T-тест студентов - Википедия - Students t-test
В т-тест есть ли проверка статистической гипотезы в которой статистика теста следует за Студенты т-распределение под нулевая гипотеза.
А т-test чаще всего применяется, когда статистика теста будет следовать нормальное распределение если значение срок масштабирования в тестовой статистике были известны. Когда коэффициент масштабирования неизвестен и заменен оценкой, основанной на данные, статистика теста (при определенных условиях) соответствует студенческой т распределение. В т-test может использоваться, например, для определения того, являются ли средние значения двух наборов данных существенно отличаются друг от друга.
История

Период, термин "т-статистический сокращенно от «статистика проверки гипотез».[1][нужна цитата ] В статистике t-распределение было впервые получено как апостериорное распределение в 1876 г. Helmert[2][3][4] и Люрот.[5][6][7] T-распределение также появилось в более общей форме как тип Пирсона. IV распространение в Карл Пирсон Бумага 1895 года.[8] Однако T-распределение, также известное как Распределение Т студентов получил свое название от Уильям Сили Госсет кто впервые опубликовал его на английском языке в 1908 году в научном журнале Биометрика под псевдонимом "Студент"[9][10] потому что его работодатель предпочитал сотрудникам использовать псевдонимы при публикации научных статей вместо их настоящего имени, поэтому он использовал имя «Студент», чтобы скрыть свою личность.[11] Госсет работал в Пивоварня Guinness в Дублин, Ирландия, и интересовался проблемами малых образцов - например, химическими свойствами ячменя при малых размерах образцов. Следовательно, вторая версия этимологии термина «студент» состоит в том, что Guinness не хотел, чтобы их конкуренты знали, что они использовали t-критерий для определения качества сырья. Хотя это был Уильям Госсет, в честь которого был написан термин «Студент», на самом деле он возник благодаря работе Рональд Фишер что это распределение стало известно как "Студенческое распределение"[12] и «t-критерий Стьюдента».
Госсет был принят на работу благодаря Клод Гиннесс политика найма лучших выпускников Оксфорд и Кембридж применять биохимия и статистика к производственным процессам Guinness.[13] Госсет разработал т-тест как экономичный способ контроля качества толстый. В т-тестовая работа отправлена и принята в журнал Биометрика и опубликовано в 1908 году.[14] Политика компании Guinness запрещала химикам публиковать свои открытия, поэтому Госсет опубликовал свою статистическую работу под псевдонимом «Студент» (см. Студенты т-распределение для подробной истории этого псевдонима, который не следует путать с буквальным термином ученик ).
В Guinness была политика, разрешающая техническому персоналу отпуск для учебы (так называемый «учебный отпуск»), который Госсет использовал в течение первых двух семестров 1906–1907 учебного года в г. Профессор Карл Пирсон биометрическая лаборатория в Университетский колледж Лондона.[15] Личность Госсета была тогда известна коллегам-статистикам и главному редактору Карлу Пирсону.[16]
Использует
Среди наиболее часто используемых т-тесты бывают:
- Один образец проверка местоположения имеет ли среднее значение генеральной совокупности значение, указанное в нулевая гипотеза.
- Двухвыборочный тест местоположения нулевой гипотезы, такой, что средства двух популяций равны. Все такие тесты обычно называются Студенты т-тесты, хотя, строго говоря, это имя следует использовать, только если отклонения двух популяций также считаются равными; форма теста, используемая, когда это предположение отбрасывается, иногда называется Велча т-тест. Эти тесты часто называют «непарными» или «независимыми выборками». т-тесты, поскольку они обычно применяются, когда статистические единицы лежащие в основе двух сравниваемых образцов не перекрываются.[17]
Предположения
Большинство тестовых статистик имеют вид т = Z/s, куда Z и s являются функциями данных.
Z может быть чувствительным к альтернативной гипотезе (то есть ее величина имеет тенденцию быть больше, когда альтернативная гипотеза верна), тогда как s это параметр масштабирования что позволяет распределять т быть определенным.
Например, в однократном т-тест

куда Икс это выборочное среднее из образца Икс1, Икс2, …, Иксп, размером п, s это стандартная ошибка среднего, оценка стандартное отклонение населения, и μ это Средняя численность населения.

