Компилятор - Википедия - Compiler
| Выполнение программы |
|---|
| Общие понятия |
| Типы кода |
| Стратегии компиляции |
| Заметное время выполнения |
|
| Известные компиляторы и инструментальные средства |
В вычисление, а компилятор это компьютерная программа который переводит компьютерный код написан в одном язык программирования (в источник язык) на другой язык ( цель язык). Название "компилятор" в основном используется для программ, которые переводят исходный код из язык программирования высокого уровня к язык нижнего уровня (например., язык ассемблера, объектный код, или же Машинный код ) для создания исполняемый файл программа.[1][2]:p1
Есть много разных типов компиляторов. Если скомпилированная программа может работать на компьютере, ЦПУ или же Операционная система отличается от того, на котором работает компилятор, компилятор является кросс-компилятор. А компилятор начальной загрузки написан на языке, который он собирается компилировать. Программа, которая переводит с языка низкого уровня на язык более высокого уровня, является декомпилятор. Программа, которая переводит между языками высокого уровня, обычно называется компилятор исходного кода или же транскомпилятор. Язык переписчик обычно это программа, которая переводит форму выражения без смены языка. Период, термин компилятор-компилятор относится к инструментам, используемым для создания синтаксических анализаторов, выполняющих синтаксический анализ.
Компилятор, скорее всего, выполнит многие или все из следующих операций: предварительная обработка, лексический анализ, разбор, семантический анализ (синтаксически управляемый перевод ), преобразование входных программ в промежуточное представление, оптимизация кода и генерация кода. Компиляторы реализуют эти операции поэтапно, что способствует эффективному проектированию и исправлению трансформации от исходного ввода до целевого вывода. Ошибки программы, вызванные неправильным поведением компилятора, очень трудно отследить и обойти; поэтому разработчики компилятора прилагают значительные усилия, чтобы обеспечить корректность компилятора.[3]
Компиляторы - не единственный языковой процессор, используемый для преобразования исходных программ. An устный переводчик представляет собой компьютерное программное обеспечение, которое преобразует, а затем выполняет указанные операции.[2]:p2 Процесс перевода влияет на дизайн компьютерных языков, что приводит к предпочтению компиляции или интерпретации. На практике интерпретатор может быть реализован для компилируемых языков, а компиляторы могут быть реализованы для интерпретируемых языков.
История
Концепции теоретических вычислений, разработанные учеными, математиками и инженерами, легли в основу современных цифровых вычислений во время Второй мировой войны. Примитивные двоичные языки развивались, потому что цифровые устройства понимают только единицы и нули, а также шаблоны схем в базовой архитектуре машины. В конце 1940-х годов были созданы языки ассемблера, чтобы предложить более работоспособную абстракцию компьютерных архитектур. Ограничено объем памяти мощность первых компьютеров привела к серьезным техническим проблемам при разработке первых компиляторов. Поэтому процесс компиляции нужно было разбить на несколько небольших программ. Внешние программы создают продукты анализа, используемые внутренними программами для генерации целевого кода. Поскольку компьютерные технологии предоставляют больше ресурсов, конструкции компиляторов могут лучше согласовываться с процессом компиляции.
Обычно для программиста более продуктивно использовать язык высокого уровня, поэтому разработка языков высокого уровня естественным образом вытекала из возможностей, предлагаемых цифровыми компьютерами. Языки высокого уровня формальные языки которые строго определены своим синтаксисом и семантикой, которые образуют архитектуру языка высокого уровня. Элементы этих формальных языков включают:
- Алфавит, любой конечный набор символов;
- Нить, конечная последовательность символов;
- Язык, любой набор строк в алфавите.
Предложения на языке могут быть определены набором правил, называемых грамматикой.[4]
Форма Бэкуса – Наура (BNF) описывает синтаксис «предложений» языка и использовался для синтаксиса Algol 60 Джон Бэкус.[5] Идеи вытекают из контекстно-свободная грамматика концепции Ноам Хомский, лингвист.[6] «BNF и его расширения стали стандартными инструментами для описания синтаксиса программных обозначений, и во многих случаях части компиляторов генерируются автоматически из описания BNF».[7]
В 1940-х годах Конрад Зузе разработал язык алгоритмического программирования под названием Plankalkül («Расчет плана»). Хотя фактической реализации не было до 1970-х годов, в нем были представлены концепции, которые позже были представлены в APL разработан Кеном Айверсоном в конце 1950-х годов.[8] APL - это язык математических вычислений.
Дизайн языков высокого уровня в годы становления цифровых вычислений предоставил полезные инструменты программирования для множества приложений:
- FORTRAN (Перевод формул) для инженерных и научных приложений считается первым языком высокого уровня.[9]
- КОБОЛ (Общий бизнес-ориентированный язык) произошел от А-0 и ПОТОК-MATIC стать доминирующим языком высокого уровня для бизнес-приложений.[10]
- LISP (Обработчик списка) для символьных вычислений.[11]
Технология компиляции возникла из необходимости строго определенного преобразования исходной программы высокого уровня в целевую программу низкого уровня для цифрового компьютера. Компилятор можно рассматривать как внешний интерфейс, который занимается анализом исходного кода, и как серверную часть, чтобы синтезировать анализ в целевой код. Оптимизация между интерфейсом и сервером может дать более эффективный целевой код.[12]
Некоторые первые вехи в развитии технологии компиляторов:
- 1952 - An Автокодирование компилятор разработан Алик Гленни для Манчестер Марк I компьютер в Манчестерском университете считается некоторыми первым компилируемым языком программирования.
- 1952 – Грейс Хоппер команда в Ремингтон Рэнд написал компилятор для А-0 язык программирования (и придумал термин компилятор чтобы описать это),[13][14] хотя компилятор A-0 функционировал больше как загрузчик или компоновщик, чем современные представления о полном компиляторе.
- 1954-1957 - Команда во главе с Джон Бэкус в IBM развитый FORTRAN который обычно считается первым языком высокого уровня. В 1957 году они завершили компилятор FORTRAN, который, как обычно считается, представил первый однозначно завершенный компилятор.
