Алгоритм Rete - Rete algorithm
эта статья нужны дополнительные цитаты для проверка. (Март 2018 г.) (Узнайте, как и когда удалить этот шаблон сообщения) |
В Алгоритм Rete (/ˈрятя/ REE-ти, /ˈрeɪтя/ РЭЙ-ти, редко /ˈрят/ REET, /рɛˈтeɪ/ пере-ВРЕМЯ ) это сопоставление с образцом алгоритм для реализации системы на основе правил. Алгоритм был разработан для эффективного применения многих правила или шаблоны для многих объектов, или факты, в база знаний. Он используется для определения того, какое из правил системы должно срабатывать, на основе его хранилища данных, его фактов. Алгоритм Рете был разработан Чарльз Л. Форги из Университет Карнеги Меллон, впервые опубликованный в рабочем документе в 1974 году, а затем развитый в его докторской диссертации 1979 года. диссертация и статья 1982 г. [1].
Обзор
А наивная реализация из экспертная система может проверить каждый правило против известных факты в база знаний, при необходимости активируя это правило, затем переходя к следующему правилу (и возвращаясь к первому правилу по завершении). Даже для баз знаний правил и фактов среднего размера этот наивный подход работает слишком медленно. Алгоритм Rete обеспечивает основу для более эффективной реализации. Экспертная система на основе Rete создает сеть узлы, где каждый узел (кроме корня) соответствует шаблону, встречающемуся в левой части (части условия) правила. Путь от корневой узел к листовой узел определяет полное правило слева. Каждый узел имеет память о фактах, которые удовлетворяют этому шаблону. Эта структура по сути является обобщенным три. По мере утверждения или изменения новых фактов они распространяются по сети, заставляя узлы аннотироваться, когда этот факт соответствует этому шаблону. Когда факт или комбинация фактов приводят к тому, что все шаблоны для данного правила удовлетворяются, достигается конечный узел и срабатывает соответствующее правило.
Rete был впервые использован в качестве основного двигателя OPS5 язык производственной системы, который использовался для создания ранних систем, включая R1 для Digital Equipment Corporation. Rete стал основой для многих популярных движков правил и оболочек экспертных систем, включая Tibco Деловые мероприятия, Newgen OmniRules, КЛИПЫ, Джесс, Слюни, IBM Operational Decision Management, OPSJ, советник по Blaze, BizTalk Механизм правил, Парить, Клара и Sparkling Logic SMARTS. Слово «Rete» на латыни означает «сеть» или «гребешок». Это же слово используется в современном итальянском языке для обозначения сеть. Чарльз Форги, как сообщается, заявил, что он принял термин «рете» из-за его использования в анатомии для описания сети кровеносных сосудов и нервных волокон.[2]
Алгоритм Rete предназначен для жертв объем памяти для увеличения скорости. В большинстве случаев увеличение скорости по сравнению с простыми реализациями составляет несколько порядков (поскольку производительность Rete теоретически не зависит от количества правил в системе). Однако в очень больших экспертных системах оригинальный алгоритм Рете имеет тенденцию сталкиваться с проблемами потребления памяти и сервера. С тех пор были разработаны другие алгоритмы, как новые, так и основанные на Rete, которые требуют меньше памяти (например, Rete *[3] или подбор, ориентированный на подборку[4]).
Описание
Алгоритм Рете предоставляет обобщенное логическое описание реализации функциональности, отвечающей за сопоставление данных. кортежи ("факты") против производства ("правила ") в производственной системе сопоставления с образцом (категория механизм правил ). Производство состоит из одного или нескольких условий и набора действий, которые могут быть предприняты для каждого полного набора фактов, соответствующих условиям. Условия проверки факт атрибуты, включая спецификаторы / идентификаторы типов фактов. Алгоритм Рете имеет следующие основные характеристики:
- Это уменьшает или устраняет определенные типы избыточности за счет использования совместного использования узлов.
- Он сохраняет частичные совпадения при выполнении присоединяется между разными типами фактов. Это, в свою очередь, позволяет производственным системам избежать полной переоценки всех фактов каждый раз, когда в рабочую память производственной системы вносятся изменения. Вместо этого производственной системе нужно только оценить изменения (дельты) рабочей памяти.
