Алгоритм ОПТИКА - Википедия - OPTICS algorithm
| Часть серии по |
| Машинное обучение и сбор данных |
|---|
Площадки для машинного обучения |
Точки упорядочивания для определения структуры кластеризации (ОПТИКА) - алгоритм поиска на основе плотности[1] кластеры в пространственных данных. Его представили Михаэль Анкерст, Маркус М. Бройниг, Ханс-Петер Кригель и Йорг Сандер.[2]Его основная идея похожа на DBSCAN,[3] но он устраняет одну из основных слабостей DBSCAN: проблему обнаружения значимых кластеров в данных различной плотности. Для этого точки в базе данных упорядочиваются (линейно) так, что пространственно ближайшие точки становятся соседями в упорядочении. Кроме того, для каждой точки сохраняется особое расстояние, которое представляет плотность, которая должна быть принята для кластера, чтобы обе точки принадлежали одному кластеру. Это представлено как дендрограмма.
Основная идея
Нравиться DBSCAN, OPTICS требует двух параметров: ε, который описывает максимальное расстояние (радиус) для рассмотрения, и МинПц, описывающий количество точек, необходимых для формирования кластера. Точка п это основная точка если хотя бы МинПц точки находятся в его ε-район (включая точку п сам). В отличие от DBSCAN, OPTICS также учитывает точки, которые являются частью более плотно упакованного кластера, поэтому каждой точке присваивается базовое расстояние который описывает расстояние до МинПцближайшая точка:


В достижимость-расстояние другой точки о с точки п это либо расстояние между о и п, или основное расстояние п, в зависимости от того, что больше:

Если п и о ближайшие соседи, это мы должны предположить, чтобы иметь п и о принадлежат к одному кластеру.

Как core-distance, так и reachability-distance не определены, если нет достаточно плотного кластера (w.r.t. ε) доступен. При достаточно большом ε, этого никогда не происходит, но затем каждый εзапрос -neighborhood возвращает всю базу данных, в результате чего время выполнения. Следовательно ε Параметр необходим для отсечения плотности кластеров, которые больше не интересны, и для ускорения работы алгоритма.

Параметр ε это, строго говоря, не обязательно. Его можно просто установить на максимально возможное значение. Однако когда пространственный индекс доступен, он действительно играет практическую роль в отношении сложности. OPTICS абстрагируется от DBSCAN, удаляя этот параметр, по крайней мере, в той степени, в которой необходимо указать только максимальное значение.
Псевдокод
Базовый подход ОПТИКИ аналогичен DBSCAN, но вместо того, чтобы поддерживать набор известных, но пока необработанных членов кластера, приоритетная очередь (например, используя индексированный куча ) используется.
функция ОПТИКА (DB, eps, MinPts) является для каждого точка p БД делать p.reachability-distance = НЕОПРЕДЕЛЕННО для каждого необработанная точка p БД делать N = getNeighbors (p, eps) помечает p как обработанный вывод p в упорядоченный список если core-distance (p, eps, MinPts)! = НЕ ОПРЕДЕЛЕН тогда Seeds = пустое обновление очереди приоритетов (N, p, Seeds, eps, MinPts) для каждого следующий q в семенах делать N '= getNeighbors (q, eps) помечает q как обработанный вывод q в упорядоченный список если core-distance (q, eps, MinPts)! = НЕ ОПРЕДЕЛЕН делать update (N ', q, Seeds, eps, MinPts)
В update () приоритетная очередь Seeds обновляется -окрестности и , соответственно:



функция обновить (N, p, Seeds, eps, MinPts) является coredist = core-distance (p, eps, MinPts) для каждого o в N если o не обрабатывается тогда новый-охват-расстояние = макс (составитель, расстояние (p, o)) если o.reachability-distance == НЕОПРЕДЕЛЕННО тогда // o отсутствует в семенах o.reachability-distance = new-range-dist Seeds.insert (o, new-range-dist) еще // o в Seeds, проверка на улучшение если новое-расстояние-досягаемостьтогда o.reachability-distance = new -reach-dist Seeds.move-up (o, new-range-dist)
Таким образом, OPTICS выводит точки в определенном порядке, помеченные наименьшим расстоянием достижимости (в исходном алгоритме базовое расстояние также экспортируется, но это не требуется для дальнейшей обработки).
Извлечение кластеров
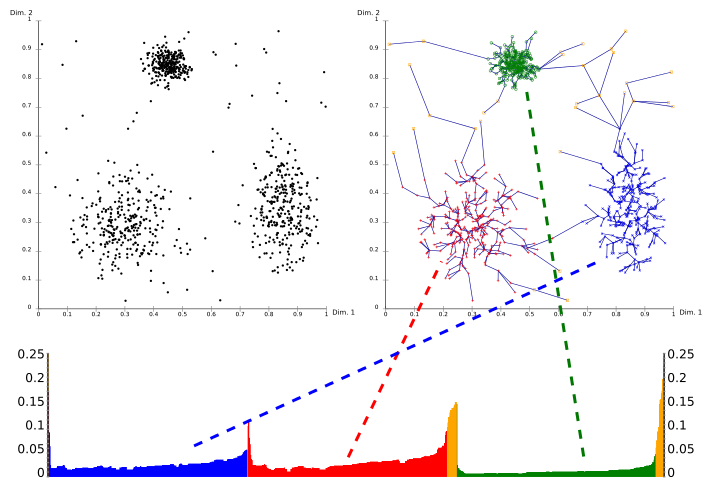
Используя график достижимости (особый вид дендрограмма ) иерархическая структура кластеров может быть получена легко. Это двухмерный график с упорядочением точек, обработанным OPTICS, по оси x и расстоянием достижимости по оси y. Поскольку точки, принадлежащие кластеру, имеют малое расстояние доступности до ближайшего соседа, кластеры отображаются в виде впадин на графике достижимости. Чем глубже долина, тем плотнее скопление.
Изображение выше иллюстрирует эту концепцию. В его верхней левой области показан набор данных синтетического примера. Верхняя правая часть визуализирует остовное дерево производится OPTICS, а в нижней части показан график достижимости, рассчитанный OPTICS. Цвета на этом графике являются метками и не вычисляются алгоритмом; но хорошо видно, как впадины на графике соответствуют кластерам в приведенном выше наборе данных. Желтые точки на этом изображении считаются шумом, и на графике их достижимости нет впадины. Обычно они не назначаются кластерам, за исключением вездесущего кластера «все данные» в иерархическом результате.
Извлечение кластеров из этого графика можно выполнить вручную, выбрав диапазон на оси x после визуального осмотра, выбрав порог на оси y (тогда результат аналогичен результату кластеризации DBSCAN с тем же и параметры minPts; здесь значение 0,1 может дать хорошие результаты), или с помощью различных алгоритмов, которые пытаются обнаружить впадины по крутизне, обнаружению перегиба или локальным максимумам. Полученные таким образом кластеры обычно иерархический, и не может быть достигнуто одним запуском DBSCAN.
Сложность
Нравиться DBSCAN, OPTICS обрабатывает каждую точку один раз и выполняет одну -соседний запрос во время этой обработки. Учитывая пространственный индекс который предоставляет запрос соседства в время выполнения, общее время выполнения получается. Авторы оригинальной статьи по OPTICS сообщают о фактическом постоянном коэффициенте замедления 1,6 по сравнению с DBSCAN. Обратите внимание, что значение может сильно повлиять на стоимость алгоритма, поскольку слишком большое значение может повысить стоимость запроса соседства до линейной сложности.


В частности, выбирая (большее, чем максимальное расстояние в наборе данных) возможно, но приводит к квадратичной сложности, поскольку каждый запрос соседства возвращает полный набор данных. Даже если пространственный индекс недоступен, это требует дополнительных затрат на управление кучей. Следовательно, следует выбирать в соответствии с набором данных.

