Суффикс-автомат - Suffix automaton
| Суффикс-автомат | |||||||||
|---|---|---|---|---|---|---|---|---|---|
 | |||||||||
| Тип | Индекс подстроки | ||||||||
| Изобрел | 1983 | ||||||||
| Изобретенный | Ансельм Блумер; Джанет Блумер; Анджей Эренфойхт; Дэвид Хаусслер; Росс МакКоннелл | ||||||||
| Сложность времени в нотация большой O | |||||||||
| |||||||||

В Информатика, а суффиксный автомат эффективный структура данных для представления индекс подстроки заданной строки, которая позволяет хранить, обрабатывать и извлекать сжатую информацию обо всех ее подстроки. Суффиксный автомат строки самый маленький ориентированный ациклический граф с выделенной начальной вершиной и набором «конечных» вершин, так что пути от начальной вершины к конечным вершинам представляют суффиксы строки. Формально суффиксный автомат определяется следующим набором свойств:

- Его дуги помечены буквы;
- ни один из его узлы иметь две исходящие дуги, помеченные одной и той же буквой;
- для каждого суффикса существует путь от начальной вершины до некоторой конечной вершины такой, что конкатенация букв на пути образует этот суффикс;
- у него наименьшее количество вершин среди всех графов, определенных указанными выше свойствами.
Говоря с точки зрения теория автоматов, суффиксный автомат - это минимальный частичный детерминированный конечный автомат который распознает набор суффиксы данного нить . В граф состояний суффиксного автомата называется ориентированным ациклическим графом слов (DAWG), термин, который также иногда используется для обозначения любого детерминированный ациклический конечный автомат.

Суффикс-автоматы были представлены в 1983 году группой ученых из Денверский университет и Университет Колорадо в Боулдере. Они предложили линейное время онлайн алгоритм для его построения и показал, что суффиксный автомат строки длина не менее двух символов не более государства и самое большее переходы. Дальнейшие работы показали тесную связь между суффиксными автоматами и суффиксные деревья, и обрисовали в общих чертах несколько обобщений суффиксных автоматов, таких как сжатый суффиксный автомат, полученный сжатием узлов с одной исходящей дугой.


Суффикс-автоматы обеспечивают эффективные решения таких проблем, как поиск подстроки и вычисление наибольшая общая подстрока из двух и более струн.
История

Понятие суффиксного автомата было введено в 1983 году.[1] группой ученых из Денверский университет и Университет Колорадо в Боулдере состоящий из Ансельма Блумера, Джанет Блумер, Анджей Эренфойхт, Дэвид Хаусслер и Росс МакКоннелл, хотя подобные концепции ранее изучались вместе с суффиксными деревьями в работах Питера Вайнера,[2] Воан Пратт[3] и Анатолий Слисенко.[4] В своей первоначальной работе Блюмер и другие. показал суффиксный автомат, построенный для строки длины больше чем имеет самое большее государства и самое большее переходов и предложил линейный алгоритм для построения автоматов.[5]



В 1983 году Му-Тиан Чен и Джоэл Сейферас независимо показали, что алгоритм построения суффиксного дерева Вейнера 1973 года[2] при построении суффиксного дерева строки строит суффиксный автомат перевернутой строки как вспомогательная конструкция.[6] В 1987 году Блюмер и другие. применил технику сжатия, используемую в суффиксных деревьях, к суффиксному автомату и изобрел сжатый суффиксный автомат, который также называют сжатым направленным ациклическим графом слов (CDAWG).[7] В 1997 г. Максим Крочмор и Рено Верен разработали линейный алгоритм для прямого построения CDAWG.[1] В 2001 году Сюнсуке Иненага и другие. разработал алгоритм построения CDAWG для набора слов, заданных три.[8]

Определения
Обычно, говоря о суффиксных автоматах и связанных с ними понятиях, некоторые понятия из формальная теория языка и теория автоматов используются, в частности:[9]
- "Алфавит" конечный набор который используется для построения слов. Его элементы называются «персонажами»;
- "Слово" конечная последовательность символов . «Длина» слова обозначается как ;
- "Формальный язык "- набор слов в заданном алфавите;
- «Язык всех слов» обозначается как (где символ "*" означает Клини звезда ), «пустое слово» (слово нулевой длины) обозначается символом ;
- "Конкатенация слов " и обозначается как или же и соответствует слову, полученному записью справа от , то есть, ;
- «Конкатенация языков» и обозначается как или же и соответствует набору попарных конкатенаций ;
- Если слово может быть представлен как , куда , затем слова , и называются "префикс", "суффикс" и "подслово "(подстрока) слова соответственно;
- Если тогда говорят, что "происходит" в как подслово. Здесь и называются левая и правая позиции вхождения в соответственно.


























