Происхождение данных - Википедия - Data lineage
Эта статья содержит формулировку, которая субъективно продвигает тему без передачи реальной информации. (Май 2015 г.) (Узнайте, как и когда удалить этот шаблон сообщения) |
Происхождение данных включает данные происхождение, что с ним происходит и куда он перемещается с течением времени.[1] Происхождение данных обеспечивает наглядность, значительно упрощая возможность отслеживания ошибок до первопричины в аналитика данных процесс.[2]
Это также позволяет воспроизводить определенные части или входы поток данных для пошагового отладка или восстановление потерянного вывода. Системы баз данных использовать такую информацию, называемую происхождение данных, чтобы решить аналогичные проблемы проверки и отладки.[3] Происхождение данных относится к записям о входах, объектах, системах и процессах, которые влияют на интересующие данные, обеспечивая историческую запись данных и их происхождения. Созданные свидетельства поддерживают такие криминалистические действия, как анализ зависимостей данных, обнаружение и восстановление ошибок / компрометации, аудит и анализ соответствия. "Происхождение это простой тип почему происхождение."[3]
Происхождение данных может быть представлен визуально обнаруживать поток / перемещение данных от источника к месту назначения через различные изменения и переходы на его пути в корпоративной среде, как данные преобразуются по пути, как меняются представление и параметры, и как данные разделяются или сходятся после каждого прыгать. Простое представление Data Lineage может быть показано точками и линиями, где точка представляет собой контейнер данных для точек данных, а линии, соединяющие их, представляют преобразования, которым точка данных претерпевает, между контейнерами данных.
Представление во многом зависит от объема управление метаданными и ориентир интереса. Линия данных предоставляет источники данных и промежуточные переходы потока данных из контрольной точки с обратная линия передачи данных, приводит к точкам данных конечного пункта назначения и его промежуточным потокам данных с прямая передача данных. Эти виды можно комбинировать с от конца до конца родословной для контрольной точки, которая обеспечивает полный контрольный журнал этой интересующей точки данных от источников до конечных пунктов назначения. По мере увеличения количества точек данных или скачков сложность такого представления становится непонятной. Таким образом, лучшей особенностью представления происхождения данных было бы возможность упростить представление путем временного маскирования нежелательных периферийных точек данных. Инструменты с функцией маскирования позволяют масштабируемость представления и улучшает анализ, обеспечивая лучший пользовательский опыт как для технических, так и для бизнес-пользователей. Линия данных также позволяет компаниям отслеживать источники конкретных бизнес-данных с целью отслеживания ошибок, внесения изменений в процессы и внедрения системные миграции чтобы сэкономить значительное количество времени и ресурсов, тем самым значительно улучшив БИ эффективность.[4]
Объем линии передачи данных определяет объем метаданных, необходимых для представления ее происхождения данных. Обычно, управление данными, и управление данными определяет объем линии передачи данных на основе их нормативно-правовые акты, стратегия управления корпоративными данными, влияние данных, атрибуты отчетности и критические элементы данных организации.
Линия данных обеспечивает контрольный журнал точек данных на самом высоком уровне детализации, но представление происхождения может быть выполнено с различными уровнями масштабирования, чтобы упростить обширную информацию, подобно аналитическим веб-картам. Происхождение данных можно визуализировать на различных уровнях в зависимости от детализации представления. На очень высоком уровне происхождение данных указывает, с какими системами данные взаимодействуют, прежде чем они достигнут пункта назначения. По мере увеличения степени детализации она поднимается до уровня точки данных, где может предоставить подробную информацию о точке данных и ее историческом поведении, свойствах атрибутов и тенденциях, а также Качество данных данных, прошедших через эту конкретную точку данных в линии передачи данных.
Управление данными играет ключевую роль в управлении метаданными для руководящих принципов, стратегий, политик, внедрения. Качество данных, и управление основными данными помогает обогатить линейку данных большей коммерческой ценностью. Несмотря на то, что окончательное представление происхождения данных обеспечивается в одном интерфейсе, но способ сбора метаданных и их предоставления графический интерфейс пользователя могло быть совсем иначе. Таким образом, происхождение данных можно в общих чертах разделить на три категории в зависимости от способа сбора метаданных: происхождение данных, включающее программные пакеты для структурированных данных, языки программирования, и большое количество данных.
Информация о происхождении данных включает технические метаданные, связанные с преобразованием данных. Обогащенная информация о происхождении данных может включать результаты проверки качества данных, значения справочных данных, модели данных, деловой словарь, распорядители данных, информация по управлению программой, и информационные системы предприятия связаны с точками данных и преобразованиями. Функция маскирования в визуализации происхождения данных позволяет инструментам включать все усовершенствования, которые имеют значение для конкретного варианта использования. Для представления разрозненных систем в одном общем виде может потребоваться «нормализация метаданных» или стандартизация.
