Прогноз структуры белка - Protein structure prediction
Эта статья ведущий раздел не адекватно подвести итог ключевые моменты его содержания. Пожалуйста, подумайте о расширении интереса до предоставить доступный обзор обо всех важных аспектах статьи. (Февраль 2017 г.) |
Эта статья должна быть обновлено. (Декабрь 2020 г.) |

Прогноз структуры белка (правильнее называть Вывод белков) - вывод о трехмерной структуре белок из его аминокислота последовательность - то есть предсказание ее складывание и это вторичный и третичная структура из его первичная структура. Прогнозирование структуры принципиально отличается от обратной задачи белковый дизайн. Прогнозирование структуры белка - одна из важнейших целей, преследуемых биоинформатика и теоретическая химия; это очень важно в лекарство (например, в дизайн лекарства ) и биотехнология (например, в оформлении романа ферменты ). Каждые два года эффективность существующих методов оценивается в CASP эксперимент (Критическая оценка методов предсказания структуры белка). Постоянная оценка веб-серверов предсказания структуры белков выполняется проектом сообщества. CAMEO3D.
Структура белка и терминология
Белки представляют собой цепочки аминокислоты объединились пептидные связи. Многие конформации этой цепи возможны из-за вращения цепи вокруг каждого Атом Cα. Именно эти конформационные изменения ответственны за различия в трехмерной структуре белков. Каждая аминокислота в цепи полярна, т. Е. Имеет разделенные положительно и отрицательно заряженные области со свободным карбонильная группа, который может действовать как акцептор водородной связи, и группа NH, которая может действовать как донор водородной связи. Следовательно, эти группы могут взаимодействовать в структуре белка. 20 аминокислот можно классифицировать по химическому составу боковой цепи, которая также играет важную структурную роль. Глицин занимает особое положение, так как имеет наименьшую боковую цепь, только один атом водорода, и, следовательно, может увеличивать локальную гибкость в структуре белка. Цистеин с другой стороны, может реагировать с другим остатком цистеина и, таким образом, образовывать поперечную связь, стабилизирующую всю структуру.
Структуру белка можно рассматривать как последовательность элементов вторичной структуры, таких как α-спирали и β-листы, которые вместе составляют общую трехмерную конфигурацию белковой цепи. В этих вторичных структурах между соседними аминокислотами образуются регулярные структуры Н-связей, и аминокислоты имеют одинаковые углы Φ и.
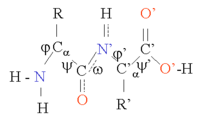
Формирование этих структур нейтрализует полярные группы каждой аминокислоты. Вторичные структуры плотно упакованы в ядре белка в гидрофобной среде. Каждая боковая группа аминокислоты имеет ограниченный объем для занятия и ограниченное количество возможных взаимодействий с другими соседними боковыми цепями, ситуацию, которую необходимо учитывать при молекулярном моделировании и выравнивании.[1]
α спираль
Спираль α - наиболее распространенный тип вторичной структуры белков. Спираль α содержит 3,6 аминокислоты на виток с образованием Н-связи между каждым четвертым остатком; средняя длина - 10 аминокислот (3 витка) или 10 Å но варьируется от 5 до 40 (от 1,5 до 11 оборотов). Выравнивание Н-связей создает дипольный момент для спирали, что приводит к частичному положительному заряду на амино-конце спирали. Поскольку в этом регионе есть бесплатный NH2 групп, он будет взаимодействовать с отрицательно заряженными группами, такими как фосфаты. Чаще всего α-спирали расположены на поверхности ядер белков, где они обеспечивают интерфейс с водной средой. Обращенная к внутренней стороне спираль имеет тенденцию содержать гидрофобные аминокислоты, а обращенная к внешней стороне сторона - гидрофильные аминокислоты. Таким образом, каждая третья из четырех аминокислот в цепи будет иметь тенденцию быть гидрофобной, и эту закономерность можно довольно легко обнаружить. В мотиве лейциновой застежки-молнии повторяющийся узор лейцинов на обращенных сторонах двух соседних спиралей очень хорошо предсказывает мотив. Чтобы показать этот повторяющийся узор, можно использовать график со спиральным колесом. Другие α-спирали, скрытые в ядре белка или в клеточных мембранах, имеют более высокое и более регулярное распределение гидрофобных аминокислот и очень предсказуемы для таких структур. Выступающие на поверхности спирали содержат меньшее количество гидрофобных аминокислот. Содержание аминокислот может указывать на наличие α-спиральной области. Регионы богаче аланин (А), глютаминовая кислота (E), лейцин (Земельные участки метионин (M) и беднее в пролин (П), глицин (ГРАММ), тирозин (Y) и серин (S) имеют тенденцию образовывать α-спираль. Пролин дестабилизирует или разрывает α-спираль, но может присутствовать в более длинных спиралях, образуя изгиб.
β лист
β-листы образованы Н-связями в среднем между 5–10 последовательными аминокислотами в одной части цепи и еще на 5–10 ниже по цепи. Взаимодействующие области могут быть смежными, с короткой петлей между ними или далеко друг от друга, с другими структурами между ними. Каждая цепь может идти в одном направлении, чтобы образовать параллельный лист, каждая другая цепь может идти в обратном химическом направлении, чтобы образовывать антипараллельный лист, или цепи могут быть параллельными и антипараллельными, чтобы образовывать смешанный лист. Рисунок H-соединения отличается в параллельной и антипараллельной конфигурациях. Каждая аминокислота во внутренних цепях листа образует две Н-связи с соседними аминокислотами, тогда как каждая аминокислота на внешних цепях образует только одну связь с внутренней цепью. Если смотреть поперек листа под прямым углом к прядям, более удаленные пряди слегка поворачиваются против часовой стрелки, чтобы образовать левый поворот. Атомы Cα чередуются над и под листом в складчатой структуре, а боковые группы R аминокислот чередуются над и под складками. Углы Φ и аминокислот в листах значительно различаются в одной области Рамачандран сюжет. Расположение β-листов сложнее предсказать, чем α-спиралей. Ситуация несколько улучшается, если принимать во внимание вариации аминокислот при множественном выравнивании последовательностей.
Петля
Петли - это участки белковой цепи, которые 1) находятся между α-спиралями и β-листами, 2) различной длины и трехмерной конфигурации и 3) на поверхности структуры.
Петли шпильки, которые представляют собой полный виток полипептидной цепи, соединяющей две антипараллельные β-цепи, могут иметь длину всего две аминокислоты. Петли взаимодействуют с окружающей водной средой и другими белками. Поскольку аминокислоты в петлях не ограничены пространством и окружающей средой, как аминокислоты в области ядра, и не влияют на расположение вторичных структур в ядре, может произойти больше замен, вставок и делеций. Таким образом, при выравнивании последовательностей наличие этих признаков может указывать на наличие петли. Позиции интроны в геномной ДНК иногда соответствуют положениям петель в кодируемом белке[нужна цитата ]. Петли также содержат заряженные и полярные аминокислоты и часто являются компонентом активных центров. Детальное изучение петлевых структур показало, что они делятся на отдельные семейства.
