Поиск информации - Information retrieval
Было высказано предположение, что полнотекстовый поиск быть слился в эту статью. (Обсуждать) Предлагается с октября 2020 года. |
Поиск информации (ИК) - деятельность по получению информационная система ресурсы, которые имеют отношение к информационной потребности из набора этих ресурсов. Поиск может быть основан на полный текст или другое индексирование на основе содержания. Информационный поиск - это наука о поиске информации в документе, поиске самих документов, а также поиск метаданные который описывает данные, а также для баз данных текстов, изображений или звуков.
Системы автоматизированного поиска информации используются для уменьшения того, что называлось информационная перегрузка. IR-система - это программная система, которая обеспечивает доступ к книгам, журналам и другим документам; хранит и управляет этими документами. Поисковые системы самые заметные IR приложения.
Обзор
Процесс поиска информации начинается, когда пользователь вводит запрос в систему. Запросы - это формальные утверждения информационных потребностей, например строки поиска в поисковых системах. При поиске информации запрос не может однозначно идентифицировать отдельный объект в коллекции. Вместо этого несколько объектов могут соответствовать запросу, возможно, с разной степенью актуальность.
Объект - это сущность, которая представлена информацией в коллекции контента или база данных. Пользовательские запросы сопоставляются с информацией из базы данных. Однако, в отличие от классических SQL-запросов к базе данных, при поиске информации возвращаемые результаты могут совпадать или не совпадать с запросом, поэтому результаты обычно ранжируются. Этот рейтинг результатов - ключевое отличие поискового поиска информации от поиска в базе данных.[1]
В зависимости от заявление объекты данных могут быть, например, текстовыми документами, изображениями,[2] аудио[3] карты разума[4] или видео. Часто сами документы не хранятся или хранятся непосредственно в IR-системе, а вместо этого представлены в системе суррогатами документов или метаданные.
Большинство IR-систем вычисляют числовую оценку того, насколько хорошо каждый объект в базе данных соответствует запросу, и ранжируют объекты в соответствии с этим значением. Затем пользователю показываются объекты с самым высоким рейтингом. Затем процесс может быть повторен, если пользователь желает уточнить запрос.[5]
История
есть ... машина под названием Univac ... в которой буквы и цифры закодированы как узор из магнитных пятен на длинной стальной ленте. Это означает, что текст документа, которому предшествует символ его предметного кода, может быть записан ... машина ... автоматически выбирает и печатает те ссылки, которые были закодированы любым желаемым способом, со скоростью 120 слов в минуту.
— Дж. Э. Холмстрем, 1948 г.
Идея использования компьютеров для поиска релевантной информации была популяризирована в статье. Как мы можем думать к Ванневар Буш в 1945 г.[6] Похоже, что Буша вдохновили патенты на «статистическую машину», поданные Эмануэль Голдберг в 1920-х и 30-х годах - искали документы, хранящиеся на пленке.[7] Первое описание компьютера, ищущего информацию, было описано Холмстремом в 1948 году.[8] детализируя раннее упоминание о Univac компьютер. Автоматизированные системы поиска информации были представлены в 1950-х годах: одна из них даже использовалась в романтической комедии 1957 года. Настольный набор. В 1960-х годах первая крупная исследовательская группа по поиску информации была сформирована Джерард Солтон в Корнелле. К 1970-м годам было показано, что несколько различных методов поиска хорошо работают на небольших текстовые корпуса например, собрание Крэнфилда (несколько тысяч документов).[6] Крупномасштабные поисковые системы, такие как система Lockheed Dialog, начали использоваться в начале 1970-х годов.
В 1992 г. Министерство обороны США вместе с Национальный институт стандартов и технологий (NIST) выступил одним из спонсоров Конференция по поиску текста (TREC) как часть текстовой программы TIPSTER. Целью этого было изучение сообщества поиска информации путем предоставления инфраструктуры, необходимой для оценки методологий поиска текста на очень большой коллекции текстов. Это послужило катализатором исследования методов, которые шкала к огромным корпусам. Вступление к поисковые системы еще больше повысила потребность в очень крупномасштабных поисковых системах.
