Переоснащение - Overfitting
эта статья нужны дополнительные цитаты для проверка. (Август 2017 г.) (Узнайте, как и когда удалить этот шаблон сообщения) |


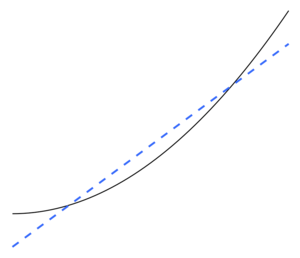
В статистике переоснащение это «производство анализа, который слишком близко или точно соответствует определенному набору данных и поэтому может не соответствовать дополнительным данным или надежно предсказывать будущие наблюдения».[1] An переоборудованная модель это статистическая модель который содержит больше параметры чем могут быть обоснованы данные.[2] Суть переобучения заключается в том, чтобы по незнанию извлечь часть остаточной вариации (т. Е. шум ), как если бы этот вариант представлял основную структуру модели.[3]:45
Другими словами, модель запоминает огромное количество примеров вместо того, чтобы учиться замечать особенности.
Недостаточное оснащение возникает, когда статистическая модель не может адекватно отразить основную структуру данных. An недостаточно подогнанная модель - это модель, в которой отсутствуют некоторые параметры или термины, которые могли бы появиться в правильно заданной модели.[2] Недостаточная подгонка может возникнуть, например, при подгонке линейной модели к нелинейным данным. Такая модель будет иметь плохие прогнозные характеристики.
Переоснащение и недооборудование может произойти в машинное обучение, особенно. В машинном обучении это явление иногда называют «перетренировкой» и «недостаточной тренировкой».
Возможность переобучения существует, потому что критерий, используемый для выбор модели не то же самое, что критерий, используемый для оценки пригодности модели. Например, модель может быть выбрана путем максимизации ее производительности на некотором наборе данные обучения, и все же его пригодность может быть определена его способностью хорошо работать с невидимыми данными; затем чрезмерная подгонка происходит, когда модель начинает «запоминать» обучающие данные, а не «учиться» делать выводы на основе тенденции.
В качестве крайнего примера, если количество параметров такое же или больше, чем количество наблюдений, то модель может идеально предсказать обучающие данные, просто запоминая данные целиком. (Для иллюстрации см. Рисунок 2.) Однако такая модель обычно терпит неудачу при прогнозировании.
Возможность переобучения зависит не только от количества параметров и данных, но также от соответствия структуры модели форме данных и величины ошибки модели по сравнению с ожидаемым уровнем шума или ошибки в данных.[нужна цитата ] Даже когда подобранная модель не имеет чрезмерного количества параметров, следует ожидать, что подобранная взаимосвязь будет работать хуже с новым набором данных, чем с набором данных, используемым для подгонки (явление, иногда известное как усадка).[2] В частности, ценность коэффициент детерминации буду сокращаться относительно исходных данных.
Чтобы уменьшить вероятность или количество переобучения, доступны несколько методов (например, сравнение моделей, перекрестная проверка, регуляризация, ранняя остановка, обрезка, Байесовские априоры, или выбывать ). В основе некоторых методов лежит либо (1) явное наказание слишком сложных моделей, либо (2) проверка способности модели к обобщению путем оценки ее производительности на наборе данных, не используемых для обучения, что, как предполагается, приближает типичные невидимые данные. что модель встретит.
Статистические выводы
Эта секция нуждается в расширении. Вы можете помочь добавляя к этому. (Октябрь 2017 г.) |
В статистике вывод взят из статистическая модель, который был выбранный через некоторую процедуру. Burnham & Anderson в своем часто цитируемом тексте о выборе модели утверждают, что во избежание переобучения мы должны придерживаться принципа "Принцип экономии ".[3] Авторы также заявляют следующее.[3]:32–33
Переоборудованные модели… часто не содержат систематических ошибок в оценках параметров, но имеют оценочные (и фактические) отклонения выборки, которые излишне велики (точность оценок низка по сравнению с тем, что можно было бы достичь с помощью более экономной модели). Как правило, выявляются ложные эффекты лечения, и ложные переменные включаются в переоборудованные модели. … Модель наилучшего приближения достигается за счет правильного баланса ошибок недостаточного и переобучения.