Катушки
Область вторичной структуры, которая не является α-спиралью, β-листом или узнаваемым витком, обычно называется спиралью.[1]
Классификация белков
Белки можно классифицировать как по структурному сходству, так и по сходству последовательностей. Для структурной классификации размеры и пространственное расположение вторичных структур, описанных в предыдущем абзаце, сравниваются с известными трехмерными структурами. Исторически первой использовалась классификация, основанная на сходстве последовательностей. Первоначально сходство было выполнено на основе выравнивания целых последовательностей. Позже белки были классифицированы на основе наличия консервативных аминокислотных паттернов. Базы данных которые классифицируют белки по одной или нескольким из этих схем. При рассмотрении схем классификации белков важно иметь в виду несколько наблюдений. Во-первых, две совершенно разные белковые последовательности из разного эволюционного происхождения могут складываться в похожую структуру. И наоборот, последовательность древнего гена данной структуры могла значительно отличаться у разных видов, в то же время сохраняя те же основные структурные особенности. Распознать любое остающееся сходство последовательностей в таких случаях может быть очень сложной задачей. Во-вторых, два белка, которые имеют значительную степень сходства последовательностей либо друг с другом, либо с третьей последовательностью, также имеют эволюционное происхождение и должны иметь общие структурные особенности. Однако дупликация генов и генетические перестройки во время эволюции могут привести к появлению новых копий генов, которые затем могут эволюционировать в белки с новой функцией и структурой.[1]
Термины, используемые для классификации структур и последовательностей белков
Ниже перечислены наиболее часто используемые термины для обозначения эволюционных и структурных отношений между белками. Многие дополнительные термины используются для обозначения различных структурных особенностей белков. Описание таких терминов можно найти на веб-сайте CATH, Структурная классификация белков (SCOP) веб-сайт и Glaxo Wellcome учебник на швейцарском веб-сайте Expasy по биоинформатике.
- Активный сайт
- локализованная комбинация боковых аминокислотных групп в третичной (трехмерной) или четвертичной (субъединица белка) структуре, которая может взаимодействовать с химически специфическим субстратом и придает белку биологическую активность. Белки с очень разными аминокислотными последовательностями могут складываться в структуру, продуцирующую один и тот же активный сайт.
- Архитектура
- - относительная ориентация вторичных структур в трехмерной структуре, независимо от того, имеют ли они аналогичную петлевую структуру.
- Сгиб (топология)
- тип архитектуры, который также имеет сохраненную структуру цикла.
- Блоки
- представляет собой консервативный образец аминокислотной последовательности в семействе белков. Шаблон включает серию возможных совпадений в каждой позиции в представленных последовательностях, но нет никаких вставленных или удаленных позиций в шаблоне или в последовательностях. Напротив, профили последовательностей представляют собой тип оценочной матрицы, которая представляет аналогичный набор шаблонов, который включает в себя вставки и удаления.
- Учебный класс
- термин, используемый для классификации белковых доменов в соответствии с их вторичным структурным содержанием и организацией. Четыре классы были первоначально признаны Левиттом и Чотиа (1976), а некоторые другие были добавлены в базу данных SCOP. В базе данных CATH даны три класса: в основном-α, в основном-β и α – β, причем класс α – β включает как чередующиеся структуры α / β, так и α + β.
- Основной
- часть свернутой белковой молекулы, которая включает гидрофобную внутреннюю часть α-спиралей и β-листов. Компактная структура объединяет боковые группы аминокислот на достаточно близком расстоянии, так что они могут взаимодействовать. При сравнении белковых структур, как в базе данных SCOP, ядро - это область, общая для большинства структур, имеющих общую складку или находящихся в одном суперсемействе. При прогнозировании структуры ядро иногда определяют как расположение вторичных структур, которые, вероятно, будут сохранены во время эволюционных изменений.
- Домен (контекст последовательности)
- сегмент полипептидной цепи, который может складываться в трехмерную структуру независимо от присутствия других сегментов цепи. Отдельные домены данного белка могут широко взаимодействовать или могут быть соединены только длиной полипептидной цепи. Белок с несколькими доменами может использовать эти домены для функционального взаимодействия с разными молекулами.
- Семья (контекст последовательности)
- группа белков со сходной биохимической функцией, которые идентичны более чем на 50% при выравнивании. Это же ограничение все еще используется Информационный ресурс о белках (PIR). Семейство белков включает белки с одинаковой функцией в разных организмах (ортологичные последовательности), но может также включать белки в том же организме (паралогичные последовательности), полученные в результате дупликации и перестройки генов. Если множественное выравнивание последовательностей семейства белков выявляет общий уровень сходства по всей длине белков, PIR относится к семейству как к гомеоморфному семейству. Выровненная область называется гомеоморфным доменом, и эта область может включать несколько меньших гомологических доменов, которые являются общими с другими семействами. Семейства могут быть дополнительно подразделены на подсемейства или сгруппированы в суперсемейства на основе соответствующих более высоких или более низких уровней сходства последовательностей. В базе данных SCOP указано 1296 семейств, а в базе данных CATH (версия 1.7 бета) - 1846 семейств.
- При более подробном изучении последовательностей белков с одинаковой функцией обнаруживается, что некоторые из них обладают высоким сходством последовательностей. Очевидно, что они являются членами одной семьи по указанным выше критериям. Однако обнаружены другие, которые имеют очень небольшое или даже незначительное сходство последовательностей с другими членами семейства. В таких случаях семейные отношения между двумя дальними членами семьи A и C часто можно продемонстрировать, найдя дополнительного члена семьи B, который имеет значительное сходство как с A, так и с C. Таким образом, B обеспечивает связующее звено между A и C. Другой подход заключается в изучении отдаленных выравниваний на предмет высококонсервативных совпадений.
- На уровне идентичности 50% белки, вероятно, будут иметь одинаковую трехмерную структуру, и идентичные атомы при выравнивании последовательностей также будут накладываться друг на друга в пределах приблизительно 1 Å в структурной модели. Таким образом, если структура одного члена семьи известна, надежный прогноз может быть сделан для второго члена семьи, и чем выше уровень идентичности, тем надежнее прогноз. Структурное моделирование белка может быть выполнено путем изучения того, насколько хорошо аминокислотные замены вписываются в ядро трехмерной структуры.
- Семья (структурный контекст)
- как используется в базе данных FSSP (Семейства структурно похожих белков ) и веб-сайт DALI / FSSP, две структуры, которые имеют значительный уровень структурного сходства, но не обязательно значительное сходство последовательностей.
- Складывать
- Подобно структурному мотиву, включает более крупную комбинацию вторичных структурных единиц в той же конфигурации. Таким образом, белки, имеющие одну и ту же складку, имеют одинаковую комбинацию вторичных структур, которые связаны подобными петлями. Примером может служить складка Россмана, состоящая из нескольких чередующихся α-спиралей и параллельных β-тяжей. В базах данных SCOP, CATH и FSSP известные белковые структуры классифицированы по иерархическим уровням структурной сложности, причем складка является базовым уровнем классификации.
- Гомологичный домен (контекст последовательности)
- расширенный паттерн последовательностей, обычно обнаруживаемый методами выравнивания последовательностей, который указывает на общее эволюционное происхождение выровненных последовательностей. Домен гомологии обычно длиннее, чем мотивы. Домен может включать в себя всю заданную последовательность белка или только часть последовательности. Некоторые домены сложны и состоят из нескольких более мелких гомологических доменов, которые соединились, чтобы сформировать более крупный в ходе эволюции. Область, покрывающая всю последовательность, называется гомеоморфной областью согласно PIR (Информационный ресурс о белках ).
- Модуль
- область консервативных аминокислотных паттернов, включающая один или несколько мотивов и рассматриваемая как фундаментальная единица структуры или функции. Наличие модуля также использовалось для классификации белков по семействам.
- Мотив (контекст последовательности)
- консервативный набор аминокислот, который содержится в двух или более белках. в Просайт В каталоге, мотив представляет собой аминокислотный паттерн, который обнаруживается в группе белков, обладающих сходной биохимической активностью, и часто находится рядом с активным центром белка. Примерами баз данных мотивов последовательностей являются каталог Prosite и база данных Stanford Motifs.[2]
- Мотив (структурный контекст)
- комбинация нескольких вторичных структурных элементов, полученных в результате сворачивания соседних участков полипептидной цепи в определенную трехмерную конфигурацию. Примером может служить мотив спираль-петля-спираль. Структурные мотивы также называют сверхвторичными структурами и складками.
