Переводчик (вычислитель) - Interpreter (computing)
| Выполнение программы |
|---|
| Общие понятия |
| Типы кода |
| Стратегии компиляции |
| Заметное время выполнения |
| Известные компиляторы и инструментальные средства |
В Информатика, переводчик это компьютерная программа это прямо выполняет инструкции, написанные в программирование или язык сценариев, не требуя, чтобы они ранее были составлен в машинный язык программа. Интерпретатор обычно использует одну из следующих стратегий для выполнения программы:
- Разобрать то исходный код и напрямую выполнять свое поведение;
- Перевести исходный код в некоторые эффективные промежуточное представление и немедленно выполните это;
- Явно выполнить сохраненный предварительно скомпилированный код[1] сделано компилятор который является частью системы переводчика.
Ранние версии Язык программирования Лисп и миникомпьютерные и микрокомпьютерные диалекты BASIC были бы примерами первого типа. Perl, Python, MATLAB, и Рубин являются примерами второго, а UCSD Паскаль является примером третьего типа. Исходные программы компилируются заранее и сохраняются как машинно-независимый код, который затем связаны во время выполнения и выполняется интерпретатором и / или компилятором (для JIT системы). Некоторые системы, такие как Болтовня и современные версии БАЗОВЫЙ и Ява также может сочетать два и три.[2] Интерпретаторы различных типов также были созданы для многих языков, традиционно связанных с компиляцией, таких как Алгол, Фортран, Кобол, C и C ++.
Хотя интерпретация и компиляция являются двумя основными средствами реализации языков программирования, они не исключают друг друга, поскольку большинство систем интерпретации также выполняют некоторую работу по переводу, как и компиляторы. Условия "интерпретируемый язык " или "компилируемый язык "означает, что канонической реализацией этого языка является интерпретатор или компилятор соответственно. A язык высокого уровня в идеале абстракция независимо от конкретных реализаций.
История
Интерпретаторы использовались еще в 1952 году, чтобы упростить программирование в рамках ограничений компьютеров того времени (например, нехватка места для хранения программ или отсутствие встроенной поддержки чисел с плавающей запятой). Интерпретаторы также использовались для перевода между низкоуровневыми машинными языками, что позволяло писать код для машин, которые все еще находились в стадии разработки, и тестировать их на уже существующих компьютерах.[3] Первый интерпретируемый язык высокого уровня был Лисп. Lisp был впервые реализован в 1958 г. Стив Рассел на IBM 704 компьютер. Рассел прочитал Джон Маккарти '' и понял (к удивлению Маккарти), что Лисп оценка функция может быть реализована в машинном коде.[4] Результатом стал работающий интерпретатор Лиспа, который можно было использовать для запуска программ Лиспа, или, точнее, «оценки выражений Лиспа».
Компиляторы против интерпретаторов
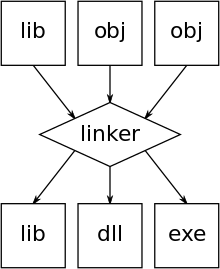
Программы, написанные на язык высокого уровня либо напрямую выполняются каким-либо интерпретатором, либо преобразуются в Машинный код компилятором (и ассемблер и компоновщик ) для ЦПУ выполнить.
Хотя компиляторы (и ассемблеры) обычно производят машинный код, непосредственно исполняемый аппаратным обеспечением компьютера, они часто (необязательно) могут создавать промежуточную форму, называемую объектный код. Это в основном тот же машинно-специфический код, но с добавлением таблица символов с именами и тегами, чтобы сделать исполняемые блоки (или модули) идентифицируемыми и перемещаемыми. Скомпилированные программы обычно используют строительные блоки (функции), хранящиеся в библиотеке таких модулей объектного кода. А компоновщик используется для объединения (готовых) файлов библиотеки с объектным файлом (ами) приложения для формирования единого исполняемого файла. Таким образом, объектные файлы, которые используются для создания исполняемого файла, часто создаются в разное время, а иногда даже на разных языках (способных генерировать один и тот же формат объекта).