- 1959 - Конференция по языку систем данных (CODASYL) инициировала разработку КОБОЛ. Дизайн COBOL основан на A-0 и FLOW-MATIC. К началу 1960-х COBOL был скомпилирован на нескольких архитектурах.
- 1958-1962 – Джон Маккарти в Массачусетский технологический институт разработан LISP.[15] Возможности обработки символов предоставили полезные функции для исследований искусственного интеллекта. В 1962 году в выпуске LISP 1.5 были отмечены некоторые инструменты: интерпретатор, написанный Стивеном Расселом, и Дэниел Дж. Эдвардс, компилятор и ассемблер, написанный Тимом Хартом и Майком Левином.[16]
Ранние операционные системы и программное обеспечение были написаны на языке ассемблера. В 1960-х и начале 1970-х годов использование языков высокого уровня для системного программирования все еще оставалось спорным из-за ограничений ресурсов. Однако некоторые исследования и отраслевые усилия положили начало переходу на языки системного программирования высокого уровня, например, BCPL, БЛАЖЕНСТВО, B, и C.
BCPL (Базовый комбинированный язык программирования), разработанный в 1966 г. Мартин Ричардс в Кембриджском университете изначально разрабатывался как инструмент для написания компиляторов.[17] Было реализовано несколько компиляторов, книга Ричардса дает представление о языке и его компиляторе.[18] BCPL был не только влиятельным языком системного программирования, который до сих пор используется в исследованиях.[19] но также послужил основой для разработки языков B и C.
БЛАЖЕНСТВО (Базовый язык для реализации системного программного обеспечения) был разработан для компьютера PDP-10 Digital Equipment Corporation (DEC) исследовательской группой Университета Карнеги-Меллона (CMU) W.A. Wulf. Группа CMU продолжила разработку компилятора BLISS-11 год спустя, в 1970 году.
Мультики (Multiplexed Information and Computing Service), проект операционной системы с разделением времени. Массачусетский технологический институт, Bell Labs, General Electric (потом Honeywell ) и руководил Фернандо Корбато из Массачусетского технологического института.[20] Multics был написан в PL / I язык, разработанный IBM и IBM User Group.[21] Целью IBM было удовлетворение требований бизнеса, науки и системного программирования. Могли быть рассмотрены и другие языки, но PL / I предлагал наиболее полное решение, хотя оно и не было реализовано.[22] В течение первых нескольких лет проекта Mulitics подмножество языка могло быть скомпилировано на язык ассемблера с помощью компилятора Early PL / I (EPL) Дугом Макилори и Бобом Моррисом из Bell Labs.[23] EPL поддерживал проект до тех пор, пока не был разработан компилятор для полной загрузки PL / I.[24]
Bell Labs покинула проект Multics в 1969 году: «Со временем надежда сменилась разочарованием, поскольку изначально групповые усилия не привели к созданию экономически полезной системы».[25] Продолжение участия увеличит расходы на поддержку проекта. Поэтому исследователи обратились к другим разработкам. Системный язык программирования B на основе концепций BCPL был написан Деннис Ричи и Кен Томпсон. Ричи создал загрузочный компилятор для B и написал Unics (Uniplexed Information and Computing Service) операционная система для PDP-7 в B. Unics в конечном итоге стала называться Unix.
Bell Labs начала разработку и расширение C на основе B и BCPL. Компилятор BCPL был перенесен в Multics компанией Bell Labs, и BCPL был предпочтительным языком в Bell Labs.[26] Первоначально использовалась интерфейсная программа для компилятора B Bell Labs, а компилятор C был разработан. В 1971 году новый PDP-11 предоставил ресурсы для определения расширений B и переписывания компилятора. К 1973 году разработка языка C была по существу завершена, и ядро Unix для PDP-11 было переписано на C. Стив Джонсон начал разработку Portable C Compiler (PCC) для поддержки перенацеливания компиляторов C на новые машины.[27][28]
Объектно-ориентированного программирования (ООП) предлагает несколько интересных возможностей для разработки и обслуживания приложений. Концепции ООП восходят к прошлому, но были частью LISP и Симула языковедение.[29] В Bell Labs разработка C ++ заинтересовался ООП.[30] C ++ впервые был использован в 1980 году для системного программирования. Первоначальный дизайн использовал возможности системного программирования на языке C с концепциями Simula. Объектно-ориентированные средства были добавлены в 1983 году.[31] Программа Cfront реализовала интерфейс C ++ для компилятора языка C84. В последующие годы по мере роста популярности C ++ было разработано несколько компиляторов C ++.
Во многих прикладных областях быстро прижилась идея использования языка более высокого уровня. Из-за расширяющейся функциональности, поддерживаемой более новыми языки программирования и с ростом сложности компьютерных архитектур компиляторы стали более сложными.
DARPA (Агентство перспективных исследовательских проектов Министерства обороны США) спонсировало проект компилятора с исследовательской группой CMU Вульфа в 1970 году. Компилятор-компилятор производственного качества PQCC design создаст компилятор производственного качества (PQC) на основе формальных определений исходного языка и цели.[32] PQCC попытался расширить термин компилятор-компилятор за пределы традиционного значения генератора синтаксического анализатора (например, Yacc ) без особого успеха. PQCC правильнее было бы называть генератором компилятора.
Исследование PQCC по процессу генерации кода было направлено на создание действительно автоматической системы написания компилятора. В рамках этой работы была обнаружена и разработана фазовая структура PQC. Компилятор BLISS-11 предоставил исходную структуру.[33] Этапы включали анализ (внешний интерфейс), промежуточный перевод в виртуальную машину (средний этап) и перевод в целевой объект (серверный интерфейс). TCOL был разработан для исследования PQCC для обработки языковых конструкций в промежуточном представлении.[34] Варианты TCOL поддерживают разные языки. В рамках проекта PQCC изучались методы построения автоматизированного компилятора. Концепции дизайна оказались полезными при оптимизации компиляторов и компиляторов для объектно-ориентированного языка программирования. Ада.