Обоснование
Распределенные системы, такие как Google Уменьшение карты,[5] Microsoft Dryad,[6] Apache Hadoop[7] (проект с открытым исходным кодом) и Google Pregel[8] предоставлять такие платформы для предприятий и пользователей. Однако даже с этими системами большое количество данных Аналитика может занять несколько часов, дней или недель просто из-за большого объема данных. Например, алгоритм прогнозирования рейтингов для задачи Netflix Prize занял почти 20 часов для выполнения на 50 ядрах, а масштабная задача обработки изображений для оценки географической информации заняла 3 дня с использованием 400 ядер.[9] «Ожидается, что Большой синоптический обзорный телескоп будет генерировать терабайты данных каждую ночь и в конечном итоге хранить более 50 петабайт, в то время как в секторе биоинформатики 12 крупнейших в мире центров секвенирования генома теперь хранят петабайты данных каждый».[10]Специалисту по анализу данных очень сложно отследить неизвестный или непредвиденный результат.
Отладка больших данных
Большое количество данных Аналитика - это процесс изучения больших наборов данных для выявления скрытых закономерностей, неизвестных корреляций, рыночных тенденций, предпочтений клиентов и другой полезной бизнес-информации. Они применяются машинное обучение алгоритмы и т. д. к данным, которые преобразуют данные. Из-за огромного размера данных в них могут быть неизвестные особенности, возможно, даже выбросы. Специалисту по данным довольно сложно отладить неожиданный результат.
Масштабность и неструктурированность данных, сложность этих аналитических конвейеров и длительное время выполнения создают серьезные проблемы с управляемостью и отладкой. Даже одну ошибку в этой аналитике бывает чрезвычайно сложно выявить и устранить. Хотя их можно отладить, повторно запустив всю аналитику через отладчик для пошаговой отладки, это может быть дорогостоящим из-за необходимого количества времени и ресурсов. Аудит и проверка данных являются другими серьезными проблемами из-за растущей простоты доступа к соответствующим источникам данных для использования в экспериментах, обмена данными между научными сообществами и использования сторонних данных на коммерческих предприятиях.[11][12][13][14] Эти проблемы будут становиться все серьезнее и острее по мере того, как эти системы и данные будут продолжать расти. Таким образом, более экономичные способы анализа масштабируемые вычисления с интенсивным использованием данных (DISC) имеют решающее значение для их дальнейшего эффективного использования.
Проблемы при отладке больших данных
Массивный масштаб
Согласно исследованию EMC / IDC:[15]
- 2,8 ЗБ данных были созданы и воспроизведены в 2012 г.
- цифровая вселенная будет удваиваться каждые два года до 2020 года, и
- в 2020 году на каждого человека будет приходиться примерно 5,2 ТБ данных.
Работа с таким масштабом данных стала очень сложной задачей.
Неструктурированные данные
Неструктурированные данные обычно относится к информации, которой нет в традиционной базе данных строка-столбец. Файлы с неструктурированными данными часто содержат текст и мультимедийный контент. Примеры включают сообщения электронной почты, текстовые документы, видео, фотографии, аудиофайлы, презентации, веб-страницы и многие другие виды деловых документов. Обратите внимание, что, хотя файлы такого типа могут иметь внутреннюю структуру, они по-прежнему считаются «неструктурированными», поскольку содержащиеся в них данные не помещаются в базу данных. По оценкам экспертов, от 80 до 90 процентов данных в любой организации неструктурированы. И объем неструктурированных данных на предприятиях растет значительно, часто во много раз быстрее, чем растут структурированные базы данных. "Большое количество данных могут включать как структурированные, так и неструктурированные данные, но, по оценкам IDC, 90 процентов большое количество данных это неструктурированные данные ".[16]
Основная проблема источников неструктурированных данных заключается в том, что их трудно распаковать, понять и подготовить к аналитическому использованию как для нетехнических бизнес-пользователей, так и для аналитиков. Помимо вопросов структуры, существует огромный объем данных этого типа. Из-за этого современные методы интеллектуального анализа данных часто упускают ценную информацию и делают анализ неструктурированных данных трудоемким и дорогостоящим.[17]
Длительное время работы
В сегодняшней конкурентной деловой среде компании должны быстро находить и анализировать нужные данные. Задача состоит в том, чтобы обработать объемы данных и получить доступ к необходимому уровню детализации на высокой скорости. Проблема только возрастает по мере увеличения степени детализации. Одно из возможных решений - оборудование. Некоторые поставщики используют увеличенную память и параллельная обработка для быстрой обработки больших объемов данных. Другой метод - размещение данных в памяти но используя сеточные вычисления подход, при котором для решения проблемы используется много машин. Оба подхода позволяют организациям исследовать огромные объемы данных. Даже на этом уровне сложного аппаратного и программного обеспечения некоторые задачи обработки изображений в большом масштабе занимают от нескольких дней до нескольких недель.[18] Отладка обработки данных чрезвычайно сложна из-за длительного времени выполнения.