Структура автомата
Формально, детерминированный конечный автомат определяется 5-кратный , куда:[10]

- это «алфавит», который используется для построения слов,
- это набор автоматов "состояния ",
- - «начальное» состояние автомата,
- набор «конечных» состояний автомата,
- это частичный «переходная» функция автомата, такая, что за и либо не определено, либо определяет переход от над характером .









Чаще всего детерминированный конечный автомат представляется в виде ориентированный граф («диаграмма») такая, что:[10]
- Набор графа вершины соответствует состоянию состояний ,
- График имеет конкретную отмеченную вершину, соответствующую начальному состоянию ,
- График имеет несколько отмеченных вершин, соответствующих множеству конечных состояний ,
- Набор графика дуги соответствует набору переходов ,
- В частности, каждый переход представлен дугой из к отмечен символом . Этот переход также можно обозначить как .






![{ textstyle q_ {1} { begin {smallmatrix} { sigma} [- 5pt] { longrightarrow} end {smallmatrix}} q_ {2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/16652b5477735b6587a69159e7dc29f9e349fe10)
По диаграмме автомат распознает слово только если есть путь из начальной вершины в какую-то последнюю вершину так что объединение символов на этом пути образует . Набор слов, распознаваемых автоматом, образует язык, который должен распознаваться автоматом. В этих терминах язык, распознаваемый суффиксным автоматом это язык его (возможно, пустых) суффиксов.[9]


Состояния автоматов
«Правильный контекст» слова относительно языка это набор это набор слов так что их соединение с образует слово из . Правильный контекст вызывает естественное отношение эквивалентности по набору всех слов. Если язык распознается некоторым детерминированным конечным автоматом, существует единственное с точностью до изоморфизм автомат, который распознает тот же язык и имеет минимально возможное количество состояний. Такой автомат называется минимальный автомат для данного языка . Теорема Майхилла – Нероде позволяет ему явно определять его с точки зрения правильного контекста:[11][12]

![{ displaystyle [ omega] _ {R} = { alpha: omega alpha in L }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0e11883b4ac05c6aecf539854d6b75c9ef741f92)
![{ displaystyle [ alpha] _ {R} = [ beta] _ {R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a98b44d0cd19b729ad56a393d0eaec1805c8e39b)
Теорема — Минимальный язык распознавания автоматов по алфавиту может быть явно определен следующим образом:
- Алфавит остается такой же,
- состояния соответствовать правильному контексту из всех возможных слов ,
- Начальное состояние соответствует правильному контексту пустого слова ,
- Конечные состояния соответствовать правильному контексту слов из ,
- Переходы даны , куда и .
![{ displaystyle [ omega] _ {R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9d0d285bcdf8a938d706449db49bf9412fa4d28c)
![{ displaystyle [ varepsilon] _ {R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0760f6b8f45135b6a59cd46f3e0fbaf6fe048e87)

![{ displaystyle [ omega] _ {R} { begin {smallmatrix} { sigma} [- 5pt] { longrightarrow} end {smallmatrix}} [ omega sigma] _ {R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/608b0d4e9d7dc30de4e7a50378e05b04f2c5a829)
В этих терминах «суффиксный автомат» - это минимальный детерминированный конечный автомат, распознающий язык суффиксов слова . Правильный контекст слова по отношению к этому языку состоит из слов , так что суффикс . Это позволяет сформулировать следующую лемму, определяющую биекция между правым контекстом слова и набором правильных позиций его вхождений в :[13][14]

Теорема — Позволять - набор правильных позиций вхождений в .

Между и :

- Если , тогда ;
- Если , тогда .

![{ displaystyle s_ {x + 1} s_ {x + 2} dots s_ {n} in [ omega] _ {R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7236e1094224b68350522b3c78e3b25c7d7590c7)
![{ Displaystyle альфа в [ omega] _ {R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/43d734319905e4142a99b88b1a4ff78848e2db43)

Например, для слова и его подслово , он держит и . Неофициально состоит из слов, следующих за вхождениями до конца и формируется правильными позициями этих вхождений. В этом примере элемент соответствует слову в то время как слово соответствует элементу .



