Дизайн нуклеиновой кислоты - Nucleic acid design
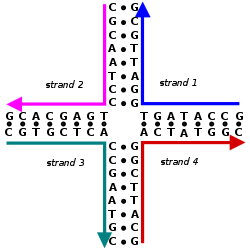
Дизайн нуклеиновой кислоты это процесс создания набора нуклеиновая кислота последовательности оснований, которые будут ассоциироваться в желаемую конформацию. Дизайн нуклеиновой кислоты является центральным в областях ДНК-нанотехнологии и ДНК-вычисления.[2] Это необходимо, потому что есть много возможных последовательности цепей нуклеиновых кислот, которые будут складываться в заданный вторичная структура, но многие из этих последовательностей будут иметь нежелательные дополнительные взаимодействия, которых следует избегать. Кроме того, есть много третичная структура соображения, которые влияют на выбор вторичной конструкции для данной конструкции.[3][4]
Дизайн нуклеиновой кислоты преследует те же цели, что и белковый дизайн: в обоих последовательность мономеров рационально разработанный благоприятствовать желаемой складчатой или связанной структуре и не одобрять альтернативные структуры. Однако дизайн нуклеиновой кислоты имеет то преимущество, что является гораздо более простой задачей в вычислительном отношении, поскольку простота Watson-Crick базовая пара правила приводят к простым эвристический методы, которые дают экспериментально устойчивые конструкции. Вычислительные модели для сворачивание белка требовать третичная структура информации, тогда как дизайн нуклеиновой кислоты может работать в основном на уровне вторичная структура. Однако структуры нуклеиновых кислот по своей функциональности менее универсальны, чем белки.[2][5]
Дизайн нуклеиновой кислоты можно рассматривать как инверсию предсказание структуры нуклеиновой кислоты. При предсказании структуры структура определяется на основе известной последовательности, тогда как при разработке нуклеиновой кислоты генерируется последовательность, которая будет формировать желаемую структуру.[2]
Основные концепции

В структура нуклеиновых кислот состоит из последовательности нуклеотиды. Существует четыре типа нуклеотидов, которые различаются по тому, какой из четырех азотистые основания они содержат: в ДНК это аденин (А), цитозин (С), гуанин (G) и тимин (Т). Нуклеиновые кислоты обладают тем свойством, что две молекулы связываются друг с другом с образованием двойная спираль только если две последовательности дополнительный, то есть они могут образовывать совпадающие последовательности пар оснований. Таким образом, в нуклеиновых кислотах последовательность определяет характер связывания и, следовательно, общую структуру.[5]
Дизайн нуклеиновой кислоты - это процесс, с помощью которого при заданной целевой структуре или функциональности генерируются последовательности для цепей нуклеиновых кислот, которые будут самособираться в эту целевую структуру. Дизайн нуклеиновой кислоты охватывает все уровни структура нуклеиновой кислоты:
- Первичная структура - необработанная последовательность азотистые основания каждой из составляющих цепей нуклеиновой кислоты;
- Вторичная структура - набор взаимодействий между основаниями, т.е. какие части каких нитей связаны друг с другом; и
- Третичная структура - расположение атомов в трехмерном пространстве с учетом геометрических и стерический ограничения.
Одна из самых больших проблем при разработке нуклеиновых кислот - обеспечение того, чтобы целевая структура имела самую низкую свободную энергию (т.е. термодинамически благоприятно), в то время как деформированные структуры имеют более высокие значения свободной энергии и, следовательно, не являются предпочтительными.[2]Этих целей можно достичь за счет использования ряда подходов, в том числе: эвристический, термодинамические и геометрические. Почти все задачи по разработке нуклеиновых кислот выполняются с помощью компьютеров, и для многих из этих задач доступен ряд пакетов программного обеспечения.
Два соображения при разработке нуклеиновых кислот заключаются в том, что желаемые гибридизации должны иметь температуры плавления в узком диапазоне, а любые ложные взаимодействия должны иметь очень низкие температуры плавления (т.е. они должны быть очень слабыми).[5] Существует также контраст между оптимизирующим сродство «позитивным дизайном», направленным на минимизацию энергии желаемой структуры в абсолютном смысле, и оптимизирующим специфичность «негативным дизайном», который рассматривает энергию целевой структуры относительно энергии нежелательной структуры. конструкции. Алгоритмы, реализующие оба типа дизайна, как правило, работают лучше, чем те, которые рассматривают только один тип.[2]
Подходы
Эвристические методы
Эвристический Методы используют простые критерии, которые можно быстро оценить, чтобы судить о пригодности различных последовательностей для данной вторичной структуры. У них есть преимущество в том, что они намного дешевле в вычислительном отношении, чем минимизация энергии алгоритмы, необходимые для термодинамического или геометрического моделирования, которые проще реализовать, но за счет того, что они менее строгие, чем эти модели.