- Это позволяет эффективно удалять элементы памяти, когда факты удаляются из рабочей памяти.
Алгоритм Rete широко используется для реализации функций сопоставления в механизмах сопоставления с образцом, которые используют цикл сопоставление-разрешение-действие для поддержки прямая цепочка и вывод.
- Он предоставляет средства для сопоставления многих-многих, что является важной функцией, когда необходимо найти множество или все возможные решения в поисковой сети.
Retes ориентированные ациклические графы которые представляют наборы правил более высокого уровня. Обычно они представляются во время выполнения с помощью сети объектов в памяти. Эти сети сопоставляют условия правил (шаблоны) с фактами (кортежами реляционных данных). Сети Rete выступают в роли обработчика реляционных запросов, выполняющего прогнозы, выбор и присоединяется условно к произвольному количеству кортежей данных.
Производство (правила) обычно фиксируются и определяются аналитики и Разработчики используя некоторый язык правил высокого уровня. Они собираются в наборы правил, которые затем транслируются, часто во время выполнения, в исполняемый файл Rete.
Когда факты «утверждаются» в рабочей памяти, движок создает элементы рабочей памяти (WME) за каждый факт. Факты представляют собой кортежи из n элементов и поэтому могут содержать произвольное количество элементов данных. Каждый WME может содержать полный набор из n или, альтернативно, каждый факт может быть представлен набором WME, где каждый WME содержит кортеж фиксированной длины. В этом случае кортежи обычно являются тройками (3-кортежами).
Каждый WME входит в сеть Rete через единственный корневой узел. Корневой узел передает каждый WME своим дочерним узлам, и каждый WME может затем распространяться по сети, возможно, сохраняться в промежуточных запоминающих устройствах, пока он не достигнет конечного узла.
Альфа-сеть
Слева" (альфа) сторона графа узлов формирует сеть различения, отвечающую за выбор отдельных WME на основе простых условных тестов, которые сопоставляют атрибуты WME с постоянными значениями. Узлы в сети распознавания также могут выполнять тесты, сравнивающие два или более атрибутов одного и того же WME. Если WME успешно сопоставляется с условиями, представленными одним узлом, он передается следующему узлу. В большинстве движков непосредственные дочерние узлы корневого узла используются для проверки идентификатора объекта или типа факта каждого WME. Следовательно, все WME, представляющие одинаковые организация type обычно проходят заданную ветвь узлов в сети распознавания.
Внутри сети распознавания каждая ветвь альфа-узлов (также называемых узлами с 1 входом) заканчивается в памяти, называемой альфа-память. В этих воспоминаниях хранятся коллекции WME, которые соответствуют каждому условию в каждом узле в данной ветви узла. WME, которые не соответствуют хотя бы одному условию в ветви, не материализуются в соответствующей альфа-памяти. Ветви альфа-узла могут разветвляться, чтобы минимизировать избыточность условий.
Бета-сеть
Право" (бета) сторона графа в основном выполняет соединения между различными WME. Это необязательно и включается только при необходимости. Он состоит из узлов с двумя входами, каждый из которых имеет «левый» и «правый» вход. Каждый бета-узел отправляет свой вывод в бета-память.
В описаниях Rete обычно упоминается передача токенов в бета-сети. В этой статье, однако, мы будем описывать распространение данных в терминах списков WME, а не токенов, с учетом различных вариантов реализации, а также основной цели и использования токенов. Когда любой список WME проходит через бета-сеть, к нему могут добавляться новые WME, и этот список может храниться в бета-памяти. Список WME в бета-памяти представляет собой частичное соответствие условиям в данном производстве.
Списки WME, которые достигают конца ветви бета-узлов, представляют собой полное соответствие для одного продукта и передаются конечным узлам. Эти узлы иногда называют p-узлы, где "p" означает производство. Каждый конечный узел представляет собой отдельное производство, и каждый список WME, поступающий на конечный узел, представляет собой полный набор соответствующих WME для условий в этом производстве. Для каждого полученного списка WME производственный узел «активирует» новый производственный экземпляр в «повестке дня». Повестки дня обычно реализуются как приоритетные очереди.