Предположения, лежащие в основе т-тест в простейшей форме выше:
- Икс следует нормальному распределению со средним μ и дисперсия σ2/п
- s2(п − 1)/σ2 следует за χ2 распределение с п − 1 степени свободы. Это предположение выполняется, когда наблюдения, используемые для оценки s2 происходят из нормального распределения (и i.i.d для каждой группы).
- Z и s находятся независимый.
в т-тест, сравнивающий средние значения двух независимых выборок, должны выполняться следующие допущения:
- Средние значения двух сравниваемых популяций должны следовать нормальные распределения. При слабых предположениях это следует для больших выборок из Центральная предельная теорема, даже если распределение наблюдений в каждой группе ненормальное.[18]
- При использовании оригинального определения Стьюдента т-test, две сравниваемые популяции должны иметь одинаковую дисперсию (проверяется с помощью F-тест, Тест Левена, Тест Бартлетта, или Тест Брауна – Форсайта; или оценивается графически с помощью Q – Q график ). Если размеры выборки в двух сравниваемых группах равны, исходная величина Стьюдента т-test очень устойчив к наличию неравных дисперсий.[19] Велча т-тест нечувствителен к равенству дисперсий независимо от того, схожи ли размеры выборки.
- Данные, используемые для проведения теста, следует либо отбирать независимо от двух сравниваемых популяций, либо полностью объединять в пары. Как правило, это не тестируется на основе данных, но если известно, что данные являются зависимыми (например, спарены по дизайну теста), необходимо применить зависимый тест. Для частично парных данных классические независимые т-тесты могут дать неверные результаты, так как статистика теста может не соответствовать т распределение, а зависимые т-test не является оптимальным, поскольку отбрасывает непарные данные.[20]
Самый двухвыборочный т-тесты устойчивы ко всем отклонениям от предположений, кроме значительных.[21]
За точность, то т-тест и Z-тест требует нормальности выборочных средних, а т-test дополнительно требует, чтобы дисперсия выборки соответствовала масштабированной χ2 распределение, и что выборочное среднее и выборочная дисперсия статистически независимый. Нормальность отдельных значений данных не требуется, если эти условия выполняются. Посредством Центральная предельная теорема средние выборки умеренно больших выборок часто хорошо аппроксимируются нормальным распределением, даже если данные не имеют нормального распределения. Для ненормальных данных распределение дисперсии выборки может существенно отличаться от χ2 распределение. Однако, если размер выборки большой, Теорема Слуцкого означает, что распределение дисперсии выборки мало влияет на распределение статистики теста.
Непарный и парный двухвыборочный т-тесты
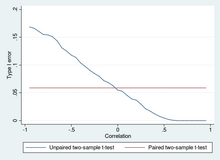

