ Гарет Джеймс; Даниэла Виттен; Тревор Хасти; Роберт Тибширани (2013). Введение в статистическое обучение. Springer. п. vii.
- ^ Мохри, Мехриар; Ростамизаде, Афшин; Талвалкар, Амит (2012). Основы машинного обучения. США, Массачусетс: MIT Press. ISBN 9780262018258.
- ^ Алпайдин, Этхем (2010). Введение в машинное обучение. Лондон: MIT Press. ISBN 978-0-262-01243-0. Получено 4 февраля 2017.
- ^ Рассел, Стюарт Дж .; Норвиг, Питер (2010). Искусственный интеллект: современный подход (Третье изд.). Прентис Холл. ISBN 9780136042594.
- ^ Мохри, Мехриар; Ростамизаде, Афшин; Талвалкар, Амит (2012). Основы машинного обучения. MIT Press. ISBN 9780262018258.
- ^ Алпайдин, Этхем (2010). Введение в машинное обучение. MIT Press. п. 9. ISBN 978-0-262-01243-0.
- ^ Джордан, Майкл I .; Епископ, Кристофер М. (2004). "Нейронные сети". В Аллен Б. Такер (ред.). Справочник по информатике, второе издание (раздел VII: Интеллектуальные системы). Бока-Ратон, Флорида: Chapman & Hall / CRC Press LLC. ISBN 978-1-58488-360-9.
- ^ Алекс Ратнер; Стивен Бах; Парома Варма; Крис. «Слабое наблюдение: новая парадигма программирования для машинного обучения». hazyresearch.github.io. ссылаясь на работы многих других членов Hazy Research. Получено 2019-06-06.
- ^ ван Оттерло, М .; Виринг, М. (2012). Обучение с подкреплением и марковские процессы принятия решений. Обучение с подкреплением. Адаптация, обучение и оптимизация. 12. С. 3–42. Дои:10.1007/978-3-642-27645-3_1. ISBN 978-3-642-27644-6.
- ^ Божиновский, С. (1982). «Самообучающаяся система с использованием вторичного подкрепления». В Trappl, Роберт (ред.). Кибернетика и системные исследования: материалы шестого европейского совещания по кибернетике и системным исследованиям. Северная Голландия. С. 397–402. ISBN 978-0-444-86488-8.
- ^ Божиновски, Стево (2014) «Моделирование механизмов когнитивно-эмоционального взаимодействия в искусственных нейронных сетях с 1981 года». Процедуры информатики с. 255-263
- ^ Bozinovski, S. (2001) "Самообучающиеся агенты: коннекционистская теория эмоций, основанная на перекрестных оценочных суждениях". Кибернетика и системы 32 (6) 637-667.
- ^ Y. Bengio; А. Курвиль; П. Винсент (2013). «Репрезентативное обучение: обзор и новые перспективы». IEEE Transactions по анализу шаблонов и машинному анализу. 35 (8): 1798–1828. arXiv:1206.5538. Дои:10.1109 / тпами.2013.50. PMID 23787338. S2CID 393948.
- ^ Натан Сребро; Джейсон Д. М. Ренни; Томми С. Яаккола (2004). Факторизация матрицы максимальной маржи. НИПС.
- ^ Коутс, Адам; Ли, Хонглак; Нг, Эндрю Ю. (2011). Анализ однослойных сетей при неконтролируемом обучении функций (PDF). Междунар. Конф. по искусственному интеллекту и статистике (AISTATS). Архивировано из оригинал (PDF) на 2017-08-13. Получено 2018-11-25.
- ^ Чурка, Габриэлла; Танец, Кристофер С .; Fan, Lixin; Вилламовски, Ютта; Брей, Седрик (2004). Визуальная категоризация с помощью наборов ключевых точек (PDF). Семинар ECCV по статистическому обучению в компьютерном зрении.
- ^ Даниэль Джурафски; Джеймс Х. Мартин (2009). Обработка речи и языка. Pearson Education International. С. 145–146.
- ^ Лу, Хайпин; Plataniotis, K.N .; Венецанопулос, А. (2011). "Обзор мультилинейного обучения подпространству тензорных данных" (PDF). Распознавание образов. 44 (7): 1540–1551. Дои:10.1016 / j.patcog.2011.01.004.