Третий подход передовых решений для обнаружения данных объединяет самостоятельная подготовка данных с визуальным обнаружением данных, позволяя аналитикам одновременно готовить и визуализировать данные бок о бок в интерактивной среде анализа, предлагаемой новыми компаниями Trifacta, Альтерикс и другие.[19]
Другой метод отслеживания происхождения данных - это программы для работы с электронными таблицами, такие как Excel, которые предлагают пользователям происхождение на уровне ячеек или возможность увидеть, какие ячейки зависят от других, но при этом теряется структура преобразования. По аналогии, ETL или картографическое программное обеспечение обеспечивает родословную на уровне преобразования, но это представление обычно не отображает данные и является слишком грубым, чтобы различать преобразования, которые являются логически независимыми (например, преобразования, которые работают с отдельными столбцами) или зависимыми.[20]
Комплексная платформа
Большое количество данных платформы имеют очень сложную структуру. Данные распределяются между несколькими машинами. Обычно задания отображаются на нескольких машинах, а результаты позже объединяются операциями сокращения. Отладка большое количество данных трубопровод становится очень сложным из-за самой природы системы. Специалисту по данным будет нелегко выяснить, какие данные машины имеют выбросы и неизвестные особенности, из-за которых конкретный алгоритм дает неожиданные результаты.
Предложенное решение
Происхождение данных или происхождение данных можно использовать для отладки большое количество данных трубопровод проще. Это требует сбора данных о преобразованиях данных. В следующем разделе более подробно объясняется происхождение данных.
Источник данных
Источник данных обеспечивает историческую запись данных и их происхождение. Источники данных, которые генерируются сложными преобразованиями, такими как рабочие процессы, имеют большое значение для ученых.[21] Из него можно определить качество данных на основе их предков и производных, отследить источники ошибок, разрешить автоматическое воспроизведение производных для обновления данных и предоставить атрибуцию источников данных. Происхождение также важно для бизнес-домена, где его можно использовать для детализации источника данных в хранилище данных, отслеживать создание интеллектуальной собственности и обеспечивать контрольный журнал для нормативных целей.
Использование источника данных предлагается в распределенных системах для отслеживания записей через поток данных, воспроизведения потока данных на подмножестве его исходных входных данных и отладки потоков данных. Для этого необходимо отслеживать набор входных данных для каждого оператора, которые использовались для получения каждого из его выходных данных. Хотя существует несколько форм происхождения, например, копирование и происхождение,[14][22] необходимая нам информация - это простая форма почему происхождение или происхождение, как определено Cui et al.[23]
Захват родословной
Интуитивно понятно, что для оператора T, производящего вывод o, происхождение состоит из триплетов формы {I, T, o}, где I - набор входных данных для T, используемых для получения o. Захват происхождения для каждого оператора T в потоке данных позволяет пользователям задавать такие вопросы, как «Какие выходные данные были получены при вводе i для оператора T?» и «Какие входы дали результат o в операторе T?»[3] Запрос, который находит входные данные, являющиеся производными для выходных данных, называется запросом обратной трассировки, в то время как тот, который находит выходные данные, созданные входными данными, называется запросом прямой трассировки.[24] Обратная трассировка полезна для отладки, а прямая трассировка полезна для отслеживания распространения ошибок.[24] Запросы трассировки также составляют основу для воспроизведения исходного потока данных.[12][23][24] Однако, чтобы эффективно использовать происхождение в системе DISC, нам необходимо иметь возможность фиксировать происхождение на нескольких уровнях (или гранулярностях) операторов и данных, фиксировать точное происхождение для структур обработки DISC и иметь возможность эффективно отслеживать несколько этапов потока данных.
Система DISC состоит из нескольких уровней операторов и данных, и различные варианты использования происхождения могут определять уровень, на котором необходимо фиксировать происхождение. Происхождение может быть зафиксировано на уровне задания, используя файлы и задавая кортежи родословной формы {IF i, M RJob, OF i}, родословную также можно зафиксировать на уровне каждой задачи, используя записи и давая, например, линейные кортежи формы {(k rr, v rr), map, (km, vm)}. Первая форма линии передачи называется крупнозернистой линией, а вторая форма - мелкозернистой линией. Интеграция происхождения с разной степенью детализации позволяет пользователям задавать такие вопросы, как «Какой файл, прочитанный заданием MapReduce, привел к этой конкретной выходной записи?» и может быть полезен при отладке различных операторов и гранулярностей данных в потоке данных.[3]

Чтобы зафиксировать сквозное происхождение в системе DISC, мы используем модель Ibis,[25] который вводит понятие иерархии включения для операторов и данных. В частности, Ibis предлагает, чтобы оператор мог содержаться в другом, и такая связь между двумя операторами называется сдерживание оператора. «Включение оператора подразумевает, что содержащийся (или дочерний) оператор выполняет часть логической операции содержащего (или родительского) оператора».[3] Например, задача MapReduce содержится в задании. Аналогичные отношения включения существуют и для данных, называемые включением данных. Включение данных подразумевает, что содержащиеся данные являются подмножеством содержащихся данных (надмножеством).