Простой интерпретатор, написанный на языке низкого уровня (например, сборка ) могут иметь аналогичные блоки машинного кода, реализующие функции языка высокого уровня, которые хранятся и выполняются, когда запись функции в поисковой таблице указывает на этот код. Однако интерпретатор, написанный на языке высокого уровня, обычно использует другой подход, такой как создание и последующее прохождение дерево синтаксического анализа либо путем создания и выполнения промежуточных программно определяемых инструкций, либо того и другого.
Таким образом, и компиляторы, и интерпретаторы обычно превращают исходный код (текстовые файлы) в токены, оба могут (или не могут) генерировать дерево синтаксического анализа, и оба могут генерировать немедленные инструкции (для штабелеукладчик, четырехкратный код, или другими способами). Основное отличие состоит в том, что система компилятора, включая (встроенный или отдельный) компоновщик, генерирует автономный Машинный код программа, а система интерпретатора вместо выполняет действия, описанные программой высокого уровня.
Таким образом, компилятор может выполнить почти все преобразования семантики исходного кода на машинный уровень раз и навсегда (то есть до тех пор, пока программа не будет изменена), в то время как интерпретатор должен сделать немного этого преобразования работают каждый раз, когда выполняется инструкция или функция. Однако в эффективном интерпретаторе большая часть работы по переводу (включая анализ типов и т. Д.) Выносится за основу и выполняется только при первом запуске программы, модуля, функции или даже оператора, что весьма похоже на то, как компилятор работает. Однако скомпилированная программа по-прежнему выполняется намного быстрее, в большинстве случаев, отчасти потому, что компиляторы предназначены для оптимизации кода, и для этого может быть предоставлено достаточно времени. Это особенно верно для более простых языков высокого уровня без (многих) динамических структур данных, проверок или типовые проверки.
При традиционной компиляции исполняемый вывод компоновщиков (файлы .exe, файлы .dll или библиотеки, см. Рисунок) обычно можно перемещать при запуске под общей операционной системой, как и модули объектного кода, но с той разницей, что это перемещение выполняется динамически во время выполнения, т.е. когда программа загружается для выполнения. С другой стороны, скомпилированные и связанные программы для небольших встроенные системы обычно выделяются статически, часто жестко запрограммированы в НЕ мигает память, поскольку часто нет вторичного хранилища и операционной системы в этом смысле.
Исторически сложилось так, что большинство систем интерпретаторов имели встроенный автономный редактор. Это становится все более распространенным также для компиляторов (которые тогда часто назывались IDE ), хотя некоторые программисты предпочитают использовать любой редактор по своему выбору и запускать компилятор, компоновщик и другие инструменты вручную. Исторически сложилось так, что компиляторы предшествовали интерпретаторам, потому что оборудование в то время не могло поддерживать как интерпретатор, так и интерпретируемый код, а типичная пакетная среда того времени ограничивала преимущества интерпретации.[5]
Цикл разработки
В течение цикл разработки программного обеспечения, программисты часто вносят изменения в исходный код. При использовании компилятора каждый раз, когда в исходный код вносятся изменения, они должны ждать, пока компилятор переведет измененные исходные файлы и ссылка на сайт все файлы двоичного кода вместе перед запуском программы. Чем больше программа, тем дольше ожидание. Напротив, программист, использующий интерпретатор, ожидает намного меньше, поскольку интерпретатору обычно просто нужно перевести код, над которым работает, в промежуточное представление (или не переводить его вообще), что требует гораздо меньше времени, прежде чем изменения могут быть проверено. Эффекты очевидны после сохранения исходного кода и перезагрузки программы. Скомпилированный код обычно труднее отлаживать, поскольку редактирование, компиляция и компоновка - это последовательные процессы, которые должны выполняться в правильной последовательности с правильным набором команд. По этой причине многие компиляторы также имеют вспомогательное средство управления, известное как Сделать файл и программа. В файле Make file перечислены командные строки компилятора и компоновщика и файлы исходного кода программы, но он может принимать простой ввод из меню командной строки (например, «Make 3»), который выбирает третью группу (набор) инструкций, затем выдает команды компилятору и компоновщик, загружающий указанные файлы исходного кода.
