Медиана - Median

В статистика и теория вероятности, а медиана это значение, отделяющее верхнюю половину от нижней половины образец данных, а численность населения или распределение вероятностей. Для набор данных, его можно рассматривать как «среднее» значение. Основное преимущество медианы в описании данных по сравнению с иметь в виду (часто описываемый просто как «средний») заключается в том, что это не перекошенный так сильно на небольшую долю чрезвычайно больших или малых значений, и поэтому это может дать лучшее представление о «типичном» значении. Например, при понимании таких статистических данных, как доход или активы домохозяйства, которые сильно различаются, среднее значение может быть искажено небольшим количеством чрезвычайно высоких или низких значений. Средний доход, например, может быть лучшим способом предположить, что такое "типичный" доход. Из-за этого медиана имеет центральное значение в надежная статистика, так как это самый стойкая статистика, иметь точка разрушения 50%: пока не более половины данных загрязнены, медиана не даст произвольно большого или малого результата.
Конечный набор данных чисел
Медиана конечного списка чисел - это «среднее» число, когда эти числа перечислены в порядке от наименьшего к наибольшему.
Если количество наблюдений нечетное, выбирается среднее. Например, рассмотрим список чисел
- 1, 3, 3, 6, 7, 8, 9
В этом списке семь номеров. Медиана - четвертая из них, она равна 6.
Если имеется четное количество наблюдений, то единого среднего значения не существует; тогда медиана обычно определяется как иметь в виду двух средних значений.[1][2] Например, в наборе данных
- 1, 2, 3, 4, 5, 6, 8, 9
медиана - это среднее значение двух средних чисел: это , который . (В более технических терминах это интерпретирует медианное значение как полностью обрезанный средний диапазон ). При таком соглашении медиана может быть описана в виде без дела формула, как показано ниже:



куда упорядоченный список числа и и обозначить функции пола и потолка, соответственно.




| Тип | Описание | Пример | Результат |
|---|---|---|---|
| Среднее арифметическое | Сумма значений набора данных, деленная на количество значений: | (1 + 2 + 2 + 3 + 4 + 7 + 9) / 7 | 4 |
| Медиана | Среднее значение, разделяющее большую и меньшую половины набора данных | 1, 2, 2, 3, 4, 7, 9 | 3 |
| Режим | Наиболее частое значение в наборе данных | 1, 2, 2, 3, 4, 7, 9 | 2 |

Формальное определение
Формально медиана численность населения - любое значение, при котором не более половины населения меньше предлагаемой медианы, а не более половины больше предлагаемой медианы. Как видно выше, медианы не могут быть уникальными. Если каждый набор содержит менее половины генеральной совокупности, то некоторая часть совокупности точно равна уникальной медиане.
Медиана хорошо определена для любого упорядоченный (одномерные) данные и не зависят от каких-либо метрика расстояния. Таким образом, медиана может применяться к классам, которые ранжируются, но не числовыми (например, вычисление средней оценки, когда учащиеся оцениваются от A до F), хотя результат может быть посередине между классами, если имеется четное количество случаев.
А геометрическая медиана, с другой стороны, определяется в любом количестве измерений. Связанная концепция, в которой результат вынужден соответствовать члену выборки, - это медоид.
Общепринятого стандартного обозначения медианы не существует, но некоторые авторы представляют медианное значение переменной. Икс либо как Икс или как μ1/2[1] иногда также M.[3][4] В любом из этих случаев использование тех или иных символов для медианы должно быть явно определено при их введении.
Медиана - это частный случай других способы обобщения типичных значений, связанных со статистическим распределением: это 2-й квартиль, 5-я дециль, и 50-е процентиль.
Использует
Медиану можно использовать как меру место расположения когда придают меньшее значение экстремальным значениям, обычно потому, что распределение перекошенный, экстремальные значения неизвестны, или выбросы ненадежны, т. е. могут быть ошибки измерения / транскрипции.
Например, рассмотрим мультимножество
- 1, 2, 2, 2, 3, 14.
В этом случае медиана равна 2 (как и Режим ), и это можно было бы рассматривать как лучшее указание на центр чем среднее арифметическое 4, что больше, чем все значения, кроме одного. Однако широко цитируемое эмпирическое соотношение, согласно которому среднее смещается «дальше в хвост» распределения, чем медиана, в целом неверно. В лучшем случае можно сказать, что эти две статистики не могут быть «слишком далеко» друг от друга; видеть § Неравенство в отношении средних и средних значений ниже.[5]
Поскольку медиана основана на средних данных в наборе, нет необходимости знать значение крайних результатов для ее вычисления. Например, в психологическом тесте, изучающем время, необходимое для решения проблемы, если небольшое количество людей вообще не смогли решить проблему за заданное время, можно вычислить медианное значение.[6]
Поскольку медиана проста для понимания и расчета, а также является надежным приближением к иметь в виду, медиана - популярный сводная статистика в описательная статистика. В этом контексте есть несколько вариантов измерения изменчивость: the классифицировать, то межквартильный размах, то среднее абсолютное отклонение, а среднее абсолютное отклонение.
Для практических целей различные меры местоположения и дисперсии часто сравниваются на основе того, насколько хорошо соответствующие значения совокупности могут быть оценены на основе выборки данных. Медиана, рассчитанная с использованием медианы выборки, имеет в этом отношении хорошие свойства. Хотя обычно предполагается, что данное распределение населения не является оптимальным, его свойства всегда достаточно хорошие. Например, сравнение эффективность кандидатов в оценщики показывает, что выборочное среднее более статистически эффективно когда - и только когда - данные не загрязнены данными из распределений с тяжелым хвостом или из смесей распределений.[нужна цитата ] Даже в этом случае медиана имеет эффективность 64% по сравнению со средним значением с минимальной дисперсией (для больших нормальных выборок), то есть дисперсия медианы будет на ~ 50% больше, чем дисперсия среднего.[7][8]
Распределения вероятностей

