Биоинформатика - Bioinformatics


| Часть серии по |
| Биохимия |
|---|
 |
| Ключевые компоненты |
| История биохимии |
| Глоссарии |
| Порталы: Биохимия |
Биоинформатика /ˌбаɪ.oʊˌɪпжərˈмæтɪks/ (![]() Слушать) является междисциплинарный область, которая разрабатывает методы и программные инструменты для понимания биологический данные, особенно когда наборы данных большие и сложные. Биоинформатика как междисциплинарная область науки объединяет биология, Информатика, информационная инженерия, математика и статистика анализировать и интерпретировать биологические данные. Биоинформатика использовалась для in silico анализ биологических запросов с использованием математических и статистических методов.[требуется разъяснение ]
Слушать) является междисциплинарный область, которая разрабатывает методы и программные инструменты для понимания биологический данные, особенно когда наборы данных большие и сложные. Биоинформатика как междисциплинарная область науки объединяет биология, Информатика, информационная инженерия, математика и статистика анализировать и интерпретировать биологические данные. Биоинформатика использовалась для in silico анализ биологических запросов с использованием математических и статистических методов.[требуется разъяснение ]
Биоинформатика включает биологические исследования, в которых используются компьютерное программирование как часть их методологии, а также конкретные аналитические «конвейеры», которые используются неоднократно, особенно в области геномика. Обычно биоинформатика используется для идентификации кандидатов. гены и один нуклеотид полиморфизмы (SNP ). Часто такая идентификация проводится с целью лучшего понимания генетической основы болезни, уникальных приспособлений, желаемых свойств (особенно у сельскохозяйственных видов) или различий между популяциями. Менее формально биоинформатика также пытается понять организационные принципы внутри нуклеиновая кислота и белок последовательности, называемые протеомика.[1]
Вступление
Биоинформатика стала важной частью многих областей биологии. В экспериментальном молекулярная биология, методы биоинформатики, такие как изображение и обработка сигналов позволяют извлекать полезные результаты из больших объемов необработанных данных. В области генетики это помогает в секвенировании и аннотировании геномов и их наблюдаемых мутации. Он играет роль в интеллектуальный анализ текста биологической литературы и развития биологических и генных онтологии для организации и запроса биологических данных. Он также играет роль в анализе экспрессии и регуляции генов и белков. Инструменты биоинформатики помогают в сравнении, анализе и интерпретации генетических и геномных данных и, в более общем плане, в понимании эволюционных аспектов молекулярной биологии. На более интегральном уровне он помогает анализировать и каталогизировать биологические пути и сети, которые являются важной частью системная биология. В структурная биология, он помогает имитировать и моделировать ДНК,[2] РНК,[2][3] белки[4] а также биомолекулярные взаимодействия.[5][6][7][8]
История
Исторически термин биоинформатика не имел в виду то, что означает сегодня. Полин Хогевег и Бен Хеспер придумал его в 1970 году для обозначения изучения информационных процессов в биотических системах.[9][10][11] Это определение помещало биоинформатику как область, параллельную биохимия (изучение химических процессов в биологических системах).[9]
Последовательности

Компьютеры стали незаменимыми в молекулярной биологии, когда белковые последовательности стал доступен после Фредерик Сэнгер определила последовательность инсулин в начале 1950-х гг. Сравнение нескольких последовательностей вручную оказалось нецелесообразным. Первопроходцем в этой области был Маргарет Окли Дейхофф.[12] Она составила одну из первых баз данных последовательностей белков, первоначально опубликованную в виде книг.[13] и первые методы выравнивания последовательностей и молекулярной эволюции.[14] Еще одним ранним участником биоинформатики был Эльвин А. Кабат, который был пионером в области анализа биологических последовательностей в 1970 году, представив обширные тома последовательностей антител, выпущенных Tai Te Wu между 1980 и 1991 годами.[15]В 1970-х годах к бактериофагам MS2 и øX174 были применены новые методы секвенирования ДНК, а затем расширенные нуклеотидные последовательности были проанализированы с помощью информационных и статистических алгоритмов. Эти исследования продемонстрировали, что хорошо известные особенности, такие как сегменты кодирования и триплетный код, выявляются в результате прямого статистического анализа и, таким образом, являются доказательством концепции, что биоинформатика может быть полезной.[16][17]
Цели
Чтобы изучить, как нормальная клеточная активность изменяется при различных болезненных состояниях, биологические данные должны быть объединены, чтобы сформировать полную картину этой активности. Таким образом, область биоинформатики развивалась так, что наиболее актуальной задачей сейчас является анализ и интерпретация различных типов данных. Это включает нуклеотид и аминокислотные последовательности, белковые домены, и белковые структуры.[18] Фактический процесс анализа и интерпретации данных называется вычислительная биология. Важные дисциплины биоинформатики и вычислительной биологии включают:
- Разработка и внедрение компьютерных программ, обеспечивающих эффективный доступ, управление и использование различных типов информации.
- Разработка новых алгоритмов (математических формул) и статистических показателей, которые оценивают отношения между членами больших наборов данных. Например, есть способы найти ген в последовательности, чтобы предсказать структуру и / или функцию белка и кластер белковые последовательности в семейства родственных последовательностей.
Основная цель биоинформатики - улучшить понимание биологических процессов. Однако то, что отличает его от других подходов, - это его ориентация на разработку и применение вычислительно-ресурсоемких методов для достижения этой цели. Примеры включают: распознавание образов, сбор данных, машинное обучение алгоритмы и визуализация. Основные исследования в этой области включают: выравнивание последовательностей, поиск генов, сборка генома, дизайн препарата, открытие лекарств, выравнивание структуры белка, предсказание структуры белка, предсказание экспрессия гена и белок-белковые взаимодействия, полногеномные ассоциации исследований, моделирование эволюция и деление / митоз клеток.
Биоинформатика в настоящее время влечет за собой создание и развитие баз данных, алгоритмов, вычислительных и статистических методов и теории для решения формальных и практических проблем, возникающих в результате управления и анализа биологических данных.
За последние несколько десятилетий быстрое развитие технологий геномных и других молекулярных исследований и разработок в информационные технологии объединились, чтобы произвести огромное количество информации, связанной с молекулярной биологией. Биоинформатика - это название, данное этим математическим и вычислительным подходам, используемым для понимания биологических процессов.
Общие виды деятельности в биоинформатике включают картографирование и анализ ДНК и белковые последовательности, выравнивание последовательностей ДНК и белков для их сравнения, а также создание и просмотр трехмерных моделей белковых структур.
Отношение к другим полям
Биоинформатика - это научная область, похожая на биологические вычисления, в то время как это часто считается синонимом вычислительная биология. Биологические вычисления используют биоинженерия и биология построить биологический компьютеры, тогда как биоинформатика использует вычисления для лучшего понимания биологии. Биоинформатика и вычислительная биология включают анализ биологических данных, в частности последовательностей ДНК, РНК и белков. Область биоинформатики пережила взрывной рост, начиная с середины 1990-х годов, во многом благодаря Проект "Геном человека" и быстрым развитием технологии секвенирования ДНК.
Анализ биологических данных для получения значимой информации включает в себя написание и запуск программ, использующих алгоритмы из теория графов, искусственный интеллект, мягкие вычисления, сбор данных, обработка изображений, и компьютерное моделирование. Алгоритмы, в свою очередь, зависят от теоретических основ, таких как дискретная математика, теория управления, теория систем, теория информации, и статистика.