Распределение
А компилятор преобразует исходный код в двоичную инструкцию для архитектуры конкретного процессора, что делает его менее переносимым. Это преобразование выполняется только один раз в среде разработчика, после чего тот же двоичный файл может быть распространен на компьютеры пользователя, где он может быть выполнен без дальнейшего преобразования. А кросс-компилятор может генерировать двоичный код для пользовательской машины, даже если у нее другой процессор, чем машина, на которой код компилируется.
Интерпретируемая программа может распространяться как исходный код. Его необходимо транслировать на каждой конечной машине, что занимает больше времени, но делает распространение программы независимым от архитектуры машины. Однако переносимость интерпретируемого исходного кода зависит от того, действительно ли целевая машина имеет подходящий интерпретатор. Если интерпретатор должен быть предоставлен вместе с исходным кодом, общий процесс установки будет более сложным, чем доставка монолитного исполняемого файла, поскольку интерпретатор сам является частью того, что необходимо установить.
Тот факт, что интерпретируемый код может быть легко прочитан и скопирован людьми, может вызывать беспокойство с точки зрения Авторские права. Однако различные системы шифрование и обфускация существует. Доставка промежуточного кода, такого как байт-код, имеет тот же эффект, что и обфускация, но байт-код может быть декодирован с помощью декомпилятор или дизассемблер.[нужна цитата ]
Эффективность
Основным недостатком интерпретаторов является то, что интерпретируемая программа обычно работает медленнее, чем если бы она была составлен. Разница в скоростях может быть крошечной или большой; часто на порядок, а иногда и больше. Обычно запуск программы в интерпретаторе занимает больше времени, чем запуск скомпилированного кода, но для его интерпретации может потребоваться меньше времени, чем общее время, необходимое для ее компиляции и запуска. Это особенно важно при прототипировании и тестировании кода, когда цикл редактирования-интерпретации-отладки часто может быть намного короче, чем цикл редактирования-компиляции-запуска-отладки.[нужна цитата ]
Интерпретация кода выполняется медленнее, чем запуск скомпилированного кода, потому что интерпретатор должен анализировать каждый заявление в программе каждый раз, когда он выполняется, а затем выполняет желаемое действие, тогда как скомпилированный код просто выполняет действие в фиксированном контексте, определяемом компиляцией. Эта время выполнения анализ известен как «накладные расходы на интерпретацию». Доступ к переменным также медленнее в интерпретаторе, потому что сопоставление идентификаторов с местами хранения должно выполняться многократно во время выполнения, а не во время выполнения. время компиляции.[нужна цитата ]
Есть разные компромиссы между скорость развития при использовании интерпретатора и скорость выполнения при использовании компилятора. Некоторые системы (например, некоторые Лиспы ) позволяют интерпретируемому и скомпилированному коду вызывать друг друга и обмениваться переменными. Это означает, что после того, как подпрограмма была протестирована и отлажена в интерпретаторе, она может быть скомпилирована и, таким образом, получит выгоду от более быстрого выполнения, пока другие подпрограммы разрабатываются.[нужна цитата ] Многие интерпретаторы не выполняют исходный код в его нынешнем виде, а преобразуют его в более компактную внутреннюю форму. Много БАЗОВЫЙ переводчики заменяют ключевые слова с одним байт жетоны который можно использовать, чтобы найти инструкцию в таблица прыжков. Несколько переводчиков, например PBASIC интерпретатора, достичь еще более высокого уровня сжатия программы за счет использования побитно-ориентированной, а не побайтовой структуры памяти программы, где токены команд занимают, возможно, 5 бит, номинально «16-битные» константы хранятся в код переменной длины требуется 3, 6, 10 или 18 бит, а операнды адреса включают «битовое смещение». Многие интерпретаторы BASIC могут сохранять и считывать собственное токенизированное внутреннее представление.