Для любого настоящий -значен распределение вероятностей с кумулятивная функция распределения F, медиана определяется как любое действительное числом что удовлетворяет неравенствам
- .
![{displaystyle int _ {(- infty, m]} dF (x) geq {frac {1} {2}} {ext {and}} int _ {[m, infty)} dF (x) geq {frac {1 } {2}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c490b959f69a76debf7ab4ece5e891a3a9bd2e47)
В эквивалентной фразе используется случайная величина Икс распределен согласно F:

Обратите внимание, что это определение не требует Икс иметь абсолютно непрерывное распределение (который имеет функция плотности вероятности ƒ), и не требует дискретный. В первом случае неравенства могут быть увеличены до равенства: медиана удовлетворяет
- .

Любой распределение вероятностей на р имеет хотя бы одну медиану, но в патологических случаях может быть более одной медианы: если F постоянна 1/2 на интервале (так что ƒ= 0), то любое значение этого интервала является медианой.
Медианы отдельных распределений
Медианы некоторых типов распределений могут быть легко вычислены по их параметрам; более того, они существуют даже для некоторых дистрибутивов, не имеющих четко определенного среднего значения, таких как Распределение Коши:
- Медиана симметричного одномодальное распределение совпадает с режимом.
- Медиана симметричное распределение который обладает средним μ также принимает значение μ.
- Медиана нормальное распределение со средним μ и дисперсия σ2 есть μ. Фактически, для нормального распределения среднее значение = медиана = мода.
- Медиана равномерное распределение в интервале [а, б] является (а + б) / 2, которое также является средним.
- Медиана Распределение Коши с параметром местоположения Икс0 и масштабный параметр у являетсяИкс0, параметр местоположения.
- Медиана распределение по степенному закону Икс−а, с показателем а > 1 равно 21/(а − 1)Иксмин, куда Иксмин - минимальное значение, при котором выполняется степенной закон[10]
- Медиана экспоненциальное распределение с параметр скорости λ - натуральный логарифм 2, деленный на параметр скорости: λ−1пер 2.
- Медиана Распределение Вейбулла с параметром формы k и масштабный параметр λ являетсяλ(пер. 2)1/k.
Населения
Свойство оптимальности
В средняя абсолютная ошибка реальной переменной c с уважением к случайная переменная Икс является

При условии, что распределение вероятностей Икс такова, что указанное выше ожидание существует, то м является средним значением Икс если и только если м является минимизатором средней абсолютной ошибки относительно Икс.[11] Особенно, м является выборочной медианой тогда и только тогда, когда м минимизирует среднее арифметическое абсолютных отклонений.[12]
В более общем смысле медиана определяется как минимум

как описано ниже в разделе о многомерные медианы (в частности, пространственная медиана ).
Это основанное на оптимизации определение медианы полезно при статистическом анализе данных, например, в kкластеризация медианы.
Неравенство в отношении средних и медиан
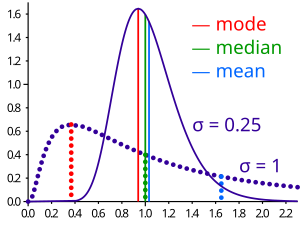
Если распределение имеет конечную дисперсию, то расстояние между медианными и среднее ограничен одним стандартное отклонение.


Эта оценка была доказана Мэллоусом,[13] кто использовал Неравенство Дженсена дважды, следующим образом. Использование | · | для абсолютная величина, у нас есть

Первое и третье неравенства происходят из неравенства Дженсена, примененного к функции абсолютного значения и функции квадрата, каждая из которых является выпуклой. Второе неравенство возникает из-за того, что медиана минимизирует абсолютное отклонение функция .

Доказательство Маллоуса можно обобщить для получения многомерной версии неравенства[14] просто заменив абсолютное значение на норма:

куда м это пространственная медиана, то есть минимизатор функции Пространственная медиана уникальна, если размерность набора данных равна двум или более.[15][16]

Альтернативное доказательство использует одностороннее неравенство Чебышева; это появляется в неравенство по локационным и масштабным параметрам. Эта формула также непосредственно следует из Неравенство Кантелли.[17]
Унимодальные распределения
В случае одномодальный распределений, можно получить более точную оценку расстояния между медианой и средним значением:
- .[18]

Аналогичная связь существует между медианой и модой:

Неравенство Дженсена для медиан
Неравенство Дженсена утверждает, что для любой случайной величины Икс с конечным ожиданием E[Икс] и для любой выпуклой функции ж
![{displaystyle f [E (x)] leq E [f (x)]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1874d0eeb97b95fcab3c70f25df212e2cb4af2d2)
Это неравенство распространяется и на медианное значение. Мы говорим функцию f: ℝ → ℝ это Функция C если для любого т,
![{displaystyle f ^ {- 1} left (, (- infty, t], ight) = {xin mathbb {R} mid f (x) leq t}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0bb6a4a02d8480c441a0f73bea93cc4fffb9b08d)
это закрытый интервал (с учетом вырожденных случаев единственная точка или пустой набор ). Каждая функция C выпукла, но обратное неверно. Если ж является C-функцией, то
![{displaystyle f (OperatorName {Median} [X]) leq operatorname {Median} [f (X)]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/71d1c1e4434b41fe5617b85c49b2e9d308c8a1a3)
Если медианы не уникальны, утверждение верно для соответствующей супремы.[19]
Медианы для образцов
Медиана выборки
Эффективное вычисление медианы выборки
Хотя сравнение-сортировка п предметы требует Ω (п бревно п) операции, алгоритмы выбора может вычислить kth-самый маленький из п Предметы только с Θ (п) операции. Сюда входит медиана, которая является п/2статистика-го порядка (или для четного числа выборок среднее арифметическое двух статистик среднего порядка).[20]
У алгоритмов выбора есть обратная сторона: Ω (п) память, то есть они должны иметь полную выборку (или ее часть линейного размера) в памяти. Поскольку это, а также требование линейного времени может быть недопустимым, было разработано несколько процедур оценки медианы. Простое правило - это правило трех элементов, которое оценивает медиану как медиану трехэлементной подвыборки; это обычно используется как подпрограмма в быстрая сортировка алгоритм сортировки, который использует оценку медианы входных данных. Более того робастная оценка является Tukey с девятый, которая является медианной из трех правил, применяемых с ограниченной рекурсией:[21] если А образец выложен как множество, и
- med3 (А) = медиана (А[1], А[п/2], А[п]),
тогда
- девятый (А) = med3 (med3 (А[1 ... 1/3п]), med3 (А[1/3п ... 2/3п]), med3 (А[2/3п ... п]))
В средство - это средство оценки медианы, которое требует линейного времени, но сублинейной памяти, работающей за один проход по выборке.[22]
Выборочное распределение
Распределение как среднего по выборке, так и медианы по выборке определялось Лаплас.[23] Распределение медианы выборки из совокупности с функцией плотности асимптотически нормально со средним и дисперсия[24]



куда это медиана и размер выборки. Современное доказательство следует ниже. Результат Лапласа теперь понимается как частный случай асимптотическое распределение произвольных квантилей.
Для нормальных образцов плотность составляет , таким образом, для больших выборок дисперсия медианы равна [7] (См. Также раздел #Эффективность ниже.)


Вывод асимптотического распределения.
Мы принимаем размер выборки за нечетное число и предположим, что наша переменная непрерывна; формула для случая дискретных переменных приведена ниже в § Эмпирическая локальная плотность. Выборку можно резюмировать как «ниже медианы», «на медиане» и «выше медианы», что соответствует трехчленному распределению с вероятностями. , и . Для непрерывной переменной вероятность того, что несколько значений выборки будут точно равны медиане, равна 0, поэтому можно вычислить плотность в точке непосредственно из трехчленного распределения:





- .
![{displaystyle Pr [OperatorName {Median} = v], dv = {frac {(2n + 1)!} {n! n!}} F (v) ^ {n} (1-F (v)) ^ {n } f (v), dv}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b99f214189b2882487bfbae7997046efa4a88cc4)
Теперь мы вводим бета-функцию. Для целочисленных аргументов и , это можно выразить как . Напомним также, что . Используя эти отношения и устанавливая оба и равно позволяет записать последнее выражение как






Следовательно, функция плотности медианы представляет собой симметричное бета-распределение толкнул вперед к . Его среднее значение, как и следовало ожидать, составляет 0,5, а его дисперсия составляет . Посредством Правило цепи, соответствующая дисперсия медианы выборки равна


- .

Дополнительные 2 незначительны в пределе.
Эмпирическая локальная плотность
На практике функции и часто не известны или не предполагаются. Однако их можно оценить по наблюдаемому частотному распределению. В этом разделе мы приводим пример. Рассмотрим следующую таблицу, представляющую выборку из 3800 (дискретных) наблюдений:

| v | 0 | 0.5 | 1 | 1.5 | 2 | 2.5 | 3 | 3.5 | 4 | 4.5 | 5 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| f (v) | 0.000 | 0.008 | 0.010 | 0.013 | 0.083 | 0.108 | 0.328 | 0.220 | 0.202 | 0.023 | 0.005 |
| F (v) | 0.000 | 0.008 | 0.018 | 0.031 | 0.114 | 0.222 | 0.550 | 0.770 | 0.972 | 0.995 | 1.000 |
Поскольку наблюдения имеют дискретные значения, построение точного распределения медианы не является немедленным переводом приведенного выше выражения для ; можно (и обычно имеет) несколько экземпляров медианы в одной выборке. Итак, мы должны суммировать все эти возможности:


Здесь, я количество точек строго меньше медианы и k число строго больше.
Используя эти предварительные сведения, можно исследовать влияние размера выборки на стандартные ошибки среднего и медианы. Наблюдаемое среднее значение составляет 3,16, наблюдаемая необработанная медиана - 3, а наблюдаемая интерполированная медиана - 3,174. Следующая таблица дает некоторую статистику сравнения.
Размер образца Статистика | 3 | 9 | 15 | 21 |
|---|---|---|---|---|
| Ожидаемое значение медианы | 3.198 | 3.191 | 3.174 | 3.161 |
| Стандартная ошибка медианы (формула выше) | 0.482 | 0.305 | 0.257 | 0.239 |
| Стандартная ошибка медианы (асимптотическое приближение) | 0.879 | 0.508 | 0.393 | 0.332 |
| Стандартная ошибка среднего | 0.421 | 0.243 | 0.188 | 0.159 |
Ожидаемое значение медианы немного уменьшается по мере увеличения размера выборки, в то время как, как и следовало ожидать, стандартные ошибки медианы и среднего пропорциональны обратному квадратному корню из размера выборки. Асимптотическое приближение проявляет осторожность из-за переоценки стандартной ошибки.
Оценка отклонения от выборочных данных
Значение - асимптотическое значение куда медиана населения - изучалась несколькими авторами. Стандартный "удалить один" складной нож метод производит непоследовательный полученные результаты.[25] Альтернатива - метод «удалить k» - где растет с размером выборки, асимптотически согласована.[26] Этот метод может быть дорогостоящим для больших наборов данных. Известно, что оценка бутстрапа непротиворечива,[27] но сходится очень медленно (порядок из ).[28] Были предложены другие методы, но их поведение может отличаться для больших и малых выборок.[29]





Эффективность
В эффективность медианы выборки, измеряемой как отношение дисперсии среднего к дисперсии медианы, зависит от размера выборки и основного распределения населения. За образец размера от нормальное распределение, эффективность при больших N равна

Эффективность стремится к в качестве стремится к бесконечности.