Анализ последовательности
Поскольку Фаг Φ-X174 был последовательный в 1977 г.[19] то Последовательности ДНК тысяч организмов были расшифрованы и сохранены в базах данных. Эта информация о последовательности анализируется для определения генов, кодирующих белки, Гены РНК, регуляторные последовательности, структурные мотивы и повторяющиеся последовательности. Сравнение генов внутри разновидность или между разными видами может показывать сходство между функциями белков или отношениями между видами (использование молекулярная систематика строить филогенетические деревья ). С растущим объемом данных давно стало непрактичным анализировать последовательности ДНК вручную. Компьютерные программы Такие как ВЗРЫВ обычно используются для поиска последовательностей - по состоянию на 2008 год, из более чем 260 000 организмов, содержащих более 190 миллиардов нуклеотиды.[20]
Секвенирование ДНК
Прежде чем последовательности могут быть проанализированы, они должны быть получены из банка хранения данных Genbank. Секвенирование ДНК по-прежнему является нетривиальной проблемой, поскольку необработанные данные могут содержать шум или содержать слабые сигналы. Алгоритмы были разработаны для базовый вызов для различных экспериментальных подходов к секвенированию ДНК.
Последовательная сборка
Большинство методов секвенирования ДНК производят короткие фрагменты последовательности, которые необходимо собрать для получения полных последовательностей гена или генома. Так называемой секвенирование дробовика техника (которая использовалась, например, Институт геномных исследований (TIGR) для секвенирования первого бактериального генома, Haemophilus influenzae )[21] генерирует последовательности из многих тысяч небольших фрагментов ДНК (длиной от 35 до 900 нуклеотидов, в зависимости от технологии секвенирования). Концы этих фрагментов перекрываются и при правильном выравнивании программой сборки генома могут быть использованы для реконструкции всего генома. Секвенирование дробовиком позволяет быстро получить данные о последовательности, но задача сборки фрагментов может быть довольно сложной для больших геномов. Для генома размером с человеческий геном, для сборки фрагментов может потребоваться много дней процессорного времени на многопроцессорных компьютерах с большим объемом памяти, и в результате сборка обычно содержит многочисленные пробелы, которые необходимо заполнить позже. Секвенирование с дробовиком - метод выбора практически для всех секвенированных сегодня геномов.[когда? ], и алгоритмы сборки генома являются важной областью исследований в области биоинформатики.
Аннотации генома
В контексте геномика, аннотация это процесс маркировки генов и других биологических особенностей в последовательности ДНК. Этот процесс необходимо автоматизировать, потому что большинство геномов слишком велики, чтобы их можно было аннотировать вручную, не говоря уже о желании аннотировать как можно больше геномов, так как скорость последовательность действий перестала быть узким местом. Аннотации стали возможными благодаря тому факту, что гены имеют распознаваемые области начала и остановки, хотя точная последовательность, обнаруженная в этих областях, может варьироваться между генами.
Первое описание комплексной системы аннотации генома было опубликовано в 1995 году.[21] командой в Институт геномных исследований который провел первое полное секвенирование и анализ генома свободноживущего организма, бактерии Haemophilus influenzae.[21] Оуэн Уайт разработала и построила систему программного обеспечения для идентификации генов, кодирующих все белки, РНК переноса, рибосомных РНК (и других сайтов), а также для выполнения начальных функциональных назначений. Большинство современных систем аннотации генома работают аналогично, но программы, доступные для анализа геномной ДНК, такие как GeneMark программа обучена и используется для поиска генов, кодирующих белок в Haemophilus influenzae, постоянно меняются и улучшаются.
Следуя целям, которые оставалось достичь проекту «Геном человека» после его закрытия в 2003 году, появился новый проект, разработанный Национальным институтом исследования генома человека в США. Так называемой КОДИРОВАТЬ Проект представляет собой совместный сбор данных о функциональных элементах человеческого генома, в котором используются технологии секвенирования ДНК следующего поколения и массивы геномных плиток, технологии, способные автоматически генерировать большие объемы данных при значительно сниженных базовых затратах, но с той же точностью (ошибка базового вызова) и верность (ошибка сборки).
Вычислительная эволюционная биология
Эволюционная биология это исследование происхождения и происхождения разновидность, а также их изменение с течением времени. Информатика помог эволюционным биологам, позволив исследователям:
- отслеживать эволюцию большого количества организмов, измеряя изменения в их ДНК, а не только с помощью физической таксономии или физиологических наблюдений,
- сравнить весь геномы, что позволяет изучать более сложные эволюционные события, такие как дупликация гена, горизонтальный перенос генов, а также прогноз факторов, важных для бактериального видообразование,
- строить сложные вычислительные популяционная генетика модели для прогнозирования результатов системы с течением времени[22]
- отслеживать и обмениваться информацией о все большем количестве видов и организмов
Будущая работа направлена на реконструкцию теперь более сложных Дерево жизни.[согласно кому? ]
Область исследований в Информатика который использует генетические алгоритмы иногда путают с вычислительной эволюционной биологией, но эти две области не обязательно связаны.
Сравнительная геномика
Суть сравнительного анализа генома - установление соответствия между гены (ортология анализ) или другие геномные особенности у разных организмов. Именно эти межгеномные карты позволяют проследить эволюционные процессы, ответственные за расхождение двух геномов. Множество эволюционных событий, действующих на разных организационных уровнях, формируют эволюцию генома. На самом низком уровне точечные мутации влияют на отдельные нуклеотиды. На более высоком уровне большие хромосомные сегменты подвергаются дупликации, латеральному переносу, инверсии, транспозиции, делеции и вставке.[23] В конечном итоге целые геномы участвуют в процессах гибридизации, полиплоидизации и эндосимбиоз, часто приводящее к быстрому видообразованию. Сложность эволюции генома ставит множество интересных задач перед разработчиками математических моделей и алгоритмов, которые прибегают к широкому спектру алгоритмических, статистических и математических методов, от точных до точных. эвристика, фиксированный параметр и аппроксимационные алгоритмы для задач, основанных на моделях экономии Цепь Маркова Монте-Карло алгоритмы для Байесовский анализ задач на основе вероятностных моделей.
