Статистика - Википедия - Statistics
| Статистика |
|---|
 |
|

Статистика это дисциплина, которая касается сбора, организации, анализа, интерпретации и представления данные.[1][2][3] При применении статистики к научной, промышленной или социальной проблеме принято начинать с статистическая совокупность или статистическая модель быть изученным. Популяции могут быть разными группами людей или объектов, такими как «все люди, живущие в стране» или «каждый атом, составляющий кристалл». Статистика имеет дело со всеми аспектами данных, включая планирование сбора данных с точки зрения дизайна опросы и эксперименты.[4] Список терминов и тем см. В глоссарий вероятностей и статистики.
Когда перепись данные не могут быть собраны, статистики собирать данные путем разработки конкретных планов экспериментов и опросов образцы. Репрезентативная выборка гарантирует, что выводы и заключения могут разумно распространяться от выборки на совокупность в целом. An экспериментальное исследование включает в себя измерения исследуемой системы, манипулирование системой, а затем выполнение дополнительных измерений с использованием той же процедуры, чтобы определить, изменила ли манипуляция значения измерений. Напротив, наблюдательное исследование не предполагает экспериментальных манипуляций.
Два основных статистических метода используются в анализ данных: описательная статистика, которые суммируют данные из выборки, используя индексы такой как иметь в виду или же стандартное отклонение, и выведенный статистика, которые делают выводы на основе данных, подверженных случайным изменениям (например, ошибкам наблюдений, вариациям выборки).[5] Описательная статистика чаще всего связана с двумя наборами свойств распределение (выборка или совокупность): основная тенденция (или же место расположения) стремится охарактеризовать центральную или типичную ценность распределения, в то время как разброс (или же изменчивость) характеризует степень отклонения членов распределения от его центра и друг от друга. Выводы о математическая статистика сделаны в рамках теория вероятности, который занимается анализом случайных явлений.
Стандартная статистическая процедура включает сбор данных, ведущих к проверка отношений между двумя наборами статистических данных или набором данных и синтетическими данными, полученными из идеализированной модели. Предлагается гипотеза о статистической взаимосвязи между двумя наборами данных, и она сравнивается как альтернатива к идеализированному нулевая гипотеза отсутствия связи между двумя наборами данных. Отклонение или опровержение нулевой гипотезы осуществляется с помощью статистических тестов, которые количественно определяют, в каком смысле нулевое значение может быть доказано как ложное, учитывая данные, которые используются в тесте. Исходя из нулевой гипотезы, различают две основные формы ошибки: Ошибки типа I (нулевая гипотеза ошибочно отвергается, давая «ложноположительный результат») и Ошибки типа II (нулевая гипотеза не может быть отвергнута, а фактическая взаимосвязь между популяциями упускается, что дает «ложноотрицательный результат»).[6] С этой структурой связано множество проблем, от получения достаточного размера выборки до определения адекватной нулевой гипотезы.[нужна цитата ]
Процессы измерения, которые генерируют статистические данные, также подвержены ошибкам. Многие из этих ошибок классифицируются как случайные (шум) или систематические (предвзятость ), но могут возникать и другие типы ошибок (например, грубая ошибка, например, когда аналитик сообщает неверные единицы измерения). Наличие отсутствующие данные или же цензура может привести к смещению оценок, и для решения этих проблем были разработаны специальные методы.
Самые ранние сочинения о вероятность и статистика, статистические методы на основе теория вероятности, Дата возврата Арабские математики и криптографы, особенно Аль-Халиль (717–786)[7] и Аль-Кинди (801–873).[8][9] В 18 веке статистика также начала в значительной степени опираться на исчисление. В последние годы статистика больше полагалась на статистическое программное обеспечение.[10]
Вступление
Статистика - это математическая наука, которая имеет отношение к сбору, анализу, интерпретации или объяснению и представлению данные,[11] или как филиал математика.[12] Некоторые считают статистику отдельной математической наукой, а не разделом математики. Хотя во многих научных исследованиях используются данные, статистика касается использования данных в контексте неопределенности и принятия решений в условиях неопределенности.[13][14]
При применении статистики к проблеме обычно начинают с численность населения или процесс, который необходимо изучить. Популяции могут быть разными, например, «все люди, живущие в стране» или «каждый атом, составляющий кристалл». В идеале статистики собирают данные обо всей популяции (операция, называемая перепись ). Это может быть организовано государственными статистическими институтами. Описательная статистика может использоваться для обобщения данных о населении. Числовые дескрипторы включают иметь в виду и стандартное отклонение за непрерывные данные (например, доход), а частота и процент более полезны с точки зрения описания категориальные данные (как образование).
Когда перепись невозможна, выбранная подгруппа населения называется образец изучается. После определения выборки, которая является репрезентативной для генеральной совокупности, собираются данные для членов выборки в ходе наблюдений или экспериментальный параметр. Опять же, описательная статистика может использоваться для обобщения выборочных данных. Однако отрисовка выборки содержит элемент случайности; следовательно, числовые дескрипторы из выборки также подвержены неопределенности. Чтобы сделать значимые выводы обо всем населении, выведенный статистика необходим. Он использует шаблоны в выборке данных, чтобы делать выводы о представленной совокупности с учетом случайности. Эти выводы могут принимать форму ответов на вопросы да / нет о данных (проверка гипотезы ), оценивая числовые характеристики данных (оценка ), описывая ассоциации в пределах данных (корреляция ) и моделирование отношений в данных (например, с помощью регрессивный анализ ). Вывод может распространяться на прогнозирование, прогноз и оценка ненаблюдаемых значений либо в исследуемой популяции, либо связанных с ней. Он может включать экстраполяция и интерполяция из Временные ряды или же пространственные данные, и сбор данных.
Математическая статистика
Математическая статистика - это приложение математика к статистике. Математические методы, используемые для этого, включают математический анализ, линейная алгебра, стохастический анализ, дифференциальные уравнения, и Теоретико-мерная теория вероятностей.[15][16]
История

Самые ранние сочинения о вероятность и статистика восходит к Арабские математики и криптографы, вовремя Исламский золотой век между 8 и 13 веками. Аль-Халиль (717–786) написал Книга криптографических сообщений, который содержит первое использование перестановки и комбинации, чтобы перечислить все возможные арабский слова с гласными и без них.[7] Самая ранняя книга по статистике - трактат IX века. Рукопись по расшифровке криптографических сообщений, написанный арабским ученым Аль-Кинди (801–873). В своей книге Аль-Кинди дал подробное описание того, как использовать статистику и частотный анализ расшифровать зашифрованный Сообщения. Этот текст заложил основы статистики и криптоанализ.[8][9] Аль-Кинди также использовал самое раннее известное использование статистические выводы, в то время как он и более поздние арабские криптографы разработали ранние статистические методы для расшифровка зашифрованные сообщения. Ибн Адлан (1187–1268) позже внесли важный вклад в использование размер образца в частотном анализе.[7]
Самые ранние европейские труды по статистике относятся к 1663 году, когда были опубликованы Естественные и политические наблюдения за счетом смертности к Джон Граунт.[17] Ранние применения статистического мышления вращались вокруг потребностей государств основывать политику на демографических и экономических данных, поэтому стат- этимология. В начале 19 века объем статистической дисциплины расширился и теперь включает сбор и анализ данных в целом. Сегодня статистика широко используется в правительстве, бизнесе, естественных и социальных науках.