Бета-узлы обычно выполняют соединения между списками WME, хранящимися в бета-памяти, и отдельными WME, хранящимися в альфа-памяти. Каждый бета-узел связан с двумя входными памятью. Альфа-память хранит WM и выполняет «правильные» активации на бета-узле каждый раз, когда сохраняет новый WME. Бета-память хранит списки WME и выполняет «левые» активации на бета-узле каждый раз, когда сохраняет новый список WME. Когда узел соединения активирован правой кнопкой мыши, он сравнивает один или несколько атрибутов вновь сохраненного WME из своей входной альфа-памяти с заданными атрибутами конкретных WME в каждом списке WME, содержащемся во входной бета-памяти. Когда узел соединения остается активированным, он просматривает единственный недавно сохраненный список WME в бета-памяти, извлекая определенные значения атрибутов данных WME. Он сравнивает эти значения со значениями атрибутов каждого WME в альфа-памяти.
Каждый бета-узел выводит списки WME, которые либо хранятся в бета-памяти, либо отправляются непосредственно на конечный узел. Списки WME хранятся в бета-памяти всякий раз, когда движок будет выполнять дополнительные левые активации на последующих бета-узлах.
Логично, что бета-узел во главе ветви бета-узлов является особым случаем, потому что он не принимает входных данных из какой-либо бета-памяти выше в сети. Разные движки решают эту проблему по-разному. Некоторые движки используют специализированные узлы-адаптеры для подключения альфа-памяти к левому входу бета-узлов. Другие механизмы позволяют бета-узлам принимать входные данные непосредственно из двух альфа-памяти, рассматривая один как «левый» вход, а другой как «правый». В обоих случаях «головные» бета-узлы получают данные от двух альфа-воспоминаний.
Чтобы исключить избыточность узлов, можно использовать любую альфа- или бета-память для выполнения активаций на нескольких бета-узлах. Помимо узлов присоединения, бета-сеть может содержать дополнительные типы узлов, некоторые из которых описаны ниже. Если Rete не содержит бета-сети, альфа-узлы подают токены, каждый из которых содержит один WME, непосредственно в p-узлы. В этом случае, возможно, нет необходимости хранить WME в альфа-памяти.
Решение конфликта
В течение любого одного цикла сопоставление-разрешение-действие механизм найдет все возможные совпадения для фактов, которые в настоящее время утверждены в рабочей памяти. После того, как все текущие совпадения были найдены и соответствующие производственные экземпляры были активированы в повестке дня, механизм определяет порядок, в котором производственные экземпляры могут быть «запущены». Это называется Решение конфликта, а список активированных производственных экземпляров называется набор конфликтов. Порядок может быть основан на приоритете правила (заметность), порядок правил, время, в которое факты, содержащиеся в каждом экземпляре, были записаны в рабочую память, сложность каждой продукции или некоторые другие критерии. Многие механизмы позволяют разработчикам правил выбирать между различными стратегиями разрешения конфликтов или объединять в цепочку выбор из нескольких стратегий.
Разрешение конфликтов не определяется как часть алгоритма Rete, но используется вместе с алгоритмом. Некоторые специализированные производственные системы не выполняют разрешение конфликтов.
Производство продукции
Выполнив разрешение конфликтов, движок теперь «запускает» первый рабочий экземпляр, выполняя список действий, связанных с производством. Действия воздействуют на данные, представленные списком WME производственного экземпляра.
По умолчанию движок будет продолжать запускать каждый производственный экземпляр по порядку, пока все производственные экземпляры не будут запущены. Каждый производственный экземпляр будет срабатывать не более одного раза в течение одного цикла матч-решение-действие. Эта характеристика называется преломление. Однако последовательность запусков производственных экземпляров может быть прервана на любом этапе путем внесения изменений в рабочую память. Действия правил могут содержать инструкции для утверждения или удаления WME из рабочей памяти движка. Каждый раз, когда какой-либо отдельный производственный экземпляр выполняет одно или несколько таких изменений, движок немедленно переходит в новый цикл сопоставления-разрешения-действия. Это включает «обновления» WME, которые в настоящее время находятся в рабочей памяти. Обновления представлены отзывом и повторным подтверждением WME. Механизм выполняет сопоставление измененных данных, что, в свою очередь, может привести к изменению списка производственных экземпляров в повестке дня. Следовательно, после того, как действия для любого конкретного производственного экземпляра были выполнены, ранее активированные экземпляры могли быть деактивированы и удалены из повестки дня, а новые экземпляры могли быть активированы.
