Таксономия Флиннса - Википедия - Flynns taxonomy
Таксономия Флинна это классификация компьютерные архитектуры, предложено Майкл Дж. Флинн в 1966 г.[1][2] Система классификации прижилась и использовалась в качестве инструмента при разработке современных процессоров и их функций. С появлением многопроцессорность центральные процессоры (CPU), a мультипрограммирование контекст эволюционировал как расширение системы классификации.
Классификации
Четыре классификации, определенные Флинном, основаны на количестве параллельных потоков инструкций (или управления) и потоков данных, доступных в архитектуре.[3]
| Таксономия Флинна |
|---|
| Единый поток данных |
| Несколько потоков данных |
Одиночный поток инструкций, одиночный поток данных (SISD)
Последовательный компьютер, не использующий параллелизм ни в потоках команд, ни в потоках данных. Единый блок управления (CU) выбирает единый поток команд (IS) из памяти. Затем CU генерирует соответствующие управляющие сигналы, чтобы указать одному элементу обработки (PE) работать с одним потоком данных (DS), то есть по одной операции за раз.
Примеры архитектуры SISD - традиционные однопроцессор машины как старые персональные компьютеры (ПК; к 2010 году многие ПК имели несколько ядер) и мэйнфреймы.
Один поток инструкций, несколько потоков данных (SIMD)
Одна инструкция работает с несколькими разными потоками данных. Инструкции могут выполняться последовательно, например, конвейерной обработкой, или параллельно несколькими функциональными модулями.
Одна инструкция, несколько потоков (SIMT) - это модель исполнения, используемая в параллельные вычисления куда одна инструкция, несколько данных (SIMD) сочетается с многопоточность. Это не отдельная классификация в таксономии Флинна, где это было бы подмножеством SIMD. Nvidia обычно использует этот термин в своих маркетинговых материалах и технических документах, аргументируя новизну архитектуры Nvidia.[4]
Несколько потоков инструкций, один поток данных (MISD)
Несколько инструкций работают с одним потоком данных. Это необычная архитектура, которая обычно используется для обеспечения отказоустойчивости. Гетерогенные системы работают с одним и тем же потоком данных и должны согласовывать результат. Примеры включают Космический шатл компьютер управления полетом.[5]
Несколько потоков инструкций, несколько потоков данных (MIMD)
Несколько автономных процессоров одновременно выполняют разные инструкции с разными данными. Архитектуры MIMD включают многоядерный суперскалярный процессоры и распределенные системы, используя либо одно пространство общей памяти, либо пространство распределенной памяти.
Схема сравнения классификаций
Эти четыре архитектуры визуально показаны ниже. Каждый блок обработки (PU) показан для одноядерного или многоядерного компьютера:

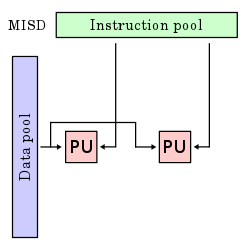
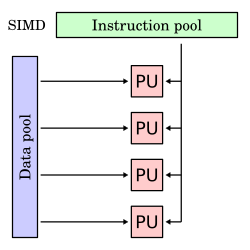
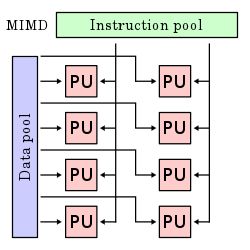
Дальнейшие подразделения
По состоянию на 2006 г.[Обновить], все 10 лучших и большинство TOP500 суперкомпьютеры основаны на архитектуре MIMD.
Некоторые делят категорию MIMD на две категории ниже:[6][7][8][9][10] и иногда рассматриваются даже дальнейшие подразделения.[11]
Одна программа, несколько потоков данных (SPMD)
Несколько автономных процессоров, одновременно выполняющих одну и ту же программу (но в независимых точках, а не в шаг что SIMD накладывает) на разные данные. Также называется один процесс, несколько данных[10] - использование этой терминологии для SPMD технически некорректно, поскольку SPMD представляет собой модель параллельного выполнения и предполагает, что несколько взаимодействующих процессоров выполняют программу. SPMD - это наиболее распространенный стиль параллельного программирования.[12] Модель и термин SPMD были предложены Фредерикой Даремой.[13] Грегори Ф. Пфистер был менеджером проекта RP3, а Дарема была частью команды RP3.
Несколько программ, несколько потоков данных (MPMD)
Несколько автономных процессоров одновременно работают как минимум с 2 независимыми программами. Обычно такие системы выбирают один узел в качестве «хоста» («явная модель программирования хост / узел») или «менеджера» (стратегия «менеджер / работник»), который запускает одну программу, которая передает данные всем остальным узлам. которые все запускают вторую программу. Затем эти другие узлы возвращают свои результаты непосредственно менеджеру. Примером этого может быть игровая консоль Sony PlayStation 3 с ее Процессор SPU / PPU.
Смотрите также
Рекомендации
- ^ Флинн, Майкл Дж. (Сентябрь 1972 г.). «Некоторые компьютерные организации и их эффективность». Транзакции IEEE на компьютерах. С-21 (9): 948–960. Дои:10.1109 / TC.1972.5009071.
- ^ Дункан, Ральф (февраль 1990 г.). «Обзор параллельных компьютерных архитектур» (PDF). Компьютер. 23 (2): 5–16. Дои:10.1109/2.44900. В архиве (PDF) из оригинала 2018-07-18. Получено 2018-07-18.
- ^ http://www.cse.msu.edu/~cse820/lectures/CAQA5e_ch4.pdf
- ^ http://www.nvidia.com/content/PDF/fermi_white_papers/NVIDIA_Fermi_Compute_Architecture_Whitepaper.pdf
- ^ Спектор, А .; Гиффорд, Д. (сентябрь 1984 г.). «Основная компьютерная система космического челнока». Коммуникации ACM. 27 (9): 872–900. Дои:10.1145/358234.358246.
- ^ «Однопрограммный поток нескольких данных (SPMD)». Llnl.gov. Получено 2013-12-09.
- ^ [1] В архиве 1 сентября 2006 г. Wayback Machine
- ^ «Виртуальная мастерская СТС». Web0.tc.cornell.edu. Получено 2013-12-09.
- ^ «Учебник по NIST SP2: программирование с распределенной памятью». Math.nist.gov. Архивировано из оригинал на 2013-12-13. Получено 2013-12-09.
- ^ а б [2] В архиве 3 февраля 2007 г. Wayback Machine
- ^ [3] В архиве 10 сентября 2006 г. Wayback Machine
- ^ «Одна программа с несколькими данными». Nist.gov. 2004-12-17. Получено 2013-12-09.
- ^ Дарема, Фредерика; Джордж, Дэвид А .; Нортон, В. Алан; Пфистер, Грегори Ф. (1988). "Вычислительная модель" одна программа - несколько данных "для EPEX / FORTRAN". Параллельные вычисления. 7 (1): 11–24. Дои:10.1016/0167-8191(88)90094-4.
| Общий | |
|---|---|
| Уровни | |
| Многопоточность | |
| Теория | |
| Элементы | |
| Координация | |
| Программирование | |
| Аппаратное обеспечение | |
| API | |
| Проблемы | |
| |
Статья основана на материалах, взятых из Бесплатный онлайн-словарь по вычислительной технике до 1 ноября 2008 г. и зарегистрированы в соответствии с условиями «перелицензирования» GFDL, версия 1.3 или новее.