Математические основы современной статистики были заложены в 17 веке с развитием теория вероятности к Джероламо Кардано, Блез Паскаль и Пьер де Ферма. Математическая теория вероятностей возникла в результате изучения азартные игры, хотя понятие вероятности уже рассматривалось в средневековый закон и философами, такими как Хуан Карамуэль.[18] В метод наименьших квадратов был впервые описан Адриан-Мари Лежандр в 1805 г.

Современная статистика возникла в конце 19 - начале 20 века в три этапа.[19] Первую волну на рубеже веков возглавляли работы Фрэнсис Гальтон и Карл Пирсон, который превратил статистику в строгую математическую дисциплину, используемую для анализа не только в науке, но также в промышленности и политике. Вклад Гальтона включал введение концепции стандартное отклонение, корреляция, регрессивный анализ и применение этих методов для изучения множества человеческих характеристик, включая рост, вес, длину ресниц.[20] Пирсон разработал Коэффициент корреляции продукт-момент Пирсона, определяемый как продукт-момент,[21] то метод моментов для подгонки распределений к выборкам и Распределение Пирсона, среди прочего.[22] Гальтон и Пирсон основали Биометрика как первый журнал математической статистики и биостатистика (тогда называемая биометрией), и последний основал первый в мире университетский статистический факультет в Университетский колледж Лондона.[23]
Рональд Фишер ввел термин нулевая гипотеза вовремя Леди дегустация чая эксперимент, который «никогда не доказывается и не устанавливается, но, возможно, опровергается в ходе экспериментов».[24][25]
Вторая волна 1910-1920-х годов была инициирована Уильям Сили Госсет, и достигла своей кульминации в понимании Рональд Фишер, который написал учебники, которые должны были определять академические дисциплины в университетах по всему миру. Самыми важными публикациями Фишера были его основополагающие статьи 1918 года. Взаимоотношения родственников на основе менделевского наследования (который первым использовал статистический термин, отклонение ), его классическая работа 1925 года Статистические методы для научных работников и его 1935 г. Планирование экспериментов,[26][27][28] где он разработал строгие дизайн экспериментов модели. Он положил начало концепции достаточность, вспомогательная статистика, Линейный дискриминатор Фишера и Информация Fisher.[29] В своей книге 1930 года Генетическая теория естественного отбора, он применял статистику к различным биологический такие концепции, как Принцип фишера[30] (который А. В. Ф. Эдвардс назвал "вероятно, самым известным аргументом в эволюционная биология ") и Фишерианский беглец,[31][32][33][34][35][36] концепция в половой отбор о положительном эффекте обратной связи, обнаруженном в эволюция.
Последняя волна, которая в основном представляла собой усовершенствование и расширение более ранних разработок, возникла в результате совместной работы между Эгон Пирсон и Ежи Нейман в 1930-е гг. Они ввели понятие "Тип II " ошибка, сила теста и доверительные интервалы. Ежи Нейман в 1934 году показал, что стратифицированная случайная выборка в целом является лучшим методом оценки, чем целенаправленная (квотная) выборка.[37]
Сегодня статистические методы применяются во всех областях, связанных с принятием решений, для точных выводов на основе сопоставленного массива данных и для принятия решений в условиях неопределенности на основе статистической методологии. Использование современных компьютеры ускорила крупномасштабные статистические вычисления, а также сделала возможными новые методы, которые непрактично выполнять вручную. Статистика продолжает оставаться областью активных исследований, например, по проблеме анализа большое количество данных.[38]
Статистические данные
Сбор информации
Отбор проб
Когда невозможно собрать полные данные переписи, статистики собирают выборочные данные, разрабатывая конкретные планы экспериментов и образцы опроса. Сама статистика также предоставляет инструменты для прогнозирования и прогнозирования с помощью статистические модели. Идея делать выводы на основе выборочных данных возникла примерно в середине 1600-х годов в связи с оценкой населения и разработкой предшественников страхования жизни.[39]
Чтобы использовать выборку в качестве ориентира для всего населения, важно, чтобы он действительно отражал все население. Представитель отбор проб гарантирует, что умозаключения и заключения могут безопасно распространяться от выборки на совокупность в целом. Основная проблема заключается в том, чтобы определить, насколько действительно репрезентативна выбранная выборка. Статистика предлагает методы для оценки и исправления любых систематических ошибок в процедурах выборки и сбора данных. Существуют также методы экспериментального планирования экспериментов, которые могут уменьшить эти проблемы в начале исследования, усиливая его способность распознавать истину о населении.
Теория выборки является частью математическая дисциплина из теория вероятности. Вероятность используется в математическая статистика изучить выборочные распределения из статистика выборки и, в более общем плане, свойства статистические процедуры. Использование любого статистического метода допустимо, если рассматриваемая система или совокупность удовлетворяет допущениям метода. Разница во взглядах между классической теорией вероятности и теорией выборки состоит, грубо говоря, в том, что теория вероятностей начинается с заданных параметров генеральной совокупности до выводить вероятности, относящиеся к выборкам. Статистический вывод, однако, движется в противоположном направлении -индуктивный вывод от образцов к параметрам большей или общей совокупности.
Экспериментальные и наблюдательные исследования
Общей целью проекта статистического исследования является изучение причинность, и в частности сделать вывод о влиянии изменения значений предикторов или независимые переменные от зависимых переменных. Существует два основных типа причинно-следственных статистических исследований: экспериментальные исследования и наблюдательные исследования. В обоих типах исследований наблюдается влияние различий независимой переменной (или переменных) на поведение зависимой переменной. Разница между этими двумя типами заключается в том, как фактически проводится исследование. Каждый из них может быть очень эффективным. Экспериментальное исследование включает в себя выполнение измерений исследуемой системы, манипулирование системой, а затем выполнение дополнительных измерений с использованием той же процедуры, чтобы определить, изменило ли манипуляция значения измерений. Напротив, обсервационное исследование не включает экспериментальная манипуляция. Вместо этого собираются данные и исследуются корреляции между предикторами и ответом. Хотя инструменты анализа данных лучше всего работают с данными из рандомизированные исследования, они также применяются к другим типам данных, например естественные эксперименты и наблюдательные исследования[40]- для чего статистика использует модифицированный, более структурированный метод оценки (например, Оценка разницы в различиях и инструментальные переменные, среди многих других), которые производят последовательные оценки.
