Алгоритм ожидания – максимизации - Expectation–maximization algorithm
В статистика, ожидание – максимизация (ЭМ) алгоритм является итерационный метод найти (местный) максимальная вероятность или максимум апостериори (MAP) оценки параметры в статистические модели, где модель зависит от ненаблюдаемых скрытые переменные. Итерация EM попеременно выполняет этап ожидания (E), который создает функцию для ожидания логарифмическая вероятность оценивается с использованием текущей оценки параметров и шага максимизации (M), на котором вычисляются параметры, максимизирующие ожидаемую логарифмическую вероятность, найденную на E шаг. Эти оценки параметров затем используются для определения распределения скрытых переменных на следующем этапе E.

История
Алгоритм EM был объяснен и получил свое название в классической статье 1977 г. Артур Демпстер, Нэн Лэрд, и Дональд Рубин.[1] Они указали, что этот метод «много раз предлагался при особых обстоятельствах» более ранними авторами. Одним из первых является метод подсчета генов для оценки частот аллелей с помощью Седрик Смит.[2] Очень подробное рассмотрение метода ЭМ для экспоненциальных семейств было опубликовано Рольфом Сундбергом в его диссертации и нескольких статьях.[3][4][5] после его сотрудничества с Пер Мартин-Лёф и Андерс Мартин-Лёф.[6][7][8][9][10][11][12] Статья Демпстера – Лэрда – Рубина 1977 г. обобщила этот метод и наметила анализ сходимости для более широкого класса проблем. В статье Демпстера – Лэрда – Рубина ЭМ-метод определен как важный инструмент статистического анализа.
Анализ сходимости алгоритма Демпстера – Лэрда – Рубина был ошибочным, и правильный анализ сходимости был опубликован К. Ф. Джефф Ву в 1983 г.[13]Доказательство Ву установило сходимость ЭМ-метода вне экспоненциальная семья, как утверждает Демпстер – Лэрд – Рубин.[13]
Вступление
Алгоритм EM используется для поиска (локального) максимальная вероятность параметры статистическая модель в случаях, когда уравнения не могут быть решены напрямую. Обычно эти модели включают скрытые переменные в дополнение к неизвестному параметры и известные данные наблюдений. То есть либо недостающие значения существуют среди данных, или модель может быть сформулирована более просто, допуская существование дополнительных ненаблюдаемых точек данных. Например, модель смеси можно описать более просто, если предположить, что каждая наблюдаемая точка данных имеет соответствующую ненаблюдаемую точку данных или скрытую переменную, определяя компонент смеси, которому принадлежит каждая точка данных.
Для поиска решения с максимальной вероятностью обычно требуется производные из функция правдоподобия относительно всех неизвестных значений, параметров и скрытых переменных и одновременно решая полученные уравнения. В статистических моделях со скрытыми переменными это обычно невозможно. Вместо этого результатом обычно является набор взаимосвязанных уравнений, в которых для решения параметров требуются значения скрытых переменных и наоборот, но подстановка одного набора уравнений в другой дает неразрешимое уравнение.
Алгоритм EM исходит из наблюдения, что существует способ решить эти две системы уравнений численно. Можно просто выбрать произвольные значения для одного из двух наборов неизвестных, использовать их для оценки второго набора, затем использовать эти новые значения, чтобы найти лучшую оценку первого набора, а затем продолжать чередовать эти два, пока оба результата не получат. сходятся к неподвижным точкам. Не очевидно, что это сработает, но можно доказать, что в данном контексте это так, и что производная вероятности (произвольно близка) к нулю в этой точке, что, в свою очередь, означает, что точка является либо максимумом, либо а точка перевала.[13] В общем, могут возникать множественные максимумы без гарантии, что глобальный максимум будет найден. Некоторые вероятности также имеют особенности в них, т. е. бессмысленные максимумы. Например, один из решения то, что может быть найдено с помощью EM в смешанной модели, включает в себя установку одного из компонентов на нулевую дисперсию и параметр среднего значения для того же компонента, равный одной из точек данных.
Описание
Учитывая статистическая модель который генерирует набор наблюдаемых данных, набор скрытых ненаблюдаемых данных или недостающие значения , и вектор неизвестных параметров вместе с функция правдоподобия , то оценка максимального правдоподобия (MLE) неизвестных параметров определяется путем максимизации предельная вероятность наблюдаемых данных





Однако с этой величиной часто трудно справиться (например, если представляет собой последовательность событий, поэтому количество значений растет экспоненциально с увеличением длины последовательности, точное вычисление суммы будет чрезвычайно затруднено).
Алгоритм EM пытается найти MLE предельного правдоподобия, итеративно применяя эти два шага:
- Шаг ожидания (шаг E): Определять как ожидаемое значение журнала функция правдоподобия из , относительно текущего условное распределение из данный и текущие оценки параметров :