Многие из этих исследований основаны на обнаружении гомология последовательностей назначить последовательности для белковые семейства.[24]
Пан геномика
Пангеномика - это концепция, представленная в 2005 году Теттелином и Медини, которая в конечном итоге прижилась в биоинформатике. Пангеном - это полный репертуар генов определенной таксономической группы: хотя изначально он применялся к близкородственным штаммам вида, он может применяться в более широком контексте, таком как род, тип и т. Д. Он разделен на две части - Основной геном: набор генов, общих для всех исследуемых геномов (часто это гены домашнего хозяйства, жизненно важные для выживания) и «Незаменимый / гибкий геном»: набор генов, присутствующих не во всех, кроме одного или нескольких исследуемых геномов. Инструмент биоинформатики BPGA можно использовать для характеристики пангенома бактериальных видов.[25]
Генетика болезни
С появлением секвенирования следующего поколения мы получаем достаточно данных о последовательностях для картирования генов сложных заболеваний. бесплодие,[26] рак молочной железы[27] или же Болезнь Альцгеймера.[28] Полногеномные исследования ассоциации - полезный подход для точного определения мутаций, ответственных за такие сложные заболевания.[29] Благодаря этим исследованиям были идентифицированы тысячи вариантов ДНК, которые связаны со схожими заболеваниями и признаками.[30] Кроме того, возможность использования генов для прогноза, диагностики или лечения является одним из наиболее важных приложений. Многие исследования обсуждают как многообещающие способы выбора используемых генов, так и проблемы и подводные камни использования генов для прогнозирования наличия или прогноза заболевания.[31]
Анализ мутаций при раке
В рак геномы пораженных клеток перестраиваются сложным или даже непредсказуемым образом. Для выявления ранее неизвестных используются огромные усилия по секвенированию. точечные мутации в различных гены при раке. Специалисты по биоинформатике продолжают создавать специализированные автоматизированные системы для управления огромным объемом производимых данных о последовательностях, и они создают новые алгоритмы и программное обеспечение для сравнения результатов секвенирования с растущей коллекцией человеческий геном последовательности и зародышевый полиморфизмы. Используются новые технологии физического обнаружения, такие как олигонуклеотид микроматрицы для определения хромосомных прибылей и убытков (называемые сравнительная геномная гибридизация ), и однонуклеотидный полиморфизм массивы для обнаружения известных точечные мутации. Эти методы обнаружения одновременно измеряют несколько сотен тысяч сайтов по всему геному, и при использовании с высокой пропускной способностью для измерения тысяч образцов генерируют терабайты данных за эксперимент. И снова огромные объемы и новые типы данных открывают новые возможности для биоинформатиков. Часто обнаруживается, что данные содержат значительную изменчивость или шум, и поэтому Скрытая марковская модель и методы анализа точек изменения разрабатываются для вывода реальных номер копии изменения.
При биоинформатическом анализе раковых геномов можно использовать два важных принципа, относящихся к идентификации мутаций в экзом. Во-первых, рак - это болезнь накопленных соматических мутаций в генах. Второй рак содержит водительские мутации, которые нужно отличать от пассажиров.[32]
Благодаря достижениям, которые эта технология секвенирования следующего поколения обеспечивает в области биоинформатики, геномика рака может кардинально измениться. Эти новые методы и программное обеспечение позволяют биоинформатикам быстро и по доступной цене секвенировать многие геномы рака. Это могло бы создать более гибкий процесс классификации типов рака путем анализа мутаций в геноме, вызванных раком. Кроме того, отслеживание пациентов по мере прогрессирования заболевания может стать возможным в будущем с помощью последовательности образцов рака.[33]
Другой тип данных, требующий развития новой информатики, - это анализ поражения обнаружено, что он рецидивирует среди многих опухолей.
Экспрессия генов и белков
Анализ экспрессии генов
В выражение многих генов можно определить путем измерения мРНК уровни с несколькими техниками, включая микрочипы, метка экспрессированной последовательности кДНК (EST) секвенирование, серийный анализ экспрессии генов (SAGE) последовательность тегов, массовая параллельная последовательность подписей (MPSS), РНК-Seq, также известное как «дробовое секвенирование полного транскриптома» (WTSS), или различные применения мультиплексной гибридизации in-situ. Все эти методы чрезвычайно подвержены шуму и / или подвержены систематической ошибке в биологических измерениях, и основная область исследований в области вычислительной биологии включает разработку статистических инструментов для разделения сигнал из шум в исследованиях экспрессии генов с высокой пропускной способностью.[34] Такие исследования часто используются для определения генов, участвующих в заболевании: можно сравнить данные микрочипов от раковых заболеваний. эпителиальный от клеток к данным незлокачественных клеток для определения транскриптов, которые активируются и подавляются в конкретной популяции раковых клеток.
Анализ экспрессии белка
Белковые микрочипы и высокая пропускная способность (HT) масс-спектрометрии (MS) может предоставить снимок белков, присутствующих в биологическом образце. Биоинформатика очень активно участвует в осмыслении данных белковых микрочипов и ВТ-МС; Первый подход сталкивается с теми же проблемами, что и микроматрицы, нацеленные на мРНК, второй включает в себя проблему сопоставления больших объемов массовых данных с предсказанными массами из баз данных последовательностей белков, а также сложный статистический анализ образцов, в которых обнаруживаются несколько, но неполные пептиды из каждого белка. обнаружен. Локализация клеточного белка в тканевом контексте может быть достигнута за счет аффинности протеомика отображаются как пространственные данные на основе иммуногистохимия и тканевые микрочипы.[35]
Анализ регулирования
Генная регуляция представляет собой сложную оркестровку событий, посредством которых сигнал, потенциально внеклеточный сигнал, такой как гормон, в конечном итоге приводит к увеличению или уменьшению активности одного или нескольких белки. Для изучения различных этапов этого процесса были применены методы биоинформатики.
Например, экспрессия гена может регулироваться соседними элементами генома. Анализ промоутера включает выявление и изучение мотивы последовательности в ДНК, окружающей кодирующую область гена. Эти мотивы влияют на степень транскрибирования этой области в мРНК. Усилитель элементы, далекие от промотора, также могут регулировать экспрессию генов посредством трехмерных петлевых взаимодействий. Эти взаимодействия можно определить с помощью биоинформатического анализа захват конформации хромосомы эксперименты.
Данные экспрессии могут использоваться для вывода о регуляции генов: можно сравнить микрочип данные из широкого спектра состояний организма для формирования гипотез о генах, участвующих в каждом состоянии. В одноклеточном организме можно сравнить стадии развития клеточный цикл, наряду с различными стрессовыми состояниями (тепловой шок, голодание и др.). Затем можно применить алгоритмы кластеризации к этим данным экспрессии, чтобы определить, какие гены коэкспрессируются. Например, в вышестоящих областях (промоторах) коэкспрессируемых генов можно искать избыточно представленные регулирующие элементы. Примеры алгоритмов кластеризации, применяемых при кластеризации генов: k-означает кластеризацию, самоорганизующиеся карты (SOM), иерархическая кластеризация, и консенсусная кластеризация методы.
Анализ клеточной организации
Было разработано несколько подходов к анализу расположения органелл, генов, белков и других компонентов внутри клеток. Это актуально, поскольку расположение этих компонентов влияет на события в клетке и, таким образом, помогает нам предсказать поведение биологических систем. А генная онтология категория клеточный компонент, был разработан для захвата субклеточной локализации во многих биологические базы данных.
Микроскопия и анализ изображений
Микроскопические снимки позволяют нам определить местонахождение обоих органеллы а также молекулы. Это также может помочь нам различать нормальные и аномальные клетки, например в рак.