В рамках нового цикла сопоставления-разрешения-действия механизм выполняет разрешение конфликта в повестке дня, а затем выполняет текущий первый экземпляр. Движок продолжает запускать производственные экземпляры и входить в новые циклы сопоставления-разрешения-действия до тех пор, пока в повестке дня не исчезнут другие производственные экземпляры. На этом этапе считается, что механизм правил завершил свою работу и останавливается.
Некоторые двигатели поддерживают расширенные стратегии преломления, в которых определенные производственные экземпляры, выполненные в предыдущем цикле, не выполняются повторно в новом цикле, даже если они все еще могут присутствовать в повестке дня.
Двигатель может войти в бесконечные циклы, в которых повестка дня никогда не достигает пустого состояния. По этой причине большинство движков поддерживают явные команды "остановки", которые можно вызывать из списков производственных действий. Они также могут предоставлять автоматические обнаружение петли в котором нескончаемые циклы автоматически останавливаются после заданного количества итераций. Некоторые механизмы поддерживают модель, в которой вместо остановки, когда повестка дня пуста, машина переходит в состояние ожидания, пока новые факты не будут утверждены извне.
Что касается разрешения конфликтов, запуск активированных производственных экземпляров не является функцией алгоритма Rete. Однако это центральная особенность машин, использующих сети Rete. Некоторые из оптимизаций, предлагаемых сетями Rete, полезны только в сценариях, когда механизм выполняет несколько циклов сопоставления-разрешения-действия.
Экзистенциальные и универсальные количественные оценки
Условные тесты чаще всего используются для выполнения выборки и объединения отдельных кортежей. Однако, реализовав дополнительные типы бета-узлов, сети Rete могут выполнять количественные оценки. Экзистенциальная количественная оценка включает проверку наличия хотя бы одного набора совпадающих WME в рабочей памяти. Универсальная количественная оценка включает в себя проверку того, что весь набор WME в рабочей памяти соответствует заданному условию. Вариант универсальной количественной оценки может проверить, что данное количество WME, взятых из набора WME, соответствует заданным критериям. Это может быть с точки зрения тестирования точного или минимального количества совпадений.
Количественная оценка не повсеместно реализована в движках Rete, и там, где она поддерживается, существует несколько вариантов. Вариант экзистенциальной количественной оценки, называемый отрицание широко, хотя и не повсеместно, поддерживается и описывается в основополагающих документах. Экзистенциально отрицаемые условия и конъюнкции включают использование специализированных бета-узлов, которые проверяют отсутствие соответствующих WME или наборов WME. Эти узлы распространяют списки WME только тогда, когда совпадений не найдено. Точная реализация отрицания варьируется. В одном из подходов узел поддерживает простой подсчет каждого списка WME, который он получает от своего левого входа. Счетчик определяет количество совпадений, найденных с WME, полученными от правого входа. Узел распространяет только списки WME, количество которых равно нулю. В другом подходе узел поддерживает дополнительную память в каждом списке WME, полученном от левого входа. Эти воспоминания представляют собой форму бета-памяти и хранят списки WME для каждого матча с WME, полученными на правом входе. Если список WME не имеет списков WME в своей памяти, он распространяется по сети. В этом подходе узлы отрицания обычно активируют дополнительные бета-узлы напрямую, а не сохраняют их вывод в дополнительной бета-памяти. Узлы отрицания представляют собой форму 'отрицание как неудача '.
Когда в рабочую память вносятся изменения, список WME, который ранее не соответствовал никаким WME, теперь может соответствовать вновь заявленным WME. В этом случае распространенный список WME и все его расширенные копии необходимо отозвать из бета-памяти дальше по сети. Второй подход, описанный выше, часто используется для поддержки эффективных механизмов удаления списков WME. При удалении списков WME все соответствующие производственные экземпляры деактивируются и удаляются из повестки дня.