Эксперименты
Основные этапы статистического эксперимента:
- Планирование исследования, в том числе определение количества повторов исследования, с использованием следующей информации: предварительные оценки размера эффекты лечения, альтернативные гипотезы, а оценочная экспериментальная изменчивость. Необходимо учитывать выбор объектов эксперимента и этику исследования. Статистики рекомендуют в экспериментах сравнить (по крайней мере) одно новое лечение со стандартным лечением или контролем, чтобы можно было объективно оценить разницу в эффектах лечения.
- Дизайн экспериментов, с помощью блокировка уменьшить влияние смешивающие переменные, и рандомизированное назначение процедур для субъектов, чтобы позволить объективные оценки эффектов лечения и экспериментальной ошибки. На этом этапе экспериментаторы и статистики пишут протокол эксперимента который будет определять эффективность эксперимента и определяет первичный анализ экспериментальных данных.
- Проведение эксперимента после протокол эксперимента и анализ данных следуя экспериментальному протоколу.
- Дальнейшее изучение набора данных во вторичном анализе, чтобы предложить новые гипотезы для будущего исследования.
- Документирование и представление результатов исследования.
Особые опасения вызывают эксперименты с человеческим поведением. Известный Хоторнское исследование изучили изменения в рабочей среде на заводе в Хоторне Western Electric Company. Исследователи были заинтересованы в том, чтобы определить, повысит ли повышенное освещение производительность сборочная линия рабочие. Исследователи сначала измерили продуктивность растения, затем изменили освещенность участка растения и проверили, влияют ли изменения освещения на продуктивность. Оказалось, что производительность действительно улучшилась (в условиях эксперимента). Однако сегодня это исследование подвергается резкой критике за ошибки в экспериментальных процедурах, особенно за отсутствие контрольная группа и слепота. В Эффект хоторна относится к обнаружению того, что результат (в данном случае производительность труда) изменился из-за самого наблюдения. Те, кто участвовал в исследовании Хоторна, стали более продуктивными не потому, что изменилось освещение, а потому, что за ними наблюдали.[41]
Наблюдательное исследование
Примером обсервационного исследования является исследование связи между курением и раком легких. Этот тип исследования обычно использует опрос для сбора наблюдений за интересующей областью, а затем выполняет статистический анализ. В этом случае исследователи собирают наблюдения как за курильщиками, так и за некурящими, возможно, через когортное исследование, а затем поищите количество случаев рака легких в каждой группе.[42] А исследование случай-контроль - это еще один тип наблюдательного исследования, в котором люди с интересующим результатом и без него (например, рак легких) приглашаются принять участие и собираются истории их воздействия.
Типы данных
Были предприняты различные попытки составить таксономию уровни измерения. Психофизик Стэнли Смит Стивенс определены номинальная, порядковая, интервальная шкала и шкала отношения. Номинальные измерения не имеют значимого ранжирования среди значений и допускают любое однозначное (инъективное) преобразование. Порядковые измерения имеют неточные различия между последовательными значениями, но имеют значимый порядок этих значений и допускают любые преобразования с сохранением порядка. Для интервальных измерений определены значимые расстояния между измерениями, но нулевое значение является произвольным (как в случае с долгота и температура измерения в Цельсия или же Фаренгейт ) и допускают любое линейное преобразование. Измерения соотношения имеют как значимое нулевое значение, так и заданные расстояния между различными измерениями, а также допускают любое преобразование масштабирования.
Поскольку переменные, соответствующие только номинальным или порядковым измерениям, не могут быть разумно измерены численно, иногда они группируются вместе как категориальные переменные, тогда как измерения отношения и интервалы сгруппированы вместе как количественные переменные, который может быть либо дискретный или же непрерывный, из-за их числовой природы. Такие различия часто слабо соотносятся с тип данных в информатике, дихотомические категориальные переменные могут быть представлены Логический тип данных, политомические категориальные переменные с произвольно назначенными целые числа в интегральный тип данных, и непрерывные переменные с реальный тип данных с участием плавающая точка вычисление. Но сопоставление типов данных информатики с типами статистических данных зависит от того, какая категоризация последних реализуется.
Были предложены и другие категории. Например, Мостеллер и Тьюки (1977)[43] отличительные оценки, ранги, счетные дроби, подсчеты, суммы и остатки. Нелдер (1990)[44] описаны непрерывные подсчеты, непрерывные отношения, отношения подсчета и категориальные режимы данных. (См. Также: Chrisman (1998),[45] ван ден Берг (1991).[46])
Вопрос о том, уместно ли применять разные виды статистических методов к данным, полученным с помощью различных процедур измерения, осложняется проблемами, связанными с преобразованием переменных и точной интерпретацией вопросов исследования. "Связь между данными и тем, что они описывают, просто отражает тот факт, что определенные виды статистических утверждений могут иметь значения истинности, которые не являются инвариантными при некоторых преобразованиях. Разумно ли рассматривать преобразование, зависит от вопроса, на который человек пытается ответить. . "[47]:82
Статистические методы
Описательная статистика
А описательная статистика (в считать имя существительное смысл) является сводная статистика который количественно описывает или суммирует особенности набора Информация,[48] пока описательная статистика в массовое существительное смысл - это процесс использования и анализа этой статистики. Описательная статистика отличается от выведенный статистика (или индуктивная статистика) в том смысле, что описательная статистика предназначена для обобщения образец, а не использовать данные, чтобы узнать о численность населения что, как предполагается, представляет собой образец данных.
Выведенный статистика
Статистические выводы это процесс использования анализ данных вывести свойства базового распределение вероятностей.[49] Логический статистический анализ выводит свойства численность населения, например, путем проверки гипотез и получения оценок. Предполагается, что набор наблюдаемых данных отобранный от большего населения. Выводную статистику можно противопоставить описательная статистика. Описательная статистика касается исключительно свойств наблюдаемых данных и не основывается на предположении, что данные поступают от большей совокупности.
Терминология и теория выводной статистики
Статистика, оценки и основные количества
Учитывать независимые одинаково распределенные (IID) случайные величины с данным распределение вероятностей: стандарт статистические выводы и теория оценки определяет случайный пример как случайный вектор предоставленный вектор столбца этих переменных IID.[50] В численность населения исследуемый описывается распределением вероятностей, которое может иметь неизвестные параметры.
А статистика - случайная величина, которая является функцией случайной выборки, но не функция неизвестных параметров. Однако вероятностное распределение статистики может иметь неизвестные параметры.