Минимизация симметрии последовательностей - это самый старый подход к дизайну нуклеиновых кислот, который впервые был использован для создания неподвижных версий разветвленных структур ДНК. Минимизация симметрии последовательностей делит последовательность нуклеиновой кислоты на перекрывающиеся подпоследовательности фиксированной длины, называемой длиной критерия. Каждый из 4N возможные подпоследовательности длины N могут появляться в последовательности только один раз. Это гарантирует, что не может произойти нежелательных гибридизаций, длина которых больше или равна длине критерия.[2][3]
Связанный эвристический подход состоит в том, чтобы рассмотреть «расстояние несовпадения», то есть количество позиций в определенном кадре, где основания не совпадают. дополнительный. Чем больше расстояние рассогласования, тем меньше вероятность возникновения сильного ложного взаимодействия.[5] Это связано с концепцией Расстояние Хэмминга в теория информации. Другой связанный, но более сложный подход - использовать методы из теория кодирования к построить последовательности нуклеиновых кислот с желаемыми свойствами.
Термодинамические модели
Информация о вторичная структура комплекса нуклеиновой кислоты вместе с его последовательностью можно использовать для прогнозирования термодинамический свойства комплекса.
Когда термодинамические модели используются в дизайне нуклеиновых кислот, обычно есть два соображения: желаемые гибридизации должны иметь температуры плавления в узком диапазоне, а любые ложные взаимодействия должны иметь очень низкие температуры плавления (т.е. они должны быть очень слабыми). В Свободная энергия Гиббса идеально подобранного дуплекса нуклеиновой кислоты можно предсказать, используя модель ближайшего соседа. Эта модель рассматривает только взаимодействия между нуклеотидом и его ближайшими соседями на цепи нуклеиновой кислоты путем суммирования свободной энергии каждого из перекрывающихся двухнуклеотидных подслов дуплекса. Затем это корректируется для самокомплементарных мономеров и для GC-контент. Как только свободная энергия известна, температура плавления дуплекса можно определить. Одно только содержание GC также можно использовать для оценки свободной энергии и температуры плавления дуплекса нуклеиновой кислоты. Это менее точно, но и требует меньших вычислительных затрат.[5]
Программное обеспечение для термодинамического моделирования нуклеиновых кислот включает: Nupack,[6][7]mfold / UNAFold,[8] и Вена.[9]
Родственный подход, предсказание обратной вторичной структуры, использует стохастический локальный поиск, который улучшает последовательность нуклеиновой кислоты путем запуска предсказание структуры алгоритм и изменение последовательности для устранения нежелательных функций.[5]
Геометрические модели

Геометрические модели нуклеиновых кислот используются для предсказания третичная структура. Это важно, потому что разработанные комплексы нуклеиновых кислот обычно содержат несколько точек соединения, что вносит геометрические ограничения в систему. Эти ограничения проистекают из основных структура нуклеиновых кислот, в основном, что двойная спираль образованный дуплексами нуклеиновых кислот имеет фиксированную спиральность около 10,4 пар оснований за ход, и составляет относительно жесткий. Из-за этих ограничений комплексы нуклеиновых кислот чувствительны к относительной ориентации основные и второстепенные канавки в точках соединения. Геометрическое моделирование может обнаружить напряжение возникающие из-за перекосов в конструкции, которые затем может исправить дизайнер.[4][11]