![{ displaystyle Q ({ boldsymbol { theta}} mid { boldsymbol { theta}} ^ {(t)}) = operatorname {E} _ { mathbf {Z} mid mathbf {X} , { boldsymbol { theta}} ^ {(t)}} left [ log L ({ boldsymbol { theta}}; mathbf {X}, mathbf {Z}) right] ,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/273a8ef209e0f8cb8b30b120a89218a8f748b9dd)
- Шаг максимизации (шаг M): Найдите параметры, которые увеличивают это количество:

Типичные модели, к которым применяется ЭМ, используют как скрытая переменная, указывающая на принадлежность к одной из множества групп:
- Наблюдаемые точки данных может быть дискретный (принимая значения в конечном или счетно бесконечном множестве) или непрерывный (принимая значения в несчетное бесконечное множество). С каждой точкой данных может быть связан вектор наблюдений.
- В недостающие значения (он же скрытые переменные ) находятся дискретный, взятые из фиксированного числа значений и с одной скрытой переменной на наблюдаемую единицу.
- Параметры являются непрерывными и бывают двух видов: параметры, связанные со всеми точками данных, и параметры, связанные с конкретным значением скрытой переменной (т.е. связанные со всеми точками данных, у которых соответствующая скрытая переменная имеет это значение).
Однако ЭМ можно применять к другим типам моделей.
Мотив таков. Если значение параметров известно, обычно значение скрытых переменных можно найти, максимизируя логарифмическую вероятность по всем возможным значениям , либо просто перебирая или с помощью такого алгоритма, как Алгоритм Баума – Велча за скрытые марковские модели. И наоборот, если мы знаем значение скрытых переменных , можно оценить параметры довольно легко, обычно путем простой группировки наблюдаемых точек данных в соответствии со значением связанной скрытой переменной и усреднения значений или некоторой функции значений точек в каждой группе. Это предполагает итерационный алгоритм в случае, когда оба и неизвестны:
- Сначала инициализируйте параметры к некоторым случайным значениям.
- Вычислите вероятность каждого возможного значения , данный .
- Затем используйте только что вычисленные значения чтобы вычислить лучшую оценку параметров .
- Повторите шаги 2 и 3 до схождения.
Алгоритм, описанный выше, монотонно приближается к локальному минимуму функции стоимости.
Характеристики
Говоря об ожидаемом шаге (E) - это что-то вроде неправильное употребление. На первом этапе вычисляются фиксированные, зависящие от данных параметры функции. Q. После того, как параметры Q известны, они полностью определены и максимизируются на втором (M) шаге алгоритма EM.
Хотя итерация EM увеличивает функцию правдоподобия наблюдаемых данных (т. Е. Предельную), нет гарантии, что последовательность сходится к оценщик максимального правдоподобия. За мультимодальные распределения, это означает, что алгоритм EM может сходиться к локальный максимум функции правдоподобия наблюдаемых данных в зависимости от начальных значений. Разнообразие эвристических или метаэвристический существуют подходы, позволяющие избежать локального максимума, такие как случайный перезапуск скалолазание (начиная с нескольких различных случайных начальных оценок θ(т)) или применяя имитация отжига методы.
EM особенно полезен, когда вероятность экспоненциальная семья: шаг E становится суммой ожиданий достаточная статистика, а шаг M включает максимизацию линейной функции. В таком случае обычно можно получить выражение в закрытой форме обновления для каждого шага, используя формулу Сундберга (опубликованную Рольфом Сундбергом с использованием неопубликованных результатов Пер Мартин-Лёф и Андерс Мартин-Лёф ).[4][5][8][9][10][11][12]
Метод EM был изменен для вычисления максимум апостериори (MAP) оценки для Байесовский вывод в оригинальной статье Демпстера, Лэрда и Рубина.
Существуют и другие методы нахождения оценок максимального правдоподобия, например градиентный спуск, сопряженный градиент, или варианты Алгоритм Гаусса – Ньютона. В отличие от EM, такие методы обычно требуют оценки первой и / или второй производной функции правдоподобия.
Доказательство правильности
Максимизация ожиданий работает на улучшение вместо прямого улучшения . Здесь показано, что улучшения первого подразумевают улучшения второго.[14]

Для любого с ненулевой вероятностью , мы можем написать


Мы ожидаем возможных значений неизвестных данных. при текущей оценке параметра умножив обе части на и суммируя (или интегрируя) по . Левая часть - это математическое ожидание константы, поэтому мы получаем:



где определяется отрицательной суммой, которую она заменяет. Последнее уравнение выполняется для любого значения в том числе ,



и вычитание этого последнего уравнения из предыдущего уравнения дает

Однако, Неравенство Гиббса говорит нам, что , поэтому мы можем заключить, что


На словах выбирая улучшить причины улучшить хотя бы на столько же.
Как процедура максимизации – максимизации
Алгоритм EM можно рассматривать как два чередующихся шага максимизации, то есть как пример координатный спуск.[15][16] Рассмотрим функцию:
![{ Displaystyle F (q, theta): = operatorname {E} _ {q} [ log L ( theta; x, Z)] + H (q),}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f4e0798985f246154015deb375e1494dfa734922)
где q - произвольное распределение вероятностей по ненаблюдаемым данным z и H (q) это энтропия распределения q. Эту функцию можно записать как

где условное распределение ненаблюдаемых данных при наблюдаемых данных и это Дивергенция Кульбака – Лейблера.