Документ Ады Стоунман формализовал среду поддержки программ (APSE) вместе с ядром (KAPSE) и минимальным (MAPSE). Переводчик Ada NYU / ED поддерживал разработку и стандартизацию усилий Американского национального института стандартов (ANSI) и Международной организации стандартов (ISO). Первоначальная разработка компилятора Ada военными службами США включала компиляторы в полностью интегрированную среду проектирования в соответствии с положениями документа Stoneman Document. Армия и флот работали над проектом Ada Language System (ALS), ориентированным на архитектуру DEC / VAX, в то время как ВВС начали над интегрированной средой Ada (AIE), ориентированной на серию IBM 370. Хотя проекты не принесли желаемых результатов, они внесли свой вклад в общие усилия по разработке Ada.[35]
Другие разработки компилятора Ada были предприняты в Великобритании в Йоркском университете и в Германии в университете Карлсруэ. В США компания Verdix (позже приобретенная Rational) предоставила армии Verdix Ada Development System (VADS). VADS предоставил набор инструментов разработки, включая компилятор. Unix / VADS может быть размещен на различных платформах Unix, таких как DEC Ultrix и Sun 3/60 Solaris, предназначенных для Motorola 68020 в оценке Army CECOM.[36] Вскоре появилось много компиляторов Ada, которые прошли проверку Ada Validation. Проект GNU Free Software Foundation разработал Коллекция компиляторов GNU (GCC), который предоставляет основную возможность для поддержки нескольких языков и целевых приложений. Версия Ады GNAT является одним из наиболее широко используемых компиляторов Ada. GNAT бесплатен, но есть также коммерческая поддержка, например, AdaCore была основана в 1994 году для предоставления коммерческих программных решений для Ada. GNAT Pro включает GNU на основе GNU GCC с набором инструментов для обеспечения интегрированная среда развития.
Языки высокого уровня продолжали стимулировать исследования и разработки компиляторов. Основные области включали оптимизацию и автоматическую генерацию кода. Тенденции в языках программирования и средах разработки повлияли на технологию компиляции. В языковые дистрибутивы (PERL, Java Development Kit) и в качестве компонента IDE (VADS, Eclipse, Ada Pro) вошло больше компиляторов. Взаимосвязь и взаимозависимость технологий росли. Появление веб-сервисов способствовало развитию веб-языков и языков сценариев. Сценарии восходят к ранним дням появления интерфейсов командной строки (CLI), когда пользователь мог вводить команды для выполнения системой. Концепции пользовательской оболочки, разработанные с использованием языков для написания программ оболочки. Ранние разработки Windows предлагали простую возможность пакетного программирования. При обычном преобразовании этих языков использовался интерпретатор. Компиляторы Bash и Batch были написаны, хотя и не получили широкого распространения. Совсем недавно сложные интерпретируемые языки стали частью набора инструментов разработчиков. Современные языки сценариев включают PHP, Python, Ruby и Lua. (Lua широко используется при разработке игр.) Все они имеют поддержку интерпретатора и компилятора.[37]
«Когда область компиляции началась в конце 50-х годов, ее внимание было ограничено переводом программ на языке высокого уровня в машинный код ... Сфера компиляции все больше переплетается с другими дисциплинами, включая компьютерную архитектуру, языки программирования, формальные методы, программная инженерия и компьютерная безопасность ".[38] В статье "Compiler Research: The Next 50 Years" отмечена важность объектно-ориентированных языков и Java. Безопасность и параллельные вычисления были названы среди целей будущих исследований.
Конструкция компилятора
Эта статья включает в себя список общих Рекомендации, но он остается в основном непроверенным, потому что ему не хватает соответствующих встроенные цитаты. (Декабрь 2019 г.) (Узнайте, как и когда удалить этот шаблон сообщения) |
Компилятор выполняет формальное преобразование исходной программы высокого уровня в целевую программу низкого уровня. Конструкция компилятора может определять сквозное решение или заниматься определенным подмножеством, которое взаимодействует с другими инструментами компиляции, например. препроцессоры, ассемблеры, линкеры. Требования к дизайну включают строго определенные интерфейсы как внутри между компонентами компилятора, так и снаружи между вспомогательными наборами инструментов.
Вначале подход к проектированию компилятора напрямую зависел от сложности обрабатываемого компьютерного языка, опыта человека (лиц), разрабатывающего его, и доступных ресурсов. Ограниченность ресурсов привела к необходимости повторения исходного кода более одного раза.
Компилятор относительно простого языка, написанный одним человеком, может представлять собой единую монолитную часть программного обеспечения. Однако по мере того, как исходный язык усложняется, проект может быть разделен на несколько взаимозависимых фаз. Отдельные этапы обеспечивают улучшения дизайна, которые фокусируют разработку на функциях в процессе компиляции.
Сравнение однопроходных и многопроходных компиляторов
Классификация компиляторов по количеству проходов проистекает из ограничений аппаратных ресурсов компьютеров. Компиляция включает в себя выполнение большого объема работы, и на ранних версиях компьютеров не было достаточно памяти, чтобы содержать одну программу, которая выполняла бы всю эту работу. Таким образом, компиляторы были разделены на более мелкие программы, каждая из которых просматривала исходный текст (или его представление), выполняя необходимый анализ и перевод.
Возможность компилировать в один проход классически рассматривается как преимущество, поскольку упрощает работу по написанию компилятора, а однопроходные компиляторы обычно выполняют компиляцию быстрее, чем многопроходные компиляторы. Таким образом, частично из-за ограничений ресурсов ранних систем, многие ранние языки были специально разработаны так, чтобы их можно было скомпилировать за один проход (например, Паскаль ).
В некоторых случаях при разработке языковой функции может потребоваться, чтобы компилятор выполнял более одного прохода по источнику. Например, рассмотрим объявление, появляющееся в строке 20 исходного текста, которое влияет на перевод оператора, отображаемого в строке 10. В этом случае на первом проходе необходимо собрать информацию об объявлениях, появляющихся после операторов, которые они затрагивают, с фактическим переводом. во время последующего прохода.
Недостаток компиляции за один проход заключается в том, что невозможно выполнить многие из сложных оптимизации необходимо для генерации высококачественного кода. Трудно подсчитать, сколько проходов делает оптимизирующий компилятор. Например, разные фазы оптимизации могут анализировать одно выражение много раз, но анализировать другое выражение только один раз.