Другими словами, относительная дисперсия медианы будет , или на 57% больше дисперсии среднего - относительного стандартная ошибка медианы будет , или на 25% больше, чем стандартная ошибка среднего, (см. также раздел #Выборочное распределение над.).[30]



Другие оценщики
Для одномерных распределений, которые симметричный около одной медианы, Оценка Ходжеса – Лемана это крепкий и очень эффективный оценщик медианы населения.[31]
Если данные представлены статистическая модель с указанием конкретной семьи распределения вероятностей, то оценки медианы могут быть получены путем подгонки этого семейства распределений вероятностей к данным и вычисления теоретической медианы подобранного распределения.[нужна цитата ] Интерполяция Парето это приложение, когда предполагается, что у населения есть Распределение Парето.
Многомерная медиана
Ранее в этой статье обсуждалась одномерная медиана, когда выборка или совокупность были одномерными. Когда размерность равна двум или выше, существует несколько концепций, расширяющих определение одномерной медианы; каждая такая многомерная медиана согласуется с одномерной медианной, когда размерность ровно одна.[31][32][33][34]
Маргинальная медиана
Маргинальная медиана определяется для векторов, определенных относительно фиксированного набора координат. Маргинальная медиана определяется как вектор, компоненты которого являются одномерными медианами. Маргинальную медиану легко вычислить, и ее свойства были изучены Пури и Сеном.[31][35]
Геометрическая медиана
В геометрическая медиана дискретного набора точек выборки в евклидовом пространстве[а] точка, минимизирующая сумму расстояний до точек выборки.


В отличие от маргинальной медианы геометрическая медиана равна эквивариантный относительно евклидова преобразования подобия Такие как переводы и вращения.
Центральная точка
Альтернативным обобщением медианы в более высоких измерениях является Центральная точка.
Интерполированная медиана
При работе с дискретной переменной иногда полезно рассматривать наблюдаемые значения как средние точки лежащих в основе непрерывных интервалов. Примером этого является шкала Лайкерта, по которой мнения или предпочтения выражаются по шкале с заданным количеством возможных ответов. Если шкала состоит из положительных целых чисел, наблюдение 3 можно рассматривать как интервал от 2,50 до 3,50.Можно оценить медианное значение базовой переменной. Если, скажем, 22% наблюдений имеют значение 2 или ниже и 55,0% имеют значение 3 или ниже (поэтому 33% имеют значение 3), то медиана равно 3, так как медиана - это наименьшее значение для которого больше половины. Но интерполированная медиана находится где-то между 2,50 и 3,50. Сначала добавляем половину ширины интервала к медиане, чтобы получить верхнюю границу медианного интервала. Затем мы вычитаем ту долю ширины интервала, которая равна доле 33%, лежащих выше отметки 50%. Другими словами, мы делим ширину интервала пропорционально количеству наблюдений. В этом случае 33% делятся на 28% ниже медианы и 5% выше нее, поэтому мы вычитаем 5/33 ширины интервала из верхней границы 3,50, чтобы получить интерполированное медианное значение 3,35. Более формально, если значения известны, интерполированная медиана может быть вычислена из


![{displaystyle m_ {ext {int}} = m + wleft [{frac {1} {2}} - {frac {F (m) - {frac {1} {2}}} {f (m)}} полет ].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5e823608d9eba650d4796825d3043ef41d06370e)
В качестве альтернативы, если в наблюдаемом образце есть баллы выше средней категории, оценки в нем и баллов ниже этого значения, то интерполированная медиана равна


![{displaystyle m_ {ext {int}} = m- {frac {w} {2}} left [{frac {k-i} {j}} ight].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2880593c3a1fd9d8346af9aa8c2be6d83da114b3)
Псевдо-медиана
Для одномерных распределений, которые симметричный около одной медианы, Оценка Ходжеса – Лемана является надежным и высокоэффективным средством оценки медианы населения; для несимметричных распределений оценка Ходжеса – Лемана является надежной и высокоэффективной оценкой совокупности псевдо-медиана, которое является медианой симметризованного распределения и близко к медиане совокупности.[37] Оценка Ходжеса – Лемана была обобщена на многомерные распределения.[38]
Варианты регресса
В Оценка Тейла – Сена это метод для крепкий линейная регрессия на основе определения медиан склоны.[39]
Медианный фильтр
В контексте обработка изображений из монохромный растровые изображения есть тип шума, известный как соль и перец шум, когда каждый пиксель независимо становится черным (с некоторой малой вероятностью) или белым (с некоторой малой вероятностью), и не изменяется в противном случае (с вероятностью, близкой к 1). Изображение, построенное из средних значений окрестностей (например, квадрат 3 × 3), может эффективно снизить уровень шума в этом случае.[нужна цитата ]
Кластерный анализ
В кластерный анализ, то k-medians кластеризация Алгоритм обеспечивает способ определения кластеров, в котором критерий максимизации расстояния между кластерными средствами, который используется в k-означает кластеризацию, заменяется максимальным расстоянием между медианными кластерами.
Срединно-срединная линия
Это метод надежной регрессии. Идея восходит к Вальд в 1940 году, который предложил разделить набор двумерных данных на две половины в зависимости от значения независимого параметра : левая половина со значениями меньше медианы и правая половина со значениями больше медианы.[40] Он предложил воспользоваться средствами зависимых и независимый переменные левой и правой половин и оценка наклона линии, соединяющей эти две точки. Затем линию можно было бы скорректировать, чтобы она соответствовала большинству точек в наборе данных.