Локализация белка
Локализация белков помогает нам оценить роль белка. Например, если белок обнаружен в ядро он может быть вовлечен в генная регуляция или же сращивание. Напротив, если белок обнаружен в митохондрии, он может быть вовлечен в дыхание или другой метаболические процессы. Таким образом, локализация белка является важным компонентом прогноз функции белка. Есть хорошо развитые прогноз субклеточной локализации белка доступные ресурсы, в том числе базы данных о субклеточном расположении белков и инструменты для прогнозирования.[36][37]
Ядерная организация хроматина
Данные с высокой пропускной способностью захват конформации хромосомы эксперименты, такие как Hi-C (эксперимент) и ЧИА-ПЭТ, может предоставить информацию о пространственной близости локусов ДНК. Анализ этих экспериментов может определить трехмерную структуру и ядерная организация хроматина. Биоинформатические проблемы в этой области включают разделение генома на домены, такие как Топологически связывающие домены (TAD), которые организованы вместе в трехмерном пространстве.[38]
Структурная биоинформатика
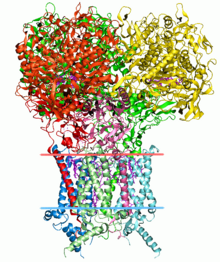
Прогнозирование структуры белков - еще одно важное приложение биоинформатики. В аминокислота последовательность белка, так называемая первичная структура, может быть легко определен по последовательности гена, который его кодирует.В подавляющем большинстве случаев эта первичная структура однозначно определяет структуру в ее естественной среде. (Конечно, есть исключения, такие как губчатая энцефалопатия (коровье бешенство) прион.) Знание этой структуры жизненно важно для понимания функции белка. Структурная информация обычно относится к одной из вторичный, высшее и четвертичный структура. Жизнеспособное общее решение таких прогнозов остается открытой проблемой. Большинство усилий до сих пор было направлено на эвристику, которая работает большую часть времени.[нужна цитата ]
Одна из ключевых идей в биоинформатике - понятие гомология. В геномной ветви биоинформатики гомология используется для прогнозирования функции гена: если последовательность гена А, функция которого известна, гомологична последовательности гена B, чья функция неизвестна, можно сделать вывод, что B может разделять функцию A. В структурной ветви биоинформатики гомология используется для определения того, какие части белка важны для формирования структуры и взаимодействия с другими белками. В технике, называемой моделирование гомологии, эта информация используется для прогнозирования структуры белка, если известна структура гомологичного белка. В настоящее время это единственный способ надежно предсказать структуру белка.
Одним из примеров этого является гемоглобин у людей и гемоглобин в бобовых (леггемоглобин ), которые являются дальними родственниками из того же белковое суперсемейство. Оба служат одной и той же цели - транспортировке кислорода в организме. Хотя оба этих белка имеют совершенно разные аминокислотные последовательности, их белковые структуры практически идентичны, что отражает их почти идентичные цели и общего предка.[39]
Другие методы прогнозирования структуры белка включают продвижение белков и de novo (с нуля) моделирование на основе физики.
Другой аспект структурной биоинформатики включает использование белковых структур для Виртуальный просмотр такие модели как Количественная взаимосвязь структура-деятельность модели и протеохимометрические модели (ПКМ). Кроме того, кристаллическую структуру белка можно использовать в моделировании, например, исследований связывания лиганда и in silico исследования мутагенеза.
Сетевая и системная биология
Сетевой анализ стремится понять отношения внутри биологические сети Такие как метаболический или же сети белок-белкового взаимодействия. Хотя биологические сети могут быть построены из одного типа молекулы или объекта (например, генов), сетевая биология часто пытается интегрировать множество различных типов данных, таких как белки, небольшие молекулы, данные экспрессии генов и другие, которые все связаны физически. , функционально или и то, и другое.
Системная биология предполагает использование компьютерное моделирование из сотовый подсистемы (такие как сети метаболитов и ферменты которые включают метаболизм, преобразование сигнала пути и сети регуляции генов ) для анализа и визуализации сложных связей этих клеточных процессов. Искусственная жизнь или виртуальная эволюция пытается понять эволюционные процессы с помощью компьютерного моделирования простых (искусственных) форм жизни.
Сети молекулярного взаимодействия

Десятки тысяч трехмерных белковых структур были определены Рентгеновская кристаллография и спектроскопия ядерного магнитного резонанса белков (ЯМР белков), и центральный вопрос в структурной биоинформатике - это практично ли предсказывать возможные межбелковые взаимодействия только на основе этих трехмерных форм, не выполняя белок-белковое взаимодействие эксперименты. Были разработаны различные методы для решения белок-белковая стыковка проблема, хотя кажется, что в этой области еще много работы.
Другие взаимодействия, встречающиеся в этой области, включают белок-лиганд (включая лекарство) и белок-пептид. Молекулярно-динамическое моделирование движения атомов вокруг вращающихся связей является фундаментальным принципом вычислительной алгоритмы, называемые алгоритмами стыковки, для изучения молекулярные взаимодействия.
Другие
Анализ литературы
Рост количества опубликованной литературы делает практически невозможным прочитать каждую статью, что приводит к разрозненным разделам исследований. Литературный анализ направлен на использование вычислительной и статистической лингвистики для добычи этой растущей библиотеки текстовых ресурсов. Например:
- Распознавание сокращений - определение полной формы и сокращения биологических терминов
- Распознавание именованных объектов - распознавание биологических терминов, таких как названия генов
- Белок-белковое взаимодействие - определите, какие белки взаимодействовать с какими белками из текста
Область исследования опирается на статистика и компьютерная лингвистика.
Высокопроизводительный анализ изображений
Вычислительные технологии используются для ускорения или полной автоматизации обработки, количественной оценки и анализа больших объемов информационного содержания. биомедицинские изображения. Современное анализ изображений системы расширяют возможности наблюдателя проводить измерения на основе большого или сложного набора изображений, улучшая точность, объективность, или скорость. Полностью разработанная система анализа может полностью заменить наблюдателя. Хотя эти системы не являются уникальными для биомедицинских изображений, биомедицинские изображения становятся все более важными для обоих. диагностика и исследования. Вот несколько примеров:
- высокая производительность и точность количественной оценки и субклеточная локализация (высококонтентный просмотр, цитогистопатология, Информатика биоизображений )
- морфометрия
- анализ и визуализация клинических изображений
- определение режимов воздушного потока в дыхательных легких живых животных в реальном времени
- количественная оценка размера окклюзии в изображениях в реальном времени при развитии и восстановлении после повреждения артерии
- проведение поведенческих наблюдений на основе расширенных видеозаписей лабораторных животных
- инфракрасные измерения для определения метаболической активности
- вывод клонов перекрывается в Картирование ДНК, например то Счет Сулстона
Высокопроизводительный анализ данных отдельных ячеек
Вычислительные методы используются для анализа данных отдельных ячеек с высокой пропускной способностью и малым объемом измерений, например, полученных из проточной цитометрии. Эти методы обычно включают обнаружение популяций клеток, соответствующих определенному болезненному состоянию или экспериментальному состоянию.
Информатика биоразнообразия
Информатика биоразнообразия занимается сбором и анализом биоразнообразие данные, такие как таксономические базы данных, или же микробиом данные. Примеры таких анализов включают: филогенетика, нишевое моделирование, видовое богатство отображение Штрих-кодирование ДНК, или же разновидность средства идентификации.
Онтологии и интеграция данных
Биологические онтологии ориентированные ациклические графы из контролируемые словари. Они предназначены для сбора биологических концепций и описаний таким образом, чтобы их можно было легко классифицировать и анализировать с помощью компьютеров. При такой классификации можно получить дополнительную ценность от целостного и комплексного анализа.
В OBO Foundry была попыткой стандартизировать определенные онтологии. Одним из самых распространенных является Генная онтология который описывает функцию гена. Существуют также онтологии, описывающие фенотипы.
Базы данных
Базы данных необходимы для исследований и приложений в области биоинформатики. Существует множество баз данных, охватывающих различные типы информации: например, последовательности ДНК и белков, молекулярные структуры, фенотипы и биоразнообразие. Базы данных могут содержать эмпирические данные (полученные непосредственно из экспериментов), предсказанные данные (полученные в результате анализа) или, как правило, и то, и другое. Они могут быть специфичными для конкретного организма, представляющего интерес пути или молекулы. Кроме того, они могут включать данные, собранные из нескольких других баз данных. Эти базы данных различаются по своему формату, механизму доступа и тому, являются ли они общедоступными или нет.