Предписательная линия передачи данных
Концепция чего-либо прескриптивная линия передачи данных сочетает в себе логическую модель (сущность) того, как эти данные должны течь, с фактическим происхождением для этого экземпляра.[26]
Происхождение и происхождение данных обычно относится к способу или этапам перехода набора данных к его текущему состоянию. Происхождение данных, а также ко всем копиям или производным. Однако простой анализ корреляций только аудита или журналов для определения происхождения с точки зрения криминалистики является ошибочным для определенных случаев управления данными. Например, без логической модели невозможно с уверенностью определить, был ли маршрут рабочего потока данных правильным или соответствующим.
Только путем объединения логической модели с атомарными криминалистическими событиями можно проверить правильность действий:
- Авторизованные копии, присоединения или операции CTAS
- Сопоставление обработки с системами, в которых эти процессы выполняются
- Ad-Hoc по сравнению с установленными последовательностями обработки
Многие сертифицированные отчеты о соответствии требуют происхождения потока данных, а также данных о конечном состоянии для конкретного экземпляра. В таких ситуациях любое отклонение от предписанного пути должно быть учтено и потенциально исправлено.[27] Это знаменует сдвиг в мышлении от чисто модели ретроспективного анализа к структуре, которая лучше подходит для отслеживания рабочих процессов соответствия.
Активная и ленивая родословная
Ленивая коллекция линий обычно захватывает только грубые линии во время выполнения. Эти системы несут низкие накладные расходы на захват из-за небольшого количества захваченных линий. Однако, чтобы ответить на запросы точной трассировки, они должны воспроизвести поток данных на всем (или на большей части) входных данных и собрать точную информацию о происхождении во время воспроизведения. Этот подход подходит для криминалистических систем, где пользователь хочет отладить наблюдаемый неверный результат.
Активные системы сбора данных фиксируют всю происхождение потока данных во время выполнения. Вид захваченной линии передачи может быть грубым или мелкозернистым, но они не требуют каких-либо дополнительных вычислений в потоке данных после его выполнения. Активные системы сбора мелкозернистых линий несут более высокие накладные расходы на сбор, чем системы ленивого сбора. Однако они позволяют выполнять сложные операции воспроизведения и отладки.[3]
Актеры
Актер - это объект, преобразующий данные; это может быть вершина Dryad, отдельные операторы map и reduce, задание MapReduce или весь конвейер потока данных. Актеры действуют как черные ящики, а входы и выходы актера используются для фиксации происхождения в форме ассоциаций, где ассоциация представляет собой тройку {i, T, o}, которая связывает вход i с выходом o для актера. Т. Таким образом, инструментарий фиксирует происхождение в потоке данных по одному актору за раз, собирая его в набор ассоциаций для каждого актора. Разработчику системы необходимо фиксировать данные, которые субъект читает (от других субъектов), и данные, которые субъект записывает (другим субъектам). Например, разработчик может рассматривать Hadoop Job Tracker как актера, записывая набор файлов, прочитанных и записанных каждым заданием.[28]
Ассоциации
Ассоциация - это комбинация входов, выходов и самой операции. Операция представлена в виде черного ящика, также известного как актер. Связи описывают преобразования, которые применяются к данным. Ассоциации хранятся в таблицах ассоциаций. Каждый уникальный актер представлен собственной таблицей ассоциаций. Сама ассоциация выглядит как {i, T, o}, где i - набор входных данных для актора T, а o - набор выходных данных, выдаваемых актором. Ассоциации являются основными единицами линии передачи данных. Позже отдельные ассоциации объединяются для построения всей истории преобразований, примененных к данным.[3]
Архитектура
Большое количество данных системы масштабируются по горизонтали, т. е. увеличивают пропускную способность за счет добавления нового оборудования или программного обеспечения в распределенную систему. Распределенная система действует как единое целое на логическом уровне, даже если она состоит из нескольких аппаратных и программных объектов. Система должна продолжать поддерживать это свойство после горизонтального масштабирования. Важным преимуществом горизонтальной масштабируемости является то, что она может обеспечить возможность увеличения емкости на лету. Самый большой плюс в том, что горизонтальное масштабирование может быть выполнено с использованием стандартного оборудования.