Типы моделей
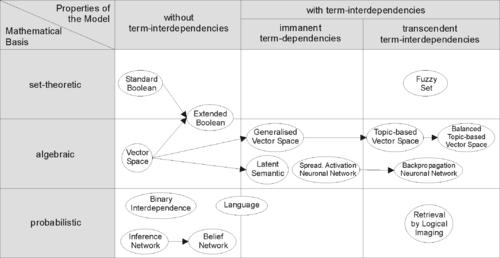
Для эффективного поиска релевантных документов с помощью IR-стратегий документы обычно преобразуются в подходящее представление. Каждая стратегия поиска включает определенную модель для целей представления документа. Картинка справа иллюстрирует взаимосвязь некоторых общих моделей. На рисунке модели разделены на две категории: математическая основа и свойства модели.
Первое измерение: математическая основа
- Теоретико-множественный модели представляют документы как наборы слов или фраз. Сходства обычно выводятся из теоретико-множественных операций с этими множествами. Общие модели:
- Алгебраические модели представляют документы и запросы обычно в виде векторов, матриц или кортежей. Сходство вектора запроса и вектора документа представлено как скалярное значение.
- Вероятностные модели рассматривать процесс поиска документов как вероятностный вывод. Сходства вычисляются как вероятности того, что документ актуален для данного запроса. Вероятностные теоремы типа Теорема Байеса часто используются в этих моделях.
- Модели поиска на основе признаков просматривать документы как векторы значений функции функции (или просто Особенности) и искать лучший способ объединить эти функции в единую оценку релевантности, обычно учиться ранжировать методы. Функциональные функции - это произвольные функции документа и запроса, и как таковые могут легко включать практически любую другую модель поиска как еще одну функцию.
Второе измерение: свойства модели
- Модели без взаимозависимостей терминов рассматривать разные термины / слова как независимые. Этот факт обычно представляется в моделях векторных пространств как ортогональность предположение векторов терминов или в вероятностных моделях независимость предположение для временных переменных.
- Модели с имманентными временными взаимозависимостями позволяют представить взаимозависимости между терминами. Однако степень взаимозависимости между двумя терминами определяется самой моделью. Обычно он прямо или косвенно получен (например, уменьшение размеров ) от совпадение этих условий во всем комплекте документов.
- Модели с трансцендентной взаимозависимостью терминов позволяют представить взаимозависимости между терминами, но они не утверждают, как определяется взаимозависимость между двумя терминами. Они полагаются на внешний источник степени взаимозависимости между двумя терминами. (Например, человек или сложные алгоритмы.)
Показатели производительности и корректности
Оценка информационно-поисковой системы - это процесс оценки того, насколько хорошо система удовлетворяет информационные потребности своих пользователей. Как правило, измерение рассматривает набор документов, в которых выполняется поиск, и поисковый запрос. Традиционные показатели оценки, предназначенные для Логическое извлечение[требуется разъяснение ] или поиск топ-k, включая точность и отзыв. Все меры предполагают наземная правда понятие релевантности: известно, что каждый документ либо релевантен, либо не имеет отношения к определенному запросу. На практике запросы могут быть некорректно и могут быть разные оттенки актуальности.
График
- Перед 1900-е годы
- 1801: Жозеф Мари Жаккард изобретает Жаккардовый ткацкий станок, первая машина, использующая перфокарты для управления последовательностью операций.
- 1880-е годы: Герман Холлерит изобретает электромеханический табулятор данных, использующий перфокарты в качестве машиночитаемого носителя.
- 1890 Холлерит открытки, нажатия клавиш и табуляторы используется для обработки Перепись населения США 1890 г. данные.
- 1920-1930-е гг.
- Эмануэль Голдберг подает патенты на свою «Статистическую машину» - поисковую машину, которая использовала фотоэлементы и распознавание образов для поиска метаданных на рулонах микрофильмированных документов.
- 1940–1950 годы
- конец 1940-х: Военные США столкнулись с проблемами индексации и поиска документов военных исследований, захваченных у немцев.
- 1945: Ванневар Буш с Как мы можем думать появился в Atlantic Monthly.
- 1947: Ханс Петер Лун (инженер-исследователь в IBM с 1941 г.) начал работу над механизированной системой поиска химических соединений на основе перфокарт.
- 1950-е годы: Растущее беспокойство в США по поводу «научного разрыва» с СССР мотивировало, поощряло финансирование и обеспечивало фон для механизированных систем поиска литературы (Аллен Кент и другие.) и изобретение индексации цитирования (Юджин Гарфилд ).