- Матрица оценок для конкретной позиции (контекст последовательности, также известный как матрица весов или оценок)
- представляет собой консервативную область при множественном выравнивании последовательностей без пробелов. Каждый столбец матрицы представляет собой вариацию, обнаруженную в одном столбце множественного выравнивания последовательностей.
- Матрица оценки для конкретной позиции - 3D (структурный контекст)
- представляет собой аминокислотную вариацию, обнаруженную при выравнивании белков, которые попадают в один и тот же структурный класс. Столбцы матрицы представляют собой аминокислотные вариации, обнаруженные в одной аминокислотной позиции в выровненных структурах.
- Первичная структура
- линейная аминокислотная последовательность белка, который химически представляет собой полипептидную цепь, состоящую из аминокислот, соединенных пептидными связями.
- Профиль (контекст последовательности)
- оценочная матрица, которая представляет множественное выравнивание последовательностей семейства белков. Профиль обычно получают из хорошо консервативной области при множественном выравнивании последовательностей. Профиль представляет собой матрицу, в которой каждый столбец представляет позицию в выравнивании, а каждая строка - одна из аминокислот. Значения матрицы дают вероятность каждой аминокислоты в соответствующем положении в выравнивании. Профиль перемещается по целевой последовательности, чтобы найти области с лучшими оценками с помощью алгоритма динамического программирования. Во время сопоставления допускаются пропуски, и в этом случае в качестве отрицательной оценки включается штраф за пропуски, если ни одна аминокислота не сопоставлена. Профиль последовательности также может быть представлен скрытая марковская модель, именуемый профилем HMM.
- Профиль (структурный контекст)
- оценочная матрица, которая представляет, какие аминокислоты должны хорошо подходить, а какие - плохо подходить в последовательных положениях в известной структуре белка. Столбцы профиля представляют собой последовательные положения в структуре, а строки профиля представляют 20 аминокислот. Как и в случае профиля последовательности, структурный профиль перемещается вдоль целевой последовательности, чтобы найти максимально возможную оценку выравнивания с помощью алгоритма динамического программирования. Пробелы могут быть включены и получить штраф. Полученная оценка дает представление о том, может ли целевой белок принять такую структуру.
- Четвертичная структура
- трехмерная конфигурация белковой молекулы, состоящая из нескольких независимых полипептидных цепей.
- Вторичная структура
- взаимодействия, которые происходят между группами C, O и NH на аминокислотах в полипептидной цепи с образованием α-спиралей, β-листов, поворотов, петель и других форм, которые облегчают сворачивание в трехмерную структуру.
- Надсемейство
- группа семейств белков одинаковой или разной длины, которые связаны отдаленным, но обнаруживаемым сходством последовательностей. Члены данного надсемейство таким образом, имеют общее эволюционное происхождение. Первоначально Дайхофф определил границу для статуса суперсемейства как вероятность того, что последовательности не связаны между собой 10 6, на основании оценки выравнивания (Dayhoff et al. 1978). Белки с небольшим количеством идентичностей при выравнивании последовательностей, но с убедительно общим числом структурных и функциональных особенностей помещаются в одно и то же суперсемейство. На уровне трехмерной структуры белки суперсемейства будут иметь общие структурные особенности, такие как общая складка, но также могут быть различия в количестве и расположении вторичных структур. На ресурсе PIR используется термин гомеоморфные суперсемейства для обозначения суперсемейства, которые состоят из последовательностей, которые могут быть выровнены от конца до конца, что представляет собой общий домен гомологии одной последовательности, область сходства, которая распространяется на протяжении всего выравнивания. Этот домен может также включать более мелкие гомологические домены, общие с другими семействами белков и суперсемействами. Хотя данная белковая последовательность может содержать домены, обнаруженные в нескольких суперсемействах, что указывает на сложную эволюционную историю, последовательности будут отнесены только к одному гомеоморфному суперсемейству на основании наличия сходства на протяжении множественного выравнивания последовательностей. Выравнивание суперсемейства может также включать области, которые не выравниваются ни внутри, ни на концах выравнивания. Напротив, последовательности в одном семействе хорошо выравниваются на протяжении всего выравнивания.
- Супервторичная структура
- термин со значением, аналогичным структурному мотиву. Третичная структура - это трехмерная или глобулярная структура, образованная путем упаковки или сворачивания вторичных структур полипептидной цепи.[1]
Вторичная структура
Прогнозирование вторичной структуры это набор техник в биоинформатика которые стремятся предсказать местный второстепенные конструкции из белки основанный только на знании своих аминокислота последовательность. Для белков прогноз состоит в назначении участков аминокислотной последовательности как вероятных. альфа спирали, бета-нити (часто называемые «расширенными» конформациями), или повороты. Успех прогноза определяется путем его сравнения с результатами DSSP алгоритм (или аналогичный, например STRIDE ) применяется к Кристальная структура белка. Были разработаны специализированные алгоритмы для обнаружения конкретных четко определенных шаблонов, таких как трансмембранные спирали и спиральные катушки в белках.[1]
Лучшие современные методы предсказания вторичной структуры белков достигают точности около 80%;[3] такая высокая точность позволяет использовать прогнозы для улучшения характеристик распознавание складок и ab initio прогноз структуры белка, классификация структурные мотивы, и доработка выравнивание последовательностей. Точность существующих методов прогнозирования вторичной структуры белков оценивается еженедельно. ориентиры Такие как LiveBench и EVA.
Фон
Ранние методы прогнозирования вторичной структуры, представленные в 1960-х и начале 1970-х годов,[4][5][6][7][8] сосредоточены на идентификации вероятных альфа-спиралей и основаны в основном на модели перехода спираль-катушка.[9] Значительно более точные прогнозы, включающие бета-листы, были введены в 1970-х годах и основывались на статистических оценках, основанных на параметрах вероятности, полученных из известных решенных структур. Эти методы, применяемые к одной последовательности, обычно имеют точность не более 60-65% и часто недооценивают бета-листы.[1] В эволюционный сохранение вторичных структур можно использовать, одновременно оценивая многие гомологичные последовательности в множественное выравнивание последовательностей путем вычисления чистой склонности к вторичной структуре выровненного столбца аминокислот. В сочетании с более крупными базами данных известных белковых структур и современных машинное обучение такие методы как нейронные сети и опорные векторные машины, эти методы могут обеспечить до 80% общей точности в глобулярные белки.[10] Теоретический верхний предел точности составляет около 90%,[10] частично из-за идиосинкразии в назначении DSSP около концов вторичных структур, где локальные конформации меняются в естественных условиях, но могут быть вынуждены принимать единственную конформацию в кристаллах из-за ограничений упаковки. Ограничения также накладываются неспособностью прогнозирования вторичной структуры учитывать третичная структура; например, последовательность, предсказанная как вероятная спираль, может все еще быть способной принять конформацию бета-цепи, если она расположена в области бета-слоя белка и ее боковые цепи хорошо упаковываются со своими соседями. Резкие конформационные изменения, связанные с функцией или окружающей средой белка, также могут изменить локальную вторичную структуру.