![{ displaystyle [ab] _ {R} = {a, acaba }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3f08d2df6474465c79e95062c1fb852ab40b5f9a)
![{ displaystyle [ab] _ {R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6ed7efb19a8c1c679df529cc521396f5084dc6bc)



![{ displaystyle s_ {3} s_ {4} s_ {5} s_ {6} s_ {7} = acaba in [ab] _ {R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c276d63dd14d389a3bc61bd2ac4ec6dd79440d1c)
![{ displaystyle a in [ab] _ {R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/95e7352493337857728aadbf551c04e533d5e6db)

Из него следует несколько структурных свойств суффиксных состояний автомата. Позволять , тогда:[14]

- Если и иметь хотя бы один общий элемент , тогда и также имеют общий элемент. Это подразумевает суффикс и поэтому и . В вышеупомянутом примере , так суффикс и поэтому и ;
- Если , тогда , таким образом происходит в только как суффикс . Например, для и он считает, что и ;
- Если и суффикс такой, что , тогда . В приведенном выше примере и это справедливо для "промежуточного" суффикса который .
![{ displaystyle [ alpha] _ {R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/71085cf6f872adc3d86197ac113b94084f5345c9)
![{ displaystyle [ beta] _ {R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6b458c8d348b152c8ce7c446dba72e2a9c06c739)




![{ displaystyle [ beta] _ {R} subset [ alpha] _ {R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/120910cc963d194c5a2e72aaabeccd99762bb0cb)
![{ displaystyle a in [ab] _ {R} cap [cab] _ {R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/290e157059e4c8570e934f79b954cbc33dad920d)

![{ displaystyle [cab] _ {R} = {a } subset {a, acaba } = [ab] _ {R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e09d83b6c56e7c9e8dfd2d011bf221f0fb43937d)




![{ displaystyle [b] _ {R} = [ab] _ {R} = {a, acaba }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3b44e32ec0f0fc2800c6a07868a498acf9e7200b)


![{ displaystyle [ alpha] _ {R} = [ gamma] _ {R} = [ beta] _ {R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3ff07aea00a27624cd9ee051aed79421a3e707c8)
![{ displaystyle [c] _ {R} = [bac] _ {R} = {aba }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3211d738bcd0308264c98a087e9538bb5c9fbc76)

![{ displaystyle [ac] _ {R} = {aba }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7121eb2486dab490f0f2f0fce9c4738d130c4979)
Любой штат суффиксного автомата распознает некоторую непрерывную цепь вложенных суффиксов самого длинного слова, распознаваемого этим состоянием.[14]
![{ Displaystyle д = [ альфа] _ {R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b41dd70277955f02fec50f8fb0f15aac98944de2)
«Левое расширение» строки самая длинная строка который имеет тот же правильный контекст, что и . Длина самой длинной строки, распознанной обозначается . Он содержит:[15]


![{ Displaystyle д = [ гамма] _ {R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fa3035b4f3dae96f18646d8eb7ffad7443c84355)

Теорема — Левое расширение может быть представлен как , куда это самое длинное слово, такое что любое вхождение в предшествует .

«Суффиксная ссылка» государства указатель на состояние который содержит самый большой суффикс что не признается .


В этом смысле можно сказать распознает точно все суффиксы это дольше, чем и не дольше . Он также содержит:[15]


Теорема — Суффиксные ссылки образуют дерево который может быть определен явно следующим образом:







Связь с суффиксными деревьями

А "префиксное дерево "(или" дерево ") - корневое ориентированное дерево, в котором дуги помечены символами таким образом, чтобы не было вершин такого дерева имеет две выходящие дуги, отмеченные одним и тем же символом. Некоторые вершины в trie помечаются как конечные. Говорят, что Trie распознает набор слов, определяемых путями от его корня до конечных вершин. Таким образом, префиксные деревья представляют собой особый вид детерминированных конечных автоматов, если вы воспринимаете их корень как начальную вершину.[16] "Суффикс трие" слова - это префиксное дерево, распознающее набор своих суффиксов. "А суффиксное дерево "представляет собой дерево, полученное из дерева суффиксов с помощью процедуры сжатия, во время которой последующие ребра объединяются, если степень вершины между ними равно двум.[15]

По его определению, суффиксный автомат может быть получен через минимизация суффикса trie. Можно показать, что уплотненный суффиксный автомат получается как минимизацией суффиксного дерева (если предположить, что каждая строка на краю суффиксного дерева является сплошным символом из алфавита), так и уплотнением суффиксного автомата.[17] Помимо этой связи между суффиксным деревом и суффиксным автоматом той же строки, существует также связь между суффиксным автоматом строки и суффиксное дерево перевернутой строки .[18]

Аналогично правым контекстам можно ввести «левые контексты». , "правильные расширения" соответствует самой длинной строке, имеющей тот же левый контекст, что и и отношение эквивалентности . Если учесть правильные расширения по отношению к языку "префиксов" строки можно получить:[15]
![{ displaystyle [ omega] _ {L} = { beta in Sigma ^ {*}: beta omega in L }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5e52cedfd75f0212d1e994dd4e26244482923cff)

![{ Displaystyle [ альфа] _ {L} = [ бета] _ {L}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f0476adeb02a48c9623b9a037d45d9e7cc104594)
Теорема — Суффиксное дерево строки может быть определен явно следующим образом:
- Вершины дерева соответствуют правым расширениям из всех подстроки,
- Края соответствуют тройкам такой, что и .