Количественная оценка существования может быть выполнена путем объединения двух бета-узлов отрицания. Это представляет семантику двойное отрицание (например, «Если НЕ подходящие WME, то ...»). Это общий подход, используемый несколькими производственными системами.
Индексирование памяти
Алгоритм Rete не требует какого-либо конкретного подхода к индексации рабочей памяти. Однако большинство современных производственных систем предоставляют механизмы индексации. В некоторых случаях индексируется только бета-память, в то время как в других индексация используется как для альфа-, так и для бета-памяти. Хорошая стратегия индексирования является основным фактором при определении общей производительности производственной системы, особенно при выполнении наборов правил, которые приводят к высоко комбинаторному сопоставлению с образцом (т. Е. Интенсивному использованию узлов бета-соединения) или, для некоторых механизмов, при выполнении правил наборы, которые выполняют значительное количество отозваний WME в течение нескольких циклов матч-решение-действие. Воспоминания часто реализуются с использованием комбинаций хеш-таблиц, а хеш-значения используются для выполнения условных соединений для подмножеств списков WME и WME, а не для всего содержимого памяти. Это, в свою очередь, часто значительно сокращает количество оценок, выполняемых сетью Rete.
Удаление WME и списков WME
Когда WME удаляется из рабочей памяти, он должен быть удален из каждой альфа-памяти, в которой он хранится. Кроме того, списки WME, содержащие WME, должны быть удалены из бета-памяти, а активированные производственные экземпляры для этих списков WME должны быть деактивированы и удалены из повестки дня. Существует несколько вариантов реализации, включая удаление на основе дерева и на основе повторного сопоставления. В некоторых случаях для оптимизации удаления может использоваться индексация памяти.
Обработка условий ORed
При определении продукции в наборе правил обычно разрешается группировать условия с помощью оператора ИЛИ. соединительный. Во многих производственных системах это обрабатывается путем интерпретации одной продукции, содержащей несколько шаблонов с оператором OR, как эквивалента нескольких производств. Результирующая сеть Rete содержит наборы конечных узлов, которые вместе представляют отдельные производства. Такой подход запрещает любую форму короткого замыкания условий ORed. В некоторых случаях это также может привести к тому, что в повестке дня будут активированы дублирующиеся производственные экземпляры, когда один и тот же набор WME соответствует нескольким внутренним производствам. Некоторые движки обеспечивают дедупликацию повестки дня для решения этой проблемы.
Диаграмма
Следующая диаграмма иллюстрирует базовую топографию Rete и показывает связи между различными типами узлов и памятью.
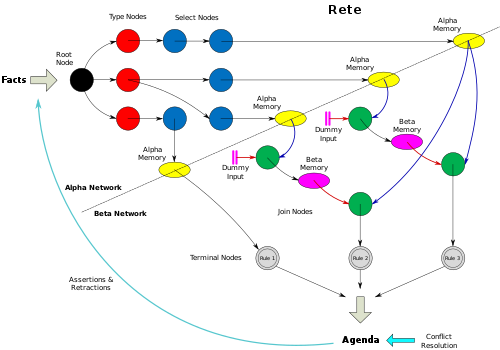
- Большинство реализаций используют узлы типов для выполнения первого уровня выбора элементов рабочей памяти из n кортежей. Узлы типа можно рассматривать как специализированные узлы выбора. Они различают разные типы кортежных отношений.
- Схема не иллюстрирует использование специализированных типов узлов, таких как узлы отрицательного соединения. Некоторые движки реализуют несколько различных специализаций узлов, чтобы расширить функциональность и максимизировать оптимизацию.
- Схема дает логическое представление о Rete. Реализации могут отличаться физическими деталями. В частности, на диаграмме показаны фиктивные входы, обеспечивающие правильную активацию в начале ветвей бета-узла. Двигатели могут реализовывать другие подходы, такие как адаптеры, которые позволяют альфа-памяти выполнять правильные активации напрямую.