Наир и Шривастава в 1942 г. предложили аналогичную идею, но вместо этого выступили за разделение выборки на три равные части перед вычислением средних значений подвыборок.[41] Браун и Муд в 1951 году предложили идею использования медиан двух подвыборок, а не средних.[42] Тьюки объединил эти идеи и рекомендовал разделить выборку на три подвыборки равного размера и оценить линию на основе медиан подвыборок.[43]
Средне-несмещенные оценки
Любой иметь в видуобъективная оценка сводит к минимуму рисковать (ожидаемый убыток ) относительно квадрата ошибки функция потерь, как заметил Гаусс. А медианаобъективная оценка сводит к минимуму риск в отношении абсолютное отклонение функция потерь, как наблюдается Лаплас. Другой функции потерь используются в статистическая теория, особенно в надежная статистика.
Теория медиан-несмещенных оценок была возрождена Джордж У. Браун в 1947 г .:[44]
Оценка одномерного параметра θ будет называться несмещенной по медиане, если для фиксированного θ медиана распределения оценки находится на значении θ; т.е. оценка занижается так же часто, как и завышается. Для большинства целей это требование выполняет столько же, сколько и требование несмещенного среднего, и обладает дополнительным свойством, состоящим в том, что оно инвариантно относительно однозначного преобразования.
— стр. 584
Сообщалось о других свойствах средне-несмещенных оценок.[45][46][47][48] Несмещенные по медиане оценки инвариантны относительно однозначные преобразования.
Существуют методы построения оптимальных оценок без смещения по медиане (в некотором смысле аналогичные свойству минимальной дисперсии для оценок с несмещенным средним). Такие конструкции существуют для вероятностных распределений, имеющих монотонные функции правдоподобия.[49][50] Одна такая процедура является аналогом Процедура Рао – Блэквелла для оценок со средним несмещением: процедура выполняется для меньшего класса распределений вероятностей, чем процедура Рао-Блэквелла, но для большего класса функции потерь.[51]
История
Научные исследователи на древнем Ближнем Востоке, похоже, не использовали сводную статистику в целом, вместо этого выбирая значения, которые предлагали максимальную согласованность с более широкой теорией, объединяющей широкий спектр явлений.[52] В рамках средиземноморского (а затем и европейского) научного сообщества статистика, такая как среднее значение, по сути, является развитием средневековья и раннего Нового времени. (История медианы за пределами Европы и ее предшественников остается относительно неизученной.)
Идея медианы возникла в XIII веке в Талмуд, чтобы справедливо проанализировать расходящиеся оценки.[53][54] Однако эта концепция не распространилась на более широкое научное сообщество.
Вместо этого ближайшим предком современной медианы является средний диапазон, изобретенный Аль-Бируни.[55]:31[56] Передача работ Аль-Бируни более поздним ученым неясна. Аль-Бируни применил свою технику к анализ металлов, но после того, как он опубликовал свою работу, большинство аналитиков по-прежнему принимали самые неблагоприятные значения своих результатов, чтобы они не казались изменять.[55]:35–8 Однако усиление судоходства в море во время Эпоха открытий означало, что судоводителям все чаще приходилось пытаться определять широту в неблагоприятную погоду против враждебных берегов, что привело к возобновлению интереса к сводной статистике. Независимо от того, открыт ли он заново или изобретен независимо, он рекомендован морским мореплавателям в «Инструкциях к путешествию Рэли в Гвиану 1595 года».[55]:45–8
Идея медианы, возможно, впервые появилась в Эдвард Райт книга 1599 года Определенные ошибки в навигации в разделе о компас навигация. Райт не хотел отказываться от измеренных значений и, возможно, чувствовал, что медиана, включающая большую часть набора данных, чем средний диапазон - был более правым. Однако Райт не привел примеров использования своей техники, что затрудняет проверку того, что он описал современное понятие медианы.[52][56][b] Медиана (в контексте вероятности) определенно фигурирует в соответствии Кристиан Гюйгенс, но как пример статистики, не подходящей для актуарная практика.[52]
Самая ранняя рекомендация медианы датируется 1757 годом, когда Роджер Джозеф Боскович разработал метод регрессии на основе L1 норма и, следовательно, неявно на медиане.[52][57] В 1774 г. Лаплас сделал это желание явным: он предложил использовать медиану в качестве стандартной оценки значения апостериорной PDF. Конкретный критерий заключался в минимизации ожидаемой величины ошибки; куда оценка и истинное значение. С этой целью Лаплас определил распределения как выборочного среднего, так и выборочного медианного в начале 1800-х годов.[23][58] Однако десять лет спустя Гаусс и Legendre разработал наименьших квадратов метод, который минимизирует чтобы получить среднее значение. В контексте регрессии инновация Гаусса и Лежандра предлагает гораздо более простые вычисления. Следовательно, предложение Лапласа обычно отклонялось до тех пор, пока вычислительные устройства 150 лет спустя (и это все еще относительно необычный алгоритм).[59]



