Параллелизм данных - Data parallelism

Параллелизм данных распараллеливание нескольких процессоры в параллельные вычисления среды. Он фокусируется на распределении данных по разным узлам, которые работают с данными параллельно. Его можно применять к обычным структурам данных, таким как массивы и матрицы, работая с каждым элементом параллельно. Это контрастирует с параллелизм задач как еще одна форма параллелизма.
Работа с параллельными данными в массиве п элементы могут быть разделены поровну между всеми процессорами. Предположим, мы хотим просуммировать все элементы данного массива, а время для одной операции сложения составляет Ta единиц времени. В случае последовательного выполнения время, затрачиваемое на процесс, будет п× Ta единицы времени, так как они суммируют все элементы массива. С другой стороны, если мы выполним это задание как параллельное задание данных на 4 процессорах, затраченное время сократится до (п/ 4) × Ta + объединение единиц времени накладных расходов. Параллельное выполнение приводит к ускорению в 4 раза по сравнению с последовательным выполнением. Следует отметить одну важную вещь: местонахождение ссылок на данные играет важную роль в оценке производительности модели параллельного программирования данных. Локальность данных зависит от обращений к памяти, выполняемых программой, а также от размера кеша.
История
Использование концепции параллелизма данных началось в 1960-х годах с разработкой машины Соломона.[1] Машина Соломона, также называемая векторный процессор, был разработан для ускорения выполнения математических операций за счет работы с большим массивом данных (оперирование несколькими данными в последовательных временных шагах). Параллелизм операций с данными также использовалась при одновременной работе с несколькими данными с использованием одной инструкции. Эти процессоры назывались «процессорами массивов».[2] В 1980-х годах был введен термин [3] чтобы описать этот стиль программирования, который широко использовался для программирования Соединительные машины в параллельных языках данных, таких как C *. Сегодня параллелизм данных лучше всего иллюстрируется графические процессоры (GPU), которые используют как методы работы с множеством данных в пространстве, так и во времени с помощью одной инструкции.
Описание
В многопроцессорной системе, выполняющей один набор инструкций (SIMD ) параллелизм данных достигается, когда каждый процессор выполняет одну и ту же задачу с разными распределенными данными. В некоторых случаях один поток выполнения контролирует операции со всеми данными. В других случаях операцию контролируют разные потоки, но они выполняют один и тот же код.
Например, рассмотрите возможность последовательного умножения и сложения матриц, как описано в примере.
Пример
Ниже приведен последовательный псевдокод для умножения и сложения двух матриц, где результат сохраняется в матрице C. Псевдокод для умножения вычисляет скалярное произведение двух матриц А, B и сохраняет результат в выходной матрице C.
Если бы следующие программы выполнялись последовательно, время, необходимое для вычисления результата, было бы равным (предполагая, что длины строк и столбцов обеих матриц равны n) и для умножения и сложения соответственно.


// Умножение матрицза (я = 0; я < row_length_A; я++){ за (k = 0; k < column_length_B; k++) { сумма = 0; за (j = 0; j < column_length_A; j++) { сумма += А[я][j] * B[j][k]; } C[я][k] = сумма; }}// Добавление массиваза (я = 0; я < п; я++) { c[я] = а[я] + б[я];}Мы можем использовать параллелизм данных в предыдущем коде, чтобы выполнить его быстрее, поскольку арифметика не зависит от цикла. Распараллеливание кода умножения матриц достигается за счет использования OpenMP. Директива OpenMP «omp parallel for» предписывает компилятору выполнять код цикла for параллельно. Для умножения мы можем разделить матрицу A и B на блоки по строкам и столбцам соответственно. Это позволяет нам вычислять каждый элемент в матрице C индивидуально, тем самым делая задачу параллельной. Например: A [m x n] точка B [n x k] можно закончить в вместо при параллельном выполнении с использованием м * к процессоры.