- 1950: Термин «поиск информации» был придуман Кэлвин Мурс.[9]
- 1951: Филип Бэгли провел самый ранний эксперимент по компьютеризированному поиску документов в магистерской диссертации в Массачусетский технологический институт.[10]
- 1955: Аллен Кент присоединился Кейс Вестерн Резервный университет, и в конце концов стал заместителем директора Центра документации и коммуникаций. В том же году Кент и его коллеги опубликовали статью в American Documentation, описывающую меры точности и отзыва, а также детализирующую предлагаемую «структуру» для оценки IR-системы, которая включала методы статистической выборки для определения количества релевантных документов, не найденных.[11]
- 1958: Международная конференция по научной информации в Вашингтоне, округ Колумбия, рассмотрела ИК-системы как решение выявленных проблем. Видеть: Труды Международной конференции по научной информации, 1958 г. (Национальная академия наук, Вашингтон, округ Колумбия, 1959 г.)
- 1959: Ханс Петер Лун опубликовал «Автокодирование документов для поиска информации».
- конец 1940-х: Военные США столкнулись с проблемами индексации и поиска документов военных исследований, захваченных у немцев.
- 1960-е:
- начало 1960-х: Джерард Солтон начал работать над IR в Гарварде, позже переехал в Корнелл.
- 1960: Мелвин Эрл Марон и Джон Лэри Кунс[12] опубликовал «О релевантности, вероятностном индексировании и поиске информации» в журнале ACM 7 (3): 216–244, июль 1960.
- 1962:
- Сирил В. Клевердон опубликовал первые результаты исследований Крэнфилда, разработав модель для оценки системы IR. См .: Сирил В. Клевердон, «Отчет о тестировании и анализе исследования сравнительной эффективности систем индексации». Cranfield Collection of Aeronautics, Крэнфилд, Англия, 1962 год.
- Кент опубликовал Информационный анализ и поиск.
- 1963:
- В докладе Вайнберга «Наука, правительство и информация» полностью сформулирована идея «кризиса научной информации». Отчет был назван в честь доктора В. Элвин Вайнберг.
- Джозеф Беккер и Роберт М. Хейз опубликованный текст по поиску информации. Беккер, Джозеф; Хейс, Роберт Мэйо. Хранение и поиск информации: инструменты, элементы, теории. Нью-Йорк, Вили (1963).
- 1964:
- Карен Спарк Джонс защитила диссертацию в Кембридже, Синонимия и семантическая классификация, и продолжил работу над компьютерная лингвистика как это относится к IR.
- В Национальное бюро стандартов спонсировал симпозиум под названием «Методы статистической ассоциации для механизированной документации». Несколько очень важных работ, в том числе первая опубликованная ссылка (как мы полагаем) Г. Солтоном на УМНАЯ система.
- середина 1960-х:
- Национальная медицинская библиотека разработана MEDLARS Система анализа и поиска медицинской литературы, первая крупная машиночитаемая база данных и система пакетного поиска.
- Проект Intrex в Массачусетском технологическом институте.
- 1965: Дж. К. Р. Ликлайдер опубликовано Библиотеки будущего.
- 1966: Дон Суонсон принимал участие в исследованиях в Чикагском университете по требованиям к будущим каталогам.
- конец 1960-х: Ф. Уилфрид Ланкастер завершил оценочные исследования системы MEDLARS и опубликовал первое издание своего текста по поиску информации.
- 1968:
- Джерард Солтон опубликовал Автоматическая организация и поиск информации.
- В отчете RADC Tech Джона В. Сэммона младшего «Некоторые математические аспекты хранения и поиска информации ...» описана векторная модель.
- 1969: Sammon's "Нелинейное отображение для анализа структуры данных «(IEEE Transactions on Computers)» было первым предложением по интерфейсу визуализации для IR-системы.
- 1970-е годы
- начало 1970-х:
- Первые онлайн-системы - NLM AIM-TWX, MEDLINE; Lockheed's Dialog; ОРБИТА SDC.
- Теодор Нельсон продвижение концепции гипертекст, опубликовано Компьютерная либ / машины мечты.
- 1971: Николас Жардин и Корнелис Дж. Ван Рейсберген опубликовано "Использование иерархическая кластеризация в информационном поиске », в которой сформулирована« кластерная гипотеза ».[13]
- 1975: Три очень влиятельных публикации Солтона полностью сформулировали его структуру векторной обработки и термин дискриминация модель:
- 1978: Первый ACM СИГИР конференция.