- ^ Йошуа Бенжио (2009). Изучение глубоких архитектур для ИИ. Теперь Publishers Inc., стр. 1–3. ISBN 978-1-60198-294-0.
- ^ Тилльманн, А. М. (2015). «О вычислительной неразрешимости точного и приближенного изучения словаря». Письма об обработке сигналов IEEE. 22 (1): 45–49. arXiv:1405.6664. Bibcode:2015ISPL ... 22 ... 45 т. Дои:10.1109 / LSP.2014.2345761. S2CID 13342762.
- ^ Аарон, М., М. Элад и А. Брукштейн. 2006. "K-SVD: алгоритм разработки переполненных словарей для разреженного представления. "Обработка сигналов, транзакции IEEE на 54 (11): 4311–4322
- ^ Зимек, Артур; Шуберт, Эрих (2017), «Обнаружение выбросов», Энциклопедия систем баз данных, Springer New York, стр. 1–5, Дои:10.1007/978-1-4899-7993-3_80719-1, ISBN 9781489979933
- ^ Hodge, V.J .; Остин, Дж. (2004). «Обзор методологий обнаружения выбросов» (PDF). Обзор искусственного интеллекта. 22 (2): 85–126. CiteSeerX 10.1.1.318.4023. Дои:10.1007 / s10462-004-4304-y. S2CID 59941878.
- ^ Докас, Пол; Эртоз, Левент; Кумар, Випин; Лазаревич, Александар; Шривастава, Джайдип; Тан, Пан-Нин (2002). «Интеллектуальный анализ данных для обнаружения сетевых вторжений» (PDF). Труды Семинар NSF по интеллектуальному анализу данных следующего поколения.
- ^ Chandola, V .; Banerjee, A .; Кумар, В. (2009). «Обнаружение аномалий: исследование». Опросы ACM Computing. 41 (3): 1–58. Дои:10.1145/1541880.1541882. S2CID 207172599.
- ^ Пятецкий-Шапиро, Григорий (1991), Открытие, анализ и представление строгих правил, в Пятецкий-Шапиро Григорий; и Фроули, Уильям Дж .; ред., Открытие знаний в базах данных, AAAI / MIT Press, Кембридж, Массачусетс.
- ^ Бассель, Джордж В .; Глааб, Энрико; Маркес, Джульетта; Холдсворт, Майкл Дж .; Бакардит, Жауме (01.09.2011). «Функциональное построение сети в Arabidopsis с использованием машинного обучения на основе правил на крупномасштабных наборах данных». Растительная клетка. 23 (9): 3101–3116. Дои:10.1105 / tpc.111.088153. ISSN 1532–298X. ЧВК 3203449. PMID 21896882.
- ^ Agrawal, R .; Имелински, Т .; Свами, А. (1993). «Правила ассоциации интеллектуального анализа данных между наборами элементов в больших базах данных». Материалы международной конференции ACM SIGMOD 1993 года по управлению данными - SIGMOD '93. п. 207. CiteSeerX 10.1.1.40.6984. Дои:10.1145/170035.170072. ISBN 978-0897915922. S2CID 490415.
- ^ Урбанович, Райан Дж .; Мур, Джейсон Х. (22 сентября 2009 г.). «Обучающие системы классификаторов: полное введение, обзор и план действий». Журнал искусственной эволюции и приложений. 2009: 1–25. Дои:10.1155/2009/736398. ISSN 1687-6229.
- ^ Плоткин Г.Д. Автоматические методы индуктивного вывода Кандидатская диссертация, Эдинбургский университет, 1970.
- ^ Шапиро, Эхуд Ю. Индуктивный вывод теорий из фактов, Отчет об исследовании 192, Йельский университет, факультет компьютерных наук, 1981. Перепечатано в J.-L. Лассез, Г. Плоткин (ред.), Computational Logic, MIT Press, Кембридж, Массачусетс, 1991, стр. 199–254.
- ^ Шапиро, Эхуд Ю. (1983). Отладка алгоритмической программы. Кембридж, Массачусетс: MIT Press. ISBN 0-262-19218-7
- ^ Шапиро, Эхуд Ю. "Система вывода модели. »Труды 7-й международной совместной конференции по искусственному интеллекту - Том 2. Morgan Kaufmann Publishers Inc., 1981.