| Игрушка C интерпретатор выражений |
|---|
// типы данных для абстрактного синтаксического дереваперечислить _вид { кВАр, kConst, kSum, kDiff, kMult, kDiv, kPlus, kMinus, узел };структура _variable { int *объем памяти; };структура _constant { int ценность; };структура _unaryOperation { структура _узел *правильно; };структура _binaryOperation { структура _узел *осталось, *правильно; };структура _узел { перечислить _вид вид; союз _expression { структура _variable переменная; структура _constant постоянный; структура _binaryOperation двоичный; структура _unaryOperation унарный; } е;};// процедура интерпретатораint executeIntExpression(const структура _узел *п) { int leftValue, rightValue; переключатель (п->вид) { кейс кВАр: вернуть *п->е.переменная.объем памяти; кейс kConst: вернуть п->е.постоянный.ценность; кейс kSum: кейс kDiff: кейс kMult: кейс kDiv: leftValue = executeIntExpression(п->е.двоичный.осталось); rightValue = executeIntExpression(п->е.двоичный.правильно); переключатель (п->вид) { кейс kSum: вернуть leftValue + rightValue; кейс kDiff: вернуть leftValue - rightValue; кейс kMult: вернуть leftValue * rightValue; кейс kDiv: если (rightValue == 0) исключение("деление на ноль"); // не возвращает вернуть leftValue / rightValue; } кейс kPlus: кейс kMinus: кейс узел: rightValue = executeIntExpression(п->е.унарный.правильно); переключатель (п->вид) { кейс kPlus: вернуть + rightValue; кейс kMinus: вернуть - rightValue; кейс узел: вернуть ! rightValue; } по умолчанию: исключение("внутренняя ошибка: недопустимый вид выражения"); }} |
Переводчик вполне может использовать то же самое лексический анализатор и парсер как компилятор, а затем интерпретировать полученный абстрактное синтаксическое дерево.Пример определений типов данных для последнего и игрушечный интерпретатор для синтаксических деревьев, полученных из C выражения показаны в рамке.
Регресс
Интерпретация не может использоваться в качестве единственного метода выполнения: даже если интерпретатор сам может быть интерпретирован и т. Д., Непосредственно выполняемая программа необходима где-то в нижней части стека, поскольку интерпретируемый код по определению не такой же, как машинный код, который может выполнять ЦП.[6][7]
Вариации
Интерпретаторы байт-кода
Существует целый спектр возможностей между интерпретацией и компиляцией, в зависимости от объема анализа, выполненного перед выполнением программы. Например, Emacs Lisp составлен для байт-код, который представляет собой сильно сжатое и оптимизированное представление исходного кода Лиспа, но не является машинным кодом (и поэтому не привязан к какому-либо конкретному оборудованию). Этот "скомпилированный" код затем интерпретируется интерпретатором байт-кода (сам написан на C ). Скомпилированный код в этом случае является машинным кодом для виртуальная машина, реализованный не аппаратно, а в интерпретаторе байт-кода. Такие компилирующие интерпретаторы иногда также называют счетчики.[8][9] В интерпретаторе байт-кода каждая инструкция начинается с байта, поэтому интерпретаторы байт-кода имеют до 256 инструкций, хотя не все могут использоваться. Некоторые байт-коды могут занимать несколько байтов и могут быть произвольно сложными.
Таблицы управления - которые не обязательно должны проходить через фазу компиляции - диктуют соответствующие алгоритмические поток управления через настраиваемые интерпретаторы аналогично интерпретаторам байт-кода.