Два образца т-тесты на разницу средних значений включают независимые выборки (непарные выборки) или парные выборки. Парный т-тесты - это форма блокировка, и иметь больше мощность чем непарные тесты, когда парные блоки подобны в отношении «шумовых факторов», которые не зависят от принадлежности к двум сравниваемым группам.[22] В другом контексте парные т-тесты можно использовать для снижения эффектов сопутствующие факторы в обсервационное исследование.
Независимые (непарные) образцы
Независимые образцы т-test используется, когда два отдельных набора независимые и одинаково распределенные берутся образцы, по одному от каждой из двух сравниваемых популяций. Например, предположим, что мы оцениваем эффект от лечения и включаем 100 субъектов в наше исследование, а затем случайным образом назначаем 50 субъектов в группу лечения и 50 субъектов в контрольную группу. В этом случае у нас есть две независимых выборки, и мы будем использовать непарную форму т-тест.
Парные образцы
Парные образцы т-тесты обычно состоят из выборки согласованных пар одинаковых единицы, или одна группа единиц, которая была протестирована дважды («повторные измерения» т-тест).
Типичный пример повторных измерений т-тест будет заключаться в том, что субъекты проходят тестирование перед лечением, скажем, на высокое кровяное давление, и те же субъекты снова проходят тестирование после лечения препаратами, снижающими кровяное давление. Сравнивая количество одних и тех же пациентов до и после лечения, мы эффективно используем каждого пациента в качестве контроля. Таким образом, правильное отклонение нулевой гипотезы (здесь: отсутствие различий, сделанных лечением) может стать гораздо более вероятным, со статистической мощностью, увеличивающейся просто потому, что случайная вариация между пациентами теперь устранена. Однако увеличение статистической мощности имеет свою цену: требуется больше тестов, каждый предмет должен быть протестирован дважды. Поскольку половина выборки теперь зависит от другой половины, парная версия Student's т-тест только п/2 − 1 степени свободы (с п - общее количество наблюдений). Пары становятся отдельными тестовыми образцами, и образец необходимо удвоить для достижения того же числа степеней свободы. Обычно есть п − 1 степени свободы (с п - общее количество наблюдений).[23]
Парные образцы т-тест, основанный на результатах «выборки совпадающих пар» из непарной выборки, которая впоследствии используется для формирования парной выборки, с использованием дополнительных переменных, которые были измерены вместе с интересующей переменной.[24] Сопоставление выполняется путем идентификации пар значений, состоящих из одного наблюдения из каждой из двух выборок, где пара аналогична с точки зрения других измеряемых переменных. Этот подход иногда используется в обсервационных исследованиях для уменьшения или устранения влияния смешивающих факторов.
Парные образцы т-тесты часто называют «зависимыми выборками». т-тесты ».
Расчеты
Явные выражения, которые можно использовать для выполнения различных т-тесты приведены ниже. В каждом случае формула для статистики теста, которая либо точно соответствует, либо близко приближается к т-приведено распределение при нулевой гипотезе. Также соответствующие степени свободы даны в каждом случае. Каждую из этих статистических данных можно использовать для проведения либо односторонний или двусторонний тест.
Однажды т величина и степени свободы определены, п-ценить можно найти с помощью таблица значений из Студенческой т-распределение. Если рассчитанный п-значение ниже порога, выбранного для Статистическая значимость (обычно на уровне 0,10, 0,05 или 0,01), нулевая гипотеза отклоняется в пользу альтернативной гипотезы.
Один образец т-тест
При проверке нулевой гипотезы о том, что среднее значение генеральной совокупности равно заданному значению μ0, используется статистика

куда выборочное среднее, s это стандартное отклонение выборки и п размер выборки. В этом тесте используются следующие степени свободы: п − 1. Хотя родительская популяция не обязательно должна быть нормально распределенной, распределение выборки означает считается нормальным.

Посредством Центральная предельная теорема, если наблюдения независимы и второй момент существует, то будет примерно нормальным N (0; 1).

Наклон линии регрессии
Предположим, что кто-то соответствует модели

куда Икс известен, α и β неизвестны, ε - нормально распределенная случайная величина со средним 0 и неизвестной дисперсией σ2, и Y интересующий результат. Мы хотим проверить нулевую гипотезу о том, что наклон β равно некоторому заданному значению β0 (часто принимается равным 0, и в этом случае нулевая гипотеза состоит в том, что Икс и у некоррелированы).
Позволять

потом

имеет т-распространение с п − 2 степени свободы, если нулевая гипотеза верна. В стандартная ошибка коэффициента наклона:

можно записать через остатки. Позволять

потом тсчет дан кем-то:

Другой способ определить тсчет является:

куда р это Коэффициент корреляции Пирсона.
В тзабить, перехватить можно определить из тоценка, наклон:

куда sИкс2 - выборочная дисперсия.
Независимый двухвыборочный т-тест
Равные размеры выборки и дисперсия
Учитывая две группы (1, 2), этот тест применим только тогда, когда:
- два размера выборки (то есть количество п участников каждой группы) равны;
- можно предположить, что два распределения имеют одинаковую дисперсию;
Нарушения этих предположений обсуждаются ниже.
В т Статистические данные для проверки различий средних значений можно рассчитать следующим образом:

куда

Здесь sп это объединенное стандартное отклонение за п = п1 = п2 и s 2
Икс1 и s 2
Икс2 являются объективные оценщики из отклонения из двух образцов. Знаменатель т это стандартная ошибка разницы между двумя средствами.
Для проверки значимости степени свободы для этого теста 2п − 2 куда п - количество участников в каждой группе.
Равные или неравные размеры выборки, одинаковые дисперсии (1/2 < sИкс1/sИкс2 < 2)
Этот тест используется только тогда, когда можно предположить, что два распределения имеют одинаковую дисперсию. (Если это предположение нарушается, см. Ниже.) Предыдущие формулы являются частным случаем формул ниже, их восстанавливают, когда оба образца равны по размеру: п = п1 = п2.
В т Статистические данные для проверки различий средних значений можно рассчитать следующим образом:

куда

является оценкой объединенное стандартное отклонение двух образцов: он определяется таким образом, что его квадрат является объективный оценщик общей дисперсии независимо от того, совпадают ли средние по численности населения. В этих формулах пя − 1 - количество степеней свободы для каждой группы, а общий размер выборки минус два (то есть п1 + п2 − 2) - общее количество степеней свободы, которое используется при проверке значимости.
Равные или неравные размеры выборки, неравные дисперсии (sИкс1 > 2sИкс2 или же sИкс2 > 2sИкс1)
Этот тест, также известный как тест Велча т-тест используется только тогда, когда предполагается, что две дисперсии генеральной совокупности не равны (два размера выборки могут быть, а могут и не быть равными) и, следовательно, должны оцениваться отдельно. В т статистика для проверки того, отличаются ли средние значения генеральной совокупности, рассчитывается как:

куда

Здесь sя2 это объективный оценщик из отклонение каждого из двух образцов с пя = количество участников в группе я (1 или 2). В этом случае s2
Δ не является совокупной дисперсией. Для использования в тестировании значимости распределение тестовой статистики аппроксимируется как обычное распределение Стьюдента. т-распределение со степенями свободы, рассчитанными с использованием

Это известно как Уравнение Велча – Саттертуэйта. Истинное распределение тестовой статистики фактически зависит (немного) от двух неизвестных дисперсий совокупности (см. Проблема Беренса – Фишера ).
Зависимый т-тест для парных образцов
Этот тест используется, когда образцы зависимы; то есть, когда есть только один образец, который был протестирован дважды (повторные измерения), или когда есть два образца, которые были сопоставлены или «спарены». Это пример тест парных различий. В т статистика рассчитывается как

куда и - среднее и стандартное отклонение разностей между всеми парами. Пары, например, либо баллы одного человека до и после тестирования, либо между парами людей, составленных в значимые группы (например, из одной семьи или возрастной группы: см. таблицу). Постоянная μ0 равен нулю, если мы хотим проверить, существенно ли отличается среднее значение разницы. Используемая степень свободы п − 1, куда п представляет количество пар.


Пример повторных измерений Число Имя Тест 1 Тест 2 1 Майк 35% 67% 2 Мелани 50% 46% 3 Мелисса 90% 86% 4 Митчелл 78% 91%
Пример подобранных пар Пара Имя Возраст Тест 1 Джон 35 250 1 Джейн 36 340 2 Джимми 22 460 2 Джесси 21 200
Примеры работ
Эта статья может не правильно подвести итог соответствующая основная статья. (Узнайте, как и когда удалить этот шаблон сообщения) |
Позволять А1 обозначают набор, полученный путем проведения случайной выборки из шести измерений:

и разреши А2 обозначим второй набор, полученный аналогично:

Это может быть, например, вес шурупов, выбранных из ведра.
Мы проведем проверку нулевой гипотезы о том, что средства популяции, из которых были взяты две пробы, равны.
Разница между двумя выборочными средними значениями, каждое из которых обозначено Икся, который появляется в числителе для всех двухвыборочных подходов к тестированию, описанных выше,