Функция горизонтального масштабирования Большое количество данных системы следует учитывать при создании архитектуры магазина lineage. Это важно, потому что хранилище родословной само по себе также должно иметь возможность масштабироваться параллельно с Большое количество данных система. Количество ассоциаций и объем памяти, необходимые для хранения происхождения, будут увеличиваться с увеличением размера и емкости системы. Архитектура Большое количество данных системы делают использование единого хранилища линии нецелесообразным и невозможным для масштабирования. Непосредственным решением этой проблемы является распространение самого хранилища родословных.[3]
Лучшим сценарием является использование локального хранилища данных для каждой машины в сети распределенной системы. Это позволяет также масштабировать хранилище родословной по горизонтали. В этой схеме происхождение преобразований данных, применяемых к данным на конкретной машине, хранится в локальном хранилище данных на этой конкретной машине. В хранилище родословной обычно хранятся таблицы ассоциаций. Каждый субъект представлен своей собственной таблицей ассоциаций. Строки сами являются ассоциациями, а столбцы представляют входы и выходы. Эта конструкция решает 2 проблемы. Это позволяет горизонтально масштабировать хранилище родословной. Если использовалось единственное централизованное хранилище родословных, то эту информацию нужно было переносить по сети, что привело бы к дополнительной сетевой задержке. Задержки в сети также можно избежать за счет использования распределенного хранилища родословных.[28]
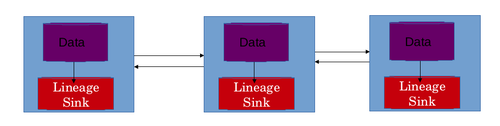
Реконструкция потока данных
Информация, хранящаяся в виде ассоциаций, должна быть каким-то образом объединена, чтобы получить поток данных конкретного задания. В распределенной системе задание разбито на несколько задач. Один или несколько экземпляров выполняют конкретную задачу. Результаты, полученные на этих отдельных машинах, позже объединяются для завершения работы. Задачи, выполняемые на разных машинах, выполняют несколько преобразований данных на машине. Все преобразования, применяемые к данным на машинах, хранятся в локальном хранилище родословных этих машин. Эту информацию необходимо объединить, чтобы получить представление о происхождении всей работы. Происхождение всей работы должно помочь специалисту по обработке данных понять поток данных в работе, и он / она может использовать поток данных для отладки большое количество данных трубопровод. Поток данных реконструируется в 3 этапа.
Таблицы ассоциаций
Первым этапом реконструкции потока данных является вычисление ассоциативных таблиц. Таблицы ассоциаций существуют для каждого актера в каждом локальном хранилище родословной. Всю таблицу ассоциаций для актера можно вычислить, объединив эти отдельные таблицы ассоциаций. Обычно это делается с помощью серии соединений равенства, основанных на самих актерах. В некоторых сценариях таблицы также могут быть объединены с использованием входных данных в качестве ключа. Индексы также могут использоваться для повышения эффективности соединения. Объединенные таблицы должны храниться в одном экземпляре или на машине, чтобы продолжить обработку. Есть несколько схем, которые используются для выбора машины, на которой будет вычислено соединение. Самый простой - с минимальной загрузкой процессора. При выборе экземпляра, в котором будет происходить соединение, также следует учитывать ограничения по объему.
График ассоциации
Второй шаг в реконструкции потока данных - это вычисление графа ассоциации на основе информации о происхождении. На графике представлены этапы потока данных. Актеры действуют как вершины, а ассоциации действуют как ребра. Каждый субъект T связан со своими вышестоящими и нижестоящими субъектами в потоке данных. Актер восходящего потока T - это тот, кто произвел ввод T, а нисходящий актор - это тот, который потребляет вывод T. При создании ссылок всегда учитываются сдерживающие отношения. Граф состоит из трех типов связей или ребер.
Явно указанные ссылки
Простейшая ссылка - это явно указанная связь между двумя участниками. Эти ссылки явно указаны в коде алгоритма машинного обучения. Когда актор знает о своем точном восходящем или нисходящем актере, он может передать эту информацию в Lineage API. Эта информация позже используется для связывания этих субъектов во время запроса трассировки. Например, в Уменьшение карты В архитектуре каждый экземпляр карты знает точный экземпляр устройства чтения записей, выходные данные которого он использует.[3]
Логически выведенные ссылки
Разработчики могут прикрепить поток данных архетипы каждому логическому действующему лицу. Архетип потока данных объясняет, как дочерние типы типа актера размещаются в потоке данных. С помощью этой информации можно сделать вывод о связи между каждым субъектом исходного типа и целевого типа. Например, в Уменьшение карты в архитектуре тип актора карты является источником для сокращения, и наоборот. Система выводит это из архетипов потока данных и должным образом связывает экземпляры карты с экземплярами сокращения. Однако может быть несколько Уменьшение карты задания в потоке данных, и связывание всех экземпляров карты со всеми экземплярами reduce может создать ложные ссылки. Чтобы предотвратить это, такие ссылки ограничены экземплярами актора, содержащимися в общем экземпляре актора содержащего (или родительского) типа актора. Таким образом, экземпляры map и reduce связаны друг с другом, только если они принадлежат одному и тому же заданию.[3]
Неявные ссылки через совместное использование набора данных
В распределенных системах иногда встречаются неявные ссылки, которые не указываются при выполнении. Например, существует неявная связь между актером, который записал в файл, и другим актером, читающим из него. Такие ссылки соединяют акторов, которые используют общий набор данных для выполнения. Набор данных является выходом первого актера и входом следующего за ним актера.[3]
Топологическая сортировка
Заключительным этапом реконструкции потока данных является топологическая сортировка графа ассоциации. Ориентированный граф, созданный на предыдущем шаге, топологически сортируется, чтобы получить порядок, в котором субъекты изменили данные. Этот порядок наследования субъектов определяет поток данных конвейера больших данных или задачи.