Разделение компилятора на небольшие программы - это метод, используемый исследователями, заинтересованными в создании достоверно корректных компиляторов. Доказательство правильности набора небольших программ часто требует меньше усилий, чем доказательство правильности более крупной, единственной эквивалентной программы.
Трехступенчатая структура компилятора

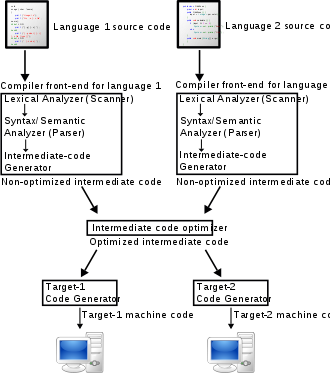
Независимо от точного количества фаз в проекте компилятора, фазы можно отнести к одному из трех этапов. Этапы включают в себя переднюю, среднюю и заднюю части.
- В внешний интерфейс проверяет синтаксис и семантику в соответствии с определенным исходным языком. За статически типизированные языки он выполняет проверка типа путем сбора информации о типе. Если программа ввода синтаксически неверна или имеет ошибку типа, она генерирует сообщения об ошибках и / или предупреждениях, обычно идентифицируя место в исходном коде, где была обнаружена проблема; в некоторых случаях фактическая ошибка может быть (намного) раньше в программе. Аспекты внешнего интерфейса включают лексический анализ, синтаксический анализ и семантический анализ. Внешний интерфейс преобразует входную программу в промежуточное представление (IR) для дальнейшей обработки средним концом. Этот IR обычно является представлением программы более низкого уровня по отношению к исходному коду.
- В средний конец выполняет оптимизацию IR, которая не зависит от целевой архитектуры ЦП. Эта независимость исходного кода / машинного кода предназначена для обеспечения возможности совместной оптимизации между версиями компилятора, поддерживающими разные языки и целевые процессоры. Примеры оптимизации среднего уровня: удаление бесполезных (устранение мертвого кода ) или недоступный код (анализ достижимости ), открытие и распространение постоянных значений (постоянное распространение ), перемещение вычислений в менее часто выполняемое место (например, вне цикла) или специализация вычислений на основе контекста. В конечном итоге создается «оптимизированный» IR, который используется серверной частью.
- В задняя часть берет оптимизированный IR с середины. Он может выполнять больше анализа, преобразований и оптимизаций, специфичных для целевой архитектуры ЦП. Серверная часть генерирует целевой ассемблерный код, выполняя распределение регистров в процессе. Серверная часть выполняет планирование инструкций, который переупорядочивает инструкции для сохранения параллельности исполнительные единицы занят заполнением слоты задержки. Хотя большинство проблем оптимизации NP-жесткий, эвристический методы их решения хорошо разработаны и в настоящее время реализованы в компиляторах производственного качества. Обычно выходные данные серверной части представляют собой машинный код, специализированный для конкретного процессора и операционной системы.
Такой внешний / средний / внутренний подход позволяет комбинировать внешние интерфейсы для разных языков с внутренними интерфейсами для разных языков. Процессоры разделяя оптимизацию среднего конца.[39] Практическими примерами такого подхода являются Коллекция компиляторов GNU, Лязг (LLVM компилятор C / C ++),[40] и Комплект компилятора Amsterdam, которые имеют несколько интерфейсов, общую оптимизацию и несколько серверных частей.
Внешний интерфейс
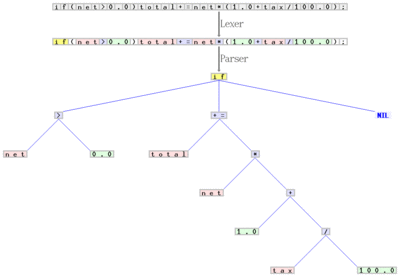
если (нетто> 0,0) итого + = нетто * (1,0 + налог / 100,0);", сканер составляет последовательность жетоны, и классифицирует каждый из них, например, как идентификатор, зарезервированное слово, числовой литерал, или же оператор. Последняя последовательность преобразуется парсером в синтаксическое дерево, который затем обрабатывается оставшимися фазами компилятора. Сканер и парсер обрабатывают обычный и правильно контекстно-свободный части грамматика для C, соответственно.Внешний интерфейс анализирует исходный код для построения внутреннего представления программы, которое называется промежуточное представление (ИК). Он также управляет таблица символов, структура данных, отображающая каждый символ в исходном коде со связанной информацией, такой как местоположение, тип и область действия.
Хотя внешний интерфейс может быть отдельной монолитной функцией или программой, как в безсканирующий парсер, он чаще реализуется и анализируется как несколько этапов, которые могут выполняться последовательно или одновременно. Этот метод пользуется популярностью из-за его модульности и разделение проблем. Чаще всего сегодня интерфейс разбивается на три этапа: лексический анализ (также известный как lexing), синтаксический анализ (также известный как сканирование или синтаксический анализ), и семантический анализ. Лексирование и синтаксический анализ включают синтаксический анализ (синтаксис слов и синтаксис фраз соответственно), и в простых случаях эти модули (лексический анализатор и синтаксический анализатор) могут быть автоматически сгенерированы из грамматики языка, хотя в более сложных случаях они требуют ручной модификации. . Лексическая грамматика и фразовая грамматика обычно контекстно-свободные грамматики, что значительно упрощает анализ, поскольку контекстная чувствительность обрабатывается на этапе семантического анализа. Этап семантического анализа, как правило, более сложен и написан от руки, но может быть частично или полностью автоматизирован с помощью грамматики атрибутов. Сами эти этапы можно разбить на следующие этапы: лексирование как сканирование и оценка, а также анализ как построение конкретное синтаксическое дерево (CST, дерево синтаксического анализа), а затем преобразовав его в абстрактное синтаксическое дерево (AST, синтаксическое дерево). В некоторых случаях используются дополнительные фазы, особенно реконструкция линии и предварительная обработка, но это редкость.
