Алгоритм Хошена – Копельмана - Википедия - Hoshen–Kopelman algorithm
| Часть серии по |
| Машинное обучение и сбор данных |
|---|
Площадки для машинного обучения |
В Алгоритм Хошена – Копельмана простой и эффективный алгоритм для маркировки кластеры на сетке, где сетка регулярная сеть ячеек, причем ячейки заняты или незаняты. Этот алгоритм основан на известном алгоритм поиска объединения.[1] Алгоритм был первоначально описан Джозефом Хошеном и Рауль Копельман в своей статье 1976 года «Перколяция и кластерное распределение. I. Метод множественной маркировки кластеров и алгоритм критической концентрации».[2]
Теория перколяции
Теория перколяции это изучение поведения и статистика из кластеры на решетки. Предположим, у нас есть большая квадратная решетка, в которой каждая ячейка может быть занята вероятность п и может быть пустым с вероятностью 1 – п. Каждая группа соседних занятых ячеек образует кластер. Соседи определяются как ячейки, имеющие общую сторону, но не те, которые имеют общий угол, т.е. мы рассматриваем 4-связный район то есть сверху, снизу, слева и справа. Каждая занятая ячейка не зависит от статуса своего соседства. Количество кластеров, размер каждого кластера и их распределение - важные темы теории перколяции.
|
| Учитывать 5x5 сетки на рисунках (а) и (б).На рисунке (а) вероятность занятости равна р = 6/25 = 0,24.На рисунке (b) вероятность занятости равна р = 16/25 = 0,64. |


Алгоритм Хошена – Копельмана для поиска кластеров
В этом алгоритме мы просматриваем сетку в поисках занятых ячеек и помечаем их метками кластера. Процесс сканирования называется Растровое сканирование. Алгоритм начинается со сканирования ячейки сетки за ячейкой и проверки, занята ячейка или нет. Если ячейка занята, то она должна быть помечена меткой кластера. Эта метка кластера определяется на основе соседей этой ячейки. (Для этого мы будем использовать Алгоритм поиска союза что объясняется в следующем разделе.) Если у ячейки нет занятых соседей, то ячейке назначается новый ярлык.[3]
Алгоритм поиска объединения
Этот алгоритм представляет собой простой метод вычисления классы эквивалентности. Вызов функции союз (х, у) указывает, что элементы Икс и у являются членами одного класса эквивалентности. Поскольку отношения эквивалентности переходный; все предметы, эквивалентные Икс эквивалентны всем предметам, эквивалентным у. Таким образом, для любого предмета Икс, есть набор элементов, которые эквивалентны Икс . Это множество является классом эквивалентности, которого Икс является членом. Вторая функция найти (х) возвращает представительный член класса эквивалентности, которому Икс принадлежит.
Псевдокод
Вовремя растровое сканирование сетки, всякий раз, когда встречается занятая ячейка, соседние ячейки сканируются, чтобы проверить, не была ли какая-либо из них уже просканирована. Если мы найдем уже просканированных соседей, союз выполняется операция, чтобы указать, что эти соседние ячейки на самом деле являются членами одного класса эквивалентности. Затемнайти операция выполняется для поиска представительного члена того класса эквивалентности, которым будет помечена текущая ячейка.
С другой стороны, если текущая ячейка не имеет соседей, ей назначается новая, ранее не использовавшаяся метка. Таким образом обрабатывается вся сетка.
Следующий псевдокод передается от Тобина Фрике реализация того же алгоритма.[3]
Растровое сканирование и нанесение надписей на сеткубольшая_ метка = 0; для x в 0 до n_columns {для y в 0 до n_rows {если занято [x, y], то влево = занято [x-1, y]; # Разве это не должно быть метка [x-1, y] выше = занято [x, y-1]; # То же самое? if (left == 0) и (вверху == 0) then / * Ни метка сверху, ни слева. * / наибольшая_ метка = наибольшая_ метка + 1; / * Создаем новую, еще не используемую метку кластера. * / метка [x, y] = большая_метка; else if (left! = 0) и (выше == 0) then / * Один сосед слева. * / label [x, y] = find (слева); else if (left == 0) и (выше! = 0) then / * Один сосед, выше. * / label [x, y] = find (вверху); else / * Соседи ОБЕИ слева и сверху. * / union (слева вверху); / * Связываем левый и верхний кластеры. * / label [x, y] = find (слева); }}Союзvoid union (int x, int y) {label [find (x)] = find (y);}Находитьint найти (int x) {int y = x; а (метки [у]! = у) у = метки [у]; а (метки [х]! = х) {int z = метки [х]; метки [x] = y; х = z; } return y;}Пример
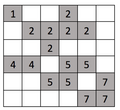
Рассмотрим следующий пример. Темные ячейки в сетке в рисунок (а) представляют, что они заняты, а белые пустые. Таким образом, запустив алгоритм H – K на этом входе, мы получим результат, как показано на рисунок (б) со всеми помеченными кластерами.
Алгоритм обрабатывает входную сетку, ячейка за ячейкой, следующим образом: Предположим, что сетка - это двумерный массив.