Отслеживание и воспроизведение
Это самый важный шаг в Большое количество данных отладка. Захваченная родословная объединяется и обрабатывается для получения потока данных конвейера. Поток данных помогает специалисту по обработке данных или разработчику глубже изучить действующих лиц и их преобразования. Этот шаг позволяет специалисту по обработке данных выяснить, какая часть алгоритма генерирует неожиданный результат. А большое количество данных трубопровод может пойти не так, как надо по двум основным причинам. Первый - это наличие подозрительного субъекта в потоке данных. Второй - наличие выбросов в данных.
Первый случай можно отладить, отслеживая поток данных. Используя информацию о происхождении и потоке данных вместе, специалист по данным может выяснить, как входные данные преобразуются в выходные. Во время процесса могут быть пойманы субъекты, которые ведут себя неожиданно. Либо эти субъекты могут быть удалены из потока данных, либо они могут быть дополнены новыми субъектами для изменения потока данных. Улучшенный поток данных можно воспроизвести, чтобы проверить его достоверность. Отладка ошибочных акторов включает в себя рекурсивное выполнение грубого воспроизведения акторов в потоке данных,[29] что может быть дорогостоящим в ресурсах для длинных потоков данных. Другой подход состоит в том, чтобы вручную просмотреть журналы происхождения, чтобы найти аномалии,[13][30] что может быть утомительным и трудоемким на нескольких этапах потока данных. Более того, эти подходы работают только тогда, когда специалист по данным может обнаружить плохие результаты. Чтобы отлаживать аналитику без известных плохих результатов, специалисту по данным необходимо проанализировать поток данных на предмет подозрительного поведения в целом. Однако часто пользователь может не знать ожидаемого нормального поведения и не может указывать предикаты. В этом разделе описывается методика отладки для ретроспективного анализа происхождения для выявления ошибочных участников в многоступенчатом потоке данных. Мы считаем, что внезапные изменения в поведении актора, такие как его средняя избирательность, скорость обработки или размер вывода, являются характеристикой аномалии. Происхождение может отражать такие изменения в поведении акторов с течением времени и в разных экземплярах акторов. Таким образом, анализ происхождения для выявления таких изменений может быть полезен при отладке неисправных участников в потоке данных.
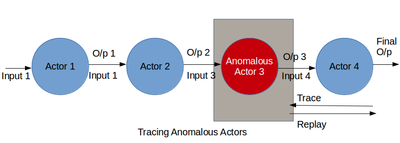
Вторая проблема, то есть наличие выбросов, также может быть идентифицирована путем пошагового выполнения потока данных и просмотра преобразованных выходных данных. Специалист по анализу данных находит подмножество выходных данных, которые не соответствуют остальным выходным данным. Входные данные, вызывающие эти плохие результаты, являются выбросами в данных. Эта проблема может быть решена путем удаления набора выбросов из данных и воспроизведения всего потока данных. Эту проблему также можно решить, изменив алгоритм машинного обучения путем добавления, удаления или перемещения субъектов в потоке данных. Изменения в потоке данных успешны, если воспроизведенный поток данных не дает плохих результатов.

Вызовы
Несмотря на то, что использование подходов к передаче данных является новым способом отладки большое количество данных трубопроводов, процесс не из простых. Проблемы включают в себя масштабируемость хранилища родословных, отказоустойчивость хранилища родословных, точное определение происхождения для операторов черного ящика и многие другие. Эти проблемы необходимо тщательно рассмотреть, и необходимо оценить компромиссы между ними, чтобы создать реалистичный дизайн для сбора данных о происхождении.
Масштабируемость
Системы DISC - это в первую очередь системы пакетной обработки, рассчитанные на высокую производительность. Они выполняют несколько заданий на аналитику, с несколькими задачами на задание. Общее количество операторов, выполняемых в любое время в кластере, может варьироваться от сотен до тысяч в зависимости от размера кластера. Захват происхождения для этих систем должен иметь возможность масштабирования как для больших объемов данных, так и для множества операторов, чтобы не быть узким местом для аналитики DISC.
Отказоустойчивость
Системы захвата происхождения также должны быть отказоустойчивыми, чтобы избежать повторного запуска потоков данных для захвата происхождения. В то же время они также должны учитывать сбои в системе DISC. Для этого они должны быть в состоянии идентифицировать неудачную задачу DISC и избегать хранения дублирующих копий родословной между частичной линией, созданной неудачной задачей, и дублирующей линией, произведенной перезапущенной задачей. Система родословной также должна уметь корректно обрабатывать несколько экземпляров локальных систем родословной, выходящих из строя. Это может быть достигнуто путем хранения реплик ассоциаций родословных на нескольких машинах. Реплика может действовать как резервная копия в случае потери реальной копии.