Основные этапы фронтенда включают следующее:
- Реконструкция линии преобразует входную последовательность символов в каноническую форму, готовую для синтаксического анализа. Языки, на которых ремень их ключевые слова или разрешить произвольные пробелы в идентификаторах требуют этого этапа. В сверху вниз, рекурсивный спуск управляемые таблицей парсеры, использовавшиеся в 1960-х годах, обычно считывали исходный текст по одному символу за раз и не требовали отдельной фазы токенизации. Атлас Автокод и Бес (и некоторые реализации АЛГОЛ и Коралловый 66 ) являются примерами стропированных языков, компиляторы которых будут иметь Реконструкция линии фаза.
- Предварительная обработка поддерживает макрос замена и условная компиляция. Обычно этап предварительной обработки происходит перед синтаксическим или семантическим анализом; например в случае C препроцессор управляет лексическими токенами, а не синтаксическими формами. Однако некоторые языки, такие как Схема поддерживают макроподстановки на основе синтаксических форм.
- Лексический анализ (также известный как лексика или же токенизация) разбивает текст исходного кода на последовательность небольших фрагментов, называемых лексические токены.[41] Этот этап можно разделить на два этапа: сканирование, который сегментирует входной текст на синтаксические единицы, называемые лексемы и присвоить им категорию; и оценка, который преобразует лексемы в обработанное значение. Токен - это пара, состоящая из имя токена и необязательный значение токена.[42] Общие категории токенов могут включать идентификаторы, ключевые слова, разделители, операторы, литералы и комментарии, хотя набор категорий токенов варьируется в зависимости от языки программирования. Синтаксис лексемы обычно обычный язык, так что конечный автомат построен из регулярное выражение можно использовать для его распознавания. Программа, выполняющая лексический анализ, называется лексический анализатор. Это не может быть отдельный шаг - его можно объединить с шагом синтаксического анализа в разбор без сканирования, и в этом случае синтаксический анализ выполняется на уровне персонажа, а не на уровне токена.
- Синтаксический анализ (также известный как разбор) включает разбор последовательность токенов для идентификации синтаксической структуры программы. На этом этапе обычно создается дерево синтаксического анализа, который заменяет линейную последовательность токенов древовидной структурой, построенной по правилам формальная грамматика которые определяют синтаксис языка. Дерево синтаксического анализа часто анализируется, дополняется и трансформируется на более поздних этапах работы компилятора.[43]
- Семантический анализ добавляет семантическую информацию к дерево синтаксического анализа и строит таблица символов. На этом этапе выполняются семантические проверки, такие как проверка типа (проверка ошибок типа), или привязка объекта (связывание ссылок на переменные и функции с их определениями) или определенное назначение (требует инициализации всех локальных переменных перед использованием), отклонение неправильных программ или выдача предупреждений. Семантический анализ обычно требует полного дерева синтаксического анализа, что означает, что этот этап логически следует за разбор фазе и логически предшествует генерация кода этап, хотя часто можно объединить несколько этапов в один проход по коду в реализации компилятора.
Средний конец
Средний конец, также известный как оптимизатор, выполняет оптимизацию промежуточного представления, чтобы улучшить производительность и качество производимого машинного кода.[44] Средняя часть содержит те оптимизации, которые не зависят от целевой архитектуры ЦП.
Основные этапы среднего конца включают следующее:
- Анализ: Это сбор программной информации из промежуточного представления, полученного из ввода; анализ потока данных используется для строительства цепочки использования-определения, вместе с анализ зависимости, анализ псевдонимов, анализ указателя, анализ побега и др. Точный анализ - основа любой оптимизации компилятора. В график потока управления каждой скомпилированной функции и график звонков программы обычно также строятся на этапе анализа.
- Оптимизация: представление промежуточного языка преобразуется в функционально эквивалентные, но более быстрые (или меньшие) формы. Популярные оптимизации встроенное расширение, устранение мертвого кода, постоянное распространение, преобразование петли и даже автоматическое распараллеливание.
Анализ компилятора является предпосылкой для любой оптимизации компилятора, и они тесно работают вместе. Например, анализ зависимости имеет решающее значение для преобразование петли.
Объем анализа и оптимизации компилятора сильно различается; их объем может варьироваться от работы в базовый блок, для целых процедур или даже для всей программы. Существует компромисс между степенью детализации оптимизации и стоимостью компиляции. Например, глазок оптимизации быстро выполняются во время компиляции, но влияют только на небольшой локальный фрагмент кода и могут выполняться независимо от контекста, в котором появляется фрагмент кода. В отличие, межпроцедурная оптимизация требует больше времени компиляции и места в памяти, но обеспечивает оптимизацию, которая возможна только при одновременном рассмотрении поведения нескольких функций.
Межпроцедурный анализ и оптимизация распространены в современных коммерческих компиляторах от HP, IBM, SGI, Intel, Microsoft, и Sun Microsystems. В бесплатно программное обеспечение GCC долгое время критиковали за отсутствие мощных межпроцедурных оптимизаций, но в этом отношении ситуация меняется. Другой компилятор с открытым исходным кодом с полной инфраструктурой анализа и оптимизации - это Открыть64, который используется многими организациями в исследовательских и коммерческих целях.
Из-за дополнительного времени и места, необходимого для анализа и оптимизации компилятора, некоторые компиляторы пропускают их по умолчанию. Пользователи должны использовать параметры компиляции, чтобы явно указать компилятору, какие оптимизации следует включить.
Бэк-энд
Серверная часть отвечает за оптимизацию архитектуры процессора и за генерация кода[44].
Основные этапы бэкенда включают следующее:
- Машинно-зависимые оптимизации: оптимизации, зависящие от деталей архитектуры ЦП, на которую нацелен компилятор.[45] Ярким примером является глазок оптимизации, который переписывает короткие последовательности инструкций ассемблера в более эффективные инструкции.
- Генерация кода: преобразованный промежуточный язык переводится на выходной язык, обычно на родной машинный язык системы. Это включает в себя решения о ресурсах и хранилище, такие как решение, какие переменные вписаться в регистры и память и отбор и планирование соответствующих машинных инструкций вместе с соответствующими режимы адресации (смотрите также Алгоритм Сетхи-Ульмана ). Также может потребоваться сгенерировать данные отладки, чтобы облегчить отладка.