Здесь тройня означает, что есть преимущество от к со строкой написано на нем



, что подразумевает дерево суффиксных ссылок строки и суффиксное дерево строки изоморфны:[18]

| Суффиксные структуры слов abbcbc и cbcbba |
|---|
|



Как и в случае левых расширений, для правых расширений верна следующая лемма:[15]
Теорема — Правое продолжение строки может быть представлен как , куда это самое длинное слово такое, что каждое вхождение в сменяется .

Размер
Суффиксный автомат строки длины имеет самое большее государства и самое большее переходы. Эти границы достигаются на строках и соответственно.[13] Это можно сформулировать более строго как куда и - количество переходов и состояний в автомате соответственно.[14]








| Максимальные суффиксные автоматы |
|---|
|




Строительство
Первоначально автомат состоит только из одного состояния, соответствующего пустому слову, затем символы строки добавляются один за другим, и автомат постепенно перестраивается на каждом шаге.[19]
Обновления состояния
После добавления нового символа к строке некоторые классы эквивалентности изменяются. Позволять быть правильным контекстом по отношению к языку суффиксы. Тогда переход от к после добавляется к определяется леммой:[14]
![{ displaystyle [ alpha] _ {R _ { omega}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bf5092b4d6aa56f342180faa815e616310a766a1)
![{ displaystyle [ alpha] _ {R _ { omega x}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5bc63f277d664c127ea435f4ec937f065812790c)
Теорема — Позволять быть несколькими словами и быть некоторым персонажем из этого алфавита. Тогда существует следующее соответствие между и :

- если суффикс ;
- иначе.
![{ displaystyle [ alpha] _ {R _ { omega x}} = [ alpha] _ {R _ { omega}} x чашка { varepsilon }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/62af9ba620fb1df6646ec322efe363af38d33047)

![{ displaystyle [ alpha] _ {R _ { omega x}} = [ alpha] _ {R _ { omega}} x}](https://wikimedia.org/api/rest_v1/media/math/render/svg/aea54945b739d0e96a6ed3769826a24a6bca469b)
После добавления к текущему слову правильный контекст может существенно измениться, только если суффикс . Отсюда следует отношение эквивалентности это уточнение из . Другими словами, если , тогда . После добавления нового символа не более двух классов эквивалентности будут разделены, и каждый из них может разделиться максимум на два новых класса. Во-первых, класс эквивалентности, соответствующий пустой правый контекст всегда разбивается на два класса эквивалентности, один из которых соответствует сам и имея как правильный контекст. Этот новый класс эквивалентности содержит ровно и все его суффиксы, которых не было в , поскольку правый контекст таких слов раньше был пуст, а теперь содержит только пустое слово.[14]


![{ displaystyle [ alpha] _ {R _ { omega x}} = [ beta] _ {R _ { omega x}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8720b747c926636d4f25ae02fd22c02e6cee6f2a)
![{ displaystyle [ alpha] _ {R _ { omega}} = [ beta] _ {R _ { omega}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/35041a5b568ed31c1c4bafcf28d5dc300a2bdd4d)

Зная соответствие между состояниями суффиксного автомата и вершинами суффиксного дерева, можно определить второе состояние, которое может расщепиться после добавления нового символа. Переход от к соответствует переходу от к в перевернутой строке. В терминах суффиксных деревьев это соответствует вставке нового самого длинного суффикса в суффиксное дерево . После такой вставки могут образоваться не более двух новых вершин: одна из них соответствует , а другой соответствует своему прямому предку, если было ветвление. Возвращаясь к суффиксным автоматам, это означает, что первое новое состояние распознает а второй (если есть второе новое состояние) - его суффиксная ссылка. Это можно сформулировать в виде леммы:[14]


Теорема — Позволять , быть немного словом и символом . Также позвольте быть самым длинным суффиксом , что происходит в , и разреши . Тогда для любых подстрок из он содержит:


- Если и , тогда ;
- Если и , тогда ;
- Если и , тогда .
![{ displaystyle [u] _ {R _ { omega}} = [v] _ {R _ { omega}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/432b8eb68fefcd343856cd77b50e1a6da1bf7226)
![{ displaystyle [u] _ {R _ { omega}} neq [ alpha] _ {R _ { omega}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a4c5d2ddc8543be4dee9f0dd9607f27ca70d1b93)
![{ displaystyle [u] _ {R _ { omega x}} = [v] _ {R _ { omega x}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d507f1de166b155876cfde9762eaa827a4d147fe)
![{ displaystyle [u] _ {R _ { omega}} = [ alpha] _ {R _ { omega}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2d49bd348b535edf97e44b2ee3ff525eb717a44f)

