Компьютерный кластер - Википедия - Computer cluster


А компьютерный кластер представляет собой набор слабо или плотно связанных компьютеры которые работают вместе, так что во многих аспектах их можно рассматривать как единую систему. В отличие от сеточные компьютеры, компьютерные кластеры имеют каждый узел настроен для выполнения одной и той же задачи, контролируемой и планируемой программным обеспечением.
Компоненты кластера обычно соединяются друг с другом посредством быстрого локальные сети, с каждым узел (компьютер, используемый в качестве сервера), на котором запущен собственный экземпляр Операционная система. В большинстве случаев все узлы используют одно и то же оборудование.[1][нужен лучший источник ] и та же операционная система, хотя в некоторых настройках (например, при использовании Ресурсы для кластерных приложений с открытым исходным кодом (OSCAR)), на каждом компьютере можно использовать разные операционные системы или разное оборудование.[2]
Кластеры обычно развертываются для повышения производительности и доступности по сравнению с одним компьютером, при этом обычно они намного более рентабельны, чем отдельные компьютеры с сопоставимой скоростью или доступностью.[3]
Компьютерные кластеры возникли в результате конвергенции ряда вычислительных тенденций, включая доступность недорогих микропроцессоров, высокоскоростных сетей и программного обеспечения для обеспечения высокой производительности. распределенных вычислений.[нужна цитата ] Они имеют широкий диапазон применимости и развертывания, от кластеров для малого бизнеса с несколькими узлами до самых быстрых. суперкомпьютеры в мире, например Секвойя IBM.[4] До появления кластеров единое целое отказоустойчивой мэйнфреймы с модульное резервирование были трудоустроены; но более низкая начальная стоимость кластеров и повышенная скорость сетевой структуры способствовали внедрению кластеров. В отличие от высоконадежных мэйнфреймов кластеры дешевле масштабировать, но они также имеют повышенную сложность в обработке ошибок, поскольку в кластерах режимы ошибок не непрозрачны для запущенных программ.[5]
Базовые концепты

Стремление получить больше вычислительной мощности и лучшую надежность за счет организации ряда недорогих коммерческая готовая компьютеры дали начало множеству архитектур и конфигураций.
Подход компьютерной кластеризации обычно (но не всегда) соединяет ряд легко доступных вычислительных узлов (например, персональные компьютеры, используемые в качестве серверов) через быстрое локальная сеть.[6] Действия вычислительных узлов координируются «промежуточным программным обеспечением кластеризации», программным уровнем, который находится поверх узлов и позволяет пользователям рассматривать кластер как в целом один связанный вычислительный блок, например через единый образ системы концепция.[6]
Кластеризация компьютеров основана на централизованном подходе к управлению, который делает узлы доступными как согласованные общие серверы. Он отличается от других подходов, таких как пиринговый или же сеточные вычисления которые также используют много узлов, но с гораздо большим распределенная природа.[6]
Компьютерный кластер может быть простой двухузловой системой, которая просто соединяет два персональных компьютера, или может быть очень быстрым. суперкомпьютер. Базовый подход к построению кластера - это Беовульф кластер, который может быть построен из нескольких персональных компьютеров, чтобы создать экономичную альтернативу традиционным высокопроизводительные вычисления. Одним из первых проектов, продемонстрировавших жизнеспособность концепции, был 133-узловой. Каменный суперкомпьютер.[7] Разработчики использовали Linux, то Параллельная виртуальная машина инструментарий и Интерфейс передачи сообщений библиотека для достижения высокой производительности при относительно низкой стоимости.[8]
Хотя кластер может состоять всего из нескольких персональных компьютеров, соединенных простой сетью, архитектура кластера также может использоваться для достижения очень высокого уровня производительности. В TOP500 полугодовой список 500 самых быстрых суперкомпьютеры часто включает много кластеров, например самая быстрая машина в мире в 2011 году была K компьютер который имеет распределенная память, кластерная архитектура.[9]
История

Грег Пфистер заявил, что кластеры были изобретены не каким-либо конкретным поставщиком, а клиентами, которые не могли разместить всю свою работу на одном компьютере или нуждались в резервной копии.[10] Пфистер считает, что это время примерно в 1960-х годах. Формальная инженерная основа кластерных вычислений как средства выполнения параллельной работы любого рода, возможно, была изобретена Джин Амдал из IBM, который в 1967 году опубликовал основополагающую статью о параллельной обработке: Закон Амдала.
