Рекурсивный фильтр наименьших квадратов - Recursive least squares filter
Рекурсивный метод наименьших квадратов (RLS) является адаптивный фильтр алгоритм, рекурсивно находящий коэффициенты, которые минимизируют взвешенный линейный метод наименьших квадратовфункция стоимости относящиеся к входным сигналам. Этот подход отличается от других алгоритмов, таких как наименьшие средние квадраты (LMS), которые направлены на сокращение среднеквадратичная ошибка. При выводе RLS входные сигналы учитываются детерминированный, а для LMS и аналогичного алгоритма они считаются стохастический. По сравнению с большинством своих конкурентов, RLS демонстрирует чрезвычайно быструю сходимость. Однако это преимущество достигается за счет высокой вычислительной сложности.
RLS был открыт Гаусс но оставался неиспользованным или игнорировался до 1950 года, когда Плакетт заново открыл оригинальную работу Гаусса с 1821 года. В общем, RLS можно использовать для решения любой проблемы, которая может быть решена с помощью адаптивные фильтры. Например, предположим, что сигнал передается по эху, шумный канал что приводит к его получению как
где представляет собой аддитивный шум. Назначение фильтра RLS - восстановить полезный сигнал. с помощью -нажмите FIR фильтр, :
где это вектор столбца содержащий самые последние образцы . Оценка восстановленного полезного сигнала
Цель - оценить параметры фильтра. , и каждый раз мы называем текущую оценку как и адаптированная оценка методом наименьших квадратов . также вектор-столбец, как показано ниже, а транспонировать, , это вектор строки. В матричный продукт (какой скалярное произведение из и ) является , скаляр. Оценка "хорошо" если небольшой по величине в некоторых наименьших квадратов смысл.
С течением времени желательно избегать полного повторения алгоритма наименьших квадратов, чтобы найти новую оценку для , с точки зрения .
Преимущество алгоритма RLS заключается в том, что нет необходимости инвертировать матрицы, тем самым экономя вычислительные затраты. Еще одно преимущество заключается в том, что он обеспечивает интуитивное понимание таких результатов, как Фильтр Калмана.
Обсуждение
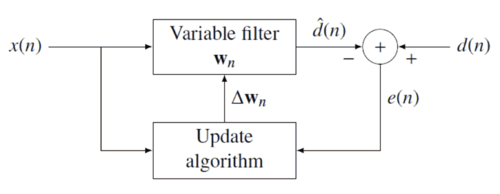
Идея фильтров RLS состоит в том, чтобы минимизировать функция стоимости надлежащим образом подобрав коэффициенты фильтра , обновляя фильтр по мере поступления новых данных. Сигнал ошибки и желаемый сигнал определены в негативный отзыв диаграмма ниже:
Ошибка неявно зависит от коэффициентов фильтра через оценку :
Функция взвешенных наименьших квадратов ошибок - функция затрат, которую мы хотим минимизировать, - являющаяся функцией поэтому также зависит от коэффициентов фильтра:
где это «фактор забвения», который придает экспоненциально меньший вес старым выборкам ошибок.
Функция стоимости минимизируется путем взятия частных производных для всех элементов вектора коэффициентов и обнуление результатов
Далее замените с определением сигнала ошибки
Преобразование уравнения дает
Эту форму можно выразить через матрицы
где взвешенный выборочная ковариация матрица для , и эквивалентная оценка для кросс-ковариация между и . На основе этого выражения находим коэффициенты, которые минимизируют функцию стоимости как
Это главный результат обсуждения.
Выбор
Меньший , тем меньше вклад предыдущих выборок в ковариационную матрицу. Это делает фильтр Больше чувствителен к недавним выборкам, что означает большие колебания коэффициентов фильтра. В дело упоминается как алгоритм растущего окна RLS. На практике, обычно выбирается между 0,98 и 1.[1] Используя оценку максимального правдоподобия типа II, оптимальная можно оценить на основе набора данных.[2]
Рекурсивный алгоритм
Обсуждение привело к единому уравнению для определения вектора коэффициентов, который минимизирует функцию стоимости. В этом разделе мы хотим получить рекурсивное решение вида
где поправочный коэффициент во времени . Мы начинаем вывод рекурсивного алгоритма с выражения кросс-ковариации с точки зрения
где это размерный вектор данных
Аналогично выражаем с точки зрения от
Для генерации вектора коэффициентов нас интересует инверсия детерминированной автоковариационной матрицы. Для этой задачи Тождество матрицы Вудбери пригодится. С участием
Чтобы соответствовать стандартной литературе, мы определяем
где вектор усиления является
Прежде чем двигаться дальше, необходимо принести в другую форму
Вычитание второго члена в левой части дает
С рекурсивным определением желаемая форма следует
Теперь мы готовы завершить рекурсию. Как обсуждалось
Второй шаг следует из рекурсивного определения . Далее мы включаем рекурсивное определение вместе с альтернативной формой и получить
С участием мы приходим к уравнению обновления
где это априори ошибка. Сравните это с апостериорный ошибка; вычисленная ошибка после фильтр обновлен:
Значит, мы нашли поправочный коэффициент
Этот интуитивно удовлетворительный результат показывает, что поправочный коэффициент прямо пропорционален как ошибке, так и вектору усиления, который определяет желаемую чувствительность через весовой коэффициент, .
Резюме алгоритма RLS
Алгоритм RLS для пФильтр RLS -го порядка можно резюмировать как
В Решетка рекурсивных наименьших квадратовадаптивный фильтр относится к стандартному RLS, за исключением того, что требует меньшего количества арифметических операций (порядок N). Он предлагает дополнительные преимущества по сравнению с обычными алгоритмами LMS, такими как более высокая скорость сходимости, модульная структура и нечувствительность к вариациям разброса собственных значений входной корреляционной матрицы. Описанный алгоритм LRLS основан на апостериорный ошибок и включает нормализованную форму. Вывод аналогичен стандартному алгоритму RLS и основан на определении . В случае прямого прогнозирования мы имеем с входным сигналом как самый актуальный образец. Случай обратного предсказания , где i - индекс выборки в прошлом, которую мы хотим спрогнозировать, а входной сигнал это самый последний образец.[4]
Сводка параметров
- коэффициент прямого отражения
коэффициент обратного отражения
представляет собой мгновенный апостериорный ошибка прогнозирования вперед
представляет собой мгновенный апостериорный ошибка обратного предсказания
минимальная ошибка обратного предсказания методом наименьших квадратов
минимальная ошибка прямого прогнозирования методом наименьших квадратов
коэффициент преобразования между априори и апостериорный ошибки
- коэффициенты множителя с прямой связью.
небольшая положительная константа, которая может быть 0,01
Нормализованная форма LRLS имеет меньше рекурсий и переменных. Его можно вычислить, применив нормализацию к внутренним переменным алгоритма, при этом их величина останется ограниченной единицей. Обычно это не используется в приложениях реального времени из-за большого количества операций деления и извлечения квадратного корня, что связано с высокой вычислительной нагрузкой.
^Уэлч, Грег и Бишоп, Гэри "Введение в фильтр Калмана", Департамент компьютерных наук, Университет Северной Каролины в Чапел-Хилл, 17 сентября 1997 г., по состоянию на 19 июля 2011 г.