- ^ Хонглак Ли, Роджер Гроссе, Раджеш Ранганатх, Эндрю Й. Нг. "Сверточные сети глубокого убеждения для масштабируемого неконтролируемого обучения иерархическим представлениям "Материалы 26-й ежегодной международной конференции по машинному обучению, 2009 г.
- ^ Кортес, Коринна; Вапник, Владимир Н. (1995). «Поддержка-вектор сети». Машинное обучение. 20 (3): 273–297. Дои:10.1007 / BF00994018.
- ^ Стивенсон, Кристофер. «Учебное пособие: полиномиальная регрессия в Excel». facultystaff.richmond.edu. Получено 22 января 2017.
- ^ Голдберг, Дэвид Э .; Голландия, Джон Х. (1988). «Генетические алгоритмы и машинное обучение» (PDF). Машинное обучение. 3 (2): 95–99. Дои:10.1007 / bf00113892. S2CID 35506513.
- ^ Michie, D .; Spiegelhalter, D. J .; Тейлор, К. С. (1994). «Машинное обучение, нейронная и статистическая классификация». Серия Эллиса Хорвуда по искусственному интеллекту. Bibcode:1994млн.книга ..... М.
- ^ Чжан, Цзюнь; Чжань, Чжи-хуэй; Линь, Инь; Чен, Ни; Гун, Юэ-цзяо; Чжун, Цзин-хуэй; Чанг, Генри С.Х .; Ли, Юнь; Ши, Ю-хуэй (2011). «Эволюционные вычисления и машинное обучение: обзор». Журнал Computational Intelligence Magazine. 6 (4): 68–75. Дои:10.1109 / mci.2011.942584. S2CID 6760276.
- ^ «Федеративное обучение: совместное машинное обучение без централизованных данных обучения». Блог Google AI. Получено 2019-06-08.
- ^ Машинное обучение включено в Учебная программа CFA (обсуждение идет сверху вниз); видеть: Кэтлин ДеРоуз и Кристоф Ле Ланно (2020). "Машинное обучение".
- ^ «Домашняя страница БелКор» research.att.com
- ^ "Технический блог Netflix: Рекомендации Netflix: за пределами пяти звезд (часть 1)". 2012-04-06. Архивировано из оригинал 31 мая 2016 г.. Получено 8 августа 2015.
- ^ Скотт Паттерсон (13 июля 2010 г.). "Предоставление машинам решения". Журнал "Уолл Стрит. Получено 24 июн 2018.
- ^ Винод Хосла (10 января 2012 г.). «Нужны ли нам врачи или алгоритмы?». Tech Crunch.
- ^ Когда алгоритм машинного обучения изучал картины изобразительного искусства, он видел то, чего историки искусства никогда не замечали, Физика в ArXiv блог
- ^ Винсент, Джеймс (2019-04-10). «Первый учебник, созданный с помощью искусственного интеллекта, показывает, в чем на самом деле хороши писатели-роботы». Грани. Получено 2019-05-05.
- ^ Ли, Давэй; Ван, Сяолун; Конг, Дегуан (10 января 2018 г.). «DeepRebirth: ускорение работы глубокой нейронной сети на мобильных устройствах». arXiv: 1708.04728 [cs].
- ^ Ховард, Эндрю Дж .; Чжу, Менглонг; Чен, Бо; Калениченко, Дмитрий; Ван, Вэйцзюнь; Вейанд, Тобиас; Андреетто, Марко; Адам, Хартвиг (2017-04-16). «Мобильные сети: эффективные сверточные нейронные сети для приложений мобильного зрения». arXiv: 1704.04861 [cs].
- ^ "Cloud Inference Api | Cloud Inference API". Google Cloud. Получено 2020-11-24.
- ^ Чун, Бюнг-Гон; Им, Сунгван; Маниатис, Петрос; Найк, Маюр; Патти, Эшвин (2011-04-10). «CloneCloud: эластичное исполнение между мобильным устройством и облаком». Материалы шестой конференции по компьютерным системам.. EuroSys '11. Зальцбург, Австрия: Ассоциация вычислительной техники: 301–314. Дои:10.1145/1966445.1966473. ISBN 978-1-4503-0634-8.
- ^ Дай, Сянфэн; Спасич, Ирена; Мейер, Брэдли; Чапмен, Сэмюэл; Андрес, Фредерик (2019-06-01). "Машинное обучение на мобильных устройствах: приложение для диагностики рака кожи на устройстве". 2019 Четвертая международная конференция по туманным и мобильным периферийным вычислениям (FMEC). Рим, Италия: IEEE: 301–305. Дои:10.1109 / FMEC.2019.8795362. ISBN 978-1-7281-1796-6.
