OCRopus - OCRopus
 | |
| Разработчики) | Томас Бройел, DFKI |
|---|---|
| изначальный выпуск | 9 апреля 2007 г.[1] |
| Стабильный выпуск | 1.3.3 / 16 декабря 2017 |
| Репозиторий | |
| Написано в | C ++ и Python |
| Операционная система | FreeBSD, Linux, Mac OS X |
| Тип | Оптическое распознавание символов |
| Лицензия | Лицензия Apache v2.0 |
| Интернет сайт | github |
OCRopus это свободный анализ документов и оптическое распознавание символов (OCR) система выпущена под Лицензия Apache v2.0 с очень модульной конструкцией с использованием интерфейсы командной строки.
OCRopus разработан под руководством Томаса Бруэля из Немецкий исследовательский центр искусственного интеллекта в Кайзерслаутерн, Германия и спонсировалась Google.
Описание
OCRopus был специально разработан для использования в оцифровка проекты книг, такие как Google Книги, Интернет-архив или библиотеки. Будет поддерживаться большое количество языков и шрифтов.[2] Однако его также можно использовать для настольных и офисных приложений или для приложений для людей с ослабленным зрением.
Основные компоненты OCRopus сформированы:
- анализ макета документа
- оптическое распознавание символов
- использование статистические языковые модели
Для этих компонентов доступны один или несколько сценариев. В модульный подход позволяет использовать отдельные рабочие процессы и обмениваться отдельными шагами.
По умолчанию OCRopus поставляется с моделью для текста на английском языке и моделью для текста на Fraktur. Эти модели относятся к сценарию и в значительной степени не зависят от реального языка.[3] Новые персонажи или языковые варианты можно обучать как новых, так и дополнительно.
Распознавание недавнего текста основано на повторяющиеся нейронные сети (LSTM ) и не требует языковой модели. Это позволяет обучать независимые от языка модели, для которых одновременно были показаны хорошие результаты распознавания для английского, немецкого и французского языков.[4] В добавок к Латинский шрифт, есть результаты для других скриптов, например санскрит, Урду, Деванагари и Греческий.
Очень хорошие показатели обнаружения могут быть достигнуты посредством соответствующего обучения. Эти дополнительные усилия особенно полезны для сложных документов или сценариев, которые сегодня уже не используются и которые не являются предметом внимания других программ OCR.[5][6]
История
9 апреля 2007 года OCRopus был объявлен спонсируемым Google проектом по разработке передовых технологий распознавания текста.[1] Финансирование было предоставлено сроком на три года и касалось, в частности, кандидатских и постдокторских должностей в DFKI и Кайзерслаутернский университет. В свою очередь, OCRopus также использовался для автоматического распознавания текста в Поиск книг Google.[7] Лицензирование по лицензии с открытым исходным кодом было сделано с самого начала, чтобы облегчить сотрудничество между промышленными и академическими исследованиями.[8] OCRopus получил дополнительное финансирование от Фонд Эндрю В. Меллона и BMBF.[9]
Первая альфа-версия 0.1 была выпущена 22 октября 2007 года, а в период с декабря 2007 года по май 2009 года последовало несколько предварительных выпусков, и в марте 2010 года была выпущена стабильная версия 0.4.4.[10] Первоначально программное обеспечение было разработано в C ++, Python и Lua с Варенье как система сборки. Полный рефакторинг исходного кода в модулях Python был сделан и выпущен в версии 0.5 (июнь 2012 г.).[11]
Первоначально, Тессеракт использовался как единственный модуль распознавания текста. С 2009 года (версия 0.4) Tesseract поддерживался только как плагин. Вместо этого был использован распознаватель текста собственной разработки (также сегментный).[12] Этот распознаватель затем использовался вместе с OpenFST.[13] за языковое моделирование после шага распознавания. С 2013 года дополнительное признание с повторяющиеся нейронные сети (LSTM ), который с выпуском версии 1.0 в ноябре 2014 года является единственным распознавателем.[14][15]
Исходный код управляется GitHub и поддерживается и развивается сообществом разработчиков.[16] Текущая версия OCRopus - 1.3.3 (декабрь 2017 г.).[17]
использование
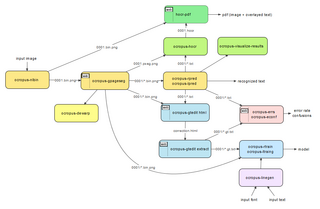
OCRopus можно использовать из командной строки. После установки его можно вызвать, указав входные изображения. Он выведет распознанный текст в стандартный вывод напрямую или напишите как hOCR (HTML на основе) кода в файлы, из которых он затем может быть преобразован в доступный для поиска PDF. Если требуется более точное управление, в командной строке можно указать параметры для выполнения определенных операций (например, распознавания одной строки).[18]
Пример вызовов OCRopus для распознавания текста на изображении:
# выполнить бинаризациюocropus-nlbin tests / ersch.png -o book # выполнить анализ макета страницыocropus-gpageseg book / 0001.bin.png # выполнить распознавание текстовых строк (с моделью фрактур) ocropus-rpred -m models / fraktur.pyrnn.gz book / 0001 / *. bin.png # генерировать HTML outputocropus-hocr book / 0001.bin.png -o book / 0001.htmlДругие инструменты сосредоточены на обучающей части OCRopus. Существуют модели OCRopus для извлечения текста из латинских, греческих, кириллических и индийских шрифтов.[19]
Рекомендации
- ^ а б Бруэль, Томас (9 апреля 2007 г.). «Объявление о системе OCRopus с открытым исходным кодом». Блог разработчиков Google. Получено 29 декабря 2017.
- ^ Бреуэл, Томас (2009). Последние достижения в системе OCRopus OCR. Материалы международного семинара по многоязычному распознаванию текста. MOCR '09. Нью-Йорк, Нью-Йорк, США: ACM. С. 2: 1–2: 10. Дои:10.1145/1577802.1577805. ISBN 9781605586984.
- ^ «Модели». ocropy вики. Получено 5 января 2018.
- ^ Уль-Хасан, Аднан; Бреуэл, Томас М. (2013). Можем ли мы создать независимое от языка OCR, используя сети LSTM?. Материалы 4-го Международного семинара по многоязычному распознаванию текста. МОЦР '13. Нью-Йорк, Нью-Йорк, США: ACM. стр. 9: 1–9: 5. Дои:10.1145/2505377.2505394. ISBN 9781450321143.
- ^ Спрингманн, Уве (1 декабря 2016 г.). «OCR für alte Drucke». Информатик-Спектрум (на немецком). 39 (6): 459–462. Дои:10.1007 / s00287-016-1004-3. ISSN 0170-6012.
- ^ Simistira, F .; Ul-Hassan, A .; Papavassiliou, V .; Gatos, B .; Katsouros, V .; Ливицки, М. (август 2015 г.). Распознавание исторических греческих политонических шрифтов с использованием сетей LSTM. 2015 13-я Международная конференция по анализу и распознаванию документов (ICDAR). С. 766–770. Дои:10.1109 / icdar.2015.7333865. ISBN 978-1-4799-1805-8.
- ^ «Исследовательский проект OCRopus». www.dfki.de. Получено 5 января 2018.
- ^ Бреуэл, Томас М. (28 января 2008 г.). «Система OCRopus с открытым исходным кодом». Слушания, том 6815, Распознавание и поиск документов XV. Распознавание и поиск документов XV. 6815: 68150F – 68150F – 15. Bibcode:2008SPIE.6815E..0FB. CiteSeerX 10.1.1.99.8505. Дои:10.1117/12.783598.
- ^ "сайт проекта окропус". Хостинг проектов Google. Январь 2019. Архивировано с оригинал 24 декабря 2012 г.
- ^ «Старые версии - ocropy». GitHub. Получено 5 января 2018.
- ^ «OCRopus 0.5». Группы Google. 2 июня 2012 г.
- ^ OCRopus по умолчанию даже не связывается с Tesseract.
- ^ Официальный сайт OpenFST.
- ^ "ocropy - выпуск v1.0". GitHub. 2 ноября 2014 г.. Получено 5 января 2018.
- ^ Breuel, T. M .; Уль-Хасан, А .; Аль-Азави, М. А .; Шафайт, Ф. (август 2013 г.). Высокопроизводительное OCR для печатного английского языка и Fraktur с использованием сетей LSTM. 2013 12-я Международная конференция по анализу и распознаванию документов. С. 683–687. Дои:10.1109 / icdar.2013.140. ISBN 978-0-7695-4999-6.
- ^ «ocropy: инструменты на основе Python для анализа документов и распознавания текста», GitHub, получено 5 января 2018
- ^ "Выпускает окропы". GitHub. Получено 5 января 2018.
- ^ "ocropy wiki". GitHub. Получено 30 декабря 2017.
- ^ "модели окропии". GitHub. Получено 13 марта 2018.
внешняя ссылка
- окропия на GitHub
- Вики по Ocropy на GitHub
- Сервер публикаций IUPR (статьи, лежащие в основе многих алгоритмов, используемых в OCRopus)