Потоковые интерпретаторы кода
Интерпретаторы потокового кода похожи на интерпретаторы байт-кода, но вместо байтов они используют указатели. Каждая «инструкция» - это слово, указывающее на функцию или последовательность инструкций, за которым, возможно, следует параметр. Интерпретатор многопоточного кода либо зацикливает выборку инструкций и вызов функций, на которые они указывают, либо выбирает первую инструкцию и переходит к ней, и каждая последовательность инструкций заканчивается выборкой и переходом к следующей инструкции. В отличие от байт-кода нет эффективного ограничения на количество различных инструкций, кроме доступной памяти и адресного пространства. Классическим примером многопоточного кода является Четвертый код, используемый в Открытая прошивка систем: исходный язык компилируется в "F-код" (байт-код), который затем интерпретируется виртуальная машина.[нужна цитата ]
Интерпретаторы абстрактного синтаксического дерева
В спектре между интерпретацией и компиляцией существует другой подход: преобразовать исходный код в оптимизированное абстрактное синтаксическое дерево (AST), затем выполнить программу, следуя этой древовидной структуре, или использовать ее для генерации собственного кода. вовремя.[10] При таком подходе каждое предложение нужно анализировать только один раз. В качестве преимущества перед байт-кодом AST сохраняет глобальную структуру программы и отношения между операторами (которые теряются в представлении байт-кода), а при сжатии обеспечивает более компактное представление.[11] Таким образом, использование AST было предложено как лучший промежуточный формат для оперативных компиляторов, чем байт-код. Кроме того, это позволяет системе выполнять лучший анализ во время выполнения.
Однако для интерпретаторов AST вызывает больше накладных расходов, чем интерпретатор байт-кода, из-за узлов, связанных с синтаксисом, не выполняющих полезной работы, менее последовательного представления (требующего обхода большего количества указателей) и накладных расходов на посещение дерева.[12]
Своевременная компиляция
Дальнейшее стирание различия между интерпретаторами, интерпретаторами байт-кода и компиляцией - это своевременная компиляция (JIT), метод, при котором промежуточное представление компилируется в собственное Машинный код во время выполнения. Это обеспечивает эффективность выполнения собственного кода за счет времени запуска и увеличения использования памяти при первой компиляции байт-кода или AST. Самый ранний опубликованный JIT-компилятор обычно приписывают работе над LISP от Джон Маккарти в 1960 г.[13] Адаптивная оптимизация это дополнительный метод, в котором интерпретатор профилирует запущенную программу и компилирует ее наиболее часто выполняемые части в собственный код. Последнему методу несколько десятилетий, и он встречается в таких языках, как Болтовня в 1980-е гг.[14]
Компиляция «точно в срок» в последние годы привлекла к себе внимание разработчиков языков. Ява, то .NET Framework, самый современный JavaScript реализации и Matlab теперь включая JIT.[нужна цитата ]
Самостоятельный переводчик
Самоинтерпретатор - это язык программирования интерпретатор, написанный на языке программирования, который может интерпретировать сам себя; пример - это БАЗОВЫЙ интерпретатор написан на БЕЙСИКЕ. Самостоятельные переводчики относятся к компиляторы с собственным хостингом.
Если нет компилятор существует для интерпретируемого языка, создание самоинтерпретатора требует реализации языка на основном языке (который может быть другим языком программирования или ассемблер ). Имея такой первый интерпретатор, система становится загруженный и новые версии интерпретатора могут быть разработаны на самом языке. Именно так Дональд Кнут разработал интерпретатор TANGLE для языка WEB промышленного стандарта TeX система набора.
Определение компьютерного языка обычно выполняется в отношении абстрактной машины (так называемой операционная семантика ) или как математическая функция (денотационная семантика ). Язык также может быть определен интерпретатором, в котором задана семантика основного языка. Определение языка самоинтерпретатором не является хорошо обоснованным (он не может определить язык), но самоинтерпретатор рассказывает читателю о выразительности и элегантности языка. Это также позволяет интерпретатору интерпретировать его исходный код, что является первым шагом к рефлексивной интерпретации.
Важным аспектом проектирования при реализации самоинтерпретатора является то, реализована ли функция интерпретируемого языка с такой же функцией на основном языке интерпретатора. Примером может служить закрытие в Лисп -подобный язык реализуется с использованием замыканий на языке интерпретатора или реализуется «вручную» со структурой данных, явно хранящей среду. Чем больше функций реализовано той же функцией на основном языке, тем меньше возможностей у программиста интерпретатора; другое поведение при работе с переполнением чисел не может быть реализовано, если арифметические операции делегированы соответствующим операциям на основном языке.