- Начиная с ячейки
сетка [0] [0]т.е. первая ячейка. Ячейка занята, и в ней нет ячеек слева или выше, поэтому мы пометим эту ячейку новой меткой, скажем1. сетка [0] [1]исетка [0] [2]оба не заняты, поэтому они не помечены.сетка [0] [3]занято, поэтому проверьте ячейку слева, которая не занята, поэтому мы увеличиваем текущее значение метки и назначаем метку ячейке как2.сетка [0] [4],сетка [0] [5]исетка [1] [0]незанятые, поэтому они не помечены.сетка [1] [1]занято, поэтому проверьте ячейку слева и выше, обе ячейки не заняты, поэтому назначьте новую метку3.сетка [1] [2]занято, поэтому проверьте ячейку слева и выше, занята только ячейка слева, поэтому присвойте этой ячейке метку ячейки слева3.сетка [1] [3]занято, поэтому проверьте ячейку слева и сверху, обе ячейки заняты, поэтому объедините два кластера и назначьте метку кластера ячейки выше ячейке слева и этой ячейке, т.е.2. (Слияние с использованием алгоритма объединения пометит все ячейки меткой3к2)сетка [1] [4]занято, поэтому проверьте ячейку слева и выше, занята только ячейка слева, поэтому присвойте этой ячейке метку ячейки слева2.сетка [1] [5],сетка [2] [0]исетка [2] [1]незанятые, поэтому они не помечены.сетка [2] [2]занято, поэтому проверьте ячейку слева и выше, занята только ячейка выше, поэтому присвойте этой ячейке метку ячейки выше3.сетка [2] [3],сетка [2] [4]исетка [2] [5]незанятые, поэтому они не помечены.сетка [3] [0]занято, поэтому проверьте ячейку выше, которая не занята, поэтому мы увеличиваем текущее значение метки и назначаем метку ячейке как4.сетка [3] [1]занято, поэтому проверьте ячейку слева и выше, занята только ячейка слева, поэтому присвойте этой ячейке метку ячейки слева4.сетка [3] [2]не занято, поэтому на нем нет надписи.сетка [3] [3]занято, поэтому проверьте ячейку слева и выше, обе ячейки не заняты, поэтому назначьте новую метку5.сетка [3] [4]занято, поэтому проверьте ячейку слева и выше, занята только ячейка слева, поэтому присвойте этой ячейке метку ячейки слева5.сетка [3] [5],сетка [4] [0]исетка [4] [1]не заняты, поэтому они не помечены.сетка [4] [2]занято, поэтому проверьте ячейку слева и выше, обе ячейки не заняты, поэтому назначьте новую метку6.сетка [4] [3]занято, поэтому проверьте ячейку слева и сверху, обе ячейки слева и выше заняты, поэтому объедините два кластера и назначьте метку кластера ячейки выше ячейке слева и этой ячейке, т.е.5. (Слияние с использованием алгоритма объединения пометит все ячейки меткой6к5).сетка [4] [4]не занято, поэтому не помечено.сетка [4] [5]занято, поэтому проверьте ячейку слева и выше, обе ячейки не заняты, поэтому назначьте новую метку7.сетка [5] [0] сетка [5] [1]сетка [5] [2]исетка [5] [3]незанятые, поэтому они не помечены.сетка [5] [4]занято, поэтому проверьте ячейку слева и выше, обе ячейки не заняты, поэтому назначьте новую метку8.сетка [5] [5]занято, поэтому проверьте ячейку слева и сверху, обе ячейки слева и выше заняты, поэтому объедините два кластера и назначьте метку кластера ячейки выше ячейке слева и этой ячейке, т.е.7. (Слияние с использованием алгоритма объединения пометит все ячейки меткой8к7).
|
| Учитывать 6x6 сетки на рисунках (а) и (б).Рисунок (а). Это входные данные для алгоритма Хошена – Копельмана. Рисунок (b), это результат работы алгоритма со всеми помеченными кластерами. |

Приложения
- Определение площади узловых доменов и длин узловых линий [4]
- Информация о узловых соединениях
- Моделирование электрическая проводимость
Смотрите также
- Алгоритм кластеризации K-средних
- Алгоритм нечеткой кластеризации
- Гауссовский (Максимизация ожиданий ) алгоритм кластеризации
- Методы кластеризации [5]
- C-означает алгоритм кластеризации [6]
- Маркировка подключенных компонентов
Рекомендации
- ^ https://www.cs.princeton.edu/~rs/AlgsDS07/01UnionFind.pdf
- ^ Hoshen, J .; Копельман, Р. (15 октября 1976 г.). «Перколяция и распределение кластеров. I. Методика множественной маркировки кластеров и алгоритм критической концентрации». Phys. Ред. B. 14 (8): 3438–3445. Дои:10.1103 / PhysRevB.14.3438 - через APS.
- ^ а б Фрике, Тобин (21 апреля 2004 г.). «Алгоритм Хошена-Копельмана для идентификации кластеров». ocf.berkeley.edu. Получено 2016-09-17.
- ^ Кристиан Иоас. «Введение в алгоритм Хошена-Копельмана и его применение в статистике узловой области» (PDF). Webhome.weizmann.ac.il. Получено 2016-09-17.
- ^ «Кластеризация» (PDF).
- ^ «Нечеткая кластеризация c-средних».