Геометрические модели нуклеиновых кислот для ДНК-нанотехнологии обычно используют сокращенные представления нуклеиновой кислоты, потому что моделирование каждого атома было бы очень затратным в вычислительном отношении для таких больших систем. Сообщается, что модели с тремя псевдоатомами на пару оснований, представляющими два основных сахара и ось спирали, обладают достаточным уровнем детализации для предсказания экспериментальных результатов.[11] Однако также используются модели с пятью псевдоатомами на пару оснований, явно включающими фосфаты скелета.[12]
Программное обеспечение для геометрического моделирования нуклеиновых кислот включает: ГИДЕОН,[11]Тиамат,[13]Наноинженер-1,и UNIQUIMER 3D.[14]Геометрические аспекты особенно интересны при проектировании ДНК оригами, потому что последовательность предопределена выбором цепи каркаса. Разработано программное обеспечение специально для дизайна ДНК оригами, в том числе КАДНКнет[15]и SARSE.[16]
Приложения
Дизайн нуклеиновой кислоты используется в ДНК-нанотехнологии для разработки прядей, которые будут самостоятельно собираться в желаемую целевую структуру. К ним относятся такие примеры, как ДНК машины, периодические двумерные и трехмерные решетки, многогранники и ДНК оригами.[2] Его также можно использовать для создания наборов цепей нуклеиновых кислот, которые являются «ортогональными» или не взаимодействуют друг с другом, чтобы минимизировать или исключить ложные взаимодействия. Это полезно в ДНК-вычисления, а также для приложений молекулярного штрих-кодирования в химическая биология и биотехнология.[5]
Смотрите также
использованная литература
- ^ Мао, Чэндэ (декабрь 2004 г.). «Возникновение сложности: уроки ДНК». PLOS Биология. 2 (12): 2036–2038. Дои:10.1371 / journal.pbio.0020431. ISSN 1544-9173. ЧВК 535573. PMID 15597116.
- ^ а б c d е ж г Диркс, Роберт М .; Лин, Майло; Уинфри, Эрик; Пирс, Найлз А. (2004). «Парадигмы для вычислительного дизайна нуклеиновых кислот». Исследования нуклеиновых кислот. 32 (4): 1392–1403. Дои:10.1093 / нар / гх291. ЧВК 390280. PMID 14990744.
- ^ а б Seeman, N (1982). «Узлы и решетки нуклеиновых кислот». Журнал теоретической биологии. 99 (2): 237–47. Дои:10.1016/0022-5193(82)90002-9. PMID 6188926.
- ^ а б Шерман, Вт; Seeman, N (2006). «Дизайн минимально деформированных нанотрубок нуклеиновых кислот». Биофизический журнал. 90 (12): 4546–57. Bibcode:2006BpJ .... 90.4546S. Дои:10.1529 / biophysj.105.080390. ЧВК 1471877. PMID 16581842.
- ^ а б c d е ж г Бреннеман, Арвен; Кондон, Энн (2002). «Конструкция нитей для биомолекулярных вычислений». Теоретическая информатика. 287: 39–58. Дои:10.1016 / S0304-3975 (02) 00135-4.
- ^ Диркс, Роберт М .; Буа, Джастин С .; Schaeffer, Joseph M .; Уинфри, Эрик; Пирс, Найлз А. (2007). «Термодинамический анализ взаимодействующих цепей нуклеиновых кислот». SIAM Обзор. 49 (1): 65–88. Bibcode:2007SIAMR..49 ... 65D. CiteSeerX 10.1.1.523.4764. Дои:10.1137/060651100.
- ^ Zadeh, Joseph N .; Вулф, Брайан Р .; Пирс, Найлз А. (2011). «Дизайн последовательности нуклеиновой кислоты посредством эффективной оптимизации дефектов ансамбля» (PDF). Журнал вычислительной химии. 32 (3): 439–452. Дои:10.1002 / jcc.21633. PMID 20717905.
- ^ Цукер, М. (2003). «Веб-сервер Mfold для предсказания сворачивания нуклеиновых кислот и гибридизации». Исследования нуклеиновых кислот. 31 (13): 3406–15. Дои:10.1093 / нар / gkg595. ЧВК 169194. PMID 12824337.
- ^ Грубер А.Р., Лоренц Р., Бернхарт С.Х., Нойбек Р., Хофакер И.Л. (2008). "Венский веб-сайт РНК". Нуклеиновые кислоты Res. 36 (Выпуск веб-сервера): W70–4. Дои:10.1093 / nar / gkn188. ЧВК 2447809. PMID 18424795.
- ^ Goodman, R.P .; Schaap, I.A.T .; Tardin, C.F .; Erben, C.M .; Berry, R.M .; Schmidt, C.F .; Турберфилд, А.Дж. (9 декабря 2005 г.). «Быстрая хиральная сборка жестких строительных блоков ДНК для молекулярного нанопроизводства». Наука. 310 (5754): 1661–1665. Bibcode:2005Наука ... 310.1661G. Дои:10.1126 / наука.1120367. ISSN 0036-8075. PMID 16339440. S2CID 13678773.