- Схема не иллюстрирует все возможности совместного использования узлов.
Для более подробного и полного описания алгоритма Рете см. Главу 2 «Производственное согласование для больших обучающих систем» Роберта Дуренбоса (см. Ссылку ниже).
Альтернативы
Альфа Сеть
Возможным вариантом является введение дополнительных запоминающих устройств для каждого промежуточного узла в сети распознавания. Это увеличивает накладные расходы Rete, но может иметь преимущества в ситуациях, когда правила динамически добавляются или удаляются из Rete, что упрощает динамическое изменение топологии сети распознавания.
Альтернативная реализация описана Дуренбосом.[5] В этом случае дискриминационная сеть заменяется набором памяти и индексом. Индекс может быть реализован с использованием хеш-таблица. Каждая память хранит WME, которые соответствуют одному условному шаблону, а индекс используется для ссылки на блоки памяти по их шаблону. Этот подход практичен только тогда, когда WME представляют кортежи фиксированной длины, а длина каждого кортежа короткая (например, 3-кортежи). Кроме того, этот подход применим только к условным шаблонам, которые выполняют равенство тесты против постоянный ценности. Когда WME входит в Rete, индекс используется для поиска набора ячеек, условный шаблон которых соответствует атрибутам WME, и WME затем добавляется непосредственно к каждой из этих ячеек. Сама по себе эта реализация не содержит узлов с 1 входом. Однако для реализации тестов на неравенство Rete может содержать дополнительные сети узлов с 1 входом, через которые передаются WME перед помещением в память. В качестве альтернативы тесты на неравенство могут выполняться в бета-сети, описанной ниже.
Бета-сеть
Распространенный вариант - построить связанные списки токенов, где каждый токен содержит один WME. В этом случае списки WME для частичного совпадения представлены связанным списком токенов. Этот подход может быть лучше, потому что он устраняет необходимость копировать списки WME с одного токена на другой. Вместо этого бета-узлу нужно только создать новый токен для хранения WME, который он хочет присоединить к частичному списку совпадений, а затем связать новый токен с родительским токеном, хранящимся во входной бета-памяти. Новый токен теперь формирует заголовок списка токенов и сохраняется в выходной бета-памяти.
Бета-узлы обрабатывают токены. Маркер - это единица хранения в памяти, а также единица обмена между памятью и узлами. Во многих реализациях токены вводятся в альфа-память, где они используются для хранения одиночных WME. Затем эти токены передаются в бета-сеть.
Каждый бета-узел выполняет свою работу и, в результате, может создавать новые токены для хранения списка WME, представляющих частичное совпадение. Эти расширенные токены затем сохраняются в бета-памяти и передаются последующим бета-узлам. В этом случае бета-узлы обычно передают списки WME через бета-сеть, копируя существующие списки WME из каждого полученного токена в новые токены, а затем добавляя дополнительные WME в списки в результате выполнения соединения или какого-либо другого действия. Затем новые токены сохраняются в выходной памяти.
Прочие соображения
Хотя это не определено алгоритмом Rete, некоторые механизмы предоставляют расширенные функции для поддержки большего контроля над сохранение истины. Например, когда соответствие найдено для одной продукции, это может привести к утверждению новых WME, которые, в свою очередь, соответствуют условиям для другой продукции. Если последующее изменение рабочей памяти приводит к тому, что первое совпадение становится недействительным, это может означать, что второе совпадение также недействительно. Алгоритм Рете не определяет никакого механизма для определения и обработки этих логическая правда зависимости автоматически. Однако некоторые движки поддерживают дополнительную функциональность, позволяющую автоматически поддерживать истинные зависимости. В этом случае отвод одного WME может привести к автоматическому отозванию дополнительных WME для поддержания логических утверждений истинности.
Алгоритм Рете не определяет никакого подхода к обоснованию. Обоснование относится к механизмам, которые обычно требуются в экспертных системах и системах принятия решений, в которых, в простейшем случае, система сообщает о каждом из внутренних решений, используемых для достижения некоторого окончательного вывода. Например, экспертная система может обосновать вывод о том, что животное является слоном, сообщив, что оно большое, серое, с большими ушами, хоботом и клыками. Некоторые движки предоставляют встроенные системы обоснования в сочетании с их реализацией алгоритма Рете.