Образец Стандартное отклонение для двух образцов примерно 0,05 и 0,11 соответственно. Для таких небольших выборок проверка равенства между двумя дисперсиями генеральной совокупности не будет очень действенной. Поскольку размеры выборки равны, две формы двухвыборочного т-test будет работать аналогично в этом примере.
Неравные отклонения
Если следовать подходу для неравных дисперсий (обсужденному выше), результаты будут

и степени свободы

Статистика теста составляет примерно 1,959, что дает двусторонний тест. п-значение 0,09077.
Равные отклонения
Если следовать подходу равных отклонений (обсужденному выше), результаты будут

и степени свободы

Статистика теста примерно равна 1.959, что дает двусторонний п-значение 0,07857.
Связанные статистические тесты
Альтернативы т-тест на проблемы с локацией
В т-test обеспечивает точный тест на равенство средних двух i.i.d. нормальные популяции с неизвестными, но равными дисперсиями. (Велча т-тест является почти точным тестом для случая, когда данные нормальные, но дисперсии могут отличаться.) Для умеренно больших выборок и одностороннего теста т-test является относительно устойчивым к умеренным нарушениям предположения о нормальности.[25] В достаточно больших выборках t-критерий асимптотически приближается к z-тест, и становится устойчивым даже к большим отклонениям от нормы.[18]
Если данные существенно не соответствуют норме и размер выборки невелик, т-тест может дать неверные результаты. Видеть Проверка местоположения для распределений смеси в масштабе Гаусса для некоторой теории, связанной с одним конкретным семейством ненормальных распределений.
Когда предположение нормальности не выполняется, a непараметрический альтернатива т-тест может быть лучше статистическая мощность. Однако, если данные не соответствуют норме с разными отклонениями между группами, t-тест может дать лучший результат. ошибка типа 1 контроль, чем некоторые непараметрические альтернативы.[26] Кроме того, непараметрические методы, такие как U-критерий Манна-Уитни обсуждаемые ниже, обычно не проверяют разницу в средствах, поэтому следует использовать осторожно, если разница в средствах представляет первостепенный научный интерес.[18] Например, U-критерий Манна-Уитни сохранит ошибку типа 1 на желаемом уровне альфа, если обе группы имеют одинаковое распределение. Он также будет иметь возможность обнаруживать альтернативу, по которой группа B имеет то же распределение, что и A, но после некоторого сдвига на константу (в этом случае действительно будет разница в средних значениях двух групп). Однако могут быть случаи, когда группы A и B будут иметь разные распределения, но с одними и теми же средними значениями (например, два распределения, одно с положительной асимметрией, а другое с отрицательным, но смещенное таким образом, чтобы иметь одинаковые средние значения). В таких случаях MW может иметь больше, чем уровень альфа-уровня в отклонении гипотезы о нуле, но приписывать интерпретацию различия в средних значениях такому результату было бы неверно.
При наличии выброс, t-тест не является устойчивым. Например, для двух независимых выборок, когда распределения данных асимметричны (т. Е. Распределения перекошенный ) или распределения имеют большие хвосты, то критерий суммы рангов Вилкоксона (также известный как Манн – Уитни U тест ) может иметь в три-четыре раза большую мощность, чем т-тест.[25][27][28] Непараметрический аналог парных выборок т-тест Знаковый ранговый тест Вилкоксона для парных образцов. Для обсуждения выбора между т-тестовые и непараметрические альтернативы, см. Lumley, et al. (2002).[18]
В одну сторону дисперсионный анализ (ANOVA) обобщает двухвыборочный т-тест, когда данные принадлежат более чем двум группам.
Дизайн, включающий как парные, так и независимые наблюдения.
Когда в двух планах выборки присутствуют как парные наблюдения, так и независимые наблюдения, при условии, что данные отсутствуют полностью случайным образом (MCAR), парные наблюдения или независимые наблюдения могут быть отброшены, чтобы продолжить стандартные тесты, описанные выше. В качестве альтернативы, используя все доступные данные, предполагая нормальность и MCAR, можно использовать t-тест обобщенных частично перекрывающихся выборок.[29]
Многовариантное тестирование
Обобщение студенческой т статистика, называемая Хотеллинга т-квадратная статистика, позволяет проверять гипотезы по нескольким (часто коррелированным) показателям в одной и той же выборке. Например, исследователь может предложить ряду испытуемых пройти личностный тест, состоящий из нескольких шкал личности (например, Миннесотский многофазный опросник личности ). Поскольку меры этого типа обычно имеют положительную корреляцию, не рекомендуется проводить отдельные одномерные т-тесты для проверки гипотез, поскольку они пренебрегают ковариацией между мерами и увеличивают вероятность ложного отклонения по крайней мере одной гипотезы (Ошибка типа I ). В этом случае для проверки гипотез предпочтительнее использовать одномерный многомерный тест. Метод Фишера для объединения нескольких тестов с альфа приведено для положительной корреляции между тестами - единица. Другой - Хотеллинг Т2 статистика следует за Т2 распределение. Однако на практике распределение используется редко, так как табличные значения для Т2 трудно найти. Обычно, Т2 вместо этого преобразуется в F статистика.
Для многомерного теста с одной выборкой гипотеза состоит в том, что средний вектор (μ) равно заданному вектору (μ0). Статистика теста Хотеллинга т2:

куда п размер выборки, Икс вектор средних столбцов и S является м × м выборочная ковариационная матрица.
Для многомерного теста с двумя выборками гипотеза состоит в том, что средние векторы (μ1, μ2) двух образцов равны. Статистика теста Двухвыборка Хотеллинга т2:

Программные реализации
Много электронная таблица программы и статистические пакеты, такие как QtiPlot, LibreOffice Calc, Майкрософт Эксель, SAS, SPSS, Stata, DAP, гретл, р, Python, PSPP, Matlab и Minitab, включают реализации Student's т-тест.
| Язык / Программа | Функция | Примечания |
|---|---|---|
| Майкрософт Эксель до 2010 | TTEST (array1, array2, хвосты, тип) | Видеть [1] |
| Майкрософт Эксель 2010 и позже | T.TEST (array1, array2, хвосты, тип) | Видеть [2] |
| LibreOffice Calc | TTEST (Data1; Data2; Режим; Тип) | Видеть [3] |
| Google Таблицы | ТТЕСТ (диапазон1; диапазон2; хвосты; тип) | Видеть [4] |
| Python | scipy.stats.ttest_ind (а, б, equal_var = True) | Видеть [5] |
| Matlab | ttest (данные1, данные2) | Видеть [6] |
| Mathematica | TTest [{данные1, данные2}] | Видеть [7] |
| р | t.test (данные1, данные2, var.equal = ИСТИНА) | Видеть [8] |
| SAS | PROC TTEST | Видеть [9] |
| Ява | tTest (образец1, образец2) | Видеть [10] |
| Юля | EqualVarianceTTest (образец1, образец2) | Видеть [11] |
| Stata | ttest data1 == data2 | Видеть [12] |
Смотрите также
Рекомендации
Цитаты
- ^ Микробиом в здоровье и болезнях. Академическая пресса. 2020-05-29. п. 397. ISBN 978-0-12-820001-8.
- ^ Сабо, Иштван (2003), Einführung in die Technische Mechanik, Springer Berlin Heidelberg, стр. 196–199, Дои:10.1007/978-3-642-61925-0_16, ISBN 978-3-540-13293-6 Отсутствует или пусто
| название =(помощь);| chapter =игнорируется (помощь) - ^ Шливич, Б. (октябрь 1937 г.). "Untersuchungen über den anastomotischen Kanal zwischen der Arteria coeliaca und mesenterica superior und damit в Zusammenhang stehende Fragen". Zeitschrift für Anatomie und Entwicklungsgeschichte. 107 (6): 709–737. Дои:10.1007 / bf02118337. ISSN 0340-2061. S2CID 27311567.
- ^ Гельмерт (1876 г.). "Die Genauigkeit der Formel von Peters zur Berechnung des wahrscheinlichen Beobachtungsfehlers directer Beobachtungen gleicher Genauigkeit". Astronomische Nachrichten (на немецком). 88 (8–9): 113–131. Bibcode:1876AN ..... 88..113H. Дои:10.1002 / asna.18760880802.
- ^ Люрот, Дж. (1876 г.). "Vergleichung von zwei Werthen des wahrscheinlichen Fehlers". Astronomische Nachrichten (на немецком). 87 (14): 209–220. Bibcode:1876AN ..... 87..209L. Дои:10.1002 / asna.18760871402.
- ^ Пфанзагл Дж, Шейнин О (1996). «Исследования по истории вероятности и статистики. XLIV. Предшественник t-распределения». Биометрика. 83 (4): 891–898. Дои: 10.1093 / biomet / 83.4.891. МИСТЕР 1766040.
- ^ Шейнин, Оскар (1995). «Работа Гельмерта по теории ошибок». Архив истории точных наук. 49 (1): 73–104. Дои:10.1007 / BF00374700. ISSN 0003-9519. S2CID 121241599.