Операторы черного ящика
Системы происхождения для потоков данных DISC должны иметь возможность фиксировать точное происхождение операторов черного ящика, чтобы обеспечить точную отладку. Текущие подходы к этому включают Prober, который стремится найти минимальный набор входных данных, который может дать определенный вывод для оператора черного ящика, путем многократного воспроизведения потока данных для вывода минимального набора,[31] и динамическое нарезание, используемое Zhang et al.[32] захватить родословную для NoSQL операторы посредством двоичной перезаписи для вычисления динамических срезов. Несмотря на то, что такие методы позволяют получать высокоточные родословные, они могут потребовать значительных временных затрат на захват или отслеживание, и вместо этого может быть предпочтительнее отдать некоторую точность ради лучшей производительности. Таким образом, существует потребность в системе сбора данных о происхождении для потоков данных DISC, которая может фиксировать происхождение от произвольных операторов с разумной точностью и без значительных накладных расходов при захвате или отслеживании.
Эффективное отслеживание
Трассировка необходима для отладки, во время которой пользователь может отправить несколько запросов трассировки. Таким образом, важно, чтобы отслеживание выполнялось быстро. Икеда и др.[24] могут выполнять эффективные запросы обратной трассировки для потоков данных MapReduce, но не являются общими для разных систем DISC и не выполняют эффективных прямых запросов. Помада[33] система происхождения для Свиньи,[34] хотя может выполнять как обратную, так и прямую трассировку, специфична для операторов Pig и SQL и может выполнять только грубую трассировку для операторов черного ящика. Таким образом, существует потребность в системе происхождения, которая обеспечивает эффективную прямую и обратную трассировку для общих систем DISC и потоков данных с операторами черного ящика.
Изысканный повтор
Воспроизведение только определенных входных данных или частей потока данных имеет решающее значение для эффективной отладки и моделирования сценариев «что, если». Икеда и др. представить методологию обновления на основе происхождения, которая выборочно воспроизводит обновленные входные данные для пересчета затронутых выходных данных.[35] Это полезно во время отладки для повторного вычисления выходных данных, когда плохой вход был исправлен. Однако иногда пользователю может потребоваться удалить неверный ввод и воспроизвести последовательность выходных данных, ранее затронутых ошибкой, для получения выходных данных без ошибок. Мы называем это эксклюзивным воспроизведением. Another use of replay in debugging involves replaying bad inputs for step-wise debugging (called selective replay). Current approaches to using lineage in DISC systems do not address these. Thus, there is a need for a lineage system that can perform both exclusive and selective replays to address different debugging needs.
Обнаружение аномалий
One of the primary debugging concerns in DISC systems is identifying faulty operators. In long dataflows with several hundreds of operators or tasks, manual inspection can be tedious and prohibitive. Even if lineage is used to narrow the subset of operators to examine, the lineage of a single output can still span several operators. There is a need for an inexpensive automated debugging system, which can substantially narrow the set of potentially faulty operators, with reasonable accuracy, to minimize the amount of manual examination required.
Смотрите также
Рекомендации
- ^ http://www.techopedia.com/definition/28040/data-lineage
- ^ Hoang, Natalie (2017-03-16). "Data Lineage Helps Drives Business Value | Trifacta". Trifacta. Получено 2017-09-20.
- ^ а б c d е ж грамм час я j k De, Soumyarupa. (2012). Newt : an architecture for lineage based replay and debugging in DISC systems. UC San Diego: b7355202. Извлекаются из: https://escholarship.org/uc/item/3170p7zn
- ^ Drori, Amanon (2020-05-18). "What is Data Lineage? | Octopai". Octopai. Получено 2020-08-25.
- ^ Jeffrey Dean and Sanjay Ghemawat. Mapreduce: simplified data processing on large clusters. Commun. ACM, 51(1):107–113, January 2008.
- ^ Michael Isard, Mihai Budiu, Yuan Yu, Andrew Birrell, and Dennis Fetterly. Dryad: distributed data-parallel programs from sequential building blocks. In Proceedings of the 2nd ACM SIGOPS/EuroSys European Conference onComputer Systems 2007, EuroSys ’07, pages 59–72, New York, NY, USA, 2007. ACM.
- ^ Apache Hadoop. http://hadoop.apache.org.
- ^ Grzegorz Malewicz, Matthew H. Austern, Aart J.C Bik, James C. Dehnert, Ilan Horn, Naty Leiser, and Grzegorz Czajkowski. Pregel: a system for largescale graph processing. In Proceedings of the 2010 international conference on Managementof data, SIGMOD ’10, pages 135–146, New York, NY, USA, 2010. ACM.
- ^ Shimin Chen and Steven W. Schlosser. Map-reduce meets wider varieties of applications. Technical report, Intel Research, 2008.
- ^ The data deluge in genomics. https://www-304.ibm.com/connections/blogs/ibmhealthcare/entry/data overload in genomics3?lang=de, 2010.