Некоторые из наиболее часто используемых баз данных перечислены ниже. Для более полного списка, пожалуйста, проверьте ссылку в начале подраздела.
- Используется в анализе биологической последовательности: Генбанк, UniProt
- Используется в структурном анализе: Банк данных белков (PDB)
- Используется для поиска семейств белков и Мотив Нахождение: ИнтерПро, Pfam
- Используется для секвенирования следующего поколения: Последовательность чтения из архива
- Используется в сетевом анализе: базы данных метаболических путей (КЕГГ, BioCyc ), Базы данных анализа взаимодействия, Функциональные сети
- Используется при разработке синтетических генетических цепей: GenoCAD
Программное обеспечение и инструменты
Программные средства для биоинформатики варьируются от простых инструментов командной строки до более сложных графических программ и автономных веб-сервисов, доступных из различных биоинформатические компании или государственные учреждения.
Программное обеспечение для биоинформатики с открытым исходным кодом
Много бесплатное программное обеспечение с открытым исходным кодом инструменты существуют и продолжают расти с 1980-х годов.[40] Сочетание постоянной потребности в новых алгоритмы для анализа появляющихся типов биологических считывателей, потенциал инновационных in silico эксперименты, и в свободном доступе открытый код Базы помогли создать возможности для всех исследовательских групп внести свой вклад как в биоинформатику, так и в диапазон доступного программного обеспечения с открытым исходным кодом, независимо от их механизмов финансирования. Инструменты с открытым исходным кодом часто действуют как инкубаторы идей или поддерживаются сообществом. плагины в коммерческих приложениях. Они также могут предоставить де-факто стандарты и общие объектные модели для помощи в решении проблемы интеграции биоинформации.
В ряд пакетов программного обеспечения с открытым исходным кодом включает такие заголовки, как Биокондуктор, BioPerl, Биопайтон, BioJava, BioJS, BioRuby, Биоклипс, EMBOSS, .NET Bio, апельсин с его надстройкой биоинформатики, Apache Taverna, UGENE и GenoCAD. Чтобы сохранить эту традицию и создать новые возможности, некоммерческая Фонд открытой биоинформатики[40] поддержали ежегодный Конференция по биоинформатике с открытым исходным кодом (BOSC) с 2000 года.[41]
Альтернативный метод создания общедоступных баз данных биоинформатики - использование движка MediaWiki с WikiOpener расширение. Эта система позволяет всем специалистам в данной области получать доступ к базе данных и обновлять ее.[42]
Веб-сервисы в биоинформатике
МЫЛО - и ОТДЫХ Интерфейсы на основе были разработаны для широкого спектра приложений биоинформатики, что позволяет приложению, работающему на одном компьютере в одной части мира, использовать алгоритмы, данные и вычислительные ресурсы на серверах в других частях мира. Основные преимущества заключаются в том, что конечным пользователям не приходится иметь дело с накладными расходами на программное обеспечение и обслуживание баз данных.
Базовые услуги в области биоинформатики классифицируются по EBI на три категории: SSS (Службы поиска последовательности), MSA (Выравнивание нескольких последовательностей) и BSA (Анализ биологической последовательности).[43] Наличие этих сервис-ориентированный Ресурсы по биоинформатике демонстрируют применимость веб-решений для биоинформатики и варьируются от набора автономных инструментов с общим форматом данных в едином автономном или веб-интерфейсе до интегрируемых, распределенных и расширяемых системы управления рабочими процессами биоинформатики.
Системы управления рабочим процессом биоинформатики
А система управления рабочим процессом биоинформатики это специализированная форма система управления рабочим процессом разработан специально для составления и выполнения серии этапов вычислений или обработки данных или рабочего процесса в приложении биоинформатики. Такие системы предназначены для
- предоставить простую в использовании среду, позволяющую самим разработчикам приложений создавать свои собственные рабочие процессы,
- предоставить ученым интерактивные инструменты, позволяющие им выполнять свои рабочие процессы и просматривать свои результаты в режиме реального времени,
- упростить процесс обмена и повторного использования рабочих процессов между учеными, и
- позволить ученым отслеживать происхождение результатов выполнения рабочего процесса и этапов создания рабочего процесса.
Некоторые из платформ, предоставляющих эту услугу: Галактика, Кеплер, Таверна, UGENE, Андурил, Улей.
Объекты BioCompute и BioCompute
В 2014 г. Управление по санитарному надзору за качеством пищевых продуктов и медикаментов США спонсировал конференцию, проведенную в Национальные институты здоровья Bethesda Campus, чтобы обсудить воспроизводимость в биоинформатике.[44] В течение следующих трех лет консорциум заинтересованных сторон регулярно встречался, чтобы обсудить, что станет парадигмой BioCompute.[45] Эти заинтересованные стороны включали представителей правительства, промышленности и академических организаций. Руководители сессий представляли многочисленные отделения институтов и центров FDA и NIH, некоммерческих организаций, включая Проект человеческого вариома и Европейская федерация медицинской информатики, и исследовательские институты, включая Стэнфорд, то Нью-Йоркский центр генома, а Университет Джорджа Вашингтона.
Было решено, что парадигма BioCompute будет иметь форму цифровых «лабораторных тетрадей», которые позволят воспроизводить, воспроизводить, просматривать и повторно использовать протоколы биоинформатики. Это было предложено для обеспечения большей преемственности внутри исследовательской группы в течение обычного потока персонала, способствуя обмену идеями между группами. FDA США профинансировало эту работу, чтобы информация о трубопроводах была более прозрачной и доступной для их регулирующего персонала.[46]
В 2016 году группа вновь собралась в NIH в Bethesda и обсудила потенциал Объект BioCompute, пример парадигмы BioCompute. Эта работа была скопирована как документ для «стандартного пробного использования» и как препринт, загруженный в bioRxiv. Объект BioCompute позволяет делиться записью в формате JSON между сотрудниками, сотрудниками и регулирующими органами.[47][48]
Образовательные платформы
Программные платформы, предназначенные для обучения концепциям и методам биоинформатики, включают: Розалинда и онлайн-курсы, предлагаемые через Швейцарский институт биоинформатики Учебный портал. В Канадские семинары по биоинформатике предоставляет видео и слайды с обучающих семинаров на своем веб-сайте в разделе Creative Commons лицензия. Проект 4273π или проект 4273pi[49] также предлагает бесплатные образовательные материалы с открытым исходным кодом. Курс работает по низкой цене Raspberry Pi компьютеры и использовались для обучения взрослых и школьников.[50][51] 4273π активно разрабатывается консорциумом ученых и исследователей, которые занимались биоинформатикой исследовательского уровня с использованием компьютеров Raspberry Pi и операционной системы 4273π.[52][53]
МООК платформы также предоставляют онлайн-сертификаты по биоинформатике и смежным дисциплинам, включая Coursera специализация "Биоинформатика" (Калифорнийский университет в Сан-Диего ) и специализация по науке о геномных данных (Джонс Хопкинс ) а также EdX Анализ данных для Life Sciences XSeries (Гарвард ). Университет Южной Калифорнии предлагает Магистр трансляционной биоинформатики с упором на биомедицинские приложения.