Историческая перспектива
На сегодняшний день разработано более 20 различных методов прогнозирования вторичной структуры. Один из первых алгоритмов был Метод Чоу-Фасмана, который основан преимущественно на параметрах вероятности, определяемых по относительной частоте появления каждой аминокислоты в каждом типе вторичной структуры.[11] Исходные параметры Чоу-Фасмана, определенные на небольшой выборке структур, решенных в середине 1970-х годов, дают плохие результаты по сравнению с современными методами, хотя параметризация была обновлена с момента ее первой публикации. Метод Чоу-Фасмана дает примерно 50-60% точности при прогнозировании вторичных структур.[1]
Следующей заметной программой была Метод газового фактора, названный в честь трех ученых, которые его разработали - граммАрнье ОСгуторп и рObson, это теория информации -основанный метод. Он использует более мощный вероятностный метод Байесовский вывод.[12] Метод газового фактора учитывает не только вероятность того, что каждая аминокислота имеет определенную вторичную структуру, но и условная возможность аминокислоты, принимая каждую структуру с учетом вкладов ее соседей (это не предполагает, что соседи имеют такую же структуру). Подход и более чувствительный, и более точный, чем подход Чоу и Фасмана, потому что структурные склонности аминокислот сильны только для небольшого числа аминокислот, таких как пролин и глицин. Слабый вклад каждого из множества соседей может привести к сильным эффектам в целом. Первоначальный метод газового фактора был примерно на 65% точен и значительно более успешен в прогнозировании альфа-спиралей, чем бета-листов, которые он часто ошибочно предсказывал как петли или неорганизованные области.[1]
Еще один большой шаг вперед - использование машинное обучение методы. Первый искусственные нейронные сети использовались методы. В качестве обучающих наборов они используют решенные структуры для определения общих мотивов последовательностей, связанных с конкретными расположениями вторичных структур. Эти методы имеют точность более 70% в своих прогнозах, хотя бета-цепочки по-прежнему часто недооцениваются из-за отсутствия трехмерной структурной информации, которая позволила бы оценить водородная связь паттерны, которые могут способствовать формированию расширенной конформации, необходимой для наличия полного бета-листа.[1] PSIPRED и JPRED являются одними из наиболее известных программ, основанных на нейронных сетях для предсказания вторичной структуры белков. Следующий, опорные векторные машины оказались особенно полезными для прогнозирования местоположения повороты, которые сложно идентифицировать статистическими методами.[13][14]
Расширения методов машинного обучения пытаются предсказать более мелкие локальные свойства белков, такие как позвоночник двугранные углы в неназначенных регионах. Оба SVM[15] и нейронные сети[16] были применены к этой проблеме.[13] В последнее время реальные значения торсионных углов могут быть точно предсказаны с помощью SPINE-X и успешно использованы для предсказания структуры ab initio.[17]
Прочие улучшения
Сообщается, что помимо белковой последовательности формирование вторичной структуры зависит от других факторов. Например, сообщается, что тенденции вторичной структуры зависят также от местной среды,[18] доступность остатков для растворителей,[19] структурный класс белков,[20] и даже организм, из которого получены белки.[21] На основании таких наблюдений некоторые исследования показали, что предсказание вторичной структуры можно улучшить, добавив информацию о структурном классе белка,[22] остаточная доступная площадь поверхности[23][24] а также Контактный телефон Информация.[25]
Третичная структура
Практическая роль предсказания структуры белков сейчас важна как никогда[26]. Огромные объемы данных о последовательности белков производятся современными крупномасштабными ДНК упорядочение усилий, таких как Проект "Геном человека". Несмотря на усилия сообщества в структурная геномика, получение экспериментально определенных белковых структур - обычно трудоемким и относительно дорогим Рентгеновская кристаллография или же ЯМР-спектроскопия - сильно отстает от выхода белковых последовательностей.
Предсказание структуры белка остается чрезвычайно сложной и нерешенной задачей. Две основные проблемы - это расчет энергия без белков и найти глобальный минимум этой энергии. Метод предсказания структуры белка должен исследовать пространство возможных структур белка, которое астрономически большой. Эти проблемы можно частично обойти в «сравнительном» или моделирование гомологии и распознавание складок методы, в которых пространство поиска сокращается, исходя из предположения, что рассматриваемый белок принимает структуру, близкую к экспериментально определенной структуре другого гомологичного белка. С другой стороны, предсказание структуры белка de novo методы должны явно разрешать эти проблемы. Прогресс и проблемы в предсказании структуры белка были рассмотрены Чжаном.[27]
Перед моделированием
Большинство методов моделирования третичной структуры, такие как Rosetta, оптимизированы для моделирования третичной структуры отдельных белковых доменов. Шаг под названием парсинг домена, или же предсказание границы домена, обычно сначала делается для разделения белка на потенциальные структурные домены. Как и в случае остального прогнозирования третичной структуры, это можно сделать сравнительно с известными структурами.[28] или же ab initio только с последовательностью (обычно машинное обучение с помощью ковариации).[29] Структуры для отдельных доменов состыковываются вместе в процессе, называемом сборка домена чтобы сформировать окончательную третичную структуру.[30][31]
Ab initio моделирование белков
Энергетические и фрагментарные методы
Ab initio- или же de novo- методы моделирования белков направлены на построение трехмерных моделей белков «с нуля», то есть на основе физических принципов, а не (непосредственно) на ранее решенных структурах. Есть много возможных процедур, которые пытаются имитировать сворачивание белка или применить некоторые стохастический метод поиска возможных решений (т. е. глобальная оптимизация подходящей энергетической функции). Эти процедуры обычно требуют огромных вычислительных ресурсов и, таким образом, выполнялись только для крошечных белков. Предсказать структуру белка de novo для более крупных белков потребуются более совершенные алгоритмы и большие вычислительные ресурсы, подобные тем, которые предоставляются мощными суперкомпьютерами (такими как Синий ген или же МДГРАП-3 ) или распределенных вычислений (например, Складной @ дома, то Проект сворачивания протеома человека и Rosetta @ Home ). Хотя эти вычислительные барьеры огромны, потенциальные преимущества структурной геномики (с помощью предсказанных или экспериментальных методов) делают ab initio структурное предсказание - активная область исследований.[27]
С 2009 года белок из 50 остатков можно было моделировать атом за атомом на суперкомпьютере в течение 1 миллисекунды.[32] С 2012 года сопоставимая выборка в стабильном состоянии могла быть сделана на стандартном настольном компьютере с новой видеокартой и более сложными алгоритмами.[33] Значительно более длительные сроки моделирования могут быть достигнуты с помощью крупнозернистое моделирование.[34][35]
Эволюционная ковариация для предсказания трехмерных контактов
Поскольку в 1990-х годах секвенирование стало более обычным явлением, несколько групп использовали выравнивание последовательностей белков для предсказания коррелированных мутации и была надежда, что эти коэволюционирующие остатки могут быть использованы для предсказания третичной структуры (используя аналогию с ограничениями расстояния из экспериментальных процедур, таких как ЯМР ). Предполагается, что когда одинарные остаточные мутации слегка вредны, могут возникать компенсаторные мутации, чтобы повторно стабилизировать остаточные взаимодействия. В этой ранней работе использовалось то, что известно как местный методы для вычисления коррелированных мутаций из белковых последовательностей, но страдали от косвенных ложных корреляций, которые возникают в результате обработки каждой пары остатков как независимой от всех других пар.[36][37][38]
В 2011 году все было иначе, и на этот раз Глобальный Статистический подход продемонстрировал, что предсказанные коэволюционные остатки были достаточны для предсказания трехмерной укладки белка при условии, что имеется достаточно доступных последовательностей (требуется> 1000 гомологичных последовательностей).[39] Метод, EVfold, не использует моделирование гомологии, нити или фрагменты трехмерной структуры и может выполняться на стандартном персональном компьютере даже для белков с сотнями остатков. Точность контактов, предсказанных с использованием этого и связанных подходов, теперь продемонстрирована на многих известных структурах и картах контактов,[40][41][42] включая предсказание экспериментально неразрешенных трансмембранных белков.[43]
Сравнительное моделирование белков
При сравнительном моделировании белков в качестве отправных точек или шаблонов используются ранее решенные структуры. Это эффективно, поскольку кажется, что, хотя количество реальных белков огромно, существует ограниченный набор высшее структурные мотивы к которому принадлежит большинство белков. Было высказано предположение, что в природе существует только около 2000 различных белковых складок, хотя существует много миллионов различных белков. Сравнительное моделирование белков может сочетаться с эволюционной ковариацией в предсказании структуры.[44]
Эти методы также можно разделить на две группы:[27]
- Гомологическое моделирование основан на разумном предположении, что два гомологичный белки будут иметь очень похожие структуры. Поскольку складка белка более эволюционно консервативна, чем его аминокислотная последовательность, последовательность-мишень может быть смоделирована с разумной точностью на очень отдаленно родственной матрице, при условии, что связь между мишенью и матрицей может быть определена через выравнивание последовательностей. Было высказано предположение, что основное узкое место в сравнительном моделировании возникает из-за трудностей в выравнивании, а не из-за ошибок в прогнозировании структуры при заведомо хорошей согласованности.[45] Неудивительно, что моделирование гомологии является наиболее точным, когда цель и шаблон имеют похожие последовательности.