В этой статье не дается исчерпывающее описание всех возможных вариантов или расширений алгоритма Рете. Есть и другие соображения и нововведения. Например, движки могут предоставлять специализированную поддержку в сети Rete, чтобы применять обработку правил сопоставления с образцом для конкретных типы данных и такие источники, как программные объекты, XML данные или таблицы реляционных данных. Другой пример касается дополнительных средств отметки времени, предоставляемых многими механизмами для каждого WME, входящего в сеть Rete, и использования этих отметок времени в сочетании со стратегиями разрешения конфликтов. Механизмы демонстрируют значительные различия в способах программного доступа к механизму и его рабочей памяти и могут расширять базовую модель Rete для поддержки форм параллельной и распределенной обработки.
Оптимизация и производительность
Несколько оптимизаций для Rete были идентифицированы и описаны в академической литературе. Некоторые из них, однако, применимы только в очень специфических сценариях, и поэтому часто имеют мало или вообще не применяются в механизме правил общего назначения. Кроме того, альтернативные алгоритмы, такие как TREAT, разработанные Даниэль П. Миранкер[6] Были сформулированы LEAPS и Design Time Inferencing (DeTI), которые могут обеспечить дополнительные улучшения производительности.
Алгоритм Rete подходит для сценариев, в которых прямая цепочка и «логический вывод» используются для вычисления новых фактов из существующих фактов или для фильтрации и отбрасывания фактов, чтобы прийти к какому-либо выводу. Он также используется как достаточно эффективный механизм для выполнения высоко комбинаторных оценок фактов, когда между кортежами фактов должно выполняться большое количество соединений. Другие подходы к выполнению оценки правил, такие как использование деревья решений или реализация последовательных механизмов, может быть более подходящей для простых сценариев и должна рассматриваться как возможные альтернативы.
Производительность Rete также во многом зависит от вариантов реализации (независимо от топологии сети), один из которых (использование хэш-таблиц) приводит к значительным улучшениям. Большинство тестов производительности и сравнений, доступных в Интернете, в некоторой степени предвзято. или другой. Чтобы упомянуть только частую предвзятость и несправедливый тип сравнения: 1) использование игрушечных задач, таких как примеры манер и вальса; такие примеры полезны для оценки конкретных свойств реализации, но они могут не отражать реальную производительность сложных приложений; 2) использование старой реализации; например, ссылки в следующих двух разделах (Rete II и Rete-NT) сравнивают некоторые коммерческие продукты с полностью устаревшими версиями CLIPS и утверждают, что коммерческие продукты могут быть на порядки быстрее, чем CLIPS; это забывает, что CLIPS 6.30 (с введением хэш-таблиц, как в Rete II) на порядки быстрее, чем версия, используемая для сравнений (CLIPS 6.04).
Варианты
Rete II
В 1980-х годах Чарльз Форги разработал преемника алгоритма Рете, названного Rete II.[7] В отличие от оригинального Rete (который является общественным достоянием) этот алгоритм не разглашается. Rete II заявляет о лучшей производительности для более сложных задач (даже на порядок[8]), и официально реализован в CLIPS / R2, реализации C / ++ и в OPSJ, реализации Java в 1998 году. Rete II дает улучшение производительности примерно на 100-1 порядок в более сложных задачах, как показано KnowledgeBased Systems Corporation.[9] ориентиры.
Rete II можно охарактеризовать двумя направлениями улучшения; конкретные оптимизации, относящиеся к общей производительности сети Rete (включая использование хешированной памяти для повышения производительности с большими наборами данных), а также включение обратная цепочка алгоритм, предназначенный для работы поверх сети Rete. Одна только обратная цепочка может объяснить самые серьезные изменения в тестах, относящихся к Rete и Rete II. Rete II реализован в коммерческом советнике по продуктам от FICO, ранее называвшемся Fair Isaac. [10]
Джесс (по крайней мере версии 5.0 и новее) также добавляет коммерческий алгоритм обратной цепочки поверх сети Rete, но нельзя сказать, что он полностью реализует Rete II, отчасти из-за того, что полная спецификация не является общедоступной.