- ^ «Почему модели машинного обучения часто не обучаются: вопросы и ответы QuickTake». Bloomberg.com. 2016-11-10. Архивировано из оригинал на 2017-03-20. Получено 2017-04-10.
- ^ «Первая волна корпоративного ИИ обречена на провал». Harvard Business Review. 2017-04-18. Получено 2018-08-20.
- ^ «Почему эйфория ИИ обречена на провал». VentureBeat. 2016-09-18. Получено 2018-08-20.
- ^ «9 причин, по которым ваш проект машинного обучения провалится». www.kdnuggets.com. Получено 2018-08-20.
- ^ «Почему беспилотный автомобиль Uber убил пешехода». Экономист. Получено 2018-08-20.
- ^ «IBM Watson рекомендовал« небезопасные и неправильные »методы лечения рака - STAT». СТАТ. 2018-07-25. Получено 2018-08-21.
- ^ Эрнандес, Даниэла; Гринвальд, Тед (11.08.2018). «У IBM есть дилемма Ватсона». Wall Street Journal. ISSN 0099-9660. Получено 2018-08-21.
- ^ Гарсия, Меган (2016). «Расист в машине». Журнал мировой политики. 33 (4): 111–117. Дои:10.1215/07402775-3813015. ISSN 0740-2775. S2CID 151595343.
- ^ Калискан, Айлин; Брайсон, Джоанна Дж .; Нараянан, Арвинд (14 апреля 2017 г.). «Семантика, полученная автоматически из языковых корпусов, содержит человеческие предубеждения». Наука. 356 (6334): 183–186. arXiv:1608.07187. Bibcode:2017Наука ... 356..183C. Дои:10.1126 / science.aal4230. ISSN 0036-8075. PMID 28408601. S2CID 23163324.
- ^ Ван, Синань; Дасгупта, Санджой (2016), Ли, Д.Д .; Sugiyama, M .; Люксбург, Вашингтон; Гийон, И. (ред.), «Алгоритм поиска ближайшего соседа L1 посредством монотонного вложения» (PDF), Достижения в системах обработки нейронной информации 29, Curran Associates, Inc., стр. 983–991., получено 2018-08-20
- ^ Джулия Ангвин; Джефф Ларсон; Лорен Киршнер; Сурья Матту (23 мая 2016 г.). "Машинное смещение". ProPublica. Получено 2018-08-20.
- ^ «Мнение | Когда алгоритм помогает отправить вас в тюрьму». Нью-Йорк Таймс. Получено 2018-08-20.
- ^ "Google приносит свои извинения за расистскую ошибку". Новости BBC. 2015-07-01. Получено 2018-08-20.
- ^ «Google« исправил »расистский алгоритм, убрав горилл из своей технологии маркировки изображений». Грани. Получено 2018-08-20.
- ^ "Мнение | Проблема белого парня искусственного интеллекта". Нью-Йорк Таймс. Получено 2018-08-20.
- ^ Мец, Рэйчел. «Почему Тэй, подростковый чат-бот Microsoft, наговорил много ужасных вещей в Интернете». Обзор технологий MIT. Получено 2018-08-20.
- ^ Симонит, Том. «Microsoft утверждает, что ее расистский чат-бот показывает, что ИИ недостаточно адаптируется, чтобы помочь большинству предприятий». Обзор технологий MIT. Получено 2018-08-20.
- ^ Хемпель, Джесси (13.11.2018). «Стремление Фэй-Фэй Ли сделать машины лучше для человечества». Проводной. ISSN 1059-1028. Получено 2019-02-17.
- ^ Кохави, Рон (1995). «Исследование перекрестной проверки и начальной загрузки для оценки точности и выбора модели» (PDF). Международная совместная конференция по искусственному интеллекту.
- ^ Понтиус, Роберт Гилмор; Си, Канпин (2014). «Общая рабочая характеристика для измерения диагностической способности для нескольких пороговых значений». Международный журнал географической информатики. 28 (3): 570–583. Дои:10.1080/13658816.2013.862623. S2CID 29204880.