История ранних компьютерных кластеров более или менее напрямую связана с историей ранних сетей, поскольку одной из основных мотиваций развития сети было соединение вычислительных ресурсов, создавая де-факто компьютерный кластер.
Первой производственной системой, разработанной в виде кластера, была система Берроуза. B5700 в середине 1960-х гг. Это позволило подключить до четырех компьютеров, каждый с одним или двумя процессорами, к общей дисковой подсистеме хранения для распределения рабочей нагрузки. В отличие от стандартных многопроцессорных систем, каждый компьютер можно было перезапустить без нарушения общей работы.
Первый коммерческий продукт для слабосвязанной кластеризации был Datapoint Corporation Система «Подключенный ресурсный компьютер» (ARC), разработанная в 1977 году и использующая ARCnet как интерфейс кластера. Кластеризация как таковая не стала популярной до тех пор, пока Корпорация цифрового оборудования выпустил свои VAXcluster продукт в 1984 году для VAX / VMS операционная система (теперь называется OpenVMS). Продукты ARC и VAXcluster не только поддерживали параллельные вычисления, но и совместно использовали файловые системы и периферийный устройств. Идея заключалась в том, чтобы предоставить преимущества параллельной обработки при сохранении надежности и уникальности данных. Двумя другими примечательными ранними коммерческими кластерами были Тандем Гималайский (продукт высокой доступности примерно 1994 г.) и Параллельный сисплекс IBM S / 390 (также около 1994 г., в основном для использования в бизнесе).
В те же сроки, в то время как компьютерные кластеры использовали параллелизм вне компьютера в товарной сети, суперкомпьютеры стали использовать их на одном компьютере. После успеха CDC 6600 в 1964 г. Cray 1 был доставлен в 1976 году и представил внутренний параллелизм через векторная обработка.[11] В то время как ранние суперкомпьютеры исключали кластеры и полагались на Общая память, со временем некоторые из самых быстрых суперкомпьютеров (например, K компьютер ) полагались на кластерные архитектуры.
Атрибуты кластеров
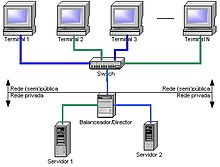
Компьютерные кластеры могут быть настроены для различных целей, начиная от общих бизнес-потребностей, таких как поддержка веб-сервисов, до научных вычислений, требующих больших вычислительных ресурсов. В любом случае кластер может использовать высокая доступность подход. Обратите внимание, что описанные ниже атрибуты не являются исключительными, и «компьютерный кластер» также может использовать подход высокой доступности и т. Д.
"Балансировка нагрузки «Кластеры - это конфигурации, в которых узлы кластера совместно используют вычислительную нагрузку для повышения общей производительности. Например, кластер веб-сервера может назначать разные запросы разным узлам, поэтому общее время ответа будет оптимизировано.[12] Однако подходы к балансировке нагрузки могут существенно различаться для разных приложений, например высокопроизводительный кластер, используемый для научных вычислений, будет балансировать нагрузку с помощью различных алгоритмов кластера веб-серверов, который может просто использовать простой циклический метод назначая каждый новый запрос другому узлу.[12]
Компьютерные кластеры используются для интенсивных вычислений, а не для обработки IO-ориентированный такие операции, как веб-служба или базы данных.[13] Например, компьютерный кластер может поддерживать компьютерное моделирование автомобильных аварий или погоды. Компьютерные кластеры с очень тесной связью предназначены для работы, которая может приближаться к "суперкомпьютеры ".