- ^ Yogesh L. Simmhan, Beth Plale, and Dennis Gannon. A survey of data prove-nance in e-science. SIGMOD Rec., 34(3):31–36, September 2005.
- ^ а б Ian Foster, Jens Vockler, Michael Wilde, and Yong Zhao. Chimera: A Virtual Data System for Representing, Querying, and Automating Data Derivation. In 14th International Conference on Scientific and Statistical Database Management, July 2002.
- ^ а б Benjamin H. Sigelman, Luiz Andr Barroso, Mike Burrows, Pat Stephenson, Manoj Plakal, Donald Beaver, Saul Jaspan, and Chandan Shanbhag. Dapper, a large-scale distributed systems tracing infrastructure. Technical report, Google Inc, 2010.
- ^ а б Питер Бунеман, Санджив Кханна, и Ван-Чью Тан. Data provenance: Some basic issues. In Proceedings of the 20th Conference on Foundations of SoftwareTechnology and Theoretical Computer Science, FST TCS 2000, pages 87–93, London, UK, UK, 2000. Springer-Verlag
- ^ http://www.emc.com/about/news/press/2012/20121211-01.htm
- ^ Вебопедия http://www.webopedia.com/TERM/U/unstructured_data.html
- ^ Schaefer, Paige (2016-08-24). "Differences Between Structured & Unstructured Data". Trifacta. Получено 2017-09-20.
- ^ SAS. http://www.sas.com/resources/asset/five-big-data-challenges-article.pdf В архиве 2014-12-20 в Wayback Machine
- ^ "5 Requirements for Effective Self-Service Data Preparation". www.itbusinessedge.com. Получено 2017-09-20.
- ^ Kandel, Sean (2016-11-04). "Tracking Data Lineage in Financial Services | Trifacta". Trifacta. Получено 2017-09-20.
- ^ Паскье, Томас; Лау, Мэтью К .; Трисович, Ана; Boose, Emery R .; Кутюрье, Бен; Кросас, Мерсе; Эллисон, Аарон М .; Гибсон, Валери; Джонс, Крис Р .; Зельцер, Марго (5 сентября 2017 г.). «Если бы эти данные могли говорить». Научные данные. 4: 170114. Дои:10.1038 / sdata.2017.114. ЧВК 5584398. PMID 28872630.
- ^ Robert Ikeda and Jennifer Widom. Data lineage: A survey. Technical report, Stanford University, 2009.
- ^ а б Y. Cui and J. Widom. Lineage tracing for general data warehouse transformations. VLDB Journal, 12(1), 2003.
- ^ а б c d Robert Ikeda, Hyunjung Park, and Jennifer Widom. Provenance for generalized map and reduce workflows. В Proc. of CIDR, January 2011.
- ^ C. Olston and A. Das Sarma. Ibis: A provenance manager for multi-layer systems. В Proc. of CIDR, January 2011.
- ^ http://info.hortonworks.com/rs/549-QAL-086/images/Hadoop-Governance-White-Paper.pdf
- ^ SEC Small Entity Compliance Guide
- ^ а б Dionysios Logothetis, Soumyarupa De, and Kenneth Yocum. 2013. Scalable lineage capture for debugging DISC analytics. In Proceedings of the 4th annual Symposium on Cloud Computing (SOCC '13). ACM, New York, NY, USA, , Article 17 , 15 pages.
- ^ Zhou, Wenchao; Fei, Qiong; Narayan, Arjun; Хеберлен, Андреас; Thau Loo, Boon; Sherr, Micah (December 2011). Secure network provenance. Proceedings of 23rd ACM Symposium on Operating System Principles (SOSP).
- ^ Фонсека, Родриго; Porter, George; Katz, Randy H.; Shenker, Scott; Stoica, Ion (2007). X-trace: A pervasive network tracing framework. Proceedings of NSDI’07.
- ^ Anish Das Sarma, Alpa Jain, and Philip Bohannon. PROBER: Ad-Hoc Debugging of Extraction and Integration Pipelines. Technical report, Yahoo, April 2010.
- ^ Mingwu Zhang, Xiangyu Zhang, Xiang Zhang, and Sunil Prabhakar. Tracing lineage beyond relational operators. В Proc. Conference on Very Large Data Bases (VLDB), September 2007.
- ^ Yael Amsterdamer, Susan B. Davidson, Daniel Deutch, Tova Milo, and Julia Stoyanovich. Putting lipstick on a pig: Enabling database-style workflow provenance. В Proc. of VLDB, August 2011.
- ^ Christopher Olston, Benjamin Reed, Utkarsh Srivastava, Ravi Kumar, and Andrew Tomkins. Pig latin: A not-so-foreign language for data processing. В Proc. of ACM SIGMOD, Vancouver, Canada, June 2008.
- ^ Robert Ikeda, Semih Salihoglu, and Jennifer Widom. Provenance-based refresh in data-oriented workflows. In Proceedings of the 20th ACM international conference on Information and knowledge management, CIKM ’11, pages 1659–1668, New York, NY, USA, 2011. ACM.