Антуан Огюстен Курно в 1843 г. был первый[60] использовать термин медиана (Валер Медиан) для значения, которое делит распределение вероятностей на две равные половины. Густав Теодор Фехнер использовали медианное значение (Centralwerth) в социологических и психологических явлениях.[61] Ранее он использовался только в астрономии и смежных областях. Густав Фехнер популяризировал медиану в формальном анализе данных, хотя ранее она использовалась Лапласом,[61] а медиана появилась в учебнике Ф. Я. Эджворт.[62] Фрэнсис Гальтон использовал английский термин медиана в 1881 г.,[63][64] использовав ранее термины среднее значение в 1869 г., а средний в 1880 г.[65][66]
Статистики активно поощряли использование медиан на протяжении всего XIX века из-за их интуитивной ясности и простоты вычислений вручную. Однако понятие медианы не поддается теории высших моментов, а также теории высших моментов. среднее арифметическое делает, и его гораздо труднее вычислить на компьютере. В результате в течение 20 века медиана неуклонно вытеснялась как понятие общего среднего средним арифметическим.[52][56]
Смотрите также
- Медоиды которые являются обобщением медианы в более высоких измерениях
- Основная тенденция
- Абсолютное отклонение
- Смещение оценщика
- Концентрация меры за Липшицевы функции
- Медиана (геометрия)
- Медианный график
- Медианный поиск
- Средний наклон
- Теория медианного избирателя
- Взвешенная медиана
Примечания
- ^ Геометрическая медиана уникальна, если образец не коллинеарен.[36]
- ^ Последующие исследователи, похоже, соглашаются с Эйзенхартом в том, что цифры 1580 г. Бороу, хотя и предполагают медианное значение, на самом деле описывают среднее арифметическое;[55]:62–3 Ни в одном другом произведении «Районы» не упоминаются.
Рекомендации
- ^ а б Вайсштейн, Эрик В. «Статистическая медиана». MathWorld.
- ^ Саймон, Лаура Дж .; "Описательная статистика" В архиве 2010-07-30 на Wayback Machine, Комплект статистических образовательных ресурсов, Государственный департамент статистики Пенсильвании
- ^ Дэвид Дж. Шескин (27 августа 2003 г.). Справочник по параметрическим и непараметрическим статистическим процедурам: третье издание. CRC Press. С. 7–. ISBN 978-1-4200-3626-8. Получено 25 февраля 2013.
- ^ Дерек Бисселл (1994). Статистические методы для Spc и Tqm. CRC Press. С. 26–. ISBN 978-0-412-39440-9. Получено 25 февраля 2013.
- ^ "Журнал статистического образования, v13n2: Пол Т. фон Хиппель". amstat.org.
- ^ Робсон, Колин (1994). Эксперимент, дизайн и статистика в психологии. Пингвин. С. 42–45. ISBN 0-14-017648-9.
- ^ а б Уильямс, Д. (2001). Взвешивая шансы. Издательство Кембриджского университета. п.165. ISBN 052100618X.
- ^ Майндональд, Джон; Браун, У. Джон (06.05.2010). Анализ данных и графики с использованием R: подход на основе примеров. Издательство Кембриджского университета. п. 104. ISBN 978-1-139-48667-5.
- ^ «Обзор статистики AP - кривые плотности и нормальные распределения». Архивировано из оригинал 8 апреля 2015 г.. Получено 16 марта 2015.
- ^ Ньюман, Марк EJ. «Степенные законы, распределения Парето и закон Ципфа». Современная физика 46.5 (2005): 323–351.
- ^ Строок, Дэниел (2011). Теория вероятности. Издательство Кембриджского университета. стр.43. ISBN 978-0-521-13250-3.
- ^ Андре Николя (https://math.stackexchange.com/users/6312/andr%c3%a9-nicolas ), Медиана минимизирует сумму абсолютных отклонений (норма $ {L} _ {1} $), URL (версия: 2012-02-25): https://math.stackexchange.com/q/113336
- ^ Мальвы, Колин (август 1991). «Еще один комментарий к О'Синнейде». Американский статистик. 45 (3): 257. Дои:10.1080/00031305.1991.10475815.
- ^ Пиш, Роберт (2012). Случайные векторы и случайные последовательности. Lambert Academic Publishing. ISBN 978-3659211966.
- ^ Кемперман, Йоханнес Х. Б. (1987). Додж, Ядола (ред.). «Медиана конечной меры в банаховом пространстве: статистический анализ данных на основе L1-нормы и связанных методов». Материалы Первой международной конференции, состоявшейся в Невшателе 31 августа - 4 сентября 1987 г.. Амстердам: North-Holland Publishing Co .: 217–230. МИСТЕР 0949228.CS1 maint: ref = harv (связь)
- ^ Милашевич, Филипп; Дюшарм, Жиль Р. (1987). «Уникальность пространственной медианы». Анналы статистики. 15 (3): 1332–1333. Дои:10.1214 / aos / 1176350511. МИСТЕР 0902264.CS1 maint: ref = harv (связь)
- ^ К. Ван Стин Заметки о вероятности и статистике
- ^ Basu, S .; Дасгупта, А. (1997). «Среднее, медианное и режим одномодальных распределений: характеристика». Теория вероятностей и ее приложения. 41 (2): 210–223. Дои:10.1137 / S0040585X97975447. S2CID 54593178.