"Кластеры высокой доступности " (также известный как аварийное переключение кластеры или кластеры высокой доступности) повышают доступность кластерного подхода. Они работают за счет дублирования узлы, которые затем используются для обслуживания при выходе из строя компонентов системы. Реализации кластера высокой доступности пытаются использовать избыточность компонентов кластера для устранения единые точки отказа. Существуют коммерческие реализации кластеров высокой доступности для многих операционных систем. В Linux-HA проект - один из наиболее часто используемых бесплатно программное обеспечение Пакет HA для Linux Операционная система.
Преимущества
Кластеры в первую очередь разрабатываются с учетом производительности, но установка основана на многих других факторах. Отказоустойчивость (способность системы продолжать работу с неисправным узлом) позволяет масштабируемость, а в ситуациях с высокой производительностью, низкой частотой обслуживания, консолидацией ресурсов (например, RAID ) и централизованное управление. Преимущества включают возможность восстановления данных в случае аварии и обеспечение параллельной обработки данных и высокую производительность обработки.[14][15]
Что касается масштабируемости, кластеры обеспечивают это возможностью добавлять узлы по горизонтали. Это означает, что к кластеру можно добавить больше компьютеров, чтобы улучшить его производительность, избыточность и отказоустойчивость. Это может быть недорогое решение для более производительного кластера по сравнению с масштабированием одного узла в кластере. Это свойство компьютерных кластеров позволяет выполнять большие вычислительные нагрузки на большем количестве менее производительных компьютеров.
При добавлении нового узла в кластер надежность увеличивается, поскольку нет необходимости отключать весь кластер. Один узел может быть отключен для обслуживания, а остальная часть кластера берет на себя нагрузку этого отдельного узла.
Если у вас есть большое количество компьютеров, сгруппированных вместе, это поддается использованию распределенные файловые системы и RAID, оба из которых могут повысить надежность и скорость кластера.
Дизайн и комплектация
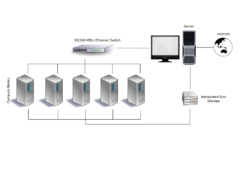
Одна из проблем при проектировании кластера - насколько сильно могут быть связаны отдельные узлы. Например, одно компьютерное задание может потребовать частого обмена данными между узлами: это означает, что кластер использует выделенную сеть, плотно расположен и, вероятно, имеет однородные узлы. Другой крайностью является ситуация, когда компьютерная работа использует один или несколько узлов и не требует или почти не требует связи между узлами, приближаясь к сеточные вычисления.
В Кластер Беовульф, прикладные программы никогда не видят вычислительные узлы (также называемые подчиненными компьютерами), а взаимодействуют только с «Мастером», который является конкретным компьютером, выполняющим планирование и управление подчиненными устройствами.[13] В типичной реализации Мастер имеет два сетевых интерфейса, один из которых обменивается данными с частной сетью Беовульфа для ведомых устройств, а другой - с сетью общего назначения организации.[13] Подчиненные компьютеры обычно имеют собственную версию той же операционной системы, а также локальную память и дисковое пространство. Однако частная подчиненная сеть может также иметь большой и совместно используемый файловый сервер, который хранит глобальные постоянные данные, к которым подчиненные устройства могут обращаться по мере необходимости.[13]
144 узла специального назначения Кластер DEGIMA настроен на выполнение астрофизических симуляций N-тел с использованием параллельного древовидного кода Multiple-Walk, а не для научных вычислений общего назначения.[16]
В связи с увеличением вычислительной мощности каждого поколения Игровые приставки, появилось новое применение, когда они были перепрофилированы в Высокопроизводительные вычисления (HPC) кластеры. Некоторые примеры кластеров игровых консолей: Кластеры Sony PlayStation и Microsoft Xbox кластеры. Другой пример потребительского игрового продукта - это Персональный суперкомпьютер Nvidia Tesla рабочая станция, использующая несколько процессорных микросхем графического ускорителя. Помимо игровых консолей, вместо них можно использовать и высококачественные видеокарты. Использование видеокарт (или, скорее, их графических процессоров) для вычислений в сетке намного более экономично, чем использование процессоров, несмотря на то, что они менее точны. Однако при использовании значений с двойной точностью они становятся такими же точными для работы, как и ЦП, и по-прежнему намного дешевле (стоимость покупки).[2]