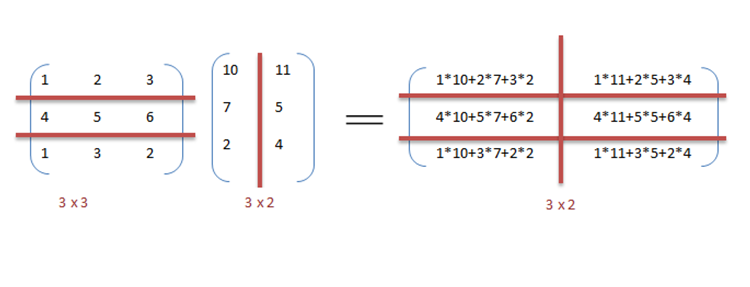
// Параллельное умножение матриц#pragma omp parallel for schedule (dynamic, 1) collapse (2)за (я = 0; я < row_length_A; я++){ за (k = 0; k < column_length_B; k++){ сумма = 0; за (j = 0; j < column_length_A; j++){ сумма += А[я][j] * B[j][k]; } C[я][k] = сумма; }}Из примера видно, что потребуется много процессоров, поскольку размеры матрицы продолжают увеличиваться. Сохранение низкого времени выполнения является приоритетом, но по мере увеличения размера матрицы мы сталкиваемся с другими ограничениями, такими как сложность такой системы и связанные с ней затраты. Таким образом, ограничивая количество процессоров в системе, мы все равно можем применить тот же принцип и разделить данные на большие части для вычисления произведения двух матриц.[4]
Для добавления массивов в параллельной реализации данных предположим более скромную систему с двумя центральные процессоры (ЦП) A и B, ЦП A может добавлять все элементы из верхней половины массивов, а ЦП B может добавлять все элементы из нижней половины массивов. Поскольку два процессора работают параллельно, задача добавления массива займет половину времени выполнения той же операции в последовательном режиме с использованием только одного процессора.
Программа выражена в псевдокод ниже - где применяется произвольная операция, фу, для каждого элемента в массиве d- иллюстрирует параллелизм данных:[nb 1]
если CPU = "а" тогда lower_limit: = 1 upper_limit: = круглый (d.length / 2)иначе если CPU = "b" тогда lower_limit: = round (d.length / 2) + 1 upper_limit: = d.lengthза i от lower_limit до upper_limit на 1 делать foo (d [i])
В СПМД система выполняется на двухпроцессорной системе, оба процессора будут выполнять код.
Параллелизм данных подчеркивает распределенный (параллельный) характер данных, в отличие от обработки (параллелизм задач). Большинство реальных программ находятся где-то в континууме между параллелизмом задач и параллелизмом данных.
Шаги к распараллеливанию
Процесс распараллеливания последовательной программы можно разбить на четыре отдельных шага.[5]
| Тип | Описание |
|---|---|
| Разложение | Программа разбита на задачи, наименьшую возможную единицу согласования. |
| Назначение | Задачи назначаются процессам. |
| Оркестровка | Доступ к данным, связь и синхронизация процессов. |
| Картография | Процессы привязаны к процессорам. |
Параллелизм данных против параллелизма задач
| Параллелизм данных | Параллелизм задач |
|---|---|
| Одни и те же операции выполняются с разными подмножествами одних и тех же данных. | Разные операции выполняются с одними и теми же или разными данными. |
| Синхронное вычисление | Асинхронное вычисление |
| Ускорение больше, поскольку есть только один поток выполнения, работающий со всеми наборами данных. | Ускорение меньше, поскольку каждый процессор будет выполнять свой поток или процесс с одним и тем же или другим набором данных. |
| Объем распараллеливания пропорционален размеру входных данных. | Объем распараллеливания пропорционален количеству независимых задач, которые необходимо выполнить. |
| Разработан для оптимального баланс нагрузки на многопроцессорной системе. | Балансировка нагрузки зависит от доступности оборудования и алгоритмов планирования, таких как статическое и динамическое планирование. |
Параллелизм данных против параллелизма моделей[6]
| Параллелизм данных | Параллелизм моделей |
|---|---|
| Для каждого потока используется одна и та же модель, но данные, передаваемые каждому из них, разделяются и используются совместно. | Для каждого потока используются одни и те же данные, а модель разделяется между потоками. |
| Это быстро для небольших сетей, но очень медленно для больших сетей, так как большие объемы данных должны передаваться между процессорами одновременно. | Это медленно для небольших сетей и быстро для больших сетей. |
| Параллелизм данных идеально используется в вычислениях массивов и матриц, а также в сверточных нейронных сетях. | Параллелизм моделей находит применение в глубоком обучении |
Смешанный параллелизм данных и задач[7]
Параллелизм данных и задач может быть реализован одновременно путем их объединения для одного приложения. Это называется смешанным параллелизмом данных и задач. Смешанный параллелизм требует сложных алгоритмов планирования и поддержки программного обеспечения. Это лучший вариант параллелизма, когда обмен данными медленный и количество процессоров велико.
Смешанный параллелизм данных и задач имеет множество применений. В частности, он используется в следующих приложениях:
- Смешанный параллелизм данных и задач находит применение в моделировании глобального климата. Параллельные вычисления с большими объемами данных выполняются путем создания сеток данных, представляющих земную атмосферу и океаны, а параллелизм задач используется для моделирования функции и модели физических процессов.