- ^ а б c Бирак, Джеффри Дж .; Шерман, Уильям Б .; Копач, Йенс; Константину, Памела Э .; Симан, Надриан К. (2006). «Архитектура с GIDEON, программа для проектирования в структурных нанотехнологиях ДНК». Журнал молекулярной графики и моделирования. 25 (4): 470–80. Дои:10.1016 / j.jmgm.2006.03.005. ЧВК 3465968. PMID 16630733.
- ^ «Описание моделей PAM3 и PAM5». Документация по Nanoengineer-1 вики. Nanorex. Получено 2010-04-15.
- ^ Уильямс, Шон; Лунд, Кайл; Линь, Чэньсян; Вонка, Питер; Линдси, Стюарт; Ян, Хао (2009). «Тиамат: инструмент трехмерного редактирования сложных структур ДНК». ДНК-вычисления. Конспект лекций по информатике. 5347. Springer Berlin / Heidelberg. С. 90–101. Дои:10.1007/978-3-642-03076-5_8. ISBN 978-3-642-03075-8. ISSN 0302-9743.
- ^ Zhu, J .; Wei, B .; Yuan, Y .; Ми, Ю. (2009). «UNIQUIMER 3D, программный комплекс для проектирования, анализа и оценки структурных нанотехнологий ДНК». Исследования нуклеиновых кислот. 37 (7): 2164–75. Дои:10.1093 / nar / gkp005. ЧВК 2673411. PMID 19228709.
- ^ Дуглас, С. М .; Marblestone, A.H .; Teerapittayanon, S .; Васкес, А .; Церковь, Г. М .; Ши, В. М. (2009). «Быстрое прототипирование трехмерных форм ДНК-оригами с помощью caDNAno». Исследования нуклеиновых кислот. 37 (15): 5001–6. Дои:10.1093 / нар / gkp436. ЧВК 2731887. PMID 19531737.
- ^ Andersen, Ebbe S .; Донг, Миндон; Nielsen, Morten M .; Ян, Каспер; Линд-Томсен, Аллан; Мамдух, Ваэль; Готельф, Курт V .; Бесенбахер, Флемминг; Кьемс, ЙёРген (2008). «Дизайн ДНК-оригами структур в форме дельфинов с гибкими хвостами». САУ Нано. 2 (6): 1213–8. Дои:10.1021 / nn800215j. PMID 19206339.
дальнейшее чтение
- Бреннеман, Арвен; Кондон, Энн (2002). «Конструкция нитей для биомолекулярных вычислений». Теоретическая информатика. 287: 39–58. Дои:10.1016 / S0304-3975 (02) 00135-4.—Обзор подходов к дизайну первичной структуры нуклеиновых кислот.
- Диркс, Роберт М.; Лин, Майло; Уинфри, Эрик; Пирс, Найлз А. (2004). «Парадигмы компьютерного дизайна нуклеиновых кислот». Исследования нуклеиновых кислот. 32 (4): 1392–1403. Дои:10.1093 / нар / гх291. ЧВК 390280. PMID 14990744.—Сравнение и оценка ряда эвристических и термодинамических методов дизайна нуклеиновых кислот.
- Seeman, N (1982). «Узлы и решетки нуклеиновых кислот». Журнал теоретической биологии. 99 (2): 237–47. Дои:10.1016/0022-5193(82)90002-9. PMID 6188926.—Одна из самых ранних статей по дизайну нуклеиновых кислот, описывающая использование минимизации симметрии последовательности для создания неподвижных разветвленных соединений.
- Андерсен, Эббе Ленивец (2010). «Прогнозирование и дизайн структур ДНК и РНК». Новая биотехнология. 27 (3): 184–193. Дои:10.1016 / j.nbt.2010.02.012. PMID 20193785.—Обзор, сравнивающий возможности доступного программного обеспечения для разработки нуклеиновых кислот.
| Обзор | |
|---|---|
| Влияние и Приложения | |
| Наноматериалы | |
| Молекулярная самосборка | |
| Наноэлектроника | |
| Сканирующая зондовая микроскопия | |
| Молекулярная нанотехнология | |
| |