В некоторых языках есть элегантный самоинтерпретатор, например Лисп или Пролог.[15] Большое количество исследований самоинтерпретаторов (особенно рефлексивных переводчиков) было проведено в Язык программирования схем, диалект Лиспа. В общем, однако, любые Полный по Тьюрингу язык позволяет писать собственный интерпретатор. Лисп является таким языком, потому что программы на Лиспе представляют собой списки символов и другие списки. XSLT является таким языком, потому что программы XSLT написаны на XML. Поддомен метапрограммирования - это написание предметно-ориентированные языки (DSL).
Клайв Гиффорд представил[16] мера качества самоинтерпретатора (собственное отношение), предел соотношения между компьютерным временем, затраченным на выполнение стека N самоинтерпретаторы и время, потраченное на запуск стопки N − 1 самоинтерпретаторы как N уходит в бесконечность. Это значение не зависит от запущенной программы.
Книга Структура и интерпретация компьютерных программ представляет примеры мета-круговая интерпретация для схемы и ее диалектов. Другие примеры языков с самоинтерпретатором: Четвертый и Паскаль.
Микрокод
Микрокод - это очень часто используемый метод, «который устанавливает интерпретатор между аппаратным обеспечением и архитектурным уровнем компьютера».[17] Таким образом, микрокод представляет собой уровень инструкций аппаратного уровня, реализующих высокоуровневые Машинный код инструкции или внутренние Государственный аппарат последовательность во многих цифровая обработка элементы. Микрокод используется в универсальных центральные процессоры, а также в более специализированных процессорах, таких как микроконтроллеры, цифровые сигнальные процессоры, контроллеры каналов, контроллеры дисков, контроллеры сетевого интерфейса, сетевые процессоры, графические процессоры, и в другом оборудовании.
Микрокод обычно находится в специальной высокоскоростной памяти и переводит машинные инструкции, Государственный аппарат данные или другой ввод в последовательности подробных операций на уровне схемы. Он отделяет машинные инструкции от лежащих в основе электроника так что инструкции могут быть разработаны и изменены более свободно. Это также облегчает построение сложных многоступенчатых инструкций, уменьшая сложность компьютерных схем. Написание микрокода часто называют микропрограммирование а микрокод в конкретной реализации процессора иногда называют микропрограмма.
Более обширное микрокодирование позволяет компактно и просто микроархитектуры к подражать более мощные архитектуры с более широкими длина слова, Больше исполнительные единицы и так далее, что является относительно простым способом достижения программной совместимости между различными продуктами семейства процессоров.
Компьютерный процессор
Даже компьютерный процессор без микрокодирования может рассматриваться как интерпретатор немедленного выполнения синтаксического анализа, написанный на языке описания оборудования общего назначения, таком как VHDL чтобы создать систему, которая анализирует инструкции машинного кода и немедленно их выполняет.
Приложения
- Переводчики часто используются для выполнения командные языки, и склеить языки поскольку каждый оператор, выполняемый на языке команд, обычно является вызовом сложной процедуры, такой как редактор или компилятор.[нужна цитата ]
- Самомодифицирующийся код может быть легко реализован на интерпретируемом языке. Это относится к истокам интерпретации в Лиспе и искусственный интеллект исследование.[нужна цитата ]
- Виртуализация. Машинный код, предназначенный для аппаратной архитектуры, может быть запущен с использованием виртуальная машина. Это часто используется, когда предполагаемая архитектура недоступна, или, среди прочего, для запуска нескольких копий.
- Песочница: Хотя некоторые типы песочниц полагаются на средства защиты операционной системы, часто используется интерпретатор или виртуальная машина. Фактическая архитектура оборудования и изначально предполагаемая архитектура оборудования могут совпадать, а могут и не совпадать. Это может показаться бессмысленным, за исключением того, что песочницы не обязаны фактически выполнять все инструкции исходного кода, которые они обрабатывают. В частности, он может отказаться выполнять код, нарушающий любые безопасность ограничения, в которых он действует.[нужна цитата ]
- Эмуляторы для запуска компьютерного программного обеспечения, написанного для устаревшего и недоступного оборудования, на более современном оборудовании.