Переобучение с большей вероятностью станет серьезной проблемой, когда имеется мало теории для проведения анализа, отчасти потому, что тогда существует тенденция к большому количеству моделей для выбора. Книга Выбор модели и усреднение модели (2008) говорит об этом так.[4]
Имея набор данных, вы можете уместить тысячи моделей одним нажатием кнопки, но как выбрать лучшую? При таком большом количестве моделей кандидатов переоснащение представляет собой реальную опасность. Действительно ли обезьяна, напечатавшая «Гамлета», хороший писатель?
Регресс
В регрессивный анализ, переобучение происходит часто.[5] В качестве крайнего примера, если есть п переменные в линейная регрессия с п точки данных, подобранная линия может проходить точно через каждую точку.[6] За логистическая регрессия или Кокс модели пропорциональных опасностей, существует множество практических правил (например, 5–9[7], 10[8] и 10–15[9] - норма из 10 наблюдений на независимую переменную известна как "правило один из десяти "). В процессе выбора регрессионной модели среднеквадратичная ошибка функции случайной регрессии может быть разделена на случайный шум, смещение аппроксимации и дисперсию в оценке функции регрессии. компромисс между смещением и дисперсией часто используется для преодоления переобучения моделей.
С большим набором объясняющие переменные которые на самом деле не имеют отношения к зависимая переменная Будучи предсказанным, некоторые переменные, как правило, будут ошибочно признаны статистически значимый и исследователь может, таким образом, сохранить их в модели, тем самым переоснастив модель. Это известно как Парадокс Фридмана.
Машинное обучение
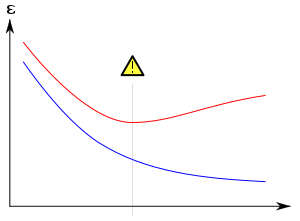
Обычно обучение алгоритм обучается с использованием некоторого набора «обучающих данных»: примерных ситуаций, для которых известен желаемый результат. Цель состоит в том, чтобы алгоритм также хорошо работал при прогнозировании выходных данных при подаче «проверочных данных», которые не были обнаружены во время его обучения.
Переобучение - это использование моделей или процедур, нарушающих бритва Оккама, например, путем включения большего количества настраиваемых параметров, чем в конечном итоге является оптимальным, или путем использования более сложного подхода, чем в конечном итоге оптимального. В качестве примера, когда есть слишком много настраиваемых параметров, рассмотрим набор данных, в котором данные обучения для у может быть адекватно предсказана линейной функцией двух независимых переменных. Для такой функции требуется всего три параметра (точка пересечения и два угла наклона). Замена этой простой функции новой, более сложной квадратичной функцией или новой, более сложной линейной функцией от более чем двух независимых переменных несет в себе риск: бритва Оккама подразумевает, что любая данная сложная функция априори менее вероятен, чем любая заданная простая функция. Если вместо простой функции выбрана новая, более сложная функция, и если не было достаточно большого прироста в обучающих данных, подходящих для компенсации увеличения сложности, то новая сложная функция «переоборудует» данные, а сложная переобучена. Функция, вероятно, будет работать хуже, чем более простая функция на данных проверки за пределами набора обучающих данных, даже если сложная функция также или, возможно, даже лучше выполняется на наборе обучающих данных.[10]
При сравнении различных типов моделей сложность не может быть измерена только путем подсчета количества параметров, существующих в каждой модели; необходимо также учитывать выразительность каждого параметра. Например, нетривиально напрямую сравнить сложность нейронной сети (которая может отслеживать криволинейные отношения) с м параметры в регрессионную модель с п параметры.[10]
Переоснащение особенно вероятно в тех случаях, когда обучение выполнялось слишком долго или когда обучающие примеры редки, что заставляет обучаемого приспосабливаться к очень специфическим случайным характеристикам обучающих данных, которые причинная связь к целевая функция. В этом процессе переобучения производительность на обучающих примерах все еще увеличивается, в то время как производительность на невидимых данных становится хуже.