- ^ Меркл, М. (2005). «Неравенство Дженсена для медиан». Письма о статистике и вероятности. 71 (3): 277–281. Дои:10.1016 / j.spl.2004.11.010.
- ^ Альфред В. Ахо, Джон Э. Хопкрофт и Джеффри Д. Ульман (1974). Разработка и анализ компьютерных алгоритмов. Ридинг / МА: Эддисон-Уэсли. ISBN 0-201-00029-6. Здесь: Раздел 3.6 «Статистика заказов», стр.97-99, в частности алгоритм 3.6 и теорема 3.9.
- ^ Бентли, Джон Л .; Макилрой, М. Дуглас (1993). «Разработка функции сортировки». Программное обеспечение - практика и опыт. 23 (11): 1249–1265. Дои:10.1002 / spe.4380231105. S2CID 8822797.
- ^ Rousseeuw, Peter J .; Бассетт, Гилберт В. младший (1990). «Средство исправления: надежный метод усреднения для больших наборов данных» (PDF). J. Amer. Статист. Assoc. 85 (409): 97–104. Дои:10.1080/01621459.1990.10475311.
- ^ а б Стиглер, Стивен (Декабрь 1973 г.). «Исследования по истории вероятности и статистики. XXXII: Лаплас, Фишер и открытие концепции достаточности». Биометрика. 60 (3): 439–445. Дои:10.1093 / biomet / 60.3.439. JSTOR 2334992. МИСТЕР 0326872.
- ^ Райдер, Пол Р. (1960). «Дисперсия медианы небольших выборок из нескольких особых популяций». J. Amer. Статист. Доц. 55 (289): 148–150. Дои:10.1080/01621459.1960.10482056.
- ^ Ефрон, Б. (1982). Складной нож, бутстрап и другие планы передискретизации. Филадельфия: СИАМ. ISBN 0898711797.
- ^ Shao, J .; Ву, К. Ф. (1989). «Общая теория для оценки дисперсии складного ножа». Анна. Стат. 17 (3): 1176–1197. Дои:10.1214 / aos / 1176347263. JSTOR 2241717.
- ^ Ефрон, Б. (1979). «Методы начальной загрузки: новый взгляд на складной нож». Анна. Стат. 7 (1): 1–26. Дои:10.1214 / aos / 1176344552. JSTOR 2958830.
- ^ Холл, П .; Мартин, М. А. (1988). «Точная скорость сходимости оценки отклонения квантиля начальной загрузки». Области, связанные с теорией вероятностей. 80 (2): 261–268. Дои:10.1007 / BF00356105. S2CID 119701556.
- ^ Хименес-Гамеро, M.D .; Munoz-García, J .; Пино-Мехиас, Р. (2004). «Уменьшенный бутстрап для медианы». Statistica Sinica. 14 (4): 1179–1198.
- ^ Майндональд, Джон; Джон Браун, В. (06.05.2010). Анализ данных и графики с использованием R: подход на основе примеров. ISBN 9781139486675.
- ^ а б c Hettmansperger, Thomas P .; Маккин, Джозеф В. (1998). Надежные непараметрические статистические методы. Библиотека статистики Кендалла. 5. Лондон: Эдвард Арнольд. ISBN 0-340-54937-8. МИСТЕР 1604954.CS1 maint: ref = harv (связь)
- ^ Смолл, Кристофер Г. «Обзор многомерных медиан». Международный статистический обзор / Revue Internationale de Statistique (1990): 263–277. Дои:10.2307/1403809 JSTOR 1403809
- ^ Ниинимаа А. и Х. Оджа. «Многомерная медиана». Энциклопедия статистических наук (1999).
- ^ Мослер, Карл. Многомерная дисперсия, центральные области и глубина: подход зоноида подъемной силы. Vol. 165. Springer Science & Business Media, 2012.
- ^ Puri, Madan L .; Sen, Pranab K .; Непараметрические методы в многомерном анализе, John Wiley & Sons, Нью-Йорк, Нью-Йорк, 197л. (Перепечатано издательством Krieger Publishing)
- ^ Варди, Иегуда; Чжан, Цунь-Хуэй (2000). "Многовариантный L1-средняя и связанная глубина данных ". Труды Национальной академии наук Соединенных Штатов Америки. 97 (4): 1423–1426 (электронный). Bibcode:2000PNAS ... 97,1423 В. Дои:10.1073 / pnas.97.4.1423. МИСТЕР 1740461. ЧВК 26449. PMID 10677477.CS1 maint: ref = harv (связь)
- ^ Пратт, Уильям К .; Купер, Тед Дж .; Кабир, Ихтишам (11 июля 1985 г.). Корбетт, Фрэнсис Дж (ред.). «Псевдомедианный фильтр». Архитектуры и алгоритмы обработки цифровых изображений II. 0534: 34. Bibcode:1985SPIE..534 ... 34P. Дои:10.1117/12.946562. S2CID 173183609.
- ^ Оя, Ханну (2010). Многомерные непараметрические методы ср: Подход, основанный на пространственных знаках и рангах.. Конспект лекций по статистике. 199. Нью-Йорк, штат Нью-Йорк: Спрингер. С. xiv + 232. Дои:10.1007/978-1-4419-0468-3. ISBN 978-1-4419-0467-6. МИСТЕР 2598854.CS1 maint: ref = harv (связь)
- ^ Уилкокс, Рэнд Р. (2001), «Оценка Тейла – Сена», Основы современных статистических методов: существенное повышение мощности и точности, Springer-Verlag, стр. 207–210, ISBN 978-0-387-95157-7.
- ^ Вальд, А. (1940). «Подбор прямых линий, если обе переменные подвержены ошибке» (PDF). Анналы математической статистики. 11 (3): 282–300. Дои:10.1214 / aoms / 1177731868. JSTOR 2235677.
- ^ Nair, K. R .; Шривастава, М. П. (1942). «О простом методе аппроксимации кривой». Санкхья: Индийский статистический журнал. 6 (2): 121–132. JSTOR 25047749.
- ^ Brown, G.W .; Настроение, А. М. (1951). «О медианных тестах для линейных гипотез». Материалы второго симпозиума в Беркли по математической статистике и теории вероятностей. Беркли, Калифорния: Калифорнийский университет Press. С. 159–166. Zbl 0045.08606.