Конференции
Есть несколько крупных конференций, посвященных биоинформатике. Некоторые из наиболее ярких примеров: Интеллектуальные системы для молекулярной биологии (ISMB), Европейская конференция по вычислительной биологии (ECCB) и Исследования в области вычислительной молекулярной биологии (РЕКОМБ).
Смотрите также
- Информатика биоразнообразия
- Биоинформатические компании
- Вычислительная биология
- Вычислительное биомоделирование
- Вычислительная геномика
- Кибербиобезопасность
- Функциональная геномика
- Информатика здоровья
- Международное общество вычислительной биологии
- Библиотека прыжков
- Список институтов биоинформатики
- Список программного обеспечения для биоинформатики с открытым исходным кодом
- Список журналов по биоинформатике
- Метаболомика
- Последовательность нуклеиновой кислоты
- Филогенетика
- Протеомика
- База данных генных болезней
Рекомендации
- ^ Леск, А. М. (26 июля 2013 г.). «Биоинформатика». Британская энциклопедия.
- ^ а б Sim, A. Y. L .; Minary, P .; Левитт, М. (2012). «Моделирование нуклеиновых кислот». Текущее мнение в структурной биологии. 22 (3): 273–78. Дои:10.1016 / j.sbi.2012.03.012. ЧВК 4028509. PMID 22538125.
- ^ Dawson, W. K .; Maciejczyk, M .; Jankowska, E.J .; Буйницки, Дж. М. (2016). «Грубое моделирование трехмерной структуры РНК». Методы. 103: 138–56. Дои:10.1016 / j.ymeth.2016.04.026. PMID 27125734.
- ^ Kmiecik, S .; Gront, D .; Колинский, М .; Wieteska, L .; Dawid, A.E .; Колинский, А. (2016). «Крупнозернистые модели белков и их применение». Химические обзоры. 116 (14): 7898–936. Дои:10.1021 / acs.chemrev.6b00163. PMID 27333362.
- ^ Вонг, К. С. (2016). Вычислительная биология и биоинформатика: регуляция генов. CRC Press / Taylor & Francis Group. ISBN 9781498724975.
- ^ Joyce, A. P .; Zhang, C .; Bradley, P .; Гавранек, Дж. Дж. (2015). «Структурное моделирование белка: специфичность ДНК». Брифинги по функциональной геномике. 14 (1): 39–49. Дои:10.1093 / bfgp / elu044. ЧВК 4366589. PMID 25414269.
- ^ Spiga, E .; Degiacomi, M. T .; Даль Пераро, М. (2014). «Новые стратегии интегрального динамического моделирования сборки макромолекул». В Карабенчева-Христова, Т. (ред.). Биомолекулярное моделирование и симуляции. Достижения в химии белков и структурной биологии. 96. Академическая пресса. С. 77–111. Дои:10.1016 / bs.apcsb.2014.06.008. ISBN 9780128000137. PMID 25443955.
- ^ Ciemny, Maciej; Курчинский, Матеуш; Камель, Кароль; Колинский, Анджей; Алам, Навсад; Шулер-Фурман, Ора; Кмечик, Себастьян (4 мая 2018 г.). «Белок-пептидный докинг: возможности и проблемы». Открытие наркотиков сегодня. 23 (8): 1530–37. Дои:10.1016 / j.drudis.2018.05.006. ISSN 1359-6446. PMID 29733895.
- ^ а б Hogeweg P (2011). Сирлс, Дэвид Б. (ред.). «Корни биоинформатики в теоретической биологии». PLOS вычислительная биология. 7 (3): e1002021. Bibcode:2011PLSCB ... 7E2021H. Дои:10.1371 / journal.pcbi.1002021. ЧВК 3068925. PMID 21483479.
- ^ Хеспер Б., Хогевег П. (1970). «Биоинформатика: концепция работы». 1 (6). Камелеон: 28–29. Цитировать журнал требует
| журнал =(помощь) - ^ Hogeweg P (1978). «Моделирование роста клеточных форм». Моделирование. 31 (3): 90–96. Дои:10.1177/003754977803100305. S2CID 61206099.
- ^ Муди, Глин (2004). Цифровой код жизни: как биоинформатика революционизирует науку, медицину и бизнес. ISBN 978-0-471-32788-2.
- ^ Dayhoff, M.O. (1966) Атлас последовательности и структуры белков. Национальный фонд биомедицинских исследований, 215 стр.
- ^ Эк Р.В., Дайхофф МО (1966). «Эволюция структуры ферредоксина на основе живых остатков примитивных аминокислотных последовательностей». Наука. 152 (3720): 363–66. Bibcode:1966Научный ... 152..363E. Дои:10.1126 / science.152.3720.363. PMID 17775169. S2CID 23208558.
- ^ Джонсон Г., Ву Т. Т. (январь 2000 г.). «База данных Kabat и ее приложения: 30 лет после первого графика изменчивости». Нуклеиновые кислоты Res. 28 (1): 214–18. Дои:10.1093 / nar / 28.1.214. ЧВК 102431. PMID 10592229.
- ^ Эриксон, JW; Альтман, GG (1979). «Поиск паттернов в нуклеотидной последовательности генома MS2». Журнал математической биологии. 7 (3): 219–230. Дои:10.1007 / BF00275725. S2CID 85199492.
- ^ Шульман, MJ; Стейнберг, CM; Уэстморленд, Н. (1981). «Функция кодирования нуклеотидных последовательностей может быть определена с помощью статистического анализа». Журнал теоретической биологии. 88 (3): 409–420. Дои:10.1016/0022-5193(81)90274-5. PMID 6456380.
- ^ Сюн, Цзинь (2006). Основная биоинформатика. Кембридж, Соединенное Королевство: Издательство Кембриджского университета. стр.4. ISBN 978-0-511-16815-4 - через Интернет-архив.
- ^ Сэнгер Ф., Air GM, Баррелл Б.Г., Браун Н.Л., Колсон А.Р., Фиддес, Калифорния, Хатчисон, Калифорния, Слокомб П.М., Смит М. (февраль 1977 г.). «Нуклеотидная последовательность ДНК бактериофага phi X174». Природа. 265 (5596): 687–95. Bibcode:1977Натура.265..687С. Дои:10.1038 / 265687a0. PMID 870828. S2CID 4206886.
- ^ Benson DA, Karsch-Mizrachi I, Lipman DJ, Ostell J, Wheeler DL (январь 2008 г.). «ГенБанк». Нуклеиновые кислоты Res. 36 (Выпуск базы данных): D25–30. Дои:10.1093 / нар / гкм929. ЧВК 2238942. PMID 18073190.
- ^ а б c Флейшманн Р.Д., Адамс, доктор медицины, Уайт О., Клейтон Р.А., Киркнесс Э.Ф., Керлаваж А.Р., Булт С.Дж., Могила Д.Ф., Догерти Б.А., Меррик Дж.М. (июль 1995 г.). «Полногеномное случайное секвенирование и сборка Haemophilus influenzae Rd». Наука. 269 (5223): 496–512. Bibcode:1995Научный ... 269..496F. Дои:10.1126 / science.7542800. PMID 7542800.
- ^ Карвахаль-Родригес А (2012). «Моделирование генов и геномов вперед во времени». Текущая геномика. 11 (1): 58–61. Дои:10.2174/138920210790218007. ЧВК 2851118. PMID 20808525.