- Протеиновая нить[46] сканирует аминокислотную последовательность неизвестной структуры по базе данных решенных структур. В каждом случае функция подсчета очков используется для оценки совместимости последовательности со структурой, что позволяет получить возможные трехмерные модели. Этот тип метода также известен как Распознавание 3D-1D сгиба благодаря анализу совместимости трехмерных структур и линейных белковых последовательностей. Этот метод также породил методы, выполняющие поиск обратного сворачивания путем оценки совместимости данной структуры с большой базой данных последовательностей, тем самым предсказывая, какие последовательности потенциально могут создать данную складку.
Прогнозирование геометрии боковой цепи
Точная упаковка аминокислоты боковые цепи представляет собой отдельную проблему в предсказании структуры белка. Методы, которые конкретно решают проблему предсказания геометрии боковой цепи, включают: тупиковое устранение и самосогласованное среднее поле методы. Конформации боковых цепей с низкой энергией обычно определяют на жестком полипептидном скелете с использованием набора дискретных конформаций боковых цепей, известных как "ротамеры. "Методы пытаются идентифицировать набор ротамеров, которые минимизируют общую энергию модели.
В этих методах используются библиотеки ротамеров, которые представляют собой наборы подходящих конформаций для каждого типа остатков в белках. Библиотеки ротамеров могут содержать информацию о конформации, ее частоте и стандартных отклонениях средних двугранных углов, которые можно использовать при отборе проб.[47] Библиотеки ротамеров получены из структурная биоинформатика или другой статистический анализ конформаций боковых цепей в известных экспериментальных структурах белков, такой как кластеризация наблюдаемых конформаций для тетраэдрических атомов углерода около разнесенных (60 °, 180 °, -60 °) значений.
Библиотеки ротамеров могут быть независимыми от скелета, зависимыми от вторичной структуры или зависимыми от скелета. Независимые от скелета библиотеки ротамеров не ссылаются на конформацию скелета и рассчитываются из всех доступных боковых цепей определенного типа (например, первый пример библиотеки ротамеров, выполненный Ponder и Ричардс в Йельском университете в 1987 году).[48] Библиотеки, зависящие от вторичной структуры, представляют разные двугранные углы и / или частоты ротамеров для -спираль, листовые, или змеевиковые вторичные конструкции.[49] Библиотеки ротамеров, зависящие от скелета, представляют конформации и / или частоты, зависящие от локальной конформации скелета, как определено двугранными углами скелета и вне зависимости от вторичной структуры.[50]




Современные версии этих библиотек, используемые в большинстве программ, представлены в виде многомерных распределений вероятности или частоты, где пики соответствуют конформациям с двугранным углом, рассматриваемым в списках как отдельные ротамеры. Некоторые версии основаны на очень тщательно отобранных данных и используются в основном для проверки структуры,[51] в то время как другие подчеркивают относительные частоты в гораздо более крупных наборах данных и являются формой, используемой в основном для предсказания структуры, например, библиотеки ротамеров Данбрака.[52]
Методы упаковки боковых цепей наиболее полезны для анализа белков. гидрофобный ядро, где боковые цепи более плотно упакованы; им труднее обращать внимание на более свободные ограничения и более высокую гибкость поверхностных остатков, которые часто занимают несколько конформаций ротамера, а не только одну.[53][54]
Прогнозирование структурных классов
Статистические методы были разработаны для прогнозирования структурных классов белков на основе их аминокислотного состава.[55] псевдоаминокислотный состав[56][57][58][59] и состав функциональной области.[60] Предсказание вторичной структуры также неявно генерирует такое предсказание для особых областей.
Четвертичная структура
В случае комплексы двух или более белков, где структуры белков известны или могут быть предсказаны с высокой точностью, белок-белковая стыковка методы могут использоваться для прогнозирования структуры комплекса. Информация о влиянии мутаций в определенных сайтах на сродство комплекса помогает понять сложную структуру и определить методы стыковки.
Программного обеспечения
Существует большое количество программных инструментов для предсказания структуры белков. Подходы включают моделирование гомологии, белковая нить, ab initio методы, прогноз вторичной структуры и предсказание трансмембранной спирали и сигнального пептида. Некоторые недавние успешные методы, основанные на CASP эксперименты включают И-ТАССЕР, HHpred и AlphaFold. Полный список см. основная статья.
Оценка серверов автоматического прогнозирования структуры
CASP, который расшифровывается как «Критическая оценка методов прогнозирования структуры белка», представляет собой эксперимент для всего сообщества по прогнозированию структуры белка, который проводится каждые два года с 1994 года. CASP предоставляет возможность оценить качество доступной человеческой неавтоматизированной методологии (человек категория) и автоматические серверы для предсказания структуры белков (категория серверов, представленная в CASP7).[61]
В CAMEO3D Сервер непрерывной автоматизированной оценки модели еженедельно оценивает серверы автоматического прогнозирования структуры белка, используя слепые прогнозы для новых структур белка. CAMEO публикует результаты на своем веб-сайте.
Смотрите также
- Белковый дизайн
- Прогнозирование функции белков
- Программное обеспечение для предсказания структуры белка
- De novo предсказание структуры белка
- Программное обеспечение для молекулярного дизайна
- Программное обеспечение для молекулярного моделирования
- Моделирование биологических систем
- Библиотеки фрагментов
- Белки решетки
- Статистический потенциал
- Банк данных кругового дихроизма белков
- МОДЕЛЛЕР - компьютерная программа для моделирования гомологии
- Rosetta @ home
Рекомендации
- ^ а б c d е ж грамм час я Mount DM (2004). Биоинформатика: анализ последовательности и генома. 2. Лабораторный пресс Колд-Спринг-Харбор. ISBN 978-0-87969-712-9.
- ^ Хуанг Дж.Й., Brutlag DL (январь 2001 г.). «База данных EMOTIF». Исследования нуклеиновых кислот. 29 (1): 202–4. Дои:10.1093 / nar / 29.1.202. ЧВК 29837. PMID 11125091.
- ^ Пировано В., Херинга Дж. (2010). «Прогнозирование вторичной структуры белков». Методы интеллектуального анализа данных для наук о жизни. Методы молекулярной биологии. 609. С. 327–48. Дои:10.1007/978-1-60327-241-4_19. ISBN 978-1-60327-240-7. PMID 20221928.