Тогда шаги в алгоритме EM можно рассматривать как:
- Шаг ожидания: Выберите максимизировать :
- Шаг максимизации: Выберите максимизировать :





Приложения
EM часто используется для оценки параметров смешанные модели,[17][18] особенно в количественная генетика.[19]
В психометрия, EM практически незаменим для оценки параметров предметов и скрытых способностей теория ответа элемента модели.
Благодаря способности работать с недостающими данными и наблюдать неопознанные переменные, EM становится полезным инструментом для определения цены и управления рисками портфеля.[нужна цитата ]
Алгоритм EM (и его более быстрый вариант Максимизация ожидания упорядоченного подмножества ) также широко используется в медицинское изображение реконструкция, особенно в позитронно-эмиссионная томография, однофотонная эмиссионная компьютерная томография, и рентген компьютерная томография. См. Ниже другие более быстрые варианты EM.
В Строительная инженерия, структурная идентификация с использованием максимизации ожиданий (STRIDE)[20] Алгоритм - это метод только для вывода для определения свойств естественной вибрации структурной системы с использованием данных датчиков (см. Оперативный модальный анализ ).
EM также часто используется для кластеризация данных, компьютерное зрение И в машинное обучение. В обработка естественного языка, два ярких примера алгоритма - это Алгоритм Баума – Велча за скрытые марковские модели, а алгоритм внутри-снаружи для неконтролируемой индукции вероятностные контекстно-свободные грамматики.
Алгоритмы фильтрации и сглаживания EM
А Фильтр Калмана обычно используется для оценки состояния в режиме онлайн, а сглаживание с минимальной дисперсией может использоваться для оценки состояния в автономном режиме или в пакетном режиме. Однако эти решения с минимальной дисперсией требуют оценок параметров модели в пространстве состояний. EM-алгоритмы могут использоваться для решения задач совместного оценивания состояния и параметров.
Алгоритмы фильтрации и сглаживания EM возникают в результате повторения этой двухэтапной процедуры:
- E-шаг
- Воспользуйтесь фильтром Калмана или сглаживателем с минимальной дисперсией, разработанным с текущими оценками параметров, чтобы получить обновленные оценки состояния.
- M-шаг
- Используйте отфильтрованные или сглаженные оценки состояния в вычислениях максимального правдоподобия для получения обновленных оценок параметров.
Предположим, что Фильтр Калмана или устройство сглаживания с минимальной дисперсией работает на измерениях системы с одним входом и одним выходом, которые обладают аддитивным белым шумом. Обновленную оценку дисперсии шума измерения можно получить из максимальная вероятность расчет

где являются скалярными выходными оценками, вычисленными фильтром или сглаживателем из N скалярных измерений . Вышеупомянутое обновление также можно применить для обновления интенсивности шума измерения Пуассона. Точно так же для авторегрессивного процесса первого порядка обновленная оценка дисперсии шума процесса может быть вычислена с помощью



где и являются скалярными оценками состояния, вычисленными фильтром или сглаживателем. Обновленная оценка коэффициента модели получается через