- ^ Бостром, Ник (2011). «Этика искусственного интеллекта» (PDF). Архивировано из оригинал (PDF) 4 марта 2016 г.. Получено 11 апреля 2016.
- ^ Эдионве, Толулоп. «Борьба с расистскими алгоритмами». Схема. Получено 17 ноября 2017.
- ^ Джеффрис, Адрианна. «Машинное обучение - расизм, потому что расизм в Интернете». Схема. Получено 17 ноября 2017.
- ^ Бостром, Ник; Юдковский, Элиэзер (2011). «ЭТИКА ИСКУССТВЕННОГО ИНТЕЛЛЕКТА» (PDF). Ник Бостром.
- ^ M.O.R. Prates, P.H.C. Авелар, Л. Lamb (11 марта 2019 г.). «Оценка гендерных предубеждений в машинном переводе - пример использования Google Translate». arXiv:1809.02208 [cs.CY ].CS1 maint: использует параметр авторов (связь)
- ^ Нараянан, Арвинд (24 августа 2016 г.). «Язык обязательно содержит человеческие предубеждения, как и машины, обученные языковым корпусам». Свобода возиться.
- ^ Char, D. S .; Shah, N.H .; Магнус, Д. (2018). «Внедрение машинного обучения в здравоохранение - решение этических проблем». Медицинский журнал Новой Англии. 378 (11): 981–983. Дои:10.1056 / nejmp1714229. ЧВК 5962261. PMID 29539284.
- ^ Research, AI (23 октября 2015 г.). «Глубокие нейронные сети для акустического моделирования в распознавании речи». airesearch.com. Получено 23 октября 2015.
- ^ «Графические процессоры продолжают доминировать на рынке ускорителей искусственного интеллекта». Информационная неделя. Декабрь 2019 г.. Получено 11 июн 2020.
- ^ Рэй, Тирнан (2019). «ИИ меняет всю природу вычислений». ZDNet. Получено 11 июн 2020.
- ^ «ИИ и вычисления». OpenAI. 16 мая 2018. Получено 11 июн 2020.
дальнейшее чтение
- Нильс Дж. Нильссон, Введение в машинное обучение.
- Тревор Хасти, Роберт Тибширани и Джером Х. Фридман (2001). Элементы статистического обучения, Springer. ISBN 0-387-95284-5.
- Педро Домингос (Сентябрь 2015 г.), Главный алгоритм, Базовые книги, ISBN 978-0-465-06570-7
- Ян Х. Виттен и Эйбе Франк (2011). Data Mining: практические инструменты и методы машинного обучения Морган Кауфманн, 664 стр., ISBN 978-0-12-374856-0.
- Этхем Алпайдин (2004). Введение в машинное обучение, MIT Press, ISBN 978-0-262-01243-0.
- Дэвид Дж. С. Маккей. Теория информации, логический вывод и алгоритмы обучения Кембридж: Издательство Кембриджского университета, 2003. ISBN 0-521-64298-1
- Ричард О. Дуда, Питер Э. Харт, Дэвид Г. Аист (2001) Классификация паттернов (2-е издание), Уайли, Нью-Йорк, ISBN 0-471-05669-3.
- Кристофер Бишоп (1995). Нейронные сети для распознавания образов, Oxford University Press. ISBN 0-19-853864-2.
- Стюарт Рассел и Питер Норвиг, (2009). Искусственный интеллект - современный подход. Пирсон, ISBN 9789332543515.
- Рэй Соломонов, Машина индуктивного вывода, Протокол IRE Convention, Раздел по теории информации, Часть 2, стр. 56–62, 1957.
- Рэй Соломонов, Машина индуктивного вывода Распространенный в частном порядке отчет 1956 г. Дартмутская летняя исследовательская конференция по ИИ.
внешняя ссылка
- Международное общество машинного обучения
- Mloss академическая база данных программного обеспечения машинного обучения с открытым исходным кодом.
- Ускоренный курс машинного обучения к Google. Это бесплатный курс по машинному обучению с использованием TensorFlow.

Дифференцируемые вычисления | |||||||
|---|---|---|---|---|---|---|---|
| Общий |  | ||||||
| Концепции | |||||||
| Языки программирования | |||||||
| Заявление | |||||||
| Аппаратное обеспечение | |||||||
| Библиотека программного обеспечения | |||||||
| Выполнение |
| ||||||
| Люди | |||||||
| |||||||