Корректность компилятора
Корректность компилятора это раздел разработки программного обеспечения, который пытается показать, что компилятор ведет себя в соответствии с его спецификация языка.[нужна цитата ] Методы включают разработку компилятора с использованием формальные методы и использование строгого тестирования (часто называемого проверкой компилятора) на существующем компиляторе.
Скомпилированные и интерпретируемые языки
Языки программирования более высокого уровня обычно появляются с типом перевод в виду: либо разработан как компилируемый язык или же интерпретируемый язык. Однако на практике в языке редко встречается что-либо, что требует он должен быть исключительно компилирован или интерпретирован исключительно, хотя можно разрабатывать языки, которые полагаются на повторную интерпретацию во время выполнения. Классификация обычно отражает наиболее популярные или широко распространенные реализации языка - например, БАЗОВЫЙ иногда называют интерпретируемым языком, а C - скомпилированным, несмотря на существование компиляторов BASIC и интерпретаторов C.
Интерпретация не заменяет компиляцию полностью. Он только скрывает это от пользователя и делает его постепенным. Несмотря на то, что интерпретатор сам может быть интерпретирован, непосредственно выполняемая программа необходима где-то в нижней части стека (см. машинный язык ).
Кроме того, компиляторы могут содержать интерпретаторы по причинам оптимизации. Например, если выражение может быть выполнено во время компиляции, а результаты вставлены в программу вывода, это предотвращает необходимость его повторного вычисления при каждом запуске программы, что может значительно ускорить окончательную программу. Современные тенденции к своевременная компиляция и интерпретация байт-кода временами еще больше размывают традиционные классификации компиляторов и интерпретаторов.
В некоторых языковых спецификациях сказано, что реализации должен включить средство компиляции; Например, Common Lisp. Однако в определении Common Lisp нет ничего, что мешало бы его интерпретации. В других языках есть функции, которые очень легко реализовать в интерпретаторе, но значительно усложняют написание компилятора; Например, APL, СНОБОЛ4, а многие языки сценариев позволяют программам создавать произвольный исходный код во время выполнения с помощью обычных строковых операций, а затем выполнять этот код, передавая его специальному функция оценки. Чтобы реализовать эти функции на скомпилированном языке, программы обычно должны поставляться с библиотека времени исполнения который включает версию самого компилятора.
Типы
Одна классификация компиляторов по Платформа на котором выполняется их сгенерированный код. Это известно как целевая платформа.
А родные или же принимал компилятор - это тот, выходные данные которого предназначены для непосредственного запуска на том же типе компьютера и операционной системы, на которых работает сам компилятор. Выход кросс-компилятор предназначен для работы на другой платформе. Кросс-компиляторы часто используются при разработке программного обеспечения для встроенные системы которые не предназначены для поддержки среды разработки программного обеспечения.
Результат компилятора, который создает код для виртуальная машина (VM) может выполняться или не выполняться на той же платформе, что и компилятор, который ее создал. По этой причине такие компиляторы обычно не классифицируются как собственные или кросс-компиляторы.
Язык нижнего уровня, который является целью компилятора, может сам быть язык программирования высокого уровня. C, рассматриваемый некоторыми как своего рода переносимый язык ассемблера, часто является целевым языком таких компиляторов. Например, Cfront, оригинальный компилятор для C ++, использовал C в качестве целевого языка. Код C, сгенерированный таким компилятором, обычно не предназначен для чтения и поддержки людьми, поэтому стиль отступа и создание красивого промежуточного кода C игнорируются. Некоторые из особенностей C, которые делают его хорошим целевым языком, включают #линия директива, которая может быть сгенерирована компилятором для поддержки отладка исходного кода и широкая поддержка платформы, доступная с помощью компиляторов C.
Хотя общий тип компилятора выводит машинный код, существует множество других типов:
- Компиляторы исходного кода представляют собой тип компилятора, который принимает на вход язык высокого уровня и выводит язык высокого уровня. Например, автоматическое распараллеливание compiler will frequently take in a high-level language program as an input and then transform the code and annotate it with parallel code annotations (e.g. OpenMP ) or language constructs (e.g. Fortran's
DOALLstatements). - Байт-код compilers that compile to assembly language of a theoretical machine, like some Пролог реализации
- This Prolog machine is also known as the Абстрактная машина Уоррена (or WAM).
- Bytecode compilers for Ява, Python are also examples of this category.
- Just-in-time compilers (JIT compiler) defer compilation until runtime. JIT compilers exist for many modern languages including Python, JavaScript, Болтовня, Ява, Microsoft .СЕТЬ с Common Intermediate Language (CIL) and others. A JIT compiler generally runs inside an interpreter. When the interpreter detects that a code path is "hot", meaning it is executed frequently, the JIT compiler will be invoked and compile the "hot" code for increased performance.
- For some languages, such as Java, applications are first compiled using a bytecode compiler and delivered in a machine-independent промежуточное представление. A bytecode interpreter executes the bytecode, but the JIT compiler will translate the bytecode to machine code when increased performance is necessary.[46][неосновной источник необходим ]
- Hardware compilers (also known as syntheses tools) are compilers whose output is a description of the hardware configuration instead of a sequence of instructions.
- The output of these compilers target компьютерное железо at a very low level, for example a программируемая вентильная матрица (FPGA) or structured специализированная интегральная схема (ASIC).[47][неосновной источник необходим ] Such compilers are said to be hardware compilers, because the source code they compile effectively controls the final configuration of the hardware and how it operates. The output of the compilation is only an interconnection of транзисторы или же таблицы поиска.
- An example of hardware compiler is XST, the Xilinx Synthesis Tool used for configuring FPGAs.[48][неосновной источник необходим ] Similar tools are available from Altera,[49][неосновной источник необходим ] Synplicity, Synopsys and other hardware vendors.[нужна цитата ]
- An ассемблер is a program that compiles human readable язык ассемблера к Машинный код, the actual instructions executed by hardware. The inverse program that translates machine code to assembly language is called a дизассемблер.