- По срокам схемотехническое моделирование. Данные распределяются между различными подсхемами, и параллелизм достигается за счет оркестровки задач.
Среды параллельного программирования данных
Сегодня доступны различные среды параллельного программирования данных, наиболее широко используемые из которых:
- Интерфейс передачи сообщений: Это кроссплатформенный интерфейс программирования передачи сообщений для параллельных компьютеров. Он определяет семантику библиотечных функций, позволяющую пользователям писать переносимые программы передачи сообщений на C, C ++ и Fortran.
- Открытая мультиобработка[8] (Open MP): это интерфейс прикладного программирования (API), который поддерживает Общая память модели программирования на нескольких платформах многопроцессорных систем.
- CUDA и OpenACC: CUDA и OpenACC (соответственно) - это платформы API параллельных вычислений, разработанные, чтобы позволить инженеру-программисту использовать вычислительные блоки GPU для обработки общего назначения.
- Заправка строительных блоков и RaftLib: Обе среды программирования с открытым исходным кодом, которые обеспечивают смешанный параллелизм данных / задач в средах C / C ++ для разнородных ресурсов.
Приложения
Параллелизм данных находит свое применение во множестве областей, от физики, химии, биологии, материаловедения до обработки сигналов. Науки подразумевают параллелизм данных для моделирования таких моделей, как молекулярная динамика,[9] анализ последовательности данных генома [10] и другое физическое явление. Движущими силами обработки сигналов для параллелизма данных являются кодирование видео, обработка изображений и графики, беспроводная связь. [11] назвать несколько.
Смотрите также
- Активное сообщение
- Параллелизм на уровне инструкций
- Масштабируемый параллелизм
- Параллелизм на уровне потоков
- Модель параллельного программирования
Примечания
- ^ Некоторые входные данные (например, когда
d. длинаоценивается в 1 икруглыйокругления до нуля [это всего лишь пример, нет никаких требований относительно того, какой тип округления используется]) приведет кНижний пределбыть больше, чемверхний предел, предполагается, что цикл немедленно завершится (т. е. не произойдет никаких итераций), когда это произойдет.
Рекомендации
- ^ "Компьютер Соломона".
- ^ "SIMD / Vector / GPU" (PDF). Получено 2016-09-07.
- ^ Хиллис, В. Дэниэл и Стил, Гай Л., Параллельные алгоритмы данных Коммуникации ACM Декабрь 1986
- ^ Барни, Блэз. «Введение в параллельные вычисления». computing.llnl.gov. Получено 2016-09-07.
- ^ Солихин, Ян (2016). Основы параллельной архитектуры. Бока-Ратон, Флорида: CRC Press. ISBN 978-1-4822-1118-4.
- ^ «Как распараллелить глубокое обучение на графических процессорах. Часть 2/2: Параллелизм моделей». Тим Деттмерс. 2014-11-09. Получено 2016-09-13.
- ^ "Нетлиб" (PDF).
- ^ "OpenMP.org". openmp.org. Архивировано из оригинал на 2016-09-05. Получено 2016-09-07.
- ^ Boyer, L. L; Поули, Г.С. (1988-10-01). «Молекулярная динамика кластеров частиц, взаимодействующих с парными силами с использованием массивно-параллельного компьютера». Журнал вычислительной физики. 78 (2): 405–423. Bibcode:1988JCoPh..78..405B. Дои:10.1016/0021-9991(88)90057-5.
- ^ Yap, T.K .; Frieder, O .; Мартино, Р.Л. (1998). «Документ IEEE Xplore - Параллельные вычисления в анализе биологической последовательности». Транзакции IEEE в параллельных и распределенных системах. 9 (3): 283–294. CiteSeerX 10.1.1.30.2819. Дои:10.1109/71.674320.
- ^ Singh, H .; Ли, Мин-Хау; Лу, Гуанмин; Kurdahi, F.J .; Багерзаде, Н .; Филхо, Э.М.Чавес (2000-06-01). «MorphoSys: интегрированная реконфигурируемая система для приложений с параллельными данными и интенсивными вычислениями». Транзакции IEEE на компьютерах. 49 (5): 465–481. Дои:10.1109/12.859540. ISSN 0018-9340.
- Хиллис, В. Дэниэл и Стил, Гай Л., Параллельные алгоритмы данных Коммуникации ACM Декабрь 1986
- Блеллох, Гай Э, Векторные модели для параллельных вычислений с данными MIT Press 1990. ISBN 0-262-02313-X
| Общий | |
|---|---|
| Уровни | |
| Многопоточность | |
| Теория | |
| Элементы | |
| Координация | |
| Программирование | |
| Аппаратное обеспечение | |
| API | |
| Проблемы | |
| |