Смотрите также
- БЕЙСИК-интерпретатор
- Интерпретатор командной строки
- Скомпилированный язык
- Динамическая компиляция
- Интерпретируемый язык
- Мета-круговой оценщик
- Частичная оценка
- Гомоиконность
Примечания и ссылки
- ^ В этом смысле ЦПУ также является интерпретатором машинных инструкций.
- ^ Хотя эта схема (объединение стратегии 2 и 3) использовалась для реализации некоторых интерпретаторов BASIC уже в 1970-х годах, таких как эффективный интерпретатор BASIC ABC 80, например.
- ^ Bennett, J.M .; Prinz, D.G .; Вудс, М. Л. (1952). «Интерпретативные подпрограммы». Материалы Национальной конференции ACM, Торонто.
- ^ Согласно тому, что сообщил Пол Грэм в Хакеры и художники, п. 185, Маккарти сказал: "Стив Рассел сказал, послушайте, почему бы мне не запрограммировать это оценка..., и я сказал ему, хо-хо, ты путаешь теорию с практикой, это оценка предназначен для чтения, а не для вычислений. Но он пошел вперед и сделал это. То есть он составил оценка в моей статье в IBM 704 машинный код, фиксация ошибка, а затем рекламировали это как интерпретатор Лиспа, что, безусловно, и было. Так что на тот момент Лисп имел по существу ту форму, которую имеет сегодня ... "
- ^ «Почему первый компилятор был написан до первого интерпретатора?». Ars Technica. Получено 9 ноября 2014.
- ^ Теодор Х. Ромер, Деннис Ли, Джеффри М. Фолькер, Алек Вулман, Уэйн А. Вонг, Жан-Лу Бэр, Брайан Н. Бершад и Генри М. Леви, Состав и работа переводчиков
- ^ Теренс Парр, Йоханнес Любер, Разница между компиляторами и интерпретаторами В архиве 2014-01-06 в Wayback Machine
- ^ Кюнель, Клаус (1987) [1986]. «4. Kleincomputer - Eigenschaften und Möglichkeiten» [4. Микрокомпьютер - Свойства и возможности. В Эрлекампфе, Райнер; Mönk, Hans-Joachim (ред.). Микроэлектроник в любительской практике [Микроэлектроника для практического любителя] (на немецком языке) (3-е изд.). Берлин: Militärverlag der Deutschen Demokratischen Republik, Лейпциг. п. 222. ISBN 3-327-00357-2. 7469332.
- ^ Хейн Р. (1984). "Basic-Compreter für U880" [BASIC compreter for U880 (Z80)]. Radio-Fernsehn-Elektronik (на немецком). 1984 (3): 150–152.
- ^ Промежуточные представления AST, Лямбда The Ultimate форум
- ^ Древовидная альтернатива байт-кодам Java, Томас Кистлер, Майкл Франц
- ^ Surfin 'Safari - Архив блога »Объявление о SquirrelFish. Webkit.org (02.06.2008). Проверено 10 августа 2013.
- ^ Эйкок 2003, 2. Методы JIT-компиляции, 2.1 Genesis, стр. 98.
- ^ Л. Дойч, А. Шиффман, Эффективное внедрение системы Smalltalk-80, Материалы 11 симпозиума POPL, 1984.
- ^ Бондорф, Андерс. "Logimix: самоприменимый частичный оценщик для Prolog. "Синтез и преобразование логических программ. Springer, London, 1993. 214-227.
- ^ Гиффорд, Клайв. "Собственные отношения самоинтерпретаторов". Blogger. Получено 10 ноября 2019.
- ^ Кент, Аллен; Уильямс, Джеймс Г. (5 апреля 1993 г.). Энциклопедия компьютерных наук и технологий: Том 28 - Приложение 13. Нью-Йорк: Marcel Dekker, Inc. ISBN 0-8247-2281-7. Получено 17 янв, 2016.
внешние ссылки
- Интерпретаторы карт IBM страница в Колумбийском университете
- Теоретические основы практического «полностью функционального программирования» (Особенно в главе 7) Докторская диссертация, посвященная проблеме формализации того, что такое переводчик
- Короткая анимация объяснение ключевой концептуальной разницы между интерпретаторами и компиляторами

| Авторитетный контроль |
|---|