Компьютерные кластеры исторически работали на отдельных физических компьютеры с тем же Операционная система. С появлением виртуализация узлы кластера могут работать на отдельных физических компьютерах с разными операционными системами, которые показаны выше с виртуальным слоем, чтобы выглядеть одинаково.[17][нужна цитата ][требуется разъяснение ] Кластер также может быть виртуализирован в различных конфигурациях по мере обслуживания; пример реализации Xen как менеджер виртуализации с Linux-HA.[17]
Обмен данными и коммуникация
Обмен данными

Как компьютерные кластеры появлялись в 1980-х годах, так и суперкомпьютеры. Одним из элементов, которые отличали эти три класса в то время, было то, что первые суперкомпьютеры полагались на Общая память. На сегодняшний день кластеры обычно не используют физически разделяемую память, хотя многие архитектуры суперкомпьютеров также отказались от нее.
Однако использование кластерная файловая система необходим в современных компьютерных кластерах.[нужна цитата ] Примеры включают Общая параллельная файловая система IBM, Microsoft Общие тома кластера или Кластерная файловая система Oracle.
Передача сообщений и общение
Два широко используемых подхода для связи между узлами кластера - это MPI (Интерфейс передачи сообщений ) и PVM (Параллельная виртуальная машина ).[18]
PVM был разработан в Национальная лаборатория Окриджа примерно в 1989 году до того, как появился MPI. PVM должен быть установлен непосредственно на каждом узле кластера и предоставляет набор программных библиотек, которые изображают узел как «параллельную виртуальную машину». PVM предоставляет среду выполнения для передачи сообщений, управления задачами и ресурсами и уведомления об ошибках. PVM может использоваться пользовательскими программами, написанными на C, C ++, Fortran и т. Д.[18][19]
MPI возник в начале 1990-х в результате дискуссий между 40 организациями. Первоначальные усилия были поддержаны ARPA и Национальный фонд науки. Вместо того, чтобы начинать заново, при разработке MPI использовались различные функции, доступные в коммерческих системах того времени. Затем спецификации MPI привели к конкретным реализациям. Реализации MPI обычно используют TCP / IP и розетки.[18] MPI теперь является широко доступной моделью коммуникации, которая позволяет писать параллельные программы на таких языках, как C, Фортран, Python, так далее.[19] Таким образом, в отличие от PVM, который обеспечивает конкретную реализацию, MPI - это спецификация, реализованная в таких системах, как MPICH и Открыть MPI.[19][20]
Управление кластером

Одной из проблем при использовании компьютерного кластера является стоимость его администрирования, которая иногда может быть такой же высокой, как стоимость администрирования N независимых машин, если в кластере N узлов.[21] В некоторых случаях это дает преимущество архитектуры с общей памятью с меньшими административными расходами.[21] Это также сделало виртуальные машины популярны благодаря простоте администрирования.[21]
Планирование задач
Когда большому многопользовательскому кластеру требуется доступ к очень большим объемам данных, планирование задач становится проблемой. В гетерогенном кластере CPU-GPU со сложной прикладной средой производительность каждого задания зависит от характеристик базового кластера. Следовательно, сопоставление задач с ядрами ЦП и устройствами с графическим процессором создает серьезные проблемы.[22] Это область постоянных исследований; алгоритмы, которые объединяют и расширяют Уменьшение карты и Hadoop были предложены и изучены.[22]
Управление отказами узлов
Когда узел в кластере выходит из строя, такие стратегии, как "ограждение "может использоваться для поддержания работоспособности остальной системы.[23][нужен лучший источник ][24] Ограждение - это процесс изоляции узла или защиты общих ресурсов, когда узел кажется неисправным. Есть два класса методов ограждения; один отключает сам узел, а другой запрещает доступ к таким ресурсам, как общие диски.[23]
В STONITH Метод расшифровывается как «Shoot The Other Node In The Head», что означает, что подозреваемый узел отключен или выключен. Например, силовое ограждение использует контроллер питания для выключения неработающего узла.[23]
В ограждение ресурсов подход запрещает доступ к ресурсам без отключения питания узла. Это может включать постоянное ограждение бронирования через SCSI3, ограждение волоконно-оптического канала для отключения оптоволоконный канал порт, или блочное устройство глобальной сети (GNBD) ограждение для отключения доступа к серверу GNBD.