- ^ Гуццо А.В. (ноябрь 1965 г.). «Влияние аминокислотной последовательности на структуру белка». Биофизический журнал. 5 (6): 809–22. Bibcode:1965BpJ ..... 5..809G. Дои:10.1016 / S0006-3495 (65) 86753-4. ЧВК 1367904. PMID 5884309.
- ^ Протеро JW (май 1966 г.). «Корреляция между распределением аминокислот и альфа-спиралей». Биофизический журнал. 6 (3): 367–70. Bibcode:1966БпДж ..... 6..367П. Дои:10.1016 / S0006-3495 (66) 86662-6. ЧВК 1367951. PMID 5962284.
- ^ Шиффер М., Эдмундсон А.Б. (март 1967 г.). «Использование спиральных колес для представления структур белков и идентификации сегментов со спиральным потенциалом». Биофизический журнал. 7 (2): 121–35. Bibcode:1967BpJ ..... 7..121S. Дои:10.1016 / S0006-3495 (67) 86579-2. ЧВК 1368002. PMID 6048867.
- ^ Котельчук Д., Щерага Н.А. (январь 1969 г.). «Влияние короткодействующих взаимодействий на образование белков. II. Модель для прогнозирования альфа-спиральных областей белков». Труды Национальной академии наук Соединенных Штатов Америки. 62 (1): 14–21. Bibcode:1969ПНАС ... 62 ... 14К. Дои:10.1073 / pnas.62.1.14. ЧВК 285948. PMID 5253650.
- ^ Льюис П.Н., Go N, Go M, Kotelchuck D, Scheraga HA (апрель 1970 г.). «Профили вероятности спирали денатурированных белков и их корреляция с нативными структурами». Труды Национальной академии наук Соединенных Штатов Америки. 65 (4): 810–5. Bibcode:1970ПНАС ... 65..810л. Дои:10.1073 / пнас.65.4.810. ЧВК 282987. PMID 5266152.
- ^ Фроймовиц М., Фасман Г.Д. (1974). «Предсказание вторичной структуры белков с использованием теории перехода спираль-клубок». Макромолекулы. 7 (5): 583–9. Bibcode:1974MaMol ... 7..583F. Дои:10.1021 / ma60041a009. PMID 4371089.
- ^ а б Дор О, Чжоу Й (март 2007 г.). «Достижение 80% -й десятикратной перекрестной проверенной точности для предсказания вторичной структуры с помощью крупномасштабного обучения». Белки. 66 (4): 838–45. Дои:10.1002 / prot.21298. PMID 17177203. S2CID 14759081.
- ^ Чжоу П. Я., Фасман Г. Д. (январь 1974 г.). «Прогнозирование конформации белков». Биохимия. 13 (2): 222–45. Дои:10.1021 / bi00699a002. PMID 4358940.
- ^ Гарнье Дж., Осгуторп Диджей, Робсон Б. (март 1978 г.). «Анализ точности и последствий простых методов для предсказания вторичной структуры глобулярных белков». Журнал молекулярной биологии. 120 (1): 97–120. Дои:10.1016/0022-2836(78)90297-8. PMID 642007.
- ^ а б Pham TH, Satou K, Ho TB (апрель 2005 г.). «Поддержка векторных машин для предсказания и анализа бета- и гамма-поворотов в белках». Журнал биоинформатики и вычислительной биологии. 3 (2): 343–58. Дои:10.1142 / S0219720005001089. PMID 15852509.
- ^ Чжан Кью, Юн С., Валлийский WJ (май 2005 г.). «Улучшенный метод прогнозирования бета-разворота с использованием машины опорных векторов». Биоинформатика. 21 (10): 2370–4. Дои:10.1093 / биоинформатика / bti358. PMID 15797917.
- ^ Zimmermann O, Hansmann UH (декабрь 2006 г.). «Вспомогательные векторные машины для предсказания областей двугранного угла». Биоинформатика. 22 (24): 3009–15. Дои:10.1093 / биоинформатика / btl489. PMID 17005536.
- ^ Куанг Р., Лесли К.С., Ян А.С. (июль 2004 г.). «Прогнозирование угла позвоночника белка с использованием подходов машинного обучения». Биоинформатика. 20 (10): 1612–21. Дои:10.1093 / биоинформатика / bth136. PMID 14988121.
- ^ Фарагги Э, Ян Й, Чжан С., Чжоу И (ноябрь 2009 г.). «Прогнозирование непрерывной локальной структуры и эффекта ее замены на вторичную структуру при прогнозировании безфрагментной структуры белка». Структура. 17 (11): 1515–27. Дои:10.1016 / j.str.2009.09.006. ЧВК 2778607. PMID 19913486.
- ^ Чжун Л., Джонсон В. К. (май 1992 г.). «Окружающая среда влияет на предпочтение аминокислот вторичной структуре». Труды Национальной академии наук Соединенных Штатов Америки. 89 (10): 4462–5. Bibcode:1992PNAS ... 89.4462Z. Дои:10.1073 / pnas.89.10.4462. ЧВК 49102. PMID 1584778.
- ^ Макдональд-младший, Джонсон WC (июнь 2001 г.). «Характеристики окружающей среды важны для определения вторичной структуры белка». Белковая наука. 10 (6): 1172–7. Дои:10.1110 / л.с. 420101. ЧВК 2374018. PMID 11369855.
- ^ Costantini S, Colonna G, Facchiano AM (апрель 2006 г.). «На предрасположенность аминокислот к вторичным структурам влияет структурный класс белка». Сообщения о биохимических и биофизических исследованиях. 342 (2): 441–51. Дои:10.1016 / j.bbrc.2006.01.159. PMID 16487481.
- ^ Мараши С.А., Бехрузи Р., Пезешк Х. (январь 2007 г.). «Адаптация белков к различным средам: сравнение структурных свойств протеома у Bacillus subtilis и Escherichia coli». Журнал теоретической биологии. 244 (1): 127–32. Дои:10.1016 / j.jtbi.2006.07.021. PMID 16945389.
- ^ Костантини С., Колонна Дж., Факкиано А.М. (октябрь 2007 г.). «PreSSAPro: программа для предсказания вторичной структуры по свойствам аминокислот». Вычислительная биология и химия. 31 (5–6): 389–92. Дои:10.1016 / j.compbiolchem.2007.08.010. PMID 17888742.
- ^ Момен-Рокнабади А., Садеги М., Пезешк Х., Мараши С.А. (август 2008 г.). «Влияние доступной для остатков площади поверхности на прогноз вторичных структур белка». BMC Bioinformatics. 9: 357. Дои:10.1186/1471-2105-9-357. ЧВК 2553345. PMID 18759992.
- ^ Адамчак Р., Поролло А., Меллер Дж. (Май 2005 г.). «Сочетание предсказания вторичной структуры и доступности растворителей в белках». Белки. 59 (3): 467–75. Дои:10.1002 / prot.20441. PMID 15768403. S2CID 13267624.
- ^ Лакизаде А., Мараши С.А. (2009). «Добавление информации о контактном номере может улучшить прогнозирование вторичной структуры белка нейронными сетями» (PDF). Excli J. 8: 66–73.
- ^ Дорн, Марсио; e Сильва, Мариэль Барбачан; Buriol, Luciana S .; Лэмб, Луис К. (2014-12-01). «Трехмерное предсказание структуры белка: методы и вычислительные стратегии». Вычислительная биология и химия. 53: 251–276. Дои:10.1016 / j.compbiolchem.2014.10.001. ISSN 1476-9271.
- ^ а б c Чжан И (июнь 2008 г.). «Прогресс и проблемы в предсказании структуры белка». Текущее мнение в структурной биологии. 18 (3): 342–8. Дои:10.1016 / j.sbi.2008.02.004. ЧВК 2680823. PMID 18436442.