- ^ Браун, TA (2002). «Мутация, ремонт и рекомбинация». Геномы (2-е изд.). Манчестер (Великобритания): Оксфорд.
- ^ Carter, N.P .; Fiegler, H .; Пайпер, Дж. (2002). «Сравнительный анализ технологий сравнительной геномной гибридизации на микрочипах: отчет о семинаре, спонсируемом фондом Wellcome Trust». Цитометрия Часть А. 49 (2): 43–48. Дои:10.1002 / cyto.10153. PMID 12357458.
- ^ Чаудхари Нарендракумар М., Кумар Гупта Винод, Дутта Читра (2016). «BPGA - сверхбыстрый конвейер пангеномного анализа». Научные отчеты. 6: 24373. Bibcode:2016НатСР ... 624373C. Дои:10.1038 / srep24373. ЧВК 4829868. PMID 27071527.CS1 maint: несколько имен: список авторов (связь)
- ^ Астон К.И. (2014). «Генетическая предрасположенность к мужскому бесплодию: новости из полногеномных исследований ассоциации». Андрология. 2 (3): 315–21. Дои:10.1111 / j.2047-2927.2014.00188.x. PMID 24574159. S2CID 206007180.
- ^ Верон А., Блейн С., Кокс Д. Г. (2014). «Общегеномные ассоциации и клиника: в центре внимания рак груди». Биомаркеры в медицине. 8 (2): 287–96. Дои:10.2217 / bmm.13.121. PMID 24521025.
- ^ Tosto G, Reitz C (2013). «Полногеномные исследования ассоциации при болезни Альцгеймера: обзор». Текущие отчеты по неврологии и неврологии. 13 (10): 381. Дои:10.1007 / s11910-013-0381-0. ЧВК 3809844. PMID 23954969.
- ^ Лондин Э, Ядав П., Суррей С., Кричка Л. Дж., Фортина П. (2013). Использование анализа сцепления, полногеномных ассоциативных исследований и секвенирования следующего поколения для выявления болезнетворных мутаций. Фармакогеномика. Методы молекулярной биологии. 1015. С. 127–46. Дои:10.1007/978-1-62703-435-7_8. ISBN 978-1-62703-434-0. PMID 23824853.
- ^ Hindorff, L.A .; и другие. (2009). «Возможные этиологические и функциональные последствия полногеномных ассоциативных локусов для болезней и признаков человека». Proc. Natl. Акад. Sci. Соединенные Штаты Америки. 106 (23): 9362–67. Bibcode:2009PNAS..106.9362H. Дои:10.1073 / pnas.0903103106. ЧВК 2687147. PMID 19474294.
- ^ Холл, Л. (2010). «Поиск правильных генов для прогнозирования болезней и прогнозов». 2010 Международная конференция по системным наукам и технике. Системные науки и инженерия (ICSSE), Международная конференция 2010 г.. С. 1–2. Дои:10.1109 / ICSSE.2010.5551766. ISBN 978-1-4244-6472-2. S2CID 21622726.
- ^ Васкес, Мигель; Торре, Виктор де ла; Валенсия, Альфонсо (27 декабря 2012 г.). «Глава 14: Анализ генома рака». PLOS вычислительная биология. 8 (12): e1002824. Bibcode:2012PLSCB ... 8E2824V. Дои:10.1371 / journal.pcbi.1002824. ISSN 1553-7358. ЧВК 3531315. PMID 23300415.
- ^ Hye-Jung, E.C .; Jaswinder, K .; Martin, K .; Самуэль, A.A; Марко, А.М. (2014). «Секвенирование второго поколения для анализа генома рака». В Деллере, Грэме; Берман, Джейсон Н .; Арчечи, Роберт Дж. (Ред.). Геномика рака. Бостон (США): Academic Press. С. 13–30. Дои:10.1016 / B978-0-12-396967-5.00002-5. ISBN 9780123969675.
- ^ Grau, J .; Ben-Gal, I .; Пощ, С .; Гроссе, И. (1 июля 2006 г.). «VOMBAT: прогнозирование сайтов связывания факторов транскрипции с использованием байесовских деревьев переменного порядка» (PDF). Исследования нуклеиновых кислот. 34 (Веб-сервер): W529 – W533. Дои:10.1093 / нар / gkl212. ЧВК 1538886. PMID 16845064.
- ^ "Атлас человеческого белка". www.proteinatlas.org. Получено 2 октября 2017.
- ^ «Клетка человека». www.proteinatlas.org. Получено 2 октября 2017.
- ^ Thul, Peter J .; Окессон, Ловиса; Викинг, Микаэла; Махдесян, Диана; Геладаки, Айкатерини; Блал, Хамму Айт; Алм, Тове; Асплунд, Анна; Бьорк, Ларс (26 мая 2017 г.). «Субклеточная карта протеома человека». Наука. 356 (6340): eaal3321. Дои:10.1126 / science.aal3321. PMID 28495876. S2CID 10744558.
- ^ Ау, Ферхат; Благородный, Уильям С. (2 сентября 2015 г.). «Методы анализа для изучения трехмерной архитектуры генома». Геномная биология. 16 (1): 183. Дои:10.1186 / s13059-015-0745-7. ЧВК 4556012. PMID 26328929.
- ^ Хой, JA; Робинсон, H; Трент Дж.Т., 3-й; Какар, S; Smagghe, BJ; Харгроув, MS (3 августа 2007 г.). «Гемоглобины растений: молекулярная летопись окаменелостей эволюции переноса кислорода». Журнал молекулярной биологии. 371 (1): 168–79. Дои:10.1016 / j.jmb.2007.05.029. PMID 17560601.
- ^ а б «Фонд открытой биоинформатики: О нас». Официальный веб-сайт. Фонд открытой биоинформатики. Получено 10 мая 2011.
- ^ «Фонд открытой биоинформатики: BOSC». Официальный веб-сайт. Фонд открытой биоинформатики. Получено 10 мая 2011.
- ^ Броэ, Сильвен; Баррио, Роланд; Моро, Ив (2010). «Базы биологических знаний с использованием вики: сочетание гибкости вики со структурой баз данных». Биоинформатика. 26 (17): 2210–11. Дои:10.1093 / биоинформатика / btq348. PMID 20591906.
- ^ Нисбет, Роберт (2009). «Биоинформатика». Справочник по приложениям статистического анализа и интеллектуального анализа данных. Джон Старейшина IV, Гэри Майнер. Академическая пресса. п. 328. ISBN 978-0080912035.
- ^ Комиссар, канцелярия. «Развитие нормативной науки - 24–25 сентября 2014 г. Открытый семинар: стандарты секвенирования нового поколения». www.fda.gov. Получено 30 ноября 2017.
- ^ Симонян, Ваган; Гокс, Джереми; Мазумдер, Раджа (2017). «Биокомпьютерные объекты - шаг к оценке и подтверждению биомедицинских научных вычислений». КПК Журнал фармацевтической науки и технологий. 71 (2): 136–46. Дои:10.5731 / pdajpst.2016.006734. ISSN 1079-7440. ЧВК 5510742. PMID 27974626.
- ^ Комиссар, канцелярия. «Развитие нормативной науки - разработка на уровне сообществ стандартов HTS для проверки данных и вычислений, а также поощрения взаимодействия». www.fda.gov. Получено 30 ноября 2017.