Рассмотрим теперь функцию неизвестного параметра: оценщик - статистика, используемая для оценки такой функции. Обычно используемые оценщики включают выборочное среднее беспристрастный выборочная дисперсия и выборочная ковариация.
Случайная величина, которая является функцией случайной выборки и неизвестного параметра, но распределение вероятностей которой не зависит от неизвестного параметра называется основное количество или поворот. Широко используемые шарниры включают z-оценка, то статистика хи-квадрат и студенческих t-значение.
Между двумя оценщиками данного параметра один с меньшим среднеквадратичная ошибка говорят, что это больше эффективный. Кроме того, оценщик называется беспристрастный если это ожидаемое значение равно истинному значению неизвестного оцениваемого параметра и асимптотически несмещен, если его ожидаемое значение сходится в предел к истинному значению такого параметра.
Другие желательные свойства для оценщиков включают: UMVUE оценщики, которые имеют наименьшую дисперсию для всех возможных значений оцениваемого параметра (обычно это свойство легче проверить, чем эффективность) и последовательные оценки который сходится по вероятности к истинному значению такого параметра.
Это все еще оставляет вопрос о том, как получить оценки в данной ситуации и провести вычисления, было предложено несколько методов: метод моментов, то максимальная вероятность метод, наименьших квадратов метод и более поздний метод оценочные уравнения.
Нулевая гипотеза и альтернативная гипотеза
Интерпретация статистической информации часто может включать в себя разработку нулевая гипотеза что обычно (но не обязательно) заключается в том, что между переменными не существует взаимосвязи или что со временем не произошло никаких изменений.[51][52]
Лучшая иллюстрация для новичка - затруднительное положение, с которым сталкивается уголовный процесс. Нулевая гипотеза, H0, утверждает, что подсудимый невиновен, тогда как альтернативная гипотеза, H1, утверждает, что подсудимый виновен. Обвинение вынесено на основании подозрения в виновности. H0 (статус-кво) противостоит H1 и сохраняется, если H1 подтверждается доказательствами «вне разумного сомнения». Однако «отказ отвергнуть H0"в данном случае не означает невиновность, а просто то, что улик было недостаточно для вынесения приговора. Таким образом, жюри не обязательно принимать ЧАС0 но не может отклонить ЧАС0. Хотя нельзя «доказать» нулевую гипотезу, можно проверить, насколько она близка к истинности, с помощью проверка мощности, который проверяет ошибки II типа.
Что статистики позвонить Альтернативная гипотеза это просто гипотеза, противоречащая нулевая гипотеза.
Ошибка
Работая с нулевая гипотеза, различают две основные формы ошибки:
- Ошибки типа I где нулевая гипотеза ошибочно отвергается, давая «ложноположительный результат».
- Ошибки типа II где нулевая гипотеза не может быть отклонена, а фактическая разница между популяциями отсутствует, что дает «ложноотрицательный результат».
Стандартное отклонение относится к степени, в которой отдельные наблюдения в выборке отличаются от центрального значения, такого как выборка или среднее значение генеральной совокупности, в то время как Стандартная ошибка относится к оценке разницы между средним значением выборки и средним значением генеральной совокупности.
А статистическая ошибка это величина, на которую наблюдение отличается от ожидаемое значение, а остаточный - величина, на которую наблюдение отличается от значения, которое оценщик ожидаемого значения принимает для данной выборки (также называемого прогнозом).
Среднеквадратичная ошибка используется для получения эффективные оценщики, широко используемый класс оценщиков. Средняя квадратическая ошибка это просто квадратный корень из среднеквадратичной ошибки.
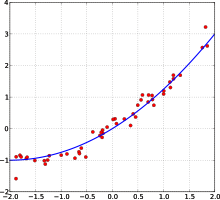
Многие статистические методы стремятся минимизировать остаточная сумма квадратов, и они называются "методы наименьших квадратов " в отличие от Наименьшие абсолютные отклонения. Последний придает равный вес малым и большим ошибкам, тогда как первый придает больший вес большим ошибкам. Остаточная сумма квадратов также дифференцируемый, который предоставляет удобное свойство для выполнения регресс. Наименьшие квадраты применены к линейная регрессия называется обыкновенный метод наименьших квадратов метод и наименьшие квадраты, применяемые к нелинейная регрессия называется нелинейный метод наименьших квадратов. Также в модели линейной регрессии недетерминированная часть модели называется членом ошибки, возмущением или, проще говоря, шумом. И линейная регрессия, и нелинейная регрессия рассматриваются в полиномиальные наименьшие квадраты, который также описывает дисперсию прогноза зависимой переменной (ось y) как функцию независимой переменной (ось x) и отклонения (ошибки, шум, возмущения) от оцененной (подобранной) кривой.
Процессы измерения, генерирующие статистические данные, также подвержены ошибкам. Многие из этих ошибок классифицируются как случайный (шум) или систематический (предвзятость ), но другие типы ошибок (например, грубая ошибка, например, когда аналитик сообщает неверные единицы измерения) также могут быть важны. Наличие отсутствующие данные или же цензура может привести к предвзятые оценки для решения этих проблем были разработаны специальные методы.[53]
Оценка интервала
Большинство исследований отбирают только часть населения, поэтому результаты не полностью отражают всю популяцию. Любые оценки, полученные из выборки, лишь приблизительно соответствуют значению генеральной совокупности. Доверительные интервалы позволяют статистикам выразить, насколько близко оценка выборки соответствует истинному значению для всей генеральной совокупности. Часто они выражаются как 95% доверительные интервалы. Формально 95% доверительный интервал для значения - это диапазон, в котором, если бы выборка и анализ были повторены в одних и тех же условиях (с получением другого набора данных), этот интервал будет включать истинное (совокупное) значение в 95% всех возможных случаев. . Это делает нет подразумевают, что вероятность того, что истинное значение находится в доверительном интервале, составляет 95%. От частотник перспективы, такое утверждение даже не имеет смысла, поскольку истинная ценность не случайная переменная. Либо истинное значение находится в заданном интервале, либо нет. Однако верно то, что до того, как будут отобраны какие-либо данные и дан план построения доверительного интервала, вероятность того, что еще не рассчитанный интервал покроет истинное значение, составляет 95%: в этот момент границы интервала еще не соблюдены случайные переменные. Один из подходов, который дает интервал, который можно интерпретировать как имеющий заданную вероятность содержания истинного значения, заключается в использовании достоверный интервал из Байесовская статистика: этот подход зависит от другого способа интерпретация того, что подразумевается под "вероятностью", то есть как Байесовская вероятность.