Сходимость оценок параметров, подобных приведенным выше, хорошо изучена.[21][22][23][24]
Варианты
Был предложен ряд методов для ускорения иногда медленной сходимости алгоритма EM, например, методы, использующие сопряженный градиент и модифицированный Методы Ньютона (Ньютон – Рафсон).[25] Кроме того, EM можно использовать с методами оценки с ограничениями.
Максимизация ожидания с расширенными параметрами (PX-EM) Алгоритм часто обеспечивает ускорение за счет «использования« ковариационной корректировки »для корректировки анализа шага M, извлекая выгоду из дополнительной информации, содержащейся в вмененных полных данных».[26]
Условная максимизация ожидания (ECM) заменяет каждый шаг M последовательностью шагов условной максимизации (CM), в которой каждый параметр θя максимизируется индивидуально, при условии, что остальные параметры остаются неизменными.[27] Сама может быть расширена в Условная максимизация ожидания либо (ECME) алгоритм.[28]
Эта идея получила дальнейшее развитие в максимизация обобщенного ожидания (GEM) алгоритм, в котором ищется только увеличение целевой функции F как для шага E, так и для шага M, как описано в Как процедура максимизации-максимизации раздел.[15] GEM продолжает развиваться в распределенной среде и показывает многообещающие результаты.[29]
Также можно рассматривать алгоритм EM как подкласс ММ Алгоритм (Majorize / Minimize или Minorize / Maximize, в зависимости от контекста),[30] поэтому используйте любую технику, разработанную в более общем случае.
алгоритм α-EM
Q-функция, используемая в алгоритме EM, основана на логарифмической вероятности. Поэтому он рассматривается как алгоритм log-EM. Использование логарифма правдоподобия может быть обобщено на использование логарифмического отношения правдоподобия. Тогда логарифмическое отношение правдоподобия наблюдаемых данных может быть точно выражено как равенство с использованием Q-функции логарифмического отношения правдоподобия и дивергенции. Получение этой Q-функции представляет собой обобщенный шаг E. Его максимизация - это обобщенный M шаг. Эта пара называется алгоритмом α-EM.[31]который содержит алгоритм log-EM в качестве подкласса.Таким образом, алгоритм α-EM по Ясуо Мацуяма является точным обобщением алгоритма log-EM. Расчет градиента или матрицы Гессе не требуется. Α-EM показывает более быструю сходимость, чем алгоритм log-EM, при выборе подходящего α. Алгоритм α-EM приводит к более быстрой версии алгоритма оценки скрытой марковской модели α-HMM.[32]
Отношение к вариационным байесовским методам
EM - это частично небайесовский метод максимального правдоподобия. Его окончательный результат дает распределение вероятностей по скрытым переменным (в байесовском стиле) вместе с точечной оценкой для θ (либо оценка максимального правдоподобия или апостериорный режим). Может потребоваться полностью байесовская версия этого, дающая распределение вероятностей по θ и скрытые переменные. Байесовский подход к умозаключениям - это просто рассматривать θ как еще одна скрытая переменная. В этой парадигме исчезает различие между ступенями E и M. Если использовать факторизованное приближение Q, как описано выше (вариационный байесовский ), решение может повторяться по каждой скрытой переменной (теперь включая θ) и оптимизируйте их по очереди. Сейчас же, k шаги на итерацию необходимы, где k - количество скрытых переменных. За графические модели это легко сделать, так как каждая новая переменная Q зависит только от его Марковское одеяло, так местный передача сообщений может использоваться для эффективного вывода.
Геометрическая интерпретация
В информационная геометрия, шаг E и шаг M интерпретируются как проекции двойственного аффинные связи, называемые электронной связью и мобильной связью; то Дивергенция Кульбака – Лейблера также можно понимать в этих терминах.
Примеры
Гауссова смесь

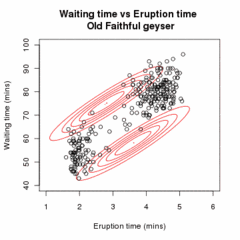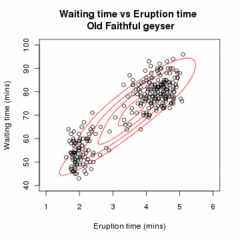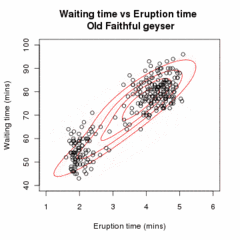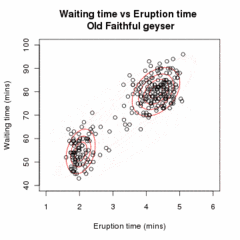
Позволять быть образцом независимые наблюдения от смесь из двух многомерные нормальные распределения измерения , и разреши быть скрытыми переменными, которые определяют компонент, из которого происходит наблюдение.[16]




- и


где
- и


Цель состоит в том, чтобы оценить неизвестные параметры, представляющие смешивание значение между гауссианами и средствами и ковариациями каждого из них:

где функция правдоподобия неполных данных

а функция правдоподобия полных данных
![{ Displaystyle L ( theta; mathbf {x}, mathbf {z}) = p ( mathbf {x}, mathbf {z} mid theta) = prod _ {i = 1} ^ { n} prod _ {j = 1} ^ {2} [f ( mathbf {x} _ {i}; { boldsymbol { mu}} _ {j}, Sigma _ {j}) tau _ {j}] ^ { mathbb {I} (z_ {i} = j)},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8992a646a56612c1c52a38302e6a84ccceeb949a)
или
![{ displaystyle L ( theta; mathbf {x}, mathbf {z}) = exp left { sum _ {i = 1} ^ {n} sum _ {j = 1} ^ {2 } mathbb {I} (z_ {i} = j) { big [} log tau _ {j} - { tfrac {1} {2}} log | Sigma _ {j} | - { tfrac {1} {2}} ( mathbf {x} _ {i} - { boldsymbol { mu}} _ {j}) ^ { top} Sigma _ {j} ^ {- 1} ( mathbf {x} _ {i} - { boldsymbol { mu}} _ {j}) - { tfrac {d} {2}} log (2 pi) { big]} right } ,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c7c30db649a3d79fca184a9ba9485609ff6ddf62)
где является индикаторная функция и это функция плотности вероятности многомерной нормали.


В последнем равенстве для каждого я, один индикатор равен нулю, а один показатель равен единице. Таким образом, внутренняя сумма сводится к одному члену.