- ^ Овчинников С., Ким Д.Э., Ван Р.Й., Лю Й., ДиМайо Ф., Бейкер Д. (сентябрь 2016 г.). «Улучшенное предсказание структуры de novo в CASP11 за счет включения информации о коэволюции в Rosetta». Белки. 84 Дополнение 1: 67–75. Дои:10.1002 / prot.24974. ЧВК 5490371. PMID 26677056.
- ^ Хон Ш., Чжу К., Ли Дж. (Ноябрь 2018 г.). «ConDo: предсказание границы домена белка с использованием коэволюционной информации». Биоинформатика. 35 (14): 2411–2417. Дои:10.1093 / биоинформатика / bty973. PMID 30500873.
- ^ Wollacott AM, Zanghellini A, Murphy P, Baker D (февраль 2007 г.). «Предсказание структур многодоменных белков из структур отдельных доменов». Белковая наука. 16 (2): 165–75. Дои:10.1110 / пс. 062270707. ЧВК 2203296. PMID 17189483.
- ^ Сюй Д., Ярошевский Л., Ли З., Годзик А. (июль 2015 г.). «AIDA: сборка домена ab initio для автоматизированного предсказания многодоменной структуры белка и предсказания взаимодействия домен-домен». Биоинформатика. 31 (13): 2098–105. Дои:10.1093 / биоинформатика / btv092. ЧВК 4481839. PMID 25701568.
- ^ Шоу Д.Е., Дрор Р.О., Лосось Дж. К., Гроссман Дж. П., Маккензи К. М., Банк Дж. А., Янг С., Денерофф М. М., Бэтсон Б., Бауэрс К. Дж., Чоу Э (2009). Моделирование молекулярной динамики на Антоне в миллисекундном масштабе. Труды конференции по высокопроизводительным вычислительным сетям, хранению данных и анализу - SC '09. п. 1. Дои:10.1145/1654059.1654126. ISBN 9781605587448.
- ^ Pierce LC, Salomon-Ferrer R, de Oliveira CA, McCammon JA, Walker RC (сентябрь 2012 г.). «Стандартный доступ к событиям в миллисекундной шкале времени с ускоренной молекулярной динамикой». Журнал химической теории и вычислений. 8 (9): 2997–3002. Дои:10.1021 / ct300284c. ЧВК 3438784. PMID 22984356.
- ^ Kmiecik S, Gront D, Kolinski M, Wieteska L, Dawid AE, Kolinski A (июль 2016 г.). «Крупнозернистые модели белков и их применение». Химические обзоры. 116 (14): 7898–936. Дои:10.1021 / acs.chemrev.6b00163. PMID 27333362.
- ^ Cheung NJ, Yu W. (ноябрь 2018 г.). «Предсказание структуры белка de novo с использованием сверхбыстрой молекулярной динамики». PLOS ONE. 13 (11): e0205819. Bibcode:2018PLoSO..1305819C. Дои:10.1371 / journal.pone.0205819. ЧВК 6245515. PMID 30458007.
- ^ Гебель У., Сандер С., Шнайдер Р., Валенсия А (апрель 1994 г.). «Коррелированные мутации и контакты остатков в белках». Белки. 18 (4): 309–17. Дои:10.1002 / prot.340180402. PMID 8208723. S2CID 14978727.
- ^ Тейлор В. Р., Хатрик К. (март 1994 г.). «Компенсация изменений множественных выравниваний последовательностей белков». Белковая инженерия. 7 (3): 341–8. Дои:10.1093 / белок / 7.3.341. PMID 8177883.
- ^ Neher E (январь 1994 г.). «Насколько часто происходят коррелированные изменения в семействах белковых последовательностей?». Труды Национальной академии наук Соединенных Штатов Америки. 91 (1): 98–102. Bibcode:1994ПНАС ... 91 ... 98Н. Дои:10.1073 / пнас.91.1.98. ЧВК 42893. PMID 8278414.
- ^ Маркс Д.С., Колвелл Л.Дж., Шеридан Р., Хопф Т.А., Паньани А., Зеккина Р., Сандер С. (2011). «Трехмерная структура белка рассчитана на основе эволюционной вариации последовательности». PLOS ONE. 6 (12): e28766. Bibcode:2011PLoSO ... 628766M. Дои:10.1371 / journal.pone.0028766. ЧВК 3233603. PMID 22163331.
- ^ Burger L, van Nimwegen E (январь 2010 г.). «Непосредственное отделение от непрямой совместной эволюции остатков в выравнивании белков». PLOS вычислительная биология. 6 (1): e1000633. Bibcode:2010PLSCB ... 6E0633B. Дои:10.1371 / journal.pcbi.1000633. ЧВК 2793430. PMID 20052271.
- ^ Morcos F, Pagnani A, Lunt B, Bertolino A, Marks DS, Sander C, Zecchina R, Onuchic JN, Hwa T, Weigt M (декабрь 2011 г.). «Анализ совместной эволюции остатков с прямым связыванием позволяет выявить нативные контакты во многих семействах белков». Труды Национальной академии наук Соединенных Штатов Америки. 108 (49): E1293-301. arXiv:1110.5223. Bibcode:2011PNAS..108E1293M. Дои:10.1073 / pnas.1111471108. ЧВК 3241805. PMID 22106262.
- ^ Наджент Т., Джонс Д. Т. (июнь 2012 г.). «Точное предсказание структуры de novo больших трансмембранных белковых доменов с использованием сборки фрагментов и анализа коррелированных мутаций». Труды Национальной академии наук Соединенных Штатов Америки. 109 (24): E1540-7. Bibcode:2012PNAS..109E1540N. Дои:10.1073 / pnas.1120036109. ЧВК 3386101. PMID 22645369.
- ^ Хопф Т.А., Колвелл Л.Дж., Шеридан Р., Рост Б., Сандер С., Маркс Д.С. (июнь 2012 г.). «Трехмерные структуры мембранных белков из геномного секвенирования». Клетка. 149 (7): 1607–21. Дои:10.1016 / j.cell.2012.04.012. ЧВК 3641781. PMID 22579045.
- ^ Джин, Шикай; Чен, Мингчен; Чен, Сюнь; Буэно, Карлос; Лу, Вэй; Шафер, Николас П .; Линь, Синчэн; Onuchic, José N .; Уолинс, Питер Г. (9 июня 2020 г.). «Прогнозирование структуры белка в CASP13 с использованием AWSEM-Suite». Журнал химической теории и вычислений. 16 (6): 3977–3988. Дои:10.1021 / acs.jctc.0c00188. PMID 32396727.
- ^ Чжан Й., Сколник Дж. (Январь 2005 г.). «Проблема предсказания структуры белка может быть решена с использованием текущей библиотеки PDB». Труды Национальной академии наук Соединенных Штатов Америки. 102 (4): 1029–34. Bibcode:2005PNAS..102.1029Z. Дои:10.1073 / pnas.0407152101. ЧВК 545829. PMID 15653774.
- ^ Боуи Дж. Ю, Люти Р., Айзенберг Д. (июль 1991 г.). «Метод идентификации белковых последовательностей, которые складываются в известную трехмерную структуру». Наука. 253 (5016): 164–70. Bibcode:1991Научный ... 253..164B. Дои:10.1126 / science.1853201. PMID 1853201.
- ^ Данбрак Р.Л. (август 2002 г.). «Библиотеки ротамеров в 21 веке». Текущее мнение в структурной биологии. 12 (4): 431–40. Дои:10.1016 / S0959-440X (02) 00344-5. PMID 12163064.
- ^ Ponder JW, Richards FM (февраль 1987 г.). «Третичные шаблоны для белков. Использование критериев упаковки при перечислении разрешенных последовательностей для различных структурных классов». Журнал молекулярной биологии. 193 (4): 775–91. Дои:10.1016/0022-2836(87)90358-5. PMID 2441069.