В принципе доверительные интервалы могут быть симметричными или асимметричными. Интервал может быть асимметричным, потому что он работает как нижняя или верхняя граница для параметра (левосторонний интервал или правосторонний интервал), но он также может быть асимметричным, поскольку двусторонний интервал построен с нарушением симметрии относительно оценки. Иногда границы доверительного интервала достигаются асимптотически, и они используются для аппроксимации истинных границ.
Значимость
Статистика редко дает простой ответ типа Да / Нет на анализируемый вопрос. Интерпретация часто сводится к уровню статистической значимости, применяемого к числам, и часто относится к вероятности того, что значение точно отвергает нулевую гипотезу (иногда называемую p-значение ).

Стандартный подход[50] заключается в проверке нулевой гипотезы против альтернативной гипотезы. А критическая область - набор значений оценки, приводящей к опровержению нулевой гипотезы. Таким образом, вероятность ошибки типа I - это вероятность того, что оценка принадлежит критической области при условии, что нулевая гипотеза верна (Статистическая значимость ), а вероятность ошибки типа II - это вероятность того, что оценка не принадлежит критической области, при условии, что альтернативная гипотеза верна. В статистическая мощность теста - это вероятность того, что он правильно отвергает нулевую гипотезу, когда нулевая гипотеза ложна.
Ссылка на статистическую значимость не обязательно означает, что общий результат значим с точки зрения реального мира. Например, в большом исследовании лекарственного средства может быть показано, что лекарственное средство имеет статистически значимый, но очень небольшой положительный эффект, так что лекарство вряд ли окажет заметную помощь пациенту.
Хотя в принципе приемлемый уровень Статистическая значимость может быть предметом обсуждения, p-значение - наименьший уровень значимости, который позволяет тесту отклонить нулевую гипотезу. Этот тест логически эквивалентен утверждению, что p-значение - это вероятность, при условии, что нулевая гипотеза верна, увидеть результат, по крайней мере такой же экстремальный, как статистика теста. Следовательно, чем меньше p-значение, тем ниже вероятность совершения ошибки типа I.
Некоторые проблемы обычно связаны с этой структурой (см. критика проверки гипотез ):
- Статистически значимая разница все же может не иметь практического значения, но можно правильно сформулировать тесты, чтобы учесть это. Один ответ предполагает выход за рамки сообщения только о уровень значимости включить п-ценить при сообщении о том, отклонена или принята гипотеза. Однако p-значение не указывает размер или важность наблюдаемого эффекта, а также может показаться преувеличением важности незначительных различий в крупных исследованиях. Лучшим и все более распространенным подходом является сообщение доверительные интервалы. Хотя они производятся на основе тех же расчетов, что и проверки гипотез или п-значения, они описывают как размер эффекта, так и окружающую его неопределенность.
- Заблуждение транспонированного условного, иначе ошибка прокурора: критика возникает, потому что подход к проверке гипотез вынуждает одну гипотезу ( нулевая гипотеза ), поскольку оценивается вероятность наблюдаемого результата с учетом нулевой гипотезы, а не вероятность нулевой гипотезы с учетом наблюдаемого результата. Альтернативу этому подходу предлагает Байесовский вывод, хотя это требует создания априорная вероятность.[54]
- Отказ от нулевой гипотезы не означает автоматического подтверждения альтернативной гипотезы.
- Как все в выведенный статистика он зависит от размера выборки, и поэтому толстые хвосты p-значения могут быть вычислены неправильно.[требуется разъяснение ]
Примеры
Некоторые известные статистические тесты и процедуры:
Исследовательский анализ данных
Исследовательский анализ данных (EDA) - подход к анализируя наборы данных резюмировать их основные характеристики, часто с помощью наглядных методов. А статистическая модель могут использоваться или нет, но в первую очередь EDA предназначена для того, чтобы увидеть, что данные могут сказать нам, помимо формального моделирования или задачи проверки гипотез.
Неправильное использование
Неправильное использование статистики могут привести к тонким, но серьезным ошибкам в описании и интерпретации - тонким в том смысле, что такие ошибки допускают даже опытные профессионалы, и серьезным в том смысле, что они могут привести к разрушительным ошибкам в принятии решений. Например, социальная политика, медицинская практика и надежность таких сооружений, как мосты, - все зависит от правильного использования статистики.
Даже при правильном применении статистических методов результаты могут быть трудными для интерпретации для тех, у кого нет опыта. В Статистическая значимость тренда в данных - который измеряет степень, в которой тренд может быть вызван случайным изменением в выборке - может или не может совпадать с интуитивным ощущением его значимости. Набор основных статистических навыков (и скептицизма), необходимых людям для правильного обращения с информацией в повседневной жизни, называется статистическая грамотность.
Существует общее мнение, что статистические знания слишком часто преднамеренно неправильно использованный находя способы интерпретировать только те данные, которые выгодны докладчику.[55] С цитатой связано недоверие и непонимание статистики »,Есть три вида лжи: ложь, проклятая ложь и статистика. ". Неправильное использование статистики может быть как непреднамеренным, так и преднамеренным, и книга Как лгать со статистикой[55] излагает ряд соображений. В попытке пролить свет на использование и неправильное использование статистики, проводятся обзоры статистических методов, используемых в конкретных областях (например, Warne, Lazo, Ramos, and Ritter (2012)).[56]
Способы избежать неправильного использования статистики включают использование правильных диаграмм и предвзятость.[57] Неправильное использование может иметь место, когда выводы чрезмерно обобщенный и утверждали, что являются репрезентативными для большего, чем они есть на самом деле, часто намеренно или бессознательно игнорируя систематическую ошибку выборки.[58] Гистограммы, пожалуй, самые простые в использовании и понимании диаграммы, и их можно создавать вручную или с помощью простых компьютерных программ.[57] К сожалению, большинство людей не ищут предвзятости или ошибок, поэтому их не замечают. Таким образом, люди часто могут верить, что что-то правда, даже если это не так. представлен.[58] Чтобы данные, собранные на основе статистики, были правдоподобными и точными, отобранная выборка должна быть репрезентативной для всего.[59] По словам Хаффа, «надежность образца может быть разрушена [предвзятостью] ... позвольте себе некоторую степень скептицизма».[60]
Чтобы помочь в понимании статистики, Хафф предложил ряд вопросов, которые нужно задать в каждом случае:[55]
- Кто так сказал? (Есть ли у него / у нее топор, который нужно заточить?)
- Откуда он / она знает? (Есть ли у него / нее ресурсы, чтобы знать факты?)
- Чего не хватает? (Дает ли он / она полную картину?)
- Кто-то сменил тему? (Предлагает ли он / она правильный ответ на неправильную проблему?)
- Имеет ли это смысл? (Логичен ли его / ее вывод и согласуется ли он с тем, что мы уже знаем?)