E шаг
Учитывая нашу текущую оценку параметров θ(т), условное распределение Zя определяется Теорема Байеса быть пропорциональной высоте нормального плотность взвешенный τ:

Они называются «вероятностями членства», которые обычно считаются выходом шага E (хотя это не функция Q, описанная ниже).
Этот шаг E соответствует настройке этой функции для Q:
![{ displaystyle { begin {align} Q ( theta mid theta ^ {(t)}) & = operatorname {E} _ { mathbf {Z} mid mathbf {X}, mathbf { theta} ^ {(t)}} [ log L ( theta; mathbf {x}, mathbf {Z})] & = operatorname {E} _ { mathbf {Z} mid mathbf {X}, mathbf { theta} ^ {(t)}} [ log prod _ {i = 1} ^ {n} L ( theta; mathbf {x} _ {i}, Z_ {i })] & = operatorname {E} _ { mathbf {Z} mid mathbf {X}, mathbf { theta} ^ {(t)}} [ sum _ {i = 1} ^ {n} log L ( theta; mathbf {x} _ {i}, Z_ {i})] & = sum _ {i = 1} ^ {n} operatorname {E} _ {Z_ {i} mid mathbf {X}; mathbf { theta} ^ {(t)}} [ log L ( theta; mathbf {x} _ {i}, Z_ {i})] & = sum _ {i = 1} ^ {n} sum _ {j = 1} ^ {2} P (Z_ {i} = j mid X_ {i} = mathbf {x} _ {i} ; theta ^ {(t)}) log L ( theta _ {j}; mathbf {x} _ {i}, j) & = sum _ {i = 1} ^ {n} сумма _ {j = 1} ^ {2} T_ {j, i} ^ {(t)} { big [} log tau _ {j} - { tfrac {1} {2}} log | Sigma _ {j} | - { tfrac {1} {2}} ( mathbf {x} _ {i} - { boldsymbol { mu}} _ {j}) ^ { top} Sigma _ {j} ^ {- 1} ( mathbf {x} _ {i} - { boldsymbol { mu}} _ {j}) - { tfrac {d} {2}} log (2 pi) { big]}. end {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/831e58b66c942513ffec52fadbf7899feb7aceb2)
Ожидание внутри сумма берется относительно функции плотности вероятности , которые могут отличаться для каждого обучающего набора. Все в шаге E известно до того, как шаг будет сделан, кроме , который вычисляется в соответствии с уравнением в начале раздела шага E.




Это полное условное ожидание не нужно рассчитывать за один шаг, потому что τ и μ/Σ появляются в отдельных линейных терминах и, таким образом, могут быть максимизированы независимо.
Шаг M
Q(θ | θ(т)) квадратичная форма означает, что определение максимальных значений θ относительно просто. Также, τ, (μ1,Σ1) и (μ2,Σ2) могут быть максимизированы независимо, поскольку все они представлены в отдельных линейных терминах.
Для начала рассмотрим τ, имеющий ограничение τ1 + τ2=1:
![{ displaystyle { begin {align} { boldsymbol { tau}} ^ {(t + 1)} & = { underset { boldsymbol { tau}} { operatorname {arg , max}}} Q ( theta mid theta ^ {(t)}) & = { underset { boldsymbol { tau}} { operatorname {arg , max}}} left { left [ sum _ {i = 1} ^ {n} T_ {1, i} ^ {(t)} right] log tau _ {1} + left [ sum _ {i = 1} ^ {n} T_ {2, i} ^ {(t)} right] log tau _ {2} right }. End {выравнивается}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f3d2b6d3ae054fad990836865c545ef1d4f1fffd)
Он имеет ту же форму, что и MLE для биномиальное распределение, так

Для следующих оценок (μ1, Σ1):

Он имеет ту же форму, что и взвешенный MLE для нормального распределения, поэтому
- и


и по симметрии
- и


Прекращение
Завершите итерационный процесс, если за ниже некоторого предустановленного порога.
![{ Displaystyle E_ {Z mid theta ^ {(t)}, mathbf {x}} [ log L ( theta ^ {(t)}; mathbf {x}, mathbf {Z})] leq E_ {Z mid theta ^ {(t-1)}, mathbf {x}} [ log L ( theta ^ {(t-1)}; mathbf {x}, mathbf {Z })] + varepsilon}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1936cdfb30674d85c6029aed6c4b3e571300374b)