Расширения
ОПТИКА-ОФ[4] является обнаружение выбросов алгоритм на базе ОПТИКИ. Основное применение - извлечение выбросов из существующей серии OPTICS с меньшими затратами по сравнению с использованием другого метода обнаружения выбросов. Наиболее известная версия LOF основан на тех же концепциях.
ДеЛи-Клу,[5] Density-Link-Clustering объединяет идеи из одинарная кластеризация и ОПТИКА, устраняя параметр и предлагает улучшения производительности по сравнению с OPTICS.
HiSC[6] это иерархический кластеризация подпространств (осево-параллельный) метод на основе ОПТИКИ.
HiCO[7] это иерархический корреляционная кластеризация алгоритм на базе ОПТИКИ.
Блюдо[8] - это усовершенствование HiSC, позволяющее находить более сложные иерархии.
ФОПТИКА[9] - более быстрая реализация с использованием случайных проекций.
HDBSCAN *[10] основан на уточнении DBSCAN, исключении пограничных точек из кластеров и, таким образом, более строгом следовании основному определению уровней плотности Хартигана.[11]
Доступность
Java-реализации OPTICS, OPTICS-OF, DeLi-Clu, HiSC, HiCO и DiSH доступны в Платформа интеллектуального анализа данных ELKI (с индексным ускорением для нескольких функций расстояния и с автоматическим извлечением кластеров с использованием метода извлечения ξ). Другие реализации Java включают Weka extension (без поддержки извлечения кластеров ξ).
В р пакет "dbscan" включает реализацию OPTICS C ++ (с традиционным dbscan-подобным извлечением и извлечением ξ кластера) с использованием k-d дерево только для ускорения индекса для евклидова расстояния.
Реализации OPTICS на Python доступны в PyClustering библиотека и в scikit-learn. HDBSCAN * доступен в hdbscan библиотека.
Рекомендации
- ^ Кригель, Ханс-Петер; Крегер, Пер; Сандер, Йорг; Зимек, Артур (май 2011 г.). «Кластеризация на основе плотности». Междисциплинарные обзоры Wiley: интеллектуальный анализ данных и открытие знаний. 1 (3): 231–240. Дои:10.1002 / widm.30.
- ^ Михаэль Анкерст; Маркус М. Бройниг; Ханс-Петер Кригель; Йорг Сандер (1999). ОПТИКА: Точки упорядочивания для определения структуры кластеризации. ACM SIGMOD международная конференция по управлению данными. ACM Press. С. 49–60. CiteSeerX 10.1.1.129.6542.
- ^ Мартин Эстер; Ханс-Петер Кригель; Йорг Сандер; Сяовэй Сюй (1996). Эвангелос Симудис; Цзявэй Хан; Усама М. Файяд (ред.). Алгоритм на основе плотности для обнаружения кластеров в больших пространственных базах данных с шумом. Труды Второй Международной конференции по открытию знаний и интеллектуальному анализу данных (KDD-96). AAAI Press. С. 226–231. CiteSeerX 10.1.1.71.1980. ISBN 1-57735-004-9.
- ^ Маркус М. Бройниг; Ханс-Петер Кригель; Раймонд Т. Нг; Йорг Сандер (1999). «ОПТИКА-ОФ: Выявление локальных выбросов». Принципы интеллектуального анализа данных и обнаружения знаний. Конспект лекций по информатике. 1704. Springer-Verlag. С. 262–270. Дои:10.1007 / b72280. ISBN 978-3-540-66490-1.
- ^ Achtert, E .; Böhm, C .; Крегер, П. (2006). DeLi-Clu: повышение надежности, полноты, удобства использования и эффективности иерархической кластеризации с помощью ранжирования ближайших пар. LNCS: достижения в области обнаружения знаний и интеллектуального анализа данных. Конспект лекций по информатике. 3918. С. 119–128. Дои:10.1007/11731139_16. ISBN 978-3-540-33206-0.
- ^ Achtert, E .; Böhm, C .; Кригель, Х.; Kröger, P .; Мюллер-Горман, I .; Зимек, А. (2006). Поиск иерархий кластеров подпространств. LNCS: обнаружение знаний в базах данных: PKDD 2006. Конспект лекций по информатике. 4213. С. 446–453. CiteSeerX 10.1.1.705.2956. Дои:10.1007/11871637_42. ISBN 978-3-540-45374-1.
- ^ Achtert, E .; Böhm, C .; Kröger, P .; Зимек, А. (2006). Иерархии корреляционных кластеров. Proc. 18-я Международная конференция по управлению научными и статистическими базами данных (SSDBM). С. 119–128. CiteSeerX 10.1.1.707.7872. Дои:10.1109 / SSDBM.2006.35. ISBN 978-0-7695-2590-7.
- ^ Achtert, E .; Böhm, C .; Кригель, Х.; Kröger, P .; Мюллер-Горман, I .; Зимек, А. (2007). Обнаружение и визуализация иерархий подпространственных кластеров. LNCS: достижения в базах данных: концепции, системы и приложения. Конспект лекций по информатике. 4443. С. 152–163. CiteSeerX 10.1.1.70.7843. Дои:10.1007/978-3-540-71703-4_15. ISBN 978-3-540-71702-7.
- ^ Шнайдер, Йоханнес; Влахос, Михаил (2013). «Быстрая кластеризация без параметров на основе плотности с помощью случайных проекций». 22-я Международная конференция ACM по управлению информацией и знаниями (CIKM).
- ^ Кампелло, Рикардо Дж. Г. Б .; Мулави, Давуд; Зимек, Артур; Сандер, Йорг (22 июля 2015 г.). «Иерархические оценки плотности для кластеризации данных, визуализации и обнаружения выбросов». Транзакции ACM при обнаружении знаний из данных. 10 (1): 1–51. Дои:10.1145/2733381.
- ^ J.A. Хартиган (1975). Алгоритмы кластеризации. Джон Вили и сыновья.