В качестве простого примера рассмотрим базу данных розничных покупок, которая включает купленный товар, покупателя, а также дату и время покупки. Легко построить модель, которая идеально впишется в обучающий набор, используя дату и время покупки для прогнозирования других атрибутов, но эта модель вообще не будет обобщаться на новые данные, потому что эти прошлые времена никогда не повторится.
Обычно говорят, что алгоритм обучения переоснащен по сравнению с более простым, если он более точен при подборе известных данных (ретроспективный взгляд), но менее точен при прогнозировании новых данных (предвидение). Можно интуитивно понять переоснащение, исходя из того факта, что информацию из всего прошлого опыта можно разделить на две группы: информацию, имеющую отношение к будущему, и информацию, не имеющую отношения к делу («шум»). При прочих равных условиях, чем труднее прогнозировать критерий (т.е. чем выше его неопределенность), тем больше шума существует в прошлой информации, которую необходимо игнорировать. Проблема в том, чтобы определить, какую часть игнорировать. Алгоритм обучения, который может снизить вероятность подгонки шума, называется "крепкий."
Последствия
Наиболее очевидным последствием переобучения является низкая производительность набора данных проверки. К другим негативным последствиям можно отнести:[10]
- Функция, которая переоборудована, вероятно, запросит больше информации о каждом элементе в наборе данных проверки, чем оптимальная функция; сбор этих дополнительных ненужных данных может быть дорогостоящим или чреватым ошибками, особенно если каждый отдельный фрагмент информации должен быть собран путем наблюдения человека и ручного ввода данных.
- Более сложная, переоборудованная функция, вероятно, будет менее переносимой, чем простая. С одной стороны, линейная регрессия с одной переменной настолько переносима, что при необходимости ее можно было бы даже выполнить вручную. Другая крайность - модели, которые могут быть воспроизведены только путем точного копирования всей установки оригинального моделиста, что затрудняет повторное использование или научное воспроизведение.
Средство правовой защиты
Оптимальная функция обычно требует проверки на больших или совершенно новых наборах данных. Однако есть такие методы, как минимальное остовное дерево или время жизни корреляции который применяет зависимость между коэффициентами корреляции и временными рядами (шириной окна). Когда ширина окна достаточно велика, коэффициенты корреляции стабильны и больше не зависят от размера окна. Следовательно, корреляционная матрица может быть создана путем вычисления коэффициента корреляции между исследуемыми переменными. Эта матрица может быть представлена топологически как сложная сеть, в которой визуализируются прямые и косвенные влияния между переменными.
Недостаточное оснащение
Недостаточное соответствие происходит, когда статистическая модель или алгоритм машинного обучения не может адекватно уловить основную структуру данных. Это происходит, когда модель или алгоритм недостаточно соответствуют данным. Недостаточное соответствие происходит, если модель или алгоритм демонстрируют низкую дисперсию, но высокую систематическую ошибку (в отличие от противоположного, переобучение из-за высокой дисперсии и низкой систематической ошибки). Часто это результат чрезмерно простой модели.[11] который не может обработать сложность проблемы (см. также ошибка приближения ). Это приводит к модели, которая не подходит для обработки всего сигнала и поэтому вынуждена принимать некоторый сигнал как шум. Если вместо этого модель способна обрабатывать сигнал, но в любом случае принимает его часть как шум, она также считается недостаточно приспособленной. Последний случай может произойти, если функция потерь модели включает штраф, который в данном конкретном случае слишком высок.