- ^ Ловелл SC, Word JM, Ричардсон JS, Ричардсон, округ Колумбия (август 2000 г.). «Предпоследняя библиотека ротамеров». Белки. 40 (3): 389–408. Дои:10.1002 / 1097-0134 (20000815) 40: 3 <389 :: AID-PROT50> 3.0.CO; 2-2. PMID 10861930.
- ^ Шаповалов М.В., Данбрак Р.Л. (июнь 2011 г.). «Сглаженная библиотека ротамеров, зависимая от остова, для белков, полученных на основе оценок и регрессий адаптивной плотности ядра». Структура. 19 (6): 844–58. Дои:10.1016 / j.str.2011.03.019. ЧВК 3118414. PMID 21645855.
- ^ Чен В.Б., Арендалл В.Б., Хедд Дж. Дж., Киди Д. А., Иммормино Р. М., Капрал Дж. Дж., Мюррей Л. В., Ричардсон Дж. С., Ричардсон, округ Колумбия (январь 2010 г.). «MolProbity: проверка структуры всех атомов для кристаллографии макромолекул». Acta Crystallographica. Раздел D, Биологическая кристаллография. 66 (Пт 1): 12–21. Дои:10.1107 / S0907444909042073. ЧВК 2803126. PMID 20057044.
- ^ Бауэр MJ, Коэн FE, Dunbrack RL (апрель 1997 г.). «Прогнозирование ротамеров боковых цепей белков из библиотеки ротамеров, зависимых от остова: новый инструмент моделирования гомологии». Журнал молекулярной биологии. 267 (5): 1268–82. Дои:10.1006 / jmbi.1997.0926. PMID 9150411.
- ^ Voigt CA, Gordon DB, Mayo SL (июнь 2000 г.). «Торговая точность для скорости: количественное сравнение алгоритмов поиска в дизайне белковой последовательности». Журнал молекулярной биологии. 299 (3): 789–803. CiteSeerX 10.1.1.138.2023. Дои:10.1006 / jmbi.2000.3758. PMID 10835284.
- ^ Кривов Г.Г., Шаповалов М.В., Данбрак Р.Л. (декабрь 2009 г.). «Улучшенное предсказание конформации боковой цепи белка с помощью SCWRL4». Белки. 77 (4): 778–95. Дои:10.1002 / prot.22488. ЧВК 2885146. PMID 19603484.
- ^ Чжоу KC, Чжан CT (1995). «Прогнозирование структурных классов белков». Критические обзоры в биохимии и молекулярной биологии. 30 (4): 275–349. Дои:10.3109/10409239509083488. PMID 7587280.
- ^ Чэнь Ц., Чжоу X, Тянь Y, Цзоу X, Цай П. (октябрь 2006 г.). «Прогнозирование структурного класса белка с псевдо-аминокислотным составом и поддержка сети слияния векторной машины». Аналитическая биохимия. 357 (1): 116–21. Дои:10.1016 / j.ab.2006.07.022. PMID 16920060.
- ^ Чен С., Тиан YX, Цзоу XY, Цай П.Х., Мо JY (декабрь 2006 г.). «Использование псевдо-Аминокислотный состав и опорных векторов, чтобы предсказать белок структурный класс». Журнал теоретической биологии. 243 (3): 444–8. Дои:10.1016 / j.jtbi.2006.06.025. PMID 16908032.
- ^ Лин Х, Ли QZ (июль 2007 г.). «Использование псевдоаминокислотного состава для прогнозирования структурного класса белка: приближается путем включения 400 дипептидных компонентов». Журнал вычислительной химии. 28 (9): 1463–1466. Дои:10.1002 / jcc.20554. PMID 17330882. S2CID 28884694.
- ^ Сяо X, Ван П, Чжоу KC (октябрь 2008 г.). «Прогнозирование структурных классов белков с псевдоаминокислотным составом: подход с использованием геометрических моментов изображения клеточного автомата». Журнал теоретической биологии. 254 (3): 691–6. Дои:10.1016 / j.jtbi.2008.06.016. PMID 18634802.
- ^ Chou KC, Cai YD (сентябрь 2004 г.). «Прогнозирование структурного класса белков по составу функциональных доменов». Сообщения о биохимических и биофизических исследованиях. 321 (4): 1007–9. Дои:10.1016 / j.bbrc.2004.07.059. PMID 15358128.
- ^ Бэтти Дж. Н., Копп Дж., Бордоли Л., Рид Р. Дж., Кларк Н. Д., Шведе Т. (2007). «Автоматизированные предсказания сервера в CASP7». Белки. 69 Дополнение 8 (Дополнение 8): 68–82. Дои:10.1002 / prot.21761. PMID 17894354. S2CID 29879391.
дальнейшее чтение
- Майорек К., Козловски Л., Якальски М., Буйницкий Ю.М. (18 декабря 2008 г.). "Глава 2: Первые шаги предсказания структуры белка" (PDF). В Bujnicki J (ред.). Прогнозирование белковых структур, функций и взаимодействий. John Wiley & Sons, Ltd., стр. 39–62. Дои:10.1002 / 9780470741894.ch2. ISBN 9780470517673.
- Бейкер Д., Сали А. (октябрь 2001 г.). «Прогнозирование структуры белков и структурная геномика». Наука. 294 (5540): 93–6. Bibcode:2001Научный ... 294 ... 93B. Дои:10.1126 / science.1065659. PMID 11588250. S2CID 7193705.
- Келли Л.А., Штернберг MJ (2009). «Прогнозирование структуры белка в Интернете: пример использования сервера Phyre» (PDF). Протоколы природы. 4 (3): 363–71. Дои:10.1038 / nprot.2009.2. HDL:10044/1/18157. PMID 19247286. S2CID 12497300.
- Крыштафович А., Фиделис К. (апрель 2009 г.). «Прогнозирование структуры белка и оценка качества модели». Открытие наркотиков сегодня. 14 (7–8): 386–93. Дои:10.1016 / j.drudis.2008.11.010. ЧВК 2808711. PMID 19100336.
- Цюй X, Суонсон Р., Дэй Р., Цай Дж. (Июнь 2009 г.). «Руководство по прогнозированию структуры на основе шаблонов». Современная наука о белках и пептидах. 10 (3): 270–85. Дои:10.2174/138920309788452182. PMID 19519455.
- Дага PR, Патель Р. Я., Дёрксен Р. Дж. (2010). «Моделирование белков на основе шаблонов: последние методологические достижения». Актуальные темы медицинской химии. 10 (1): 84–94. Дои:10.2174/156802610790232314. ЧВК 5943704. PMID 19929829.
- Фисер, А. (2010). «Матричное моделирование структуры белка». Вычислительная биология. Методы молекулярной биологии. 673. С. 73–94. Дои:10.1007/978-1-60761-842-3_6. ISBN 978-1-60761-841-6. ЧВК 4108304. PMID 20835794.
- Коццетто Д., Трамонтано А. (декабрь 2008 г.). «Достижения и ошибки в предсказании структуры белка». Современная наука о белках и пептидах. 9 (6): 567–77. Дои:10.2174/138920308786733958. PMID 19075747.
- Наим А., Ситкофф Д., Крыстек С. (апрель 2006 г.). «Сравнительное исследование доступного программного обеспечения для высокоточного моделирования гомологии: от выравнивания последовательностей до структурных моделей». Белковая наука. 15 (4): 808–24. Дои:10.1110 / пс. 051892906. ЧВК 2242473. PMID 16600967.
внешняя ссылка
- Домашняя страница экспериментов CASP
- Инструменты ExPASy Proteomics - список инструментов и серверов прогнозирования