Обобщение
Проиллюстрированный выше алгоритм можно обобщить для смесей более двух многомерные нормальные распределения.
Усеченная и цензурированная регрессия
Алгоритм EM был реализован в случае, когда базовый линейная регрессия существует модель, объясняющая изменение некоторой величины, но фактически наблюдаемые значения являются цензурированными или усеченными версиями представленных в модели.[33] Частные случаи этой модели включают цензурированные или усеченные наблюдения из одного нормальное распределение.[33]
Альтернативы
EM обычно сходится к локальному оптимуму, не обязательно к глобальному оптимуму, без каких-либо ограничений на скорость сходимости в целом. Возможно, что он может быть сколь угодно плохим в больших размерностях и может иметь экспоненциальное число локальных оптимумов. Следовательно, существует потребность в альтернативных методах гарантированного обучения, особенно в условиях большой размерности. Существуют альтернативы EM с лучшими гарантиями согласованности, которые называются моментальные подходы[34] или так называемый спектральные методы[35][36][нужна цитата ]. Моментные подходы к изучению параметров вероятностной модели в последнее время вызывают все больший интерес, поскольку они обладают такими гарантиями, как глобальная конвергенция при определенных условиях, в отличие от EM, который часто страдает проблемой застревания в локальных оптимумах. Алгоритмы с гарантиями обучения могут быть получены для ряда важных моделей, таких как модели смеси, HMM и т. Д. Для этих спектральных методов не возникает ложных локальных оптимумов, и истинные параметры могут быть последовательно оценены при некоторых условиях регулярности.[нужна цитата ].
Смотрите также
- распределение смеси
- составное распределение
- оценка плотности
- спектроскопия полного поглощения
- Алгоритм ожидания – максимизации
- Алгоритм EM можно рассматривать как частный случай алгоритм мажоризации-минимизации (MM).[37]
Рекомендации
- ^ Демпстер, А.; Лэрд, Н.; Рубин, Д. (1977). «Максимальная вероятность неполных данных с помощью алгоритма EM». Журнал Королевского статистического общества, серия B. 39 (1): 1–38. JSTOR 2984875. Г-Н 0501537.
- ^ Чеппелини, Р. (1955). «Оценка частот генов в популяции случайного спаривания». Анна. Гм. Genet. 20 (2): 97–115. Дои:10.1111 / j.1469-1809.1955.tb01360.x. PMID 13268982. S2CID 38625779.
- ^ Сундберг, Рольф (1974). «Теория максимального правдоподобия для неполных данных из экспоненциальной семьи». Скандинавский статистический журнал. 1 (2): 49–58. JSTOR 4615553. Г-Н 0381110.
- ^ а б Рольф Сундберг. 1971 г. Теория максимального правдоподобия и приложения для распределений, сгенерированных при наблюдении функции экспоненциальной переменной семейства. Диссертация, Институт математической статистики, Стокгольмский университет.
- ^ а б Сундберг, Рольф (1976). «Итерационный метод решения уравнений правдоподобия для неполных данных из экспоненциальных семейств». Коммуникации в статистике - моделирование и вычисления. 5 (1): 55–64. Дои:10.1080/03610917608812007. Г-Н 0443190.
- ^ См. Благодарность Демпстера, Лэрда и Рубина на страницах 3, 5 и 11.
- ^ Г. Куллдорф. 1961 г. Вклад в теорию оценивания по сгруппированным и частично сгруппированным выборкам. Альмквист и Викселл.
- ^ а б Андерс Мартин-Лёф. 1963. "Utvärdering av livslängder i subnanosekundsområdet" ("Оценка субнаносекундных времен жизни"). («Формула Сундберга»)
- ^ а б Пер Мартин-Лёф. 1966. Статистика с точки зрения статистической механики. Конспект лекций Математического института Орхусского университета. («Формула Сундберга» приписана Андерсу Мартин-Лёфу).
- ^ а б Пер Мартин-Лёф. 1970. Statistika Modeller (Статистические модели): Anteckningar from Seminarier läsåret 1969–1970 (Записи семинаров в 1969-1970 учебном году) при содействии Рольфа Сундберга. Стокгольмский университет. («Формула Сундберга»)
- ^ а б Мартин-Лёф, П. Понятие избыточности и его использование в качестве количественной меры отклонения между статистической гипотезой и набором данных наблюдений. С обсуждением Ф. Абильдгарда, А. П. Демпстер, Д. Басу, Д. Р. Кокс, А. В. Ф. Эдвардс, Д. А. Спротт, Г. А. Барнард, О. Барндорф-Нильсен, Дж. Д. Кальбфляйш и Г. Раш и ответ автора. Труды конференции по основополагающим вопросам статистического вывода (Орхус, 1973), стр. 1–42. Воспоминания, № 1, Теорет. Статист., Инст. Матем., Univ. Орхус, Орхус, 1974.