Разработка и администрирование программного обеспечения
Параллельное программирование
Кластеры с балансировкой нагрузки, такие как веб-серверы, используют кластерные архитектуры для поддержки большого количества пользователей, и обычно каждый пользовательский запрос направляется на определенный узел, что позволяет параллелизм задач без взаимодействия нескольких узлов, учитывая, что основная цель системы - обеспечение быстрого доступа пользователей к общим данным. Однако «компьютерные кластеры», которые выполняют сложные вычисления для небольшого числа пользователей, должны использовать преимущества возможностей параллельной обработки кластера и разделять «те же вычисления» между несколькими узлами.[25]
Автоматическое распараллеливание программ остается технической проблемой, но модели параллельного программирования может быть использован для повышения степень параллелизма за счет одновременного выполнения отдельных частей программы на разных процессорах.[25][26]
Отладка и мониторинг
Для разработки и отладки параллельных программ в кластере требуются примитивы параллельного языка, а также подходящие инструменты, такие как те, которые обсуждались Форум по высокопроизводительной отладке (HPDF), в результате чего были разработаны спецификации HPD.[19][27]Такие инструменты как TotalView затем были разработаны для отладки параллельных реализаций на компьютерных кластерах, которые используют MPI или же PVM для передачи сообщений.
В Беркли Система NOW (Сеть рабочих станций) собирает данные о кластерах и сохраняет их в базе данных, а такая система, как PARMON, разработанная в Индии, позволяет визуально наблюдать и управлять большими кластерами.[19]
Контрольные точки приложения может использоваться для восстановления заданного состояния системы, когда узел выходит из строя во время долгих многоузловых вычислений.[28] Это важно в больших кластерах, учитывая, что по мере увеличения количества узлов увеличивается вероятность отказа узла при больших вычислительных нагрузках. Контрольная точка может восстановить систему до стабильного состояния, чтобы обработка могла возобновиться без повторного вычисления результатов.[28]
Реализации
Мир GNU / Linux поддерживает различное кластерное программное обеспечение; для кластеризации приложений есть distcc, и MPICH. Виртуальный сервер Linux, Linux-HA - кластеры на основе директоров, которые позволяют распределять входящие запросы на услуги по множеству узлов кластера. MOSIX, LinuxPMI, Kerrighed, OpenSSI полноценные кластеры, интегрированные в ядро которые обеспечивают автоматическую миграцию процессов между однородными узлами. OpenSSI, openMosix и Kerrighed находятся односистемный образ реализации.
Майкрософт Виндоус компьютерный кластер Server 2003 на базе Windows Server Платформа предоставляет такие компоненты для высокопроизводительных вычислений, как планировщик заданий, библиотека MSMPI и инструменты управления.
gLite представляет собой набор технологий промежуточного программного обеспечения, созданных Включение гридов для E-sciencE (EGEE) проект.
трепать также используется для планирования и управления некоторыми из крупнейших кластеров суперкомпьютеров (см. список top500).
Другие подходы
Хотя большинство компьютерных кластеров являются постоянными приспособлениями, попытки флэш-моб вычисления были созданы для создания короткоживущих кластеров для конкретных вычислений. Однако более масштабные волонтерские вычисления такие системы как BOINC у систем появилось больше последователей.
Смотрите также
Базовые концепты Распределенных вычислений | Особые системы Компьютерные фермы |
Рекомендации
- ^ «Кластерные или грид-вычисления». Переполнение стека.
- ^ Бадер, Дэвид; Пеннингтон, Роберт (май 2001 г.). «Кластерные вычисления: приложения». Компьютерный колледж Джорджии. Архивировано из оригинал 21 декабря 2007 г.. Получено 2017-02-28.
- ^ «Суперкомпьютер с ядерным оружием устанавливает мировой рекорд скорости для США». Телеграф. 18 июн 2012. Получено 18 июн 2012.
- ^ Грей, Джим; Рутер, Андреас (1993). Обработка транзакций: концепции и методы. Издательство Морган Кауфманн. ISBN 978-1558601901.
- ^ а б c Сетевые информационные системы: первая международная конференция, NBIS 2007. п. 375. ISBN 3-540-74572-6.
- ^ Уильям В. Харгроув, Форрест М. Хоффман и Томас Стерлинг (16 августа 2001 г.). "Самостоятельный суперкомпьютер". Scientific American. 265 (2). стр. 72–79. Получено 18 октября, 2011.
- ^ Харгроув, Уильям В .; Хоффман, Форрест М. (1999). «Кластерные вычисления: Linux, доведенный до крайности». Журнал Linux. Архивировано из оригинал 18 октября 2011 г.. Получено 18 октября, 2011.
- ^ Йококава, Мицуо; и другие. (1–3 августа 2011 г.). Компьютер K: японский проект по разработке суперкомпьютеров нового поколения. Международный симпозиум по маломощной электронике и дизайну (ISLPED). С. 371–372. Дои:10.1109 / ISLPED.2011.5993668.
- ^ Пфистер, Грегори (1998). В поисках кластеров (2-е изд.). Река Аппер Сэдл, Нью-Джерси: Prentice Hall PTR. п.36. ISBN 978-0-13-899709-0.
- ^ Хилл, Марк Дональд; Джуппи, Норман Пол; Сохи, Гуриндар (1999). Чтения по компьютерной архитектуре. С. 41–48. ISBN 978-1-55860-539-8.
- ^ а б Слоан, Джозеф Д. (2004). Высокопроизводительные кластеры Linux. ISBN 978-0-596-00570-2.
- ^ а б c d Дайде, Мишель; Донгарра, Джек (2005). Высокопроизводительные вычисления для вычислительной науки - VECPAR 2004. С. 120–121. ISBN 978-3-540-25424-9.
- ^ «IBM Cluster System: преимущества». IBM. Архивировано из оригинал 29 апреля 2016 г.. Получено 8 сентября 2014.
- ^ «Оценка преимуществ кластеризации». Microsoft. 28 марта 2003 г. Архивировано с оригинал 22 апреля 2016 г.. Получено 8 сентября 2014.
- ^ Хамада, Цуёси; и другие. (2009). «Новый параллельный алгоритм с несколькими обходами для древовидного кода Барнса – Хата на графических процессорах - в направлении экономичного и высокопроизводительного моделирования N-тела». Компьютерные науки - Исследования и разработки. 24 (1–2): 21–31. Дои:10.1007 / s00450-009-0089-1. S2CID 31071570.
- ^ а б Мауэр, Райан (12 января 2006 г.). «Виртуализация Xen и кластеризация Linux, часть 1». Linux журнал. Получено 2 июн 2017.
- ^ а б c Миликкио, Франко; Герке, Вольфганг Александр (2007). Распределенные сервисы с OpenAFS: для предприятий и образования. С. 339–341. ISBN 9783540366348.
- ^ а б c d е Прабху, C.S.R. (2008). Грид и кластерные вычисления. С. 109–112. ISBN 978-8120334281.
- ^ Гропп, Уильям; Ласк, Юинг; Скьеллум, Энтони (1996). «Высокопроизводительная портативная реализация интерфейса передачи сообщений MPI». Параллельные вычисления. 22 (6): 789–828. CiteSeerX 10.1.1.102.9485. Дои:10.1016/0167-8191(96)00024-5.CS1 maint: ref = harv (связь)
- ^ а б c Паттерсон, Дэвид А .; Хеннесси, Джон Л. (2011). Компьютерная организация и дизайн. С. 641–642. ISBN 978-0-12-374750-1.
- ^ а б К. Ширахата; и другие. (30 ноября - 3 декабря 2010 г.). Планирование задач гибридной карты для гетерогенных кластеров на базе GPU. Технология облачных вычислений и наука (CloudCom). С. 733–740. Дои:10.1109 / CloudCom.2010.55. ISBN 978-1-4244-9405-7.
- ^ а б c Робертсон, Алан (2010). «Ограждение ресурсов с помощью STONITH» (PDF). Исследовательский центр IBM Linux.
- ^ Варгас, Энрике; Бьянко, Джозеф; Дитс, Дэвид (2001). Среда Sun Cluster: Sun Cluster 2.2. Prentice Hall Professional. п. 58. ISBN 9780130418708.
- ^ а б Ахо, Альфред V .; Блюм, Эдвард К. (2011). Компьютерные науки: оборудование, программное обеспечение и его суть. С. 156–166. ISBN 978-1-4614-1167-3.
- ^ Раубер, Томас; Рюнгер, Гудула (2010). Параллельное программирование: для многоядерных и кластерных систем. С. 94–95. ISBN 978-3-642-04817-3.
- ^ Francioni, Joan M .; Блин, Черри М. (Апрель 2000 г.). «Стандарт отладки для высокопроизводительных вычислений». Научное программирование. Амстердам, Нидерланды: IOS Press. 8 (2): 95–108. Дои:10.1155/2000/971291. ISSN 1058-9244.
- ^ а б Sloot, Питер, изд. (2003). Вычислительная наука - ICCS 2003: Международная конференция. С. 291–292. ISBN 3-540-40195-4.
дальнейшее чтение
- Бейкер, Марк; и другие. (11 января 2001 г.). «Белая книга кластерных вычислений». arXiv:cs / 0004014.
- Маркус, Эван; Стерн, Хэл (2000-02-14). Чертежи для обеспечения высокой доступности: проектирование отказоустойчивых распределенных систем. Джон Вили и сыновья. ISBN 978-0-471-35601-1.
- Пфистер, Грег (1998). В поисках кластеров. Прентис Холл. ISBN 978-0-13-899709-0.
- Буйя, Раджкумар, изд. (1999). Высокопроизводительные кластерные вычисления: архитектуры и системы. 1. Нью-Джерси, США: Прентис Холл. ISBN 978-0-13-013784-5.
- Буйя, Раджкумар, изд. (1999). Высокопроизводительные кластерные вычисления: архитектуры и системы. 2. Нью-Джерси, США: Прентис Холл. ISBN 978-0-13-013785-2.
внешняя ссылка
- Технический комитет IEEE по масштабируемым вычислениям (TCSC)
- Надежная масштабируемая кластерная технология, IBM[постоянная мертвая ссылка ]
- Вики по Tivoli System Automation
- Управление крупномасштабным кластером в Google с помощью Borg, Апрель 2015 г., Абхишек Верма, Луис Педроса, Мадукар Коруполу, Дэвид Оппенгеймер, Эрик Тьюн и Джон Уилкс
| Общий | |
|---|---|
| Уровни | |
| Многопоточность | |
| Теория | |
| Элементы | |
| Координация | |
| Программирование | |
| Аппаратное обеспечение | |
| API | |
| Проблемы | |
| |