- ^ Пирсон, К. (1895-01-01). «Вклад в математическую теорию эволюции. II. Косые вариации в однородном материале». Философские труды Королевского общества A: математические, физические и инженерные науки. 186: 343–414 (374). Дои: 10.1098 / rsta.1895.0010. ISSN 1364-503X
- ^ "Ученик" Уильям Сили Госсет (1908). «Вероятная ошибка среднего» (PDF). Биометрика. 6 (1): 1–25. Дои: 10.1093 / biomet / 6.1.1. HDL: 10338.dmlcz / 143545. JSTOR 2331554
- ^ «Таблица T | История таблицы T, этимология, таблица T с одним концом, таблица T с двумя хвостами и T-статистика».
- ^ Wendl MC (2016). «Псевдонимная слава». Наука. 351 (6280): 1406. DOI: 10.1126 / science.351.6280.1406. PMID 27013722
- ^ Уолпол, Рональд Э. (2006). Вероятность и статистика для инженеров и ученых. Майерс, Х. Раймонд. (7-е изд.). Нью-Дели: Пирсон. ISBN 81-7758-404-9. OCLC 818811849.
- ^ О'Коннор, Джон Дж.; Робертсон, Эдмунд Ф., "Уильям Сили Госсет", Архив истории математики MacTutor, Сент-Эндрюсский университет.
- ^ «Вероятная ошибка среднего» (PDF). Биометрика. 6 (1): 1–25. 1908. Дои:10.1093 / biomet / 6.1.1. HDL:10338.dmlcz / 143545. Получено 24 июля 2016.
- ^ Раджу, Т. Н. (2005). «Уильям Сили Госсет и Уильям А. Сильверман: два« студента »науки». Педиатрия. 116 (3): 732–5. Дои:10.1542 / педс.2005-1134. PMID 16140715. S2CID 32745754.
- ^ Додж, Ядола (2008). Краткая энциклопедия статистики. Springer Science & Business Media. С. 234–235. ISBN 978-0-387-31742-7.
- ^ Фадем, Барбара (2008). Высокоэффективная поведенческая наука. Высокодоходная серия. Хагерстаун, Мэриленд: Липпинкотт Уильямс и Уилкинс. ISBN 978-0-7817-8258-6.
- ^ а б c d Ламли, Томас; Дир, Паула; Эмерсон, Скотт; Чен, Лу (май 2002 г.). «Важность предположения о нормальности в больших наборах данных общественного здравоохранения». Ежегодный обзор общественного здравоохранения. 23 (1): 151–169. Дои:10.1146 / annurev.publhealth.23.100901.140546. ISSN 0163-7525. PMID 11910059.
- ^ Марковски, Кэрол А .; Марковский, Эдвард П. (1990). «Условия эффективности предварительного дисперсионного теста». Американский статистик. 44 (4): 322–326. Дои:10.2307/2684360. JSTOR 2684360.
- ^ Го, Бэйбэй; Юань, Ин (2017). «Сравнительный обзор методов сравнения средних с использованием частично парных данных». Статистические методы в медицинских исследованиях. 26 (3): 1323–1340. Дои:10.1177/0962280215577111. PMID 25834090. S2CID 46598415.
- ^ Блэнд, Мартин (1995). Введение в медицинскую статистику. Издательство Оксфордского университета. п. 168. ISBN 978-0-19-262428-4.
- ^ Райс, Джон А. (2006). Математическая статистика и анализ данных (3-е изд.). Duxbury Advanced.[ISBN отсутствует ]
- ^ Вайсштейн, Эрик. "Студенческое t-распределение". mathworld.wolfram.com.
- ^ Дэвид, Х. А .; Ганнинк, Джейсон Л. (1997). "Парный т Тест при искусственном спаривании ». Американский статистик. 51 (1): 9–12. Дои:10.2307/2684684. JSTOR 2684684.