Неправильная интерпретация: корреляция
Концепция чего-либо корреляция особенно примечателен тем, что может вызвать путаницу. Статистический анализ набор данных часто обнаруживает, что две переменные (свойства) рассматриваемой совокупности имеют тенденцию изменяться вместе, как если бы они были связаны. Например, исследование годового дохода, которое также учитывает возраст смерти, может обнаружить, что бедные люди, как правило, живут короче, чем богатые. Говорят, что две переменные коррелированы; однако они могут быть или не быть причиной друг друга. The correlation phenomena could be caused by a third, previously unconsidered phenomenon, called a lurking variable or смешивающая переменная. For this reason, there is no way to immediately infer the existence of a causal relationship between the two variables. (Видеть Корреляция не подразумевает причинно-следственной связи.)
Приложения
Applied statistics, theoretical statistics and mathematical statistics
Прикладная статистика comprises descriptive statistics and the application of inferential statistics.[61][62] Theoretical statistics concerns the logical arguments underlying justification of approaches to статистические выводы, as well as encompassing математическая статистика. Mathematical statistics includes not only the manipulation of распределения вероятностей necessary for deriving results related to methods of estimation and inference, but also various aspects of вычислительная статистика и дизайн экспериментов.
Statistical consultants can help organizations and companies that don't have in-house expertise relevant to their particular questions.
Machine learning and data mining
Машинное обучение models are statistical and probabilistic models that capture patterns in the data through use of computational algorithms.
Statistics in academia
Statistics is applicable to a wide variety of академические дисциплины, включая естественный и социальные науки, government, and business. Business statistics applies statistical methods in эконометрика, auditing and production and operations, including services improvement and marketing research.[63] In the field of biological sciences, the 12 most frequent statistical tests are: Analysis of Variance (ANOVA), Chi-Square Test, Student’s T Test, Линейная регрессия, Pearson’s Correlation Coefficient, Mann-Whitney U Test, Kruskal-Wallis Test, Shannon’s Diversity Index, Tukey's Test[необходимо разрешение неоднозначности ], Кластерный анализ, Spearman’s Rank Correlation Test и Анализ главных компонентов.[64]
A typical statistics course covers descriptive statistics, probability, binomial and normal distributions, test of hypotheses and confidence intervals, линейная регрессия, and correlation.[65] Modern fundamental statistical courses for undergraduate students focus on correct test selection, results interpretation, and use of free statistics software.[64]
Статистические вычисления
The rapid and sustained increases in computing power starting from the second half of the 20th century have had a substantial impact on the practice of statistical science. Early statistical models were almost always from the class of linear models, but powerful computers, coupled with suitable numerical алгоритмы, caused an increased interest in nonlinear models (Такие как нейронные сети ) as well as the creation of new types, such as обобщенные линейные модели и multilevel models.
Increased computing power has also led to the growing popularity of computationally intensive methods based on повторная выборка, Такие как permutation tests и бутстрап, while techniques such as Выборка Гиббса have made use of Байесовские модели more feasible. The computer revolution has implications for the future of statistics with a new emphasis on "experimental" and "empirical" statistics. A large number of both general and special purpose statistical software are now available. Examples of available software capable of complex statistical computation include programs such as Mathematica, SAS, SPSS, и р.
Statistics applied to mathematics or the arts
Traditionally, statistics was concerned with drawing inferences using a semi-standardized methodology that was "required learning" in most sciences.[нужна цитата ] This tradition has changed with the use of statistics in non-inferential contexts. What was once considered a dry subject, taken in many fields as a degree-requirement, is now viewed enthusiastically.[согласно кому? ] Initially derided by some mathematical purists, it is now considered essential methodology in certain areas.
- В теория чисел, точечные диаграммы of data generated by a distribution function may be transformed with familiar tools used in statistics to reveal underlying patterns, which may then lead to hypotheses.
- Methods of statistics including predictive methods in прогнозирование are combined with теория хаоса и фрактальная геометрия to create video works that are considered to have great beauty.[нужна цитата ]
- В искусство процесса из Джексон Поллок relied on artistic experiments whereby underlying distributions in nature were artistically revealed.[нужна цитата ] With the advent of computers, statistical methods were applied to formalize such distribution-driven natural processes to make and analyze moving video art.[нужна цитата ]
- Methods of statistics may be used predicatively in исполнительское искусство, as in a card trick based on a Марковский процесс that only works some of the time, the occasion of which can be predicted using statistical methodology.
- Statistics can be used to predicatively create art, as in the statistical or stochastic music invented by Яннис Ксенакис, where the music is performance-specific. Though this type of artistry does not always come out as expected, it does behave in ways that are predictable and tunable using statistics.
Specialized disciplines
Statistical techniques are used in a wide range of types of scientific and social research, including: биостатистика, вычислительная биология, вычислительная социология, network biology, социальная наука, социология и социальные исследования. Some fields of inquiry use applied statistics so extensively that they have specialized terminology. These disciplines include:
- Актуарная наука (assesses risk in the insurance and finance industries)
- Прикладная информационная экономика
- Astrostatistics (statistical evaluation of astronomical data)
- Биостатистика
- Хемометрия (for analysis of data from химия )
- Сбор данных (applying statistics and распознавание образов to discover knowledge from data)
- Наука о данных
- Демография (statistical study of populations)
- Эконометрика (statistical analysis of economic data)
- Energy statistics
- Инженерная статистика
- Эпидемиология (statistical analysis of disease)
- География и географические информационные системы особенно в spatial analysis
- Обработка изображений
- Юриметрия (закон )
- Медицинская статистика
- Политическая наука
- Psychological statistics
- Техника надежности
- Социальная статистика
- Статистическая механика
In addition, there are particular types of statistical analysis that have also developed their own specialised terminology and methodology:
- Бутстрап / складной нож повторная выборка
- Многовариантная статистика
- Статистическая классификация
- Structured data analysis
- Моделирование структурным уравнением
- Методология исследования
- Анализ выживаемости
- Statistics in various sports, particularly бейсбол - известный как саберметрика - и крикет
Statistics form a key basis tool in business and manufacturing as well. It is used to understand measurement systems variability, control processes (as in Статистическое управление процессами or SPC), for summarizing data, and to make data-driven decisions. In these roles, it is a key tool, and perhaps the only reliable tool.
Смотрите также
| Библиотечные ресурсы о Статистика |
- Оценка изобилия
- Наука о данных
- Глоссарий вероятности и статистики
- List of academic statistical associations
- List of important publications in statistics
- Список национальных и международных статистических служб
- Список статистических пакетов (программного обеспечения)
- Список статей статистики
- List of university statistical consulting centers
- Обозначения в вероятности и статистике
- World Statistics Day
- Foundations and major areas of statistics
Рекомендации
- ^ "Oxford Reference".