- 1979: C. J. van Rijsbergen опубликовано Поиск информации (Баттервортс). Большой упор на вероятностные модели.
- 1979: Тамаш Дошкоц внедрил CITE пользовательский интерфейс на естественном языке для MEDLINE в Национальной медицинской библиотеке. Система CITE поддерживает ввод запроса в произвольной форме, ранжированный вывод и обратную связь по релевантности.[14]
- начало 1970-х:
- 1980-е
- 1980: Первая международная конференция ACM SIGIR, совместно с IR-группой Британского компьютерного общества в Кембридже.
- 1982: Николай Дж. Белкин, Роберт Н. Одди и Хелен М. Брукс предложили точку зрения ASK (аномальное состояние знаний) для поиска информации. Это была важная концепция, хотя их инструмент автоматического анализа в конечном итоге разочаровал.
- 1983: Солтон (и Майкл Дж. МакГилл) опубликовал Введение в современный поиск информации (МакГроу-Хилл) с упором на векторные модели.
- 1985: Дэвид Блер и Билл Марон publish: оценка эффективности поиска для системы поиска полнотекстовых документов
- середина 1980-х: Усилия по разработке версий коммерческих IR-систем для конечных пользователей.
- 1985–1993: Ключевые статьи и экспериментальные системы для визуализации интерфейсов.
- Работа Дональд Б. Крауч, Роберт Р. Корфхаге, Мэтью Чалмерс, Ансельм Спёрри и другие.
- 1989: Первый Всемирная паутина предложения от Тим Бернерс-Ли в ЦЕРН.
- 1990-е годы
- 1992: Первый TREC конференция.
- 1997: Публикация Корфхаге с Хранение и поиск информации[15] с упором на визуализацию и системы с несколькими опорными точками.
- 1999: Публикация Рикардо Баеза-Йейтс и Бертье Рибейро-Нето Современный информационный поиск Аддисон Уэсли, первая книга, которая пытается охватить все IR.
- конец 1990-х: Поисковые системы реализация многих функций, ранее существовавших только в экспериментальных ИК-системах. Поисковые системы становятся наиболее распространенным и, возможно, лучшим экземпляром IR-моделей.
Основные конференции
- СИГИР: Конференция по исследованиям и разработкам в области информационного поиска
- ECIR: Европейская конференция по поиску информации
- CIKM: Конференция по управлению информацией и знаниями
- WWW: Международная конференция по всемирной паутине
- WSDM: Конференция по веб-поиску и интеллектуальному анализу данных
- ICTIR: Международная конференция по теории информационного поиска
Награды в области
Смотрите также
- Получение состязательной информации - Стратегии поиска информации в наборах данных
- Совместный поиск информации
- Память компьютера - Устройство, используемое на компьютере для хранения данных
- Контролируемый словарный запас
- Поиск информации на разных языках
- Сбор данных - Поиск закономерностей в больших наборах данных с помощью сложных вычислительных методов
- Европейская летняя школа по информационному поиску
- Человеко-компьютерный поиск информации (HCIR)
- Извлечение информации - Автоматическое извлечение структурированной информации из неструктурированных или полуструктурированных машиночитаемых документов, например текстов на человеческом языке
- Средство поиска информации
- Визуализация знаний
- Поиск мультимедийной информации
- Управление личной информацией
- Актуальность (информационный поиск)
- Отзыв о релевантности
- Классификация роккио
- Индексирование поисковой системой
- Поиск социальной информации
- Специальная группа по поиску информации
- Индексирование тем
- Поиск временной информации
- tf – idf - (частота термина - обратная частота документа) числовая статистика, предназначенная для отражения важности слова для документа в коллекции или корпусах текста
- Получение XML
- Веб-майнинг
Рекомендации
- ^ Янсен, Б. Дж. И Рие, С. (2010) Семнадцать теоретических конструкций информационного поиска и информационного поиска В архиве 2016-03-04 в Wayback Machine. Журнал Американского общества информационных наук и технологий. 61 (8), 1517-1534.
- ^ Гудрам, Эбби А. (2000). «Поиск информации об изображении: обзор текущих исследований». Информирование науки. 3 (2).
- ^ Фут, Джонатан (1999). «Обзор поиска аудиоинформации». Мультимедийные системы. 7: 2–10. CiteSeerX 10.1.1.39.6339. Дои:10.1007 / s005300050106. S2CID 2000641.