![{ displaystyle [u] _ {R _ { omega x}} = [ alpha] _ {R _ { omega x}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/dc2ae2510aa9e9ee2d0f6ec623fdb4bf70ffacdd)

![{ displaystyle [u] _ {R _ { omega x}} = [ beta] _ {R _ { omega x}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2e6d5e324fa555ebe1942df7367ebadc6c1f9353)
Это означает, что если (например, когда не произошло в вообще и ), то разбивается только класс эквивалентности, соответствующий пустому правому контексту.[14]


Помимо суффиксных ссылок необходимо также определить конечные состояния автомата. Из свойств структуры следует, что все суффиксы слова признанный распознаются некоторой вершиной на суффикс путь из . А именно, суффиксы длиной больше, чем роды , суффиксы длиной больше, чем но не больше чем роды и так далее. Таким образом, если государство, признающее обозначается , то все конечные состояния (то есть распознавание суффиксов ) образуют последовательность .[19]




Обновления переходов и суффиксных ссылок
После персонажа добавляется к возможные новые состояния суффиксного автомата и . Суффиксная ссылка от идет в и из это идет к . Слова из происходить в только в качестве его суффиксов, поэтому вообще не должно быть переходов от а переходы к нему должны идти от суффиксов иметь длину не менее и быть отмеченным символом . Состояние формируется подмножеством , таким образом, переход от должно быть таким же, как от . Между тем переходы, ведущие к должен идти от суффиксов имеющий длину меньше чем и по крайней мере , поскольку такие переходы привели к раньше и соответствовал отделившейся части этого государства. Состояния, соответствующие этим суффиксам, могут быть определены путем обхода пути ссылки суффикса для .[19]
![{ displaystyle [ omega x] _ {R _ { omega x}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4fc3ec8722532016ceae828eeaf081202ac42b05)
![{ displaystyle ссылка ([ alpha] _ {R _ { omega}})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/91d45b00112aebf52e311e9255240351d52531c2)

![{ displaystyle len (ссылка ([ alpha] _ {R _ { omega}}))}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6ddac98ddeaf4716b89cf8092632952e5ae753e5)
![{ displaystyle [ omega] _ {R _ { omega}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f3af043acf29d9539fa3e1c72adfb971594474df)
| Построение суффиксного автомата для слова abbcbc | |||||||||
|---|---|---|---|---|---|---|---|---|---|
|
| ||||||||
|
| ||||||||
|
| ||||||||




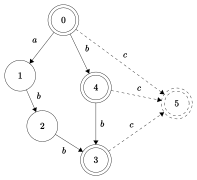





Алгоритм построения
Теоретические результаты, приведенные выше, приводят к следующему алгоритму, который принимает характер и восстанавливает суффиксный автомат в суффиксный автомат :[19]
- Состояние, соответствующее слову хранится как ;
- После добавляется предыдущее значение хранится в переменной и сам переназначен в новое состояние, соответствующее ;
- Состояния, соответствующие суффиксам обновляются переходами на . Для этого нужно пройти , пока не появится состояние, в котором уже есть переход на ;
- По окончании вышеупомянутого цикла возможны 3 случая:
- Если ни одно из состояний на пути суффикса не имело перехода на , тогда никогда не происходило в до и суффиксная ссылка из должен привести к ;
- Если переход по находится и ведет от государства государству , так что , тогда не нужно разделять, и это суффиксная ссылка ;
- Если переход найден, но , затем слова из иметь длину не более следует выделить в новое состояние «клон» ;
- Если предыдущий шаг был завершен созданием , переходы от него и его суффиксная ссылка должны копировать переходы от , в то же время назначается как общее суффиксное звено обоих и ;
- Переходы, которые привели к раньше, но соответствовало словам длины не более перенаправлены на . Для этого нужно пройти суффиксный путь пока не будет найдено состояние, при котором переход по от этого не ведет к .