- ^ Romijn, Jan-Willem (2014). "Philosophy of statistics". Стэнфордская энциклопедия философии.
- ^ "Кембриджский словарь".
- ^ Додж, Ю. (2006) Оксфордский словарь статистических терминов, Oxford University Press. ISBN 0-19-920613-9
- ^ Lund Research Ltd. "Descriptive and Inferential Statistics". statistics.laerd.com. Получено 2014-03-23.
- ^ "What Is the Difference Between Type I and Type II Hypothesis Testing Errors?". About.com Education. Получено 2015-11-27.
- ^ а б c Broemeling, Lyle D. (1 November 2011). "An Account of Early Statistical Inference in Arab Cryptology". Американский статистик. 65 (4): 255–257. Дои:10.1198/tas.2011.10191.
- ^ а б Сингх, Саймон (2000). The code book : the science of secrecy from ancient Egypt to quantum cryptography (1st Anchor Books ed.). Нью-Йорк: якорные книги. ISBN 978-0-385-49532-5.
- ^ а б Ibrahim A. Al-Kadi "The origins of cryptology: The Arab contributions", Криптология, 16(2) (April 1992) pp. 97–126.
- ^ "How to Calculate Descriptive Statistics". Answers Consulting. 2018-02-03.
- ^ Moses, Lincoln E. (1986) Think and Explain with Statistics, Addison-Wesley, ISBN 978-0-201-15619-5. стр. 1–3
- ^ Hays, William Lee, (1973) Statistics for the Social Sciences, Holt, Rinehart and Winston, p.xii, ISBN 978-0-03-077945-9
- ^ Moore, David (1992). "Teaching Statistics as a Respectable Subject". In F. Gordon; S. Gordon (eds.). Statistics for the Twenty-First Century. Washington, DC: The Mathematical Association of America. стр.14–25. ISBN 978-0-88385-078-7.
- ^ Chance, Beth L.; Rossman, Allan J. (2005). "Предисловие" (PDF). Investigating Statistical Concepts, Applications, and Methods. Duxbury Press. ISBN 978-0-495-05064-3.
- ^ Lakshmikantham, ed. by D. Kannan, V. (2002). Handbook of stochastic analysis and applications. Нью-Йорк: М. Деккер. ISBN 0824706609.CS1 maint: дополнительный текст: список авторов (связь)
- ^ Шервиш, Марк Дж. (1995). Theory of statistics (Corr. 2nd print. ed.). Нью-Йорк: Спрингер. ISBN 0387945466.
- ^ Willcox, Walter (1938) "The Founder of Statistics". Обзор International Statistical Institute 5(4): 321–328. JSTOR 1400906
- ^ J. Franklin, The Science of Conjecture: Evidence and Probability before Pascal, Johns Hopkins Univ Pr 2002
- ^ Helen Mary Walker (1975). Studies in the history of statistical method. Арно Пресс. ISBN 9780405066283.
- ^ Galton, F (1877). "Typical laws of heredity". Природа. 15 (388): 492–553. Bibcode:1877Natur..15..492.. Дои:10.1038/015492a0.
- ^ Stigler, S.M. (1989). "Francis Galton's Account of the Invention of Correlation". Статистическая наука. 4 (2): 73–79. Дои:10.1214/ss/1177012580.
- ^ Pearson, K. (1900). "On the Criterion that a given System of Deviations from the Probable in the Case of a Correlated System of Variables is such that it can be reasonably supposed to have arisen from Random Sampling". Философский журнал. Серия 5. 50 (302): 157–175. Дои:10.1080/14786440009463897.
- ^ "Karl Pearson (1857–1936)". Department of Statistical Science – Университетский колледж Лондона. Архивировано из оригинал на 2008-09-25.
- ^ Fisher|1971|loc=Chapter II. The Principles of Experimentation, Illustrated by a Psycho-physical Experiment, Section 8. The Null Hypothesis
- ^ OED quote: 1935 Р.А. Фишер, The Design of Experiments II. 19, "We may speak of this hypothesis as the 'null hypothesis', and the null hypothesis is never proved or established, but is possibly disproved, in the course of experimentation."
- ^ Box, JF (февраль 1980 г.). "R.A. Fisher and the Design of Experiments, 1922–1926". Американский статистик. 34 (1): 1–7. Дои:10.2307/2682986. JSTOR 2682986.
- ^ Yates, F (June 1964). «Сэр Рональд Фишер и план экспериментов». Биометрия. 20 (2): 307–321. Дои:10.2307/2528399. JSTOR 2528399.
- ^ Stanley, Julian C. (1966). "Влияние" Плана экспериментов "Фишера на образовательные исследования тридцать лет спустя". Американский журнал исследований в области образования. 3 (3): 223–229. Дои:10.3102/00028312003003223. JSTOR 1161806.
- ^ Агрести, Алан; David B. Hichcock (2005). "Bayesian Inference for Categorical Data Analysis" (PDF). Statistical Methods & Applications. 14 (3): 298. Дои:10.1007/s10260-005-0121-y.
- ^ Эдвардс, A.W.F. (1998). "Natural Selection and the Sex Ratio: Fisher's Sources". Американский натуралист. 151 (6): 564–569. Дои:10.1086/286141. PMID 18811377.
- ^ Fisher, R.A. (1915) The evolution of sexual preference. Eugenics Review (7) 184:192
- ^ Fisher, R.A. (1930) Генетическая теория естественного отбора. ISBN 0-19-850440-3
- ^ Эдвардс, A.W.F. (2000) Perspectives: Anecdotal, Historial and Critical Commentaries on Genetics. The Genetics Society of America (154) 1419:1426
- ^ Andersson, Malte (1994). Sexual Selection. Издательство Принстонского университета. ISBN 0-691-00057-3.
- ^ Andersson, M. and Simmons, L.W. (2006) Sexual selection and mate choice. Trends, Ecology and Evolution (21) 296:302
- ^ Gayon, J. (2010) Sexual selection: Another Darwinian process. Comptes Rendus Biologies (333) 134:144
- ^ Neyman, J (1934). "On the two different aspects of the representative method: The method of stratified sampling and the method of purposive selection". Журнал Королевского статистического общества. 97 (4): 557–625. Дои:10.2307/2342192. JSTOR 2342192.
- ^ "Science in a Complex World – Big Data: Opportunity or Threat?". Институт Санта-Фе.
- ^ Вольфрам, Стивен (2002). Новый вид науки. Wolfram Media, Inc. стр.1082. ISBN 1-57955-008-8.