Рете-III
В начале 2000-х годов двигатель Rete III был разработан Чарльзом Форги в сотрудничестве с инженерами FICO. Алгоритм Rete III, который не является Rete-NT, является товарным знаком FICO для Rete II и реализован как часть механизма FICO Advisor. По сути, это механизм Rete II с API, который позволяет получить доступ к модулю Advisor, поскольку механизм Advisor может получать доступ к другим продуктам FICO.[11]
Rete-NT
В 2010 году Forgy разработал новое поколение алгоритма Rete. В тесте InfoWorld алгоритм был признан в 500 раз быстрее, чем исходный алгоритм Rete, и в 10 раз быстрее, чем его предшественник, Rete II.[12] Этот алгоритм теперь лицензирован Sparkling Logic, компании, к которой Форги присоединился в качестве инвестора и стратегического советника.[13][14] в качестве механизма вывода продукта СМАРТС.
Смотрите также
использованная литература
- ^ Чарльз Форги: Rete: Быстрый алгоритм для проблемы соответствия множеству шаблонов / множеству объектов. В: Искусственный интеллект, т. 19. С. 17–37, 1982.
- ^ "Демистификация алгоритма Rete! - Часть 1" Кэрол-Энн Матиньон
- ^ Ян Райт; Джеймс Маршалл. "Ядро выполнения RC ++: RETE * более быстрое повторение с TREAT в качестве особого случая" (PDF). Архивировано из оригинал (PDF) на 2004-07-25. Получено 2013-09-13.
- ^ Анураг Ачарья; Милинд Тамбе. «Матч, ориентированный на коллекцию» (PDF). CIKM '93 Материалы второй международной конференции по управлению информацией и знаниями. Дои:10.1145/170088.170411. Архивировано из оригинал (PDF) 18 марта 2012 г.
- ^ Согласование производства для больших систем обучения из коллекции технических отчетов SCS, Школа компьютерных наук, Университет Карнеги-Меллона
- ^ http://dl.acm.org/citation.cfm?id=39946 «TREAT: новый и эффективный алгоритм сопоставления производственных систем искусственного интеллекта»
- ^ RETE2 от Технологии производственных систем
- ^ Сравнительный анализ CLIPS / R2 от Технологии производственных систем
- ^ KBSC
- ^ http://dmblog.fico.com/2005/09/what_is_rete_ii.html
- ^ http://dmblog.fico.com/2005/09/what_is_rete_ii.html
- ^ Оуэн, Джеймс (2010-09-20). «Самая быстрая в мире система правил | Системы управления бизнес-правилами». InfoWorld. Получено 2012-04-07.
- ^ «Официально доктор Чарльз Форги присоединяется к Sparkling Logic в качестве стратегического советника». PR.com. 2011-10-31. Получено 2012-04-07.
- ^ "Доктор Чарльз Форги, доктор философии". www.sparklinglogic.com. Получено 2012-04-07.
Эта статья включает в себя список общих использованная литература, но он остается в основном непроверенным, потому что ему не хватает соответствующих встроенные цитаты. (Август 2011 г.) (Узнайте, как и когда удалить этот шаблон сообщения) |
- Чарльз Форги, «Процедура сетевого сопоставления для производственных систем». Рабочий документ, 1974 г.
- Чарльз Форги "«Об эффективном внедрении производственных систем». Кандидат наук. Диссертация, Университет Карнеги-Меллона, 1979.
- Чарльз, Форджи (1982). "Rete: Быстрый алгоритм для задачи соответствия множеству шаблонов / множеству объектов". Искусственный интеллект. 19: 17–37. Дои:10.1016/0004-3702(82)90020-0.
внешняя ссылка
- Объяснение алгоритма Rete Брюс Шнайер, журнал доктора Добба
- Согласование производства для больших систем обучения - Р. Дуренбос Подробное и доступное описание Rete, также описывается вариант Rete / UL, оптимизированный для больших систем (PDF)
- По правилам (Краткое введение от завязать узел )