- ^ Бил, Йоран; Гипп, Бела; Стиллер, Ян-Олаф (2009). Поиск информации на ментальных картах - для чего он нужен?. Труды 5-й Международной конференции по совместным вычислениям: сети, приложения и совместная работа (CollaborateCom'09). Вашингтон, округ Колумбия: IEEE. Архивировано из оригинал на 2011-05-13. Получено 2012-03-13.
- ^ Фрейкс, Уильям Б.; Баеза-Йейтс, Рикардо (1992). Структуры и алгоритмы информационного поиска. Prentice-Hall, Inc. ISBN 978-0-13-463837-9. Архивировано из оригинал на 2013-09-28.
- ^ а б Сингхал, Амит (2001). «Современный поиск информации: краткий обзор» (PDF). Бюллетень Технического комитета компьютерного общества IEEE по инженерии данных. 24 (4): 35–43.
- ^ Марк Сандерсон и В. Брюс Крофт (2012). «История поисковиков». Труды IEEE. 100: 1444–1451. Дои:10.1109 / jproc.2012.2189916.
- ^ Дж. Э. Холмстрем (1948). "'Раздел III. Открытие пленарного заседания ». Конференция по научной информации Королевского общества, 21 июня - 2 июля 1948 г .: отчет и документы представлены: 85.
- ^ Mooers, Calvin N .; Теория цифровой обработки нечисловой информации и ее значение для экономики машин (Технический бюллетень Zator № 48), цитируется в Фэрторн, Р. А. (1958). «Автоматический поиск записанной информации». Компьютерный журнал. 1 (1): 37. Дои:10.1093 / comjnl / 1.1.36.
- ^ Дойл, Лорен; Беккер, Джозеф (1975). Поиск и обработка информации. Мелвилл. стр.410 с. ISBN 978-0-471-22151-7.
- ^ Перри, Джеймс У .; Кент, Аллен; Берри, Мэдлин М. (1955). «Машинный поиск литературы X. Машинный язык; факторы, лежащие в основе его проектирования и развития». Американская документация. 6 (4): 242–254. Дои:10.1002 / asi.5090060411.
- ^ Марон, Мелвин Э. (2008). «Историческая справка об истоках вероятностного индексирования» (PDF). Обработка информации и управление. 44 (2): 971–972. Дои:10.1016 / j.ipm.2007.02.012.
- ^ Н. Жардин, К.Дж. ван Рейсберген (декабрь 1971 г.). «Использование иерархической кластеризации при поиске информации». Хранение и поиск информации. 7 (5): 217–240. Дои:10.1016/0020-0271(71)90051-9.
- ^ Doszkocs, T.E. И Рапп, Б.А. (1979). «Поиск в MEDLINE на английском языке: прототип пользовательского интерфейса с запросом на естественном языке, ранжированным выводом и обратной связью по релевантности», В: Proceedings of the ASIS Annual Meeting, 16: 131-139.
- ^ Корфхаге, Роберт Р. (1997). Хранение и поиск информации. Вайли. стр.368 стр.. ISBN 978-0-471-14338-3.
дальнейшее чтение
- Рикардо Баеза-Йейтс, Бертье Рибейро-Нето. Современный информационный поиск: концепции и технологии поиска (второе издание). Аддисон-Уэсли, Великобритания, 2011 г.
- Стефан Бюттчер, Чарльз Л. А. Кларк и Гордон В. Кормак. Поиск информации: внедрение и оценка поисковых систем. MIT Press, Кембридж, Массачусетс, 2010 г.
- «Информационно-поисковая система». Библиотечно-информационная сеть. 24 апреля 2015 г.
- Кристофер Д. Мэннинг, Прабхакар Рагхаван и Хинрих Шютце. Введение в поиск информации. Издательство Кембриджского университета, 2008.
внешняя ссылка
- ACM SIGIR: Специальная группа по поиску информации
- BCS IRSG: Британское компьютерное общество - Группа специалистов по поиску информации
- Конференция по поиску текста (TREC)
- Форум по оценке поиска информации (FIRE)
- Поиск информации (электронная книга) К. Дж. Ван Рейсберген
- Информационный поиск вики
- Средство поиска информации
- Получение информации @ DUTH
- Отчет TREC о методах оценки информационного поиска
- Как eBay измеряет релевантность поиска
- Инструмент оценки эффективности информационного поиска @ Athena Research Center
| Авторитетный контроль |
|---|