- ^ Freedman, D.A. (2005) Statistical Models: Theory and Practice, Издательство Кембриджского университета. ISBN 978-0-521-67105-7
- ^ McCarney R, Warner J, Iliffe S, van Haselen R, Griffin M, Fisher P (2007). "The Hawthorne Effect: a randomised, controlled trial". BMC Med Res Methodol. 7 (1): 30. Дои:10.1186/1471-2288-7-30. ЧВК 1936999. PMID 17608932.
- ^ Ротман, Кеннет Дж; Greenland, Sander; Lash, Timothy, eds. (2008). «7». Modern Epidemiology (3-е изд.). Липпинкотт Уильямс и Уилкинс. п.100.
- ^ Мостеллер, Ф.; Tukey, J.W (1977). Анализ данных и регрессия. Бостон: Эддисон-Уэсли.
- ^ Нелдер, Дж. (1990). Знания, необходимые для компьютеризации анализа и интерпретации статистической информации. В Экспертные системы и искусственный интеллект: потребность в информации о данных. Отчет библиотечной ассоциации, Лондон, 23–27 марта.
- ^ Chrisman, Nicholas R (1998). "Rethinking Levels of Measurement for Cartography". Картография и географическая информатика. 25 (4): 231–242. Дои:10.1559/152304098782383043.
- ^ ван ден Берг, Г. (1991). Выбор метода анализа. Лейден: DSWO Press
- ^ Хэнд, Д.Дж. (2004). Теория и практика измерения: мир через количественную оценку. Лондон: Арнольд.
- ^ Mann, Prem S. (1995). Вводная статистика (2-е изд.). Вайли. ISBN 0-471-31009-3.
- ^ Upton, G., Cook, I. (2008) Oxford Dictionary of Statistics, OUP. ISBN 978-0-19-954145-4.
- ^ а б Piazza Elio, Probabilità e Statistica, Esculapio 2007
- ^ Everitt, Brian (1998). The Cambridge Dictionary of Statistics. Кембридж, Великобритания Нью-Йорк: Издательство Кембриджского университета. ISBN 0521593468.
- ^ "Cohen (1994) The Earth Is Round (p < .05)". YourStatsGuru.com.
- ^ Rubin, Donald B.; Little, Roderick J.A., Statistical analysis with missing data, New York: Wiley 2002
- ^ Ioannidis, J.P.A. (2005). «Почему большинство опубликованных результатов исследований ложны». PLOS Медицина. 2 (8): e124. Дои:10.1371 / journal.pmed.0020124. ЧВК 1182327. PMID 16060722.
- ^ а б c Huff, Darrell (1954) Как лгать со статистикой, WW Norton & Company, Inc. New York. ISBN 0-393-31072-8
- ^ Warne, R. Lazo; Ramos, T.; Ritter, N. (2012). "Statistical Methods Used in Gifted Education Journals, 2006–2010". Gifted Child Quarterly. 56 (3): 134–149. Дои:10.1177/0016986212444122.
- ^ а б Drennan, Robert D. (2008). "Statistics in archaeology". In Pearsall, Deborah M. (ed.). Encyclopedia of Archaeology. Elsevier Inc. pp.2093 –2100. ISBN 978-0-12-373962-9.
- ^ а б Cohen, Jerome B. (December 1938). "Misuse of Statistics". Журнал Американской статистической ассоциации. JSTOR. 33 (204): 657–674. Дои:10.1080/01621459.1938.10502344.
- ^ Freund, J.E. (1988). "Modern Elementary Statistics". Credo Reference.
- ^ Huff, Darrell; Irving Geis (1954). Как лгать со статистикой. Нью-Йорк: Нортон.
The dependability of a sample can be destroyed by [bias]... allow yourself some degree of skepticism.
- ^ Nikoletseas, M.M. (2014) "Statistics: Concepts and Examples." ISBN 978-1500815684
- ^ Anderson, D.R.; Sweeney, D.J.; Williams, T.A. (1994) Introduction to Statistics: Concepts and Applications, стр. 5–9. Западная группа. ISBN 978-0-314-03309-3
- ^ "Journal of Business & Economic Statistics". Журнал деловой и экономической статистики. Тейлор и Фрэнсис. Получено 16 марта 2020.
- ^ а б Natalia Loaiza Velásquez, María Isabel González Lutz & Julián Monge-Nájera (2011). "Which statistics should tropical biologists learn?" (PDF). Revista Biología Tropical. 59: 983–992.
- ^ Pekoz, Erol (2009). The Manager's Guide to Statistics. Erol Pekoz. ISBN 9780979570438.
дальнейшее чтение
- Lydia Denworth, "A Significant Problem: Standard scientific methods are under fire. Will anything change?", Scientific American, т. 321, нет. 4 (October 2019), pp. 62–67. "Использование п значения в течение почти столетия [с 1925 года], чтобы определить Статистическая значимость из экспериментальный результаты способствовали иллюзии уверенность и [к] кризисы воспроизводимости во многих научные области. There is growing determination to reform statistical analysis... Some [researchers] suggest changing statistical methods, whereas others would do away with a threshold for defining "significant" results." (p. 63.)
- Barbara Illowsky; Susan Dean (2014). Вводная статистика. OpenStax CNX. ISBN 9781938168208.
- Stockburger, David W. "Introductory Statistics: Concepts, Models, and Applications". Государственный университет Миссури (3rd Web ed.). Архивировано из оригинал on 28 May 2020.
- OpenIntro Statistics, 3rd edition by Diez, Barr, and Cetinkaya-Rundel
- Stephen Jones, 2010. Statistics in Psychology: Explanations without Equations. Пэлгрейв Макмиллан. ISBN 9781137282392.
- Cohen, J (1990). "Things I have learned (so far)" (PDF). Американский психолог. 45: 1304–1312. Дои:10.1037/0003-066x.45.12.1304. Архивировано из оригинал (PDF) on 2017-10-18.
- Gigerenzer, G (2004). "Mindless statistics". Социально-экономический журнал. 33: 587–606. Дои:10.1016/j.socec.2004.09.033.
- Ioannidis, J.P.A. (2005). "Why most published research findings are false". PLoS Медицина. 2: 696–701. Дои:10.1371/journal.pmed.0040168. ЧВК 1855693. PMID 17456002.
внешняя ссылка
- (Electronic Version): TIBCO Software Inc. (2020). Data Science Textbook.
- Online Statistics Education: An Interactive Multimedia Course of Study. Developed by Rice University (Lead Developer), University of Houston Clear Lake, Tufts University, and National Science Foundation.
- UCLA Statistical Computing Resources
- Philosophy of Statistics от Стэнфордская энциклопедия философии
| Фонды | |
|---|---|
| Алгебра | |
| Анализ | |
| Дискретный | |
| Геометрия | |
| Теория чисел | |
| Топология | |
| Применяемый | |
| Вычислительная | |
| похожие темы | |
| |