- A program that translates from a low-level language to a higher level one is a декомпилятор.[нужна цитата ]
- A program that translates between high-level languages is usually called a language translator, компилятор исходного кода, language converter, or language rewriter.[нужна цитата ] The last term is usually applied to translations that do not involve a change of language.[50]
- A program that translates into an object code format that is not supported on the compilation machine is called a кросс-компилятор and is commonly used to prepare code for embedded applications.[нужна цитата ][требуется разъяснение ]
- A program that rewrites object code back into the same type of object code while applying optimisations and transformations is a двоичный рекомпилятор.
Смотрите также
Рекомендации
- ^ PC Mag Staff (28 February 2019). "Encyclopedia: Definition of Compiler". PCMag.com. Получено 28 февраля 2017.
- ^ а б Compilers: Principles, Techniques, and Tools by Alfred V. Aho, Ravi Sethi, Jeffrey D. Ullman - Second Edition, 2007
- ^ Sun, Chengnian; Le, Vu; Zhang, Qirun; Su, Zhendong (2016). "Toward Understanding Compiler Bugs in GCC and LLVM". ACM.
- ^ lecture notesCompilers: Principles, Techniques, and ToolsJing-Shin ChangDepartment of Computer Science & Information EngineeringNational Chi-Nan University
- ^ Naur, P. et al. "Report on ALGOL 60". Коммуникации ACM 3 (May 1960), 299–314.
- ^ Хомский, Ноам; Lightfoot, David W. (2002). Синтаксические структуры. Вальтер де Грюйтер. ISBN 978-3-11-017279-9.
- ^ Gries, David (2012). "Appendix 1: Backus-Naur Form". Наука программирования. Springer Science & Business Media. п. 304. ISBN 978-1461259831.
- ^ Iverson, Kenneth E. (1962). Язык программирования. Джон Вили и сыновья. ISBN 978-0-471430-14-8.
- ^ Backus, John. "The history of FORTRAN I, II and III" (PDF). История языков программирования. Softwarepreservation.org.
- ^ Porter Adams, Vicki (5 October 1981). "Captain Grace M. Hopper: the Mother of COBOL". InfoWorld. 3 (20): 33. ISSN 0199-6649.
- ^ McCarthy, J .; Brayton, R.; Edwards, D.; Fox, P.; Hodes, L.; Luckham, D.; Maling, K.; Парк, Д .; Russell, S. (March 1960). "LISP I Programmers Manual" (PDF). Boston, Massachusetts: Artificial Intelligence Group, M.I.T. Computation Center and Research Laboratory.
- ^ Compilers Principles, Techniques, & Tools 2nd edition by Aho, Lam, Sethi, Ullman ISBN 0-321-48681-1
- ^ Hopper, Grace Murray (1952). "The Education of a Computer". Proceedings of the 1952 ACM National Meeting (Pittsburgh): 243–249. Дои:10.1145/609784.609818. S2CID 10081016.
- ^ Ridgway, Richard K. (1952). "Compiling routines". Proceedings of the 1952 ACM National Meeting (Toronto): 1–5. Дои:10.1145/800259.808980. S2CID 14878552.
- ^ "Recursive Functions of Symbolic Expressions and Their Computation by Machine ", Communications of the ACM, April 1960
- ^ McCarthy, John; Abrahams, Paul W.; Edwards, Daniel J.; Hart, Timothy P.; Levin, Michael I. (1965). Lisp 1.5 Programmers Manual. MIT Press. ISBN 9780262130110.
- ^ "BCPL: A tool for compiler writing and system programming " M. Richards, University Mathematical Laboratory Cambridge, England 1969
- ^ BCPL: The Language and Its Compiler, M Richards, Cambridge University Press (first published 31 December 1981)
- ^ The BCPL Cintsys and Cintpos User Guide, M. Richards, 2017
- ^ Corbató, F. J.; Vyssotsky, V. A. "Introduction and Overview of the MULTICS System". 1965 Fall Joint Computer Conference. Multicians.org.
- ^ Report II of the SHARE Advanced Language Development Committee, 25 June 1964
- ^ Multicians.org "The Choice of PL/I" article, Editor /tom Van Vleck
- ^ "PL/I As a Tool for System Programming", F.J. Corbato, Datamation 6 May 1969 issue
- ^ "The Multics PL/1 Compiler ", R. A. Freiburghouse, GE, Fall Joint Computer Conference 1969
- ^ Датамация column, 1969
- ^ Dennis M. Ritchie, "Развитие языка C ", ACM Second History of Programming Languages Conference, April 1993
- ^ S.C. Johnson, "a Portable C Compiler: Theory and Practice", 5th ACM POPL Symposium, January 1978
- ^ A. Snyder, A Portable Compiler for the Language C, MIT, 1974.
- ^ K. Nygarard, University of Oslo, Norway, "Basic Concepts in Object Oriented Programming ", SIGPLAN Notices V21, 1986
- ^ B. Stroustrup: "What is Object-Oriented Programming?" Proceedings 14th ASU Conference, 1986.
- ^ Bjarne Stroustrup, "An Overview of the C++ Programming Language", Handbook of Object Technology (Editor: Saba Zamir, ISBN 0-8493-3135-8)
- ^ Leverett, Cattell, Hobbs, Newcomer, Reiner, Schatz, Wulf: "An Overview of the Production Quality Compiler-Compiler Project", CMU-CS-89-105, 1979
- ^ W. Wulf, K. Nori, "Delayed binding in PQCC generated compilers ", CMU Research Showcase Report, CMU-CS-82-138, 1982
- ^ Joseph M. Newcomer, David Alex Lamb, Bruce W. Leverett, Michael Tighe, William A. Wulf - Carnegie-Mellon University and David Levine, Andrew H. Reinerit - Intermetrics: "TCOL Ada: Revised Report on An Intermediate Representation for the DOD Standard Programming Language", 1979
- ^ William A. Whitaker, "Ada - the project: the DoD High Order Working Group", ACM SIGPLAN Notices (Volume 28, No. 3, March 1991)
- ^ CECOM Center for Software Engineering Advanced Software Technology, "Final Report - Evaluation of the ACEC Benchmark Suite for Real-Time Applications", AD-A231 968, 1990
- ^ P.Biggar, E. de Vries, D. Gregg, "A Practical Solution for Scripting Language Compilers", submission to Science of Computer Programming, 2009
- ^ M.Hall, D. Padua, K. Pingali, "Compiler Research: The Next 50 Years", ACM Communications 2009 Vol 54 #2
- ^ Cooper and Torczon 2012, p. 8
- ^ Lattner, Chris (2017). "LLVM". In Brown, Amy; Wilson, Greg (eds.). The Architecture of Open Source Applications. В архиве из оригинала 2 декабря 2016 г.. Получено 28 февраля 2017.
