MIMD - MIMD
| Таксономия Флинна |
|---|
| Единый поток данных |
| Несколько потоков данных |
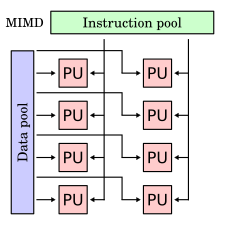
В вычисление, MIMD (несколько инструкций, несколько данных) - это метод, используемый для достижения параллелизма. Машины, использующие MIMD, имеют ряд процессоры эта функция асинхронно и самостоятельно. В любое время разные процессоры могут выполнять разные инструкции для разных фрагментов данных. Архитектуры MIMD могут использоваться в ряде областей приложений, таких как системы автоматизированного проектирования /автоматическое производство, симуляция, моделирование, и в качестве переключатели связи. MIMD-машины могут быть Общая память или распределенная память категории. Эти классификации основаны на том, как процессоры MIMD получают доступ к памяти. Машины с общей памятью могут быть автобусный, расширенный или иерархический тип. Машины с распределенной памятью могут иметь гиперкуб или сетка схемы подключения.
Примеры
Пример системы MIMD: Intel Xeon Phi, произошедший от Ларраби микроархитектура.[1] Эти процессоры имеют несколько процессорных ядер (до 61 по состоянию на 2015 год), которые могут выполнять разные инструкции с разными данными.
Большинство параллельных компьютеров по состоянию на 2013 год являются системами MIMD.[2]
Все процессоры подключены к "глобально доступной" памяти через любой программного обеспечения или аппаратные средства. В Операционная система обычно сохраняет связность памяти.[3]
С точки зрения программиста, эта модель памяти более понятна, чем модель распределенной памяти. Еще одно преимущество состоит в том, что согласованность памяти управляется операционной системой, а не написанной программой. Два известных недостатка: масштабируемость за пределы тридцати двух процессоров затруднена, и модель общей памяти менее гибкая, чем модель распределенной памяти.[3]
Есть много примеров разделяемой памяти (мультипроцессоров): UMA (Единый доступ к памяти ), КОМА (Доступ только к кешу ).[4]
На автобусе
MIMD-машины с общей памятью имеют процессоры, которые используют общую центральную память. В простейшей форме все процессоры подключены к шине, которая соединяет их с памятью. Это означает, что каждая машина с разделяемой памятью использует определенную CM, общую систему шин для всех клиентов.
Например, если мы рассмотрим шину с клиентами A, B, C, подключенными на одной стороне, и P, Q, R, подключенными на противоположной стороне, любой из клиентов будет связываться с другим посредством интерфейса шины между ними.
Иерархический
Машины MIMD с иерархической общей памятью используют иерархию шин (как, например, в "Жирное дерево "), чтобы предоставить процессорам доступ к памяти друг друга. Процессоры на разных платах могут обмениваться данными через межузловые шины. Шины поддерживают связь между платами. При таком типе архитектуры машина может поддерживать более девяти тысяч процессоров.
Распределенная память
В машинах MIMD с распределенной памятью каждый процессор имеет свою собственную индивидуальную ячейку памяти. Каждый процессор не имеет прямых сведений о памяти другого процессора. Для обмена данными они должны передаваться от одного процессора к другому в виде сообщения. Поскольку разделяемой памяти нет, конкуренция на этих машинах не является большой проблемой. Прямое подключение большого количества процессоров друг к другу экономически нецелесообразно. Способ избежать этого множества прямых подключений - подключить каждый процессор всего к нескольким другим. Этот тип дизайна может быть неэффективным из-за дополнительного времени, необходимого для передачи сообщения от одного процессора к другому по пути сообщения. Время, необходимое процессорам для выполнения простой маршрутизации сообщений, может быть значительным. Системы были разработаны, чтобы уменьшить эту потерю времени и гиперкуб и сетка входят в число двух популярных схем подключения.
Примеры распределенной памяти (несколько компьютеров) включают: MPP (массивно-параллельные процессоры), COW (кластеры рабочих станций) и NUMA (Неравномерный доступ к памяти ). Первый сложен и дорог: множество суперкомпьютеров соединены широкополосными сетями. Примеры включают соединения гиперкуба и сетки. COW - это "самодельная" версия за небольшую плату.[4]
Сеть межсоединений Hypercube
В машине с распределенной памятью MIMD с гиперкуб сеть межсетевого взаимодействия системы, содержащая четыре процессора, процессор и модуль памяти размещены в каждой вершине квадрата. Диаметр системы - это минимальное количество шагов, которое требуется для одного процессора, чтобы отправить сообщение процессору, который находится дальше всего. Так, например, диаметр 2-куба равен 2. В системе гиперкуба с восемью процессорами и каждым процессором и модулем памяти, размещенными в вершине куба, диаметр равен 3. В общем случае система, содержащая 2 ^ N процессоров, каждый из которых напрямую подключен к N другим процессорам, диаметр системы равен N. Одним из недостатков системы гиперкубов является то, что она должна быть сконфигурирована в степени двойки, поэтому должна быть построена машина, которая потенциально могла бы иметь намного больше процессоров, чем это действительно необходимо для приложения.
Ячеистая взаимосвязанная сеть
В машине с распределенной памятью MIMD с ячеистой сетью межсоединений процессоры размещаются в двумерной сетке. Каждый процессор связан со своими четырьмя ближайшими соседями. По краям сетки могут быть предусмотрены соединения с обертыванием. Одно из преимуществ ячеистой сети межсоединений по сравнению с гиперкубом состоит в том, что ячеистая система не требует настройки степени двойки. Недостатком является то, что диаметр ячеистой сети больше, чем диаметр гиперкуба для систем с более чем четырьмя процессорами.
Смотрите также
использованная литература
- ^ http://perilsofparallel.blogspot.gr/2008/09/larrabee-vs-nvidia-mimd-vs-simd.html
- ^ «Архивная копия». Архивировано из оригинал на 2013-10-16. Получено 2013-10-16.CS1 maint: заархивированная копия как заголовок (ссылка на сайт)
- ^ а б Ибаруден, Джаффер. «Параллельная обработка, EG6370G: Глава 1, Мотивация и история». Слайды лекций. Университет Святой Марии, Сан-Антонио, Техас. Весна 2008 г.
- ^ а б Эндрю С. Таненбаум (1997). Структурированная компьютерная организация (4-е изд.). Прентис-Холл. С. 559–585. ISBN 978-0130959904. Архивировано из оригинал на 2013-12-01. Получено 2013-03-15.
| Общее | |
|---|---|
| Уровни | |
| Многопоточность | |
| Теория | |
| Элементы | |
| Координация | |
| Программирование | |
| Оборудование | |
| API | |
| Проблемы | |
| |