Вся процедура описывается следующим псевдокодом:[19]
функция add_letter (x): определять p = последний назначать last = new_state () назначать len (последняя) = len (p) + 1 пока δ (р, х) не определено: назначать δ (p, x) = последняя, p = ссылка (p) определять д = δ (р, х) если q = последний: назначать ссылка (последняя) = q0 иначе если len (q) = len (p) + 1: назначать ссылка (последняя) = q еще: определять cl = new_state () назначать len (cl) = len (p) + 1 назначать δ (cl) = δ (q), ссылка (cl) = ссылка (q) назначать ссылка (последняя) = ссылка (q) = cl пока δ (p, x) = q: назначать δ (p, x) = cl, p = ссылка (p)
Здесь - начальное состояние автомата и это функция, создающая для него новое состояние. Предполагается , , и хранятся как глобальные переменные.[19]



Сложность
Сложность алгоритма может варьироваться в зависимости от базовой структуры, используемой для хранения переходов автомата. Это может быть реализовано в с накладные расходы памяти или в с накладные расходы на память, если предполагается, что выделение памяти выполняется в . Чтобы получить такую сложность, необходимо использовать методы амортизированный анализ. Значение строго уменьшается с каждой итерацией цикла, в то время как он может увеличиваться только на единицу после первой итерации цикла на следующей add_letter вызов. Общая стоимость никогда не превышает и он увеличивается только на единицу между итерациями добавления новых букв, что предполагает, что общая сложность также является не более чем линейной. Аналогично демонстрируется линейность второго цикла.[19]





Обобщения
Суффиксный автомат тесно связан с другими суффиксными структурами и индексы подстроки. Имея суффиксный автомат конкретной строки, можно построить ее суффиксное дерево с помощью сжатия и рекурсивного обхода за линейное время.[20] Подобные преобразования возможны в обоих направлениях для переключения между суффиксным автоматом и суффиксное дерево перевернутой строки .[18] Помимо этого, было разработано несколько обобщений для построения автомата для набора строк, заданных trie,[8] компактная суффиксная автоматизация (CDAWG),[7] сохранить структуру автомата на скользящем окне,[21] и строить его двунаправленным способом, поддерживая вставку символов как в начало, так и в конец строки.[22]
Сжатый суффикс-автомат
Как уже упоминалось выше, уплотненный суффиксный автомат получается как посредством уплотнения регулярного суффиксного автомата (путем удаления состояний, которые не являются конечными и имеют ровно одну выходящую дугу), так и посредством минимизации суффиксного дерева. Как и в случае обычного суффиксного автомата, состояния уплотненного суффиксного автомата могут быть определены явно. Двустороннее расширение слова это самое длинное слово , так что каждое вхождение в предшествует и ему удалось . В терминах левого и правого расширений это означает, что двустороннее расширение - это левое расширение правого расширения или, что эквивалентно, правое расширение левого расширения, то есть . В терминах двустороннего расширения компактный автомат определяется следующим образом:[15]



Теорема — Сжатый суффикс-автомат слова определяется парой , куда:

- - набор состояний автомата;
- представляет собой набор автоматных переходов.


Двусторонние расширения индуцируют отношение эквивалентности который определяет набор слов, распознаваемых одним и тем же состоянием уплотненного автомата. Это отношение эквивалентности является переходное закрытие отношения, определяемого , что подчеркивает тот факт, что компактный автомат может быть получен склейкой эквивалентных вершин суффиксного дерева через отношения (минимизация суффиксного дерева) и состояний суффиксного автомата склейки эквивалентны через отношение (уплотнение суффиксного автомата).[23] Если слова и имеют такие же правильные расширения и слова и имеют одинаковые левые расширения, затем все строки в совокупности , и имеют такие же двусторонние расширения. В то же время может случиться так, что ни левое, ни правое продолжение и совпадают. В качестве примера можно взять , и , для которых левое и правое расширение следующие: , но и . При этом, в то время как отношения эквивалентности односторонних расширений были сформированы некоторой непрерывной цепочкой вложенных префиксов или суффиксов, отношения эквивалентности двусторонних расширений более сложны, и единственное, что можно сделать с уверенностью, это то, что строки с одинаковым двусторонним расширением находятся подстроки самой длинной строки с одинаковым двусторонним расширением, но может даже случиться так, что у них нет общей непустой подстроки. Общее количество классов эквивалентности для этого отношения не превышает откуда следует, что сжатый суффикс-автомат строки длины имеет самое большее состояния. Количество переходов в таком автомате не более .[15]












Суффиксный автомат из нескольких строк
Рассмотрим набор слов . Можно построить обобщение суффиксного автомата, которое распознало бы язык, образованный суффиксами всех слов из набора. Ограничения на количество состояний и переходов в таком автомате останутся такими же, как и для однословного автомата, если вы положите .[23] Алгоритм аналогичен построению однословного автомата, но вместо состояние, функция add_letter будет работать с состоянием, соответствующим слову предполагая переход от набора слов к набору .[24][25]