- ^ Тьюки, Дж. У. (1977). Исследовательский анализ данных. Ридинг, Массачусетс: Эддисон-Уэсли. ISBN 0201076160.
- ^ Браун, Джордж У. (1947). «Об оценке по малой выборке». Анналы математической статистики. 18 (4): 582–585. Дои:10.1214 / aoms / 1177730349. JSTOR 2236236.
- ^ Леманн, Эрих Л. (1951). «Общее понятие беспристрастности». Анналы математической статистики. 22 (4): 587–592. Дои:10.1214 / aoms / 1177729549. JSTOR 2236928.
- ^ Бирнбаум, Аллан (1961). "Единая теория оценивания, I". Анналы математической статистики. 32 (1): 112–135. Дои:10.1214 / aoms / 1177705145. JSTOR 2237612.
- ^ ван дер Ваарт, Х. Роберт (1961). «Некоторые расширения идеи предвзятости». Анналы математической статистики. 32 (2): 436–447. Дои:10.1214 / aoms / 1177705051. JSTOR 2237754. МИСТЕР 0125674.
- ^ Пфанцагль, Иоганн; при содействии Р. Хамбёкера (1994). Параметрическая статистическая теория. Вальтер де Грюйтер. ISBN 3-11-013863-8. МИСТЕР 1291393.
- ^ Пфанцагль, Иоганн. «Об оптимальных срединных несмещенных оценках при наличии мешающих параметров». Анналы статистики (1979): 187–193.
- ^ Brown, L.D .; Коэн, Артур; Strawderman, W. E. (1976). «Теорема о полном классе для строгого монотонного отношения правдоподобия с приложениями». Анна. Статист. 4 (4): 712–722. Дои:10.1214 / aos / 1176343543.
- ^ Страница; Brown, L.D .; Коэн, Артур; Strawderman, W. E. (1976). «Теорема о полном классе для строгого монотонного отношения правдоподобия с приложениями». Анна. Статист. 4 (4): 712–722. Дои:10.1214 / aos / 1176343543.
- ^ а б c d е Баккер, Артур; Гравемейер, Коено П. Э. (01.06.2006). «Историческая феноменология среднего и медианы». Образовательные исследования по математике. 62 (2): 149–168. Дои:10.1007 / s10649-006-7099-8. ISSN 1573-0816. S2CID 143708116.
- ^ Адлер, Дан (31 декабря 2014 г.). «Талмуд и современная экономика». Еврейские американские и израильские проблемы. Архивировано из оригинал 6 декабря 2015 г.. Получено 22 февраля 2020.
- ^ Современная экономическая теория в Талмуде к Исраэль Ауманн
- ^ а б c d Эйзенхарт, Черчилль (24 августа 1971 г.). Развитие концепции наилучшего среднего значения системы измерений с древности до наших дней. (PDF) (Речь). 131-е ежегодное собрание Американской статистической ассоциации. Государственный университет Колорадо.
- ^ а б c «Как среднее превзошло медианное». Ценономика. Получено 2020-02-23.
- ^ Стиглер, С. М. (1986). История статистики: измерение неопределенности до 1900 г.. Издательство Гарвардского университета. ISBN 0674403401.
- ^ Лаплас П.С. де (1818 г.) Deuxième Supplément à la Théorie Analytique des Probabilités, Париж, Курсье
- ^ Джейнс, Э. (2007). Теория вероятностей: логика науки (5. печат. Ред.). Кембридж [u.a.]: Cambridge Univ. Нажмите. п. 172. ISBN 978-0-521-59271-0.
- ^ Ховарт, Ричард (2017). Словарь математических наук о Земле: с историческими примечаниями. Springer. п. 374.
- ^ а б Кейнс, Дж. М. (1921) Трактат о вероятности. Часть II, глава XVII, §5 (стр. 201) (перепечатка 2006 г., Cosimo Classics, ISBN 9781596055308 : несколько других репринтов)
- ^ Стиглер, Стивен М. (2002). Статистика на столе: история статистических концепций и методов. Издательство Гарвардского университета. С. 105–7. ISBN 978-0-674-00979-0.
- ^ Гальтон Ф. (1881) «Отчет Антропометрического комитета», стр. 245–260. Отчет 51-го заседания Британской ассоциации содействия развитию науки
- ^ Дэвид, Х.А. (1995). «Первое (?) Появление общих терминов в математической статистике». Американский статистик. 49 (2): 121–133. Дои:10.2307/2684625. ISSN 0003-1305. JSTOR 2684625.
- ^ encyclopediaofmath.org
- ^ personal.psu.edu
внешняя ссылка
- «Медиана (в статистике)», Энциклопедия математики, EMS Press, 2001 [1994]
- Медиана как средневзвешенное арифметическое всех наблюдений выборки
- Он-лайн калькулятор
- Расчет медианы
- Проблема, связанная со средним значением, медианой и модой.
- Вайсштейн, Эрик В. «Статистическая медиана». MathWorld.
- Скрипт Python для вычислений медианы и показатели неравенства доходов
- Быстрое вычисление медианы путем последовательного биннинга
- "Среднее, медиана, мода и асимметрия", Учебное пособие, разработанное для студентов первого курса психологии Оксфордского университета на основе рабочего примера.
- Сложная задача по SAT-математике, которую даже совет колледжа ошибся: Эндрю Дэниэлс в Популярная механика
В этой статье используется материал из Median по распределению на PlanetMath, который находится под лицензией Лицензия Creative Commons Attribution / Share-Alike.