Бернхэм и Андерсон заявляют следующее.[3]:32
… Недостаточно приспособленная модель игнорирует некоторые важные воспроизводимые (т.е. концептуально воспроизводимые в большинстве других выборок) структуры данных и, таким образом, не может идентифицировать эффекты, которые фактически поддерживаются данными. В этом случае систематическая ошибка в оценках параметров часто бывает значительной, а дисперсия выборки недооценивается; оба фактора приводят к плохому охвату доверительного интервала. Недостаточно подогнанные модели часто упускают из виду важные эффекты лечения в экспериментальных условиях.
Смотрите также
- Компромисс смещения и дисперсии
- Подгонка кривой
- Дноуглубительные работы
- Выбор функции
- Парадокс Фридмана
- Ошибка обобщения
- Доброту соответствия
- Время жизни корреляции
- Выбор модели
- бритва Оккама
- Первичная модель
- Размер ВК - больший размер VC подразумевает больший риск переобучения
Примечания
- ^ Значение "переоснащение " в OxfordDictionaries.com: это определение специально для статистики.
- ^ а б c Эверитт Б.С., Скрондал А. (2010), Кембриджский статистический словарь, Издательство Кембриджского университета.
- ^ а б c d Burnham, K. P .; Андерсон, Д. Р. (2002), Выбор модели и многомодельный вывод (2-е изд.), Springer-Verlag.
- ^ Клаескенс, Г.; Hjort, N.L. (2008), Выбор модели и усреднение модели, Издательство Кембриджского университета.
- ^ Харрелл Ф. Э. младший (2001 г.), Стратегии регрессионного моделирования, Springer.
- ^ Марта К. Смит (13.06.2014). «Переоснащение». Техасский университет в Остине. Получено 2016-07-31.
- ^ Vittinghoff, E .; Маккалок, К. Э. (2007). «Ослабление правила десяти событий на переменную в логистической регрессии и регрессии Кокса». Американский журнал эпидемиологии. 165 (6): 710–718. Дои:10.1093 / aje / kwk052. PMID 17182981.
- ^ Draper, Norman R .; Смит, Гарри (1998). Прикладной регрессионный анализ (3-е изд.). Wiley. ISBN 978-0471170822.
- ^ Джим Фрост (03.09.2015). «Опасность переобучения регрессионных моделей». Получено 2016-07-31.
- ^ а б c Хокинс, Дуглас М (2004). «Проблема переоснащения». Журнал химической информации и моделирования. 44 (1): 1–12. Дои:10.1021 / ci0342472. PMID 14741005.
- ^ Кай, Эрик (2014-03-20). «Урок дня по машинному обучению - переоснащение и недостаточное оснащение». Статблоги. Архивировано из оригинал на 2016-12-29. Получено 2016-12-29.
использованная литература
- Лайнвебер, Д. Дж. (2007). «Глупые уловки майнера данных». Журнал инвестирования. 16: 15–22. Дои:10.3905 / joi.2007.681820. S2CID 108627390.
- Тетько, И. В .; Ливингстон, Д. Дж .; Луйк, А. И. (1995). «Исследования нейронных сетей. 1. Сравнение переобучения и перетренированности» (PDF). Журнал химической информации и моделирования. 35 (5): 826–833. Дои:10.1021 / ci00027a006.
- Совет 7: минимизируйте переобучение. Chicco, D. (декабрь 2017 г.). «Десять быстрых советов по машинному обучению в вычислительной биологии». BioData Mining. 10 (35): 35. Дои:10.1186 / s13040-017-0155-3. ЧВК 5721660. PMID 29234465.
дальнейшее чтение
- Кристиан, Брайан; Гриффитс, Том (апрель 2017 г.), «Глава 7: Переоснащение», Алгоритмы жизни: информатика человеческих решений, Уильям Коллинз, стр. 149–168, ISBN 978-0-00-754799-9