- ^ а б Савиловский, Шломо С .; Блэр, Р. Клиффорд (1992). "Более реалистичный взгляд на устойчивость и свойства ошибок типа II т Тест на отклонение от нормы популяции ». Психологический бюллетень. 111 (2): 352–360. Дои:10.1037/0033-2909.111.2.352.
- ^ Циммерман, Дональд В. (январь 1998 г.). «Признание недействительными параметрических и непараметрических статистических тестов одновременным нарушением двух предположений». Журнал экспериментального образования. 67 (1): 55–68. Дои:10.1080/00220979809598344. ISSN 0022-0973.
- ^ Блэр, Р. Клиффорд; Хиггинс, Джеймс Дж. (1980). "Сравнение мощности статистики ранговых сумм Вилкоксона со статистикой студента т Статистика при различных ненормальных распределениях ». Журнал образовательной статистики. 5 (4): 309–335. Дои:10.2307/1164905. JSTOR 1164905.
- ^ Фэй, Майкл П .; Прошан, Майкл А. (2010). "Вилкоксон – Манн – Уитни или т-тест? О допущениях для проверки гипотез и множественной интерпретации решающих правил ». Статистические исследования. 4: 1–39. Дои:10.1214 / 09-SS051. ЧВК 2857732. PMID 20414472.
- ^ Деррик, B; Toher, D; Белый, П (2017). «Как сравнить средние значения двух выборок, которые включают парные наблюдения и независимые наблюдения: спутник Деррика, Расс, Тохер и Уайт (2017)» (PDF). Количественные методы психологии. 13 (2): 120–126. Дои:10.20982 / tqmp.13.2.p120.
Источники
- О'Махони, Майкл (1986). Сенсорная оценка пищевых продуктов: статистические методы и процедуры. CRC Press. п. 487. ISBN 0-82477337-3.
- Press, William H .; Teukolsky, Saul A .; Веттерлинг, Уильям Т .; Фланнери, Брайан П. (1992). http://www.nrbook.com/a/bookcpdf/c14–2.pdf
| URL-адрес главы =отсутствует заголовок (помощь) (PDF). Числовые рецепты на языке C: искусство научных вычислений. Издательство Кембриджского университета. п.616. ISBN 0-521-43108-5.
дальнейшее чтение
- Боне, К. Алан (1960). "Последствия нарушения предположений, лежащих в основе т тест". Психологический бюллетень. 57 (1): 49–64. Дои:10,1037 / ч0041412. PMID 13802482.
- Edgell, Stephen E .; Полдень, Шейла М. (1984). "Влияние нарушения нормальности на т проверка коэффициента корреляции ». Психологический бюллетень. 95 (3): 576–583. Дои:10.1037/0033-2909.95.3.576.
внешняя ссылка
- «Студенческий тест», Энциклопедия математики, EMS Press, 2001 [1994]
- Концептуальная статья о студенческой т-тест
- Лекция по эконометрике (тема: проверка гипотез) на YouTube к Марк Тома
- Один образец студенческого т-тест Калькулятор
| Общий |
| ||||||
|---|---|---|---|---|---|---|---|
| Профилактическое здравоохранение | |||||||
| Здоровье населения |
| ||||||
| Биологические и эпидемиологическая статистика | |||||||
| Инфекционно-эпидемический профилактика болезни | |||||||
| Пищевая гигиена и управление безопасностью | |||||||
| Поведенческое здоровье науки | |||||||
| Организации, образование и история |
| ||||||
| |||||||