- ^ а б Мартин-Лёф, Пер (1974). «Понятие избыточности и его использование в качестве количественной меры несоответствия между статистической гипотезой и набором данных наблюдений». Сканд. Дж. Статист. 1 (1): 3–18.
- ^ а б c Ву, К.Ф. Джефф (март 1983 г.). «О свойствах сходимости EM-алгоритма». Анналы статистики. 11 (1): 95–103. Дои:10.1214 / aos / 1176346060. JSTOR 2240463. Г-Н 0684867.
- ^ Little, Roderick J.A .; Рубин, Дональд Б. (1987). Статистический анализ с отсутствующими данными. Ряд Уайли по вероятности и математической статистике. Нью-Йорк: Джон Вили и сыновья. стр.134 –136. ISBN 978-0-471-80254-9.
- ^ а б Нил, Рэдфорд; Хинтон, Джеффри (1999). Майкл И. Джордан (ред.). Взгляд на алгоритм EM, который оправдывает инкрементальные, разреженные и другие варианты (PDF). Обучение в графических моделях. Кембридж, Массачусетс: MIT Press. С. 355–368. ISBN 978-0-262-60032-3. Получено 2009-03-22.
- ^ а б Хасти, Тревор; Тибширани, Роберт; Фридман, Джером (2001). «8.5 Алгоритм ЭМ». Элементы статистического обучения. Нью-Йорк: Спрингер. стр.236 –243. ISBN 978-0-387-95284-0.
- ^ Линдстрем, Мэри Дж; Бейтс, Дуглас М (1988). "Алгоритмы Ньютона-Рафсона и EM для линейных моделей смешанных эффектов для данных повторяющихся измерений". Журнал Американской статистической ассоциации. 83 (404): 1014. Дои:10.1080/01621459.1988.10478693.
- ^ Ван Дайк, Дэвид А (2000). «Подбор моделей со смешанными эффектами с использованием эффективных алгоритмов EM-типа». Журнал вычислительной и графической статистики. 9 (1): 78–98. Дои:10.2307/1390614. JSTOR 1390614.
- ^ Диффей, С. М; Смит, А. Б; Валлийский, A.H; Куллис, Б. Р. (2017). «Новый EM-алгоритм REML (расширенный параметр) для линейных смешанных моделей». Статистический журнал Австралии и Новой Зеландии. 59 (4): 433. Дои:10.1111 / anzs.12208.
- ^ Матараццо, Т. Дж., И Пакзад, С. Н. (2016). «STRIDE для структурной идентификации с использованием максимизации ожиданий: итеративный метод только для вывода для модальной идентификации». Журнал инженерной механики.http://ascelibrary.org/doi/abs/10.1061/(ASCE)EM.1943-7889.0000951
- ^ Einicke, G.A .; Malos, J. T .; Reid, D.C .; Хейнсворт, Д. У. (январь 2009 г.). «Уравнение Риккати и сходимость алгоритмов ЭМ для выравнивания инерциальной навигации». IEEE Trans. Сигнальный процесс. 57 (1): 370–375. Bibcode:2009ITSP ... 57..370E. Дои:10.1109 / TSP.2008.2007090. S2CID 1930004.
- ^ Einicke, G.A .; Falco, G .; Малос, Дж. Т. (май 2010 г.). "Матрица состояний алгоритмов ЭМ для навигации". Письма об обработке сигналов IEEE. 17 (5): 437–440. Bibcode:2010ISPL ... 17..437E. Дои:10.1109 / LSP.2010.2043151. S2CID 14114266.
- ^ Einicke, G.A .; Falco, G .; Dunn, M. T .; Рид, Д. К. (май 2012 г.). «Итеративная сглаженная оценка дисперсии». Письма об обработке сигналов IEEE. 19 (5): 275–278. Bibcode:2012ISPL ... 19..275E. Дои:10.1109 / LSP.2012.2190278. S2CID 17476971.
- ^ Эйнике, Г. А. (сентябрь 2015 г.). «Итерационная фильтрация и сглаживание измерений, содержащих пуассоновский шум». IEEE Transactions по аэрокосмическим и электронным системам. 51 (3): 2205–2011. Bibcode:2015ITAES..51.2205E. Дои:10.1109 / TAES.2015.140843. S2CID 32667132.
- ^ Джамшидиан, Мортаза; Дженнрих, Роберт И. (1997). «Ускорение алгоритма ЭМ с помощью квазиньютоновских методов». Журнал Королевского статистического общества, серия B. 59 (2): 569–587. Дои:10.1111/1467-9868.00083. Г-Н 1452026.
- ^ Лю, К. (1998). «Расширение параметров для ускорения EM: алгоритм PX-EM». Биометрика. 85 (4): 755–770. CiteSeerX 10.1.1.134.9617. Дои:10.1093 / biomet / 85.4.755.
- ^ Мэн, Сяо-Ли; Рубин, Дональд Б. (1993). «Оценка максимального правдоподобия с помощью алгоритма ECM: общие рамки». Биометрика. 80 (2): 267–278. Дои:10.1093 / biomet / 80.2.267. Г-Н 1243503. S2CID 40571416.
- ^ Лю, Чуаньхай; Рубин, Дональд Б. (1994). «Алгоритм ECME: простое расширение EM и ECM с более быстрой монотонной сходимостью». Биометрика. 81 (4): 633. Дои:10.1093 / biomet / 81.4.633. JSTOR 2337067.