This idea is further generalized to the case when is not given explicitly but instead is given by a prefix tree с вершины. Mohri и другие. showed such an automaton would have at most and may be constructed in linear time from its size. At the same time, the number of transitions in such automaton may reach , for example for the set of words over the alphabet the total length of workds is equal to , the number of vertices in corresponding suffix trie is equal to and corresponding suffix automaton is formed of государства и transitions. Algorithm suggested by Mohri mainly repeats the generic algorithm for building automaton of several strings but instead of growing words one by one, it traverses the trie in a breadth-first search order and append new characters as it meet them in the traversal, which guarantees amortized linear complexity.[26]







Sliding window
Немного алгоритмы сжатия, Такие как LZ77 и RLE may benefit from storing suffix automaton or similar structure not for the whole string but for only last its characters while the string is updated. This is because compressing data is usually expressively large and using memory is undesirable. In 1985, Janet Blumer developed an algorithm to maintain a suffix automaton on a sliding window of size в worst-case and on average, assuming characters are distributed independently and равномерно. She also showed complexity cannot be improved: if one considers words construed as a concatenation of several words, where , then the number of states for the window of size would frequently change with jumps of order , which renders even theoretical improvement of for regular suffix automata impossible.[27]





The same should be true for the suffix tree because its vertices correspond to states of the suffix automaton of the reversed string but this problem may be resolved by not explicitly storing every vertex corresponding to the suffix of the whole string, thus only storing vertices with at least two out-going edges. A variation of McCreight's suffix tree construction algorithm for this task was suggested in 1989 by Edward Fiala and Daniel Greene;[28] several years later a similar result was obtained with the variation of Ukkonen's algorithm by Jesper Larsson.[29][30] The existence of such an algorithm, for compacted suffix automaton that absorbs some properties of both suffix trees and suffix automata, was an open question for a long time until it was discovered by Martin Senft and Tomasz Dvorak in 2008, that it is impossible if the alphabet's size is at least two.[31]
One way to overcome this obstacle is to allow window width to vary a bit while staying . It may be achieved by an approximate algorithm suggested by Inenaga et al. in 2004. The window for which suffix automaton is built in this algorithm is not guaranteed to be of length but it is guaranteed to be at least and at most while providing linear overall complexity of the algorithm.[32]


Приложения
Suffix automaton of the string may be used to solve such problems as:[33][34]
- Counting the number of distinct substrings of в on-line,
- Finding the longest substring of occurring at least twice in ,
- Finding the longest common substring of и в ,
- Counting the number of occurrences of в в ,
- Finding all occurrences of в в , куда is the number of occurrences.



Здесь предполагается, что is given on the input after suffix automaton of is constructed.[33]
Suffix automata are also used in data compression,[35] music retrieval[36][37] and matching on genome sequences.[38]
Рекомендации
- ^ а б Crochemore, Vérin (1997), п. 192
- ^ а б Weiner (1973)
- ^ Pratt (1973)
- ^ Slisenko (1983)
- ^ Blumer et al. (1984), п. 109
- ^ Chen, Seiferas (1985), п. 97
- ^ а б Blumer et al. (1987), п. 578
- ^ а б Inenaga et al. (2001), п. 1
- ^ а б Crochemore, Hancart (1997), pp. 3—6
- ^ а б Серебряков и др. (2006), pp. 50—54
- ^ Рубцов (2019), pp. 89—94
- ^ Hopcroft, Ullman (1979), pp. 65—68
- ^ а б Blumer et al. (1984), pp. 111—114
- ^ а б c d е ж грамм час Crochemore, Hancart (1997), pp. 27—31
- ^ а б c d е ж грамм Inenaga et al. (2005), pp. 159—162
- ^ Rubinchik, Shur (2018), pp. 1—2
- ^ Inenaga et al. (2005), pp. 156—158
- ^ а б c Fujishige et al. (2016), pp. 1—3
- ^ а б c d е ж грамм Crochemore, Hancart (1997), pp. 31—36
- ^ Паращенко (2007), pp. 19—22
- ^ Blumer (1987), п. 451
- ^ Inenaga (2003), п. 1
- ^ а б Blumer et al. (1987), pp. 585—588
- ^ Blumer et al. (1987), pp. 588—589
- ^ Blumer et al. (1987), п. 593
- ^ Mohri et al. (2009), pp. 3558—3560
- ^ Blumer (1987), pp. 461—465
- ^ Fiala, Greene (1989), п. 490
- ^ Larsson (1996)
- ^ Brodnik, Jekovec (2018), п. 1
- ^ Senft, Dvořák (2008), п. 109
- ^ Inenaga et al. (2004)
- ^ а б Crochemore, Hancart (1997), pp. 36—39
- ^ Crochemore, Hancart (1997), pp. 39—41
- ^ Ямамото и др. (2014), п. 675
- ^ Crochemore et al. (2003), п. 211
- ^ Mohri et al. (2009), п. 3553
- ^ Faro (2016), п. 145
Библиография
- Peter Weiner (October 1973), "Linear pattern matching algorithms", Symposium on Foundations of Computer Science: 1–11, CiteSeerX 10.1.1.474.9582, Дои:10.1109 / SWAT.1973.13, Викиданные Q29541479
- Vaughan Ronald Pratt (1973), Improvements and applications for the Weiner repetition finder, OCLC 726598262, Викиданные Q90300966
- Anatoly Olesievich Slisenko (1983), "Detection of periodicities and string-matching in real time", Журнал математических наук, 22 (3): 1316–1387, Дои:10.1007/BF01084395, ISSN 1072-3374, Викиданные Q90305414
- Anselm Blumer; Janet Blumer; Andrzej Ehrenfeucht; Дэвид Хаусслер; Ross McConnell (1984), "Building the minimal DFA for the set of all subwords of a word on-line in linear time", Международный коллоквиум по автоматам, языкам и программированию: 109–118, Дои:10.1007/3-540-13345-3_9, ISBN 978-3-540-13345-2, Викиданные Q90309073
- Anselm Blumer; Janet Blumer; Andrzej Ehrenfeucht; Дэвид Хаусслер; Ross McConnell (1987), "Complete inverted files for efficient text retrieval and analysis", Журнал ACM, 34 (3): 578–595, CiteSeerX 10.1.1.87.6824, Дои:10.1145/28869.28873, ISSN 0004-5411, Викиданные Q90311855
- Janet Blumer (1987), "How much is that DAWG in the window? A moving window algorithm for the directed acyclic word graph", Журнал алгоритмов, 8 (4): 451–469, Дои:10.1016/0196-6774(87)90045-9, ISSN 0196-6774, Викиданные Q90327976
- Mu-Tian Chen; Joel Seiferas (1985), "Efficient and Elegant Subword-Tree Construction", Combinatorial Algorithms on Words: 97–107, CiteSeerX 10.1.1.632.4, Дои:10.1007/978-3-642-82456-2_7, ISBN 978-3-642-82456-2, Викиданные Q90329833
- Shunsuke Inenaga (2003), "Bidirectional Construction of Suffix Trees" (PDF), Nordic Journal of Computing, 10 (1): 52–67, CiteSeerX 10.1.1.100.8726, ISSN 1236-6064, Викиданные Q90335534
- Shunsuke Inenaga; Hiromasa Hoshino; Ayumi Shinohara; Masayuki Takeda; Setsuo Arikawa; Giancarlo Mauri; Giulio Pavesi (March 2005), "On-line construction of compact directed acyclic word graphs", Дискретная прикладная математика, 146 (2): 156–179, CiteSeerX 10.1.1.1039.6992, Дои:10.1016/J.DAM.2004.04.012, ISSN 0166-218X, Викиданные Q57518591
- Shunsuke Inenaga; Hiromasa Hoshino; Ayumi Shinohara; Masayuki Takeda; Setsuo Arikawa (2001), "Construction of the CDAWG for a trie" (PDF), Prague Stringology Conference: 37–48, CiteSeerX 10.1.1.24.2637, Викиданные Q90341606
- Shunsuke Inenaga; Ayumi Shinohara; Masayuki Takeda; Setsuo Arikawa (2004), "Compact directed acyclic word graphs for a sliding window", Journal of Discrete Algorithms, 2 (1): 33–51, CiteSeerX 10.1.1.101.358, Дои:10.1016/S1570-8667(03)00064-9, ISSN 1570-8667, Викиданные Q90345535
- Jun'ichi Yamamoto; Tomohiro I; Hideo Bannai; Shunsuke Inenaga; Masayuki Takeda (2014), "Faster Compact On-Line Lempel-Ziv Factorization" (PDF), Симпозиум по теоретическим аспектам информатики, Leibniz International Proceedings in Informatics, 25: 675–686, CiteSeerX 10.1.1.742.6691, Дои:10.4230/LIPICS.STACS.2014.675, ISBN 978-3-939897-65-1, ISSN 1868-8969, Викиданные Q90348192
- Yuta Fujishige; Yuki Tsujimaru; Shunsuke Inenaga; Hideo Bannai; Masayuki Takeda (2016), "Computing DAWGs and Minimal Absent Words in Linear Time for Integer Alphabets" (PDF), International Symposium on Mathematical Foundations of Computer Science, 58: 38:1—38:14, Дои:10.4230/LIPICS.MFCS.2016.38, ISBN 978-3-95977-016-3, ISSN 1868-8969, Викиданные Q90410044
- Mehryar Mohri; Pedro Moreno; Eugene Weinstein (