- ^ Альтеровиц, Гил; Дин, Деннис А .; Гобл, Кэрол; Крузо, Майкл Р .; Соиланд-Рейес, Стиан; Белл, Аманда; Хейс, Анаис; Кинг, Чарльз Хэдли С .; Йохансон, Элейн (4 октября 2017 г.). «Обеспечение прецизионной медицины посредством стандартного обмена информацией о происхождении, анализе и результатах NGS». bioRxiv 10.1101/191783.
- ^ Проект BioCompute Object (BCO) - это совместная и управляемая сообществом структура для стандартизации вычислительных данных HTS. 1. Спецификация BCO: руководство пользователя для понимания и создания B., биокомпьют-объекты, 3 сентября 2017 г.
- ^ Баркер, Д; Ferrier, D.E.K .; Holland, P.W; Mitchell, J.B.O; Plaisier, H; Ричи, М.Г .; Смарт, С.Д. (2013). «4273π: обучение биоинформатике на недорогом оборудовании ARM». BMC Bioinformatics. 14: 243. Дои:10.1186/1471-2105-14-243. ЧВК 3751261. PMID 23937194.
- ^ Баркер, Д; Олдерсон, Р.Г .; McDonagh, J.L; Plaisier, H; Комри, M.M; Дункан, L; Muirhead, G.T.P; Суини, С. (2015). «Практическая деятельность университетского уровня по биоинформатике приносит пользу добровольным группам школьников в последние 2 года обучения в школе». Международный журнал STEM-образования. 2 (17). Дои:10.1186 / s40594-015-0030-z.
- ^ McDonagh, J.L; Баркер, Д; Олдерсон, Р. (2016). «Доведение вычислительной науки до общественности». SpringerPlus. 5 (259): 259. Дои:10.1186 / s40064-016-1856-7. ЧВК 4775721. PMID 27006868.
- ^ Робсон, Дж. Ф .; Баркер, Д. (2015). «Сравнение содержания генов, кодирующих белок, в Chlamydia trachomatis и Protochlamydia amoebophila с использованием компьютера Raspberry Pi». BMC Research Notes. 8 (561): 561. Дои:10.1186 / s13104-015-1476-2. ЧВК 4604092. PMID 26462790.
- ^ Wregglesworth, K.M; Баркер, Д. (2015). «Сравнение кодирующих белок геномов двух зеленых серных бактерий, Chlorobium tepidum TLS и Pelodictyon phaeoclathratiforme BU-1». BMC Research Notes. 8 (565): 565. Дои:10.1186 / s13104-015-1535-8. ЧВК 4606965. PMID 26467441.
дальнейшее чтение
- Sehgal et al. : Структурные, филогенетические и стыковочные исследования активатора оксидазы D-аминокислот (DAOA), гена-кандидата шизофрении. Теоретическая биология и медицинское моделирование 2013 10: 3.
- Рауль Исеа Современное значение слова биоинформатика, Глобальный журнал перспективных исследований, 2015 г.
- Achuthsankar S Nair Вычислительная биология и биоинформатика - краткий обзор, Коммуникации компьютерного общества Индии, январь 2007 г.
- Алуру, Шринивас, изд. Справочник по вычислительной молекулярной биологии. Chapman & Hall / Crc, 2006. ISBN 1-58488-406-1 (Серия Chapman & Hall / Crc Computer and Information Science)
- Балди, П. и Брунак, С. Биоинформатика: подход машинного обучения, 2-е изд. MIT Press, 2001. ISBN 0-262-02506-X
- Барнс, М.Р. и Грей, И.С., ред., Биоинформатика для генетиков, первое издание. Wiley, 2003. ISBN 0-470-84394-2
- Баксеванис А.Д. и Уэллетт Б.Ф.Ф., ред., Биоинформатика: практическое руководство по анализу генов и белков, Третье издание. Wiley, 2005. ISBN 0-471-47878-4
- Баксеванис, А.Д., Пецко, Г.А., Стейн, Л.Д., и Стормо, Г.Д., ред., Текущие протоколы в биоинформатике. Wiley, 2007. ISBN 0-471-25093-7
- Кристианини, Н. и Хан, М. Введение в вычислительную геномику, Cambridge University Press, 2006. (ISBN 9780521671910 |ISBN 0-521-67191-4)
- Дурбин Р., С. Эдди, А. Крог и Г. Митчисон, Анализ биологической последовательности. Издательство Кембриджского университета, 1998. ISBN 0-521-62971-3
- Гилберт Д. (2004). «Программные ресурсы биоинформатики». Брифинги по биоинформатике. 5 (3): 300–304. Дои:10.1093 / bib / 5.3.300. PMID 15383216.
- Кидвелл, Э., Интеллектуальная биоинформатика: применение методов искусственного интеллекта к проблемам биоинформатики. Wiley, 2005. ISBN 0-470-02175-6
- Кохан и др. Микромассивы для интегративной геномики. MIT Press, 2002. ISBN 0-262-11271-X
- Lund, O. et al. Иммунологическая биоинформатика. MIT Press, 2005. ISBN 0-262-12280-4
- Пахтер, Лиор и Штурмфельс, Бернд. «Алгебраическая статистика для вычислительной биологии» Cambridge University Press, 2005. ISBN 0-521-85700-7
- Певзнер, Павел А. Вычислительная молекулярная биология: алгоритмический подход MIT Press, 2000. ISBN 0-262-16197-4
- Соинов, Л. Биоинформатика и распознавание образов объединяются Журнал исследований распознавания образов (JPRR ), Том 1 (1) 2006 стр. 37–41
- Стивенс, Халлам, Жизнь вне последовательности: история биоинформатики, основанная на данных, Чикаго: Издательство Чикагского университета, 2013 г. ISBN 9780226080208
- Тисдалл, Джеймс. "Начало Perl для биоинформатики" О'Рейли, 2001. ISBN 0-596-00080-4
- Катализирующий запрос на стыке вычислений и биологии (2005) Отчет CSTB
- Вычисление секретов жизни: вклад математических наук и вычислений в молекулярную биологию (1995)
- Основы вычислительной и системной биологии MIT курса
- Вычислительная биология: геномы, сети, курс без эволюции MIT
внешняя ссылка
| Библиотечные ресурсы о Биоинформатика |
- Аудио помощь
- Больше устных статей
 Словарное определение биоинформатика в Викисловарь
Словарное определение биоинформатика в Викисловарь Учебные материалы, связанные с Биоинформатика в Викиверситете
Учебные материалы, связанные с Биоинформатика в Викиверситете СМИ, связанные с Биоинформатика в Wikimedia Commons
СМИ, связанные с Биоинформатика в Wikimedia Commons- Портал ресурсов по биоинформатике (SIB)
| Геномика | |
|---|---|
| Биоинформатика | |
| Структурная биология | |
| Инструменты исследования | |
| Организации |
|
| |

Примечание. Этот шаблон примерно соответствует модели 2012 г. Система классификации вычислений ACM. | ||
| Аппаратное обеспечение |  | |
| Компьютерные системы организация | ||
| Сети | ||
| Организация программного обеспечения | ||
| Обозначения программного обеспечения и инструменты | ||
| Разработка программного обеспечения | ||
| Теория вычислений | ||
| Алгоритмы | ||
| Математика вычислений | ||
| Информация системы |
| |
| Безопасность | ||
| Человек – компьютер взаимодействие | ||
| Параллелизм | ||
| Искусственный интеллект | ||
| Машинное обучение | ||
| Графика | ||
| Применяемый вычисление |
| |