- ^ Цзянтао Инь; Яньфэн Чжан; Лисинь Гао (2012). «Ускорение алгоритмов максимизации ожиданий с помощью частых обновлений» (PDF). Труды Международной конференции IEEE по кластерным вычислениям.
- ^ Хантер Д.Р. и Ланге К. (2004), Учебник по алгоритмам MM, Американский статистик, 58: 30-37
- ^ Мацуяма, Ясуо (2003). «Алгоритм α-EM: максимизация суррогатного правдоподобия с использованием мер α-логарифмической информации». IEEE Transactions по теории информации. 49 (3): 692–706. Дои:10.1109 / TIT.2002.808105.
- ^ Мацуяма, Ясуо (2011). «Оценка скрытой марковской модели на основе алгоритма альфа-ЭМ: дискретные и непрерывные альфа-ГММ». Международная совместная конференция по нейронным сетям: 808–816.
- ^ а б Волынец, М. (1979). «Оценка максимального правдоподобия в линейной модели по ограниченным и цензурированным нормальным данным». Журнал Королевского статистического общества, серия C. 28 (2): 195–206. Дои:10.2307/2346749. JSTOR 2346749.
- ^ Пирсон, Карл (1894). «Вклад в математическую теорию эволюции». Философские труды Лондонского королевского общества A. 185: 71–110. Bibcode:1894RSPTA.185 ... 71P. Дои:10.1098 / рста.1894.0003. ISSN 0264-3820. JSTOR 90667.
- ^ Шабан, Амирреза; Мехрдад, Фараджтабар; Бо, Се; Ле, песня; Байрон, Сапоги (2015). "Изучение моделей с латентными переменными путем улучшения спектральных решений с помощью метода внешней точки" (PDF). UAI: 792–801.
- ^ Балле, Борха Кваттони, Ариадна Каррерас, Ксавьер (27.06.2012). Оптимизация локальных потерь в моделях операторов: новый взгляд на спектральное обучение. OCLC 815865081.CS1 maint: несколько имен: список авторов (ссылка на сайт)
- ^ Ланге, Кеннет. «Алгоритм ММ» (PDF).
дальнейшее чтение
- Хогг, Роберт; Маккин, Джозеф; Крейг, Аллен (2005). Введение в математическую статистику. Река Аппер Сэдл, Нью-Джерси: Пирсон Прентис Холл. С. 359–364.
- Делларт, Франк (2002). «Алгоритм максимизации ожидания». CiteSeerX 10.1.1.9.9735. Цитировать журнал требует
| журнал =(Помогите) дает более простое объяснение алгоритма EM в отношении максимизации нижней границы. - Епископ, Кристофер М. (2006). Распознавание образов и машинное обучение. Springer. ISBN 978-0-387-31073-2.
- Gupta, M. R .; Чен, Ю. (2010). «Теория и использование алгоритма ЭМ». Основы и тенденции в обработке сигналов. 4 (3): 223–296. CiteSeerX 10.1.1.219.6830. Дои:10.1561/2000000034. Хорошо написанная короткая книга по EM, включая подробный вывод EM для GMM, HMM и Дирихле.
- Билмес, Джефф (1998). "Мягкое руководство по алгоритму EM и его применению для оценки параметров для гауссовской смеси и скрытых марковских моделей". CiteSeerX 10.1.1.28.613. Цитировать журнал требует
| журнал =(Помогите) включает упрощенный вывод уравнений EM для гауссовских смесей и скрытых марковских моделей гауссовской смеси. - Маклахлан, Джеффри Дж .; Кришнан, Триямбакам (2008). Алгоритм EM и расширения (2-е изд.). Хобокен: Вайли. ISBN 978-0-471-20170-0.
внешняя ссылка
- Различные 1D, 2D и 3D демонстрации EM вместе с Mixture Modeling предоставляются в составе парных SOCR активности и апплеты. Эти апплеты и действия эмпирически демонстрируют свойства алгоритма EM для оценки параметров в различных условиях.
- k-MLE: быстрый алгоритм для изучения моделей статистической смеси
- Иерархия классов в C ++ (GPL), включая гауссовские смеси
- Он-лайн учебник: теория информации, выводы и алгоритмы обучения, к Дэвид Дж. К. Маккей включает простые примеры алгоритма EM, такие как кластеризация с использованием программного k- означает алгоритм и подчеркивает вариативный вид алгоритма EM, как описано в главе 33.7 версии 7.2 (четвертое издание).
- Вариационные алгоритмы приближенного байесовского вывода М. Дж.Бил включает в себя сравнения EM с вариационной байесовской EM и выводы нескольких моделей, включая вариационные байесовские модели HMM (главы ).
- Алгоритм максимизации ожидания: краткое руководство, Автономный вывод алгоритма EM Шона Бормана.
- ЭМ алгоритм, пользователя Xiaojin Zhu.
- Алгоритм и варианты EM: неформальное руководство пользователя Alexis Roche. Краткое и очень четкое описание EM и множество интересных вариантов.