- ^ Aho, Lam, Sethi, Ullman 2007, p. 5-6, 109-189
- ^ Aho, Lam, Sethi, Ullman 2007, p. 111
- ^ Aho, Lam, Sethi, Ullman 2007, p. 8, 191-300
- ^ а б Blindell, Gabriel Hjort (3 June 2016). Instruction selection : principles, methods, and applications. Швейцария. ISBN 9783319340197. OCLC 951745657.
- ^ Cooper and Toczon (2012), p. 540
- ^ Aycock, John (2003). "A Brief History of Just-in-Time". ACM Comput. Surv. 35 (2, June): 93–113. Дои:10.1145/857076.857077. S2CID 15345671.[неосновной источник необходим ]
- ^ Swartz, Jordan S.; Betz, Vaugh; Rose, Jonathan (22–25 February 1998). "A Fast Routability-Driven Router for FPGAs" (PDF). FPGA '98 Proceedings of the 1998 ACM/SIGDA Sixth International Symposium on Field Programmable Gate Arrays. Monterey, CA: ACM: 140–149. Дои:10.1145/275107.275134. ISBN 978-0897919784. S2CID 7128364. В архиве (PDF) из оригинала от 9 августа 2017 года.
- ^ Xilinx Staff (2009). "XST Synthesis Overview". Xilinx, Inc. В архиве из оригинала 2 ноября 2016 г.. Получено 28 февраля 2017.[неосновной источник необходим ]
- ^ Altera Staff (2017). "Spectra-Q™ Engine". Altera.com. Архивировано из оригинал 10 октября 2016 г.. Получено 28 февраля 2017.[неосновной источник необходим ]
- ^ "Language Translator Tutorial" (PDF). Вашингтонский университет.
дальнейшее чтение
- Ахо, Альфред В.; Сетхи, Рави; Ульман, Джеффри Д. (1986). Compilers: Principles, Techniques, and Tools (1-е изд.). Эддисон-Уэсли. ISBN 9780201100884.
- Allen, Frances E. (Сентябрь 1981 г.). "A History of Language Processor Technology in IBM". Журнал исследований и разработок IBM. IBM. 25 (5): 535–548. Дои:10.1147/rd.255.0535.
- Allen, Randy; Kennedy, Ken (2001). Optimizing Compilers for Modern Architectures. Издательство Morgan Kaufmann. ISBN 978-1-55860-286-1.
- Appel, Andrew Wilson (2002). Modern Compiler Implementation in Java (2-е изд.). Издательство Кембриджского университета. ISBN 978-0-521-82060-8.
- Appel, Andrew Wilson (1998). Современная реализация компилятора в ML. Издательство Кембриджского университета. ISBN 978-0-521-58274-2.
- Bornat, Richard (1979). Understanding and Writing Compilers: A Do It Yourself Guide (PDF). Macmillan Publishing. ISBN 978-0-333-21732-0.
- Calingaert, Peter (1979). Horowitz, Ellis (ред.). Assemblers, Compilers, and Program Translation. Computer software engineering series (1st printing, 1st ed.). Potomac, Maryland: Computer Science Press, Inc. ISBN 0-914894-23-4. ISSN 0888-2088. LCCN 78-21905. Получено 20 марта 2020. (2+xiv+270+6 pages)
- Cooper, Keith Daniel; Torczon, Linda (2012). Engineering a compiler (2-е изд.). Амстердам: Эльзевир / Морган Кауфманн. п. 8. ISBN 9780120884780. OCLC 714113472.
- McKeeman, William Marshall; Хорнинг, Джеймс Дж.; Уортман, Дэвид Б. (1970). Генератор компилятора. Энглвуд Клиффс, Нью-Джерси: Prentice-Hall. ISBN 978-0-13-155077-3.
- Muchnick, Steven (1997). Расширенный дизайн и реализация компилятора. Издательство Morgan Kaufmann. ISBN 978-1-55860-320-2.
- Scott, Michael Lee (2005). Programming Language Pragmatics (2-е изд.). Морган Кауфманн. ISBN 978-0-12-633951-2.
- Srikant, Y. N.; Shankar, Priti (2003). The Compiler Design Handbook: Optimizations and Machine Code Generation. CRC Press. ISBN 978-0-8493-1240-3.
- Terry, Patrick D. (1997). Compilers and Compiler Generators: An Introduction with C++. International Thomson Computer Press. ISBN 978-1-85032-298-6.
- Вирт, Никлаус (1996). Конструкция компилятора (PDF). Эддисон-Уэсли. ISBN 978-0-201-40353-4. Архивировано из оригинал (PDF) 17 февраля 2017 г.. Получено 24 апреля 2012.
- LLVM community. "The LLVM Target-Independent Code Generator". LLVM Documentation. Получено 17 июн 2016.
- Compiler textbook references A collection of references to mainstream Compiler Construction Textbooks
внешняя ссылка
- Компиляторы в Керли
- Incremental Approach to Compiler Construction – a PDF tutorial
- Compile-Howto
- Basics of Compiler Design на Wayback Machine (archived 15 May 2018)
- Short animation на YouTube explaining the key conceptual difference between compilers and interpreters
- Syntax Analysis & LL1 Parsing на YouTube
- Let's Build a Compiler, by Jack Crenshaw
- Forum about compiler development на Wayback Machine (archived 10 October 2014)