![{ displaystyle mathbf {x} _ {n} = [x (n) quad x (n-1) quad ldots quad x (n-p)] ^ {T}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/09eb921b307dabe5f3f396085912215d09c02114)

















![sum _ {{i = 0}} ^ {{n}} lambda ^ {{ni}} left [d (i) - sum _ {{l = 0}} ^ {{p}} w_ { {n}} (l) x (il) right] x (ik) = 0 qquad k = 0,1, cdots, p](https://wikimedia.org/api/rest_v1/media/math/render/svg/f227f57b5708e2279ff63386d33c501f76f500b7)
![sum _ {{l = 0}} ^ {{p}} w _ {{n}} (l) left [ sum _ {{i = 0}} ^ {{n}} lambda ^ {{ni }} , x (il) x (ik) right] = sum _ {{i = 0}} ^ {{n}} lambda ^ {{ni}} d (i) x (ik) qquad к = 0,1, cdots, p](https://wikimedia.org/api/rest_v1/media/math/render/svg/43bb38e8f5f1fa0bb012d33ae44308679a9707c2)














![{ mathbf {x}} (i) = [x (i), x (i-1), dots, x (i-p)] ^ {{T}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/dab2ea44a54d82de74ac9f6d26e3f5f6c2a44d8a)













![left [ lambda { mathbf {R}} _ {{x}} (n-1) + { mathbf {x}} (n) { mathbf {x}} ^ {{T}} (n) right] ^ {{- 1}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f12c798517a6c530e616e5915429e3e16370785e)














![= lambda ^ {{- 1}} left [{ mathbf {P}} (n-1) - { mathbf {g}} (n) { mathbf {x}} ^ {{T}} ( n) { mathbf {P}} (n-1) right] { mathbf {x}} (n)](https://wikimedia.org/api/rest_v1/media/math/render/svg/3baaff4ae27f9cfc51e54ada85a9de0999978262)



![= lambda left [ lambda ^ {{- 1}} { mathbf {P}} (n-1) - { mathbf {g}} (n) { mathbf {x}} ^ {{T} } (n) lambda ^ {{- 1}} { mathbf {P}} (n-1) right] { mathbf {r}} _ {{dx}} (n-1) + d (n ) { mathbf {g}} (п)](https://wikimedia.org/api/rest_v1/media/math/render/svg/d1dfdfb80807912183bd47c28d76f65ea9d4c553)

![= { mathbf {P}} (n-1) { mathbf {r}} _ {{dx}} (n-1) + { mathbf {g}} (n) left [d (n) - { mathbf {x}} ^ {{T}} (n) { mathbf {P}} (n-1) { mathbf {r}} _ {{dx}} (n-1) right]](https://wikimedia.org/api/rest_v1/media/math/render/svg/9800c914543c33d7b8ebd7f295efc9fdc51b57e7)

![= { mathbf {w}} _ {{n-1}} + { mathbf {g}} (n) left [d (n) - { mathbf {x}} ^ {{T}} (n ) { mathbf {w}} _ {{n-1}} right]](https://wikimedia.org/api/rest_v1/media/math/render/svg/78ebe76268d69116b2d676aab45f0272977a6df2)














![{ mathbf {x}} (n) = left [{ begin {matrix} x (n) x (n-1) vdots x (np) end {matrix}} right ]](https://wikimedia.org/api/rest_v1/media/math/render/svg/d85a8706d78172d40a299b2bb60ae26b22a21f6c)


















































![overline {e} (k, i + 1) = { frac {1} {{ sqrt {(1- overline {e} _ {b} ^ {2} (k, i)) (1- overline { delta} _ {D} ^ {2} (k, i))}}}} [ overline {e} (k, i) - overline { delta} _ {D} (k, i) overline {e} _ {b} (k, i)]](https://wikimedia.org/api/rest_v1/media/math/render/svg/580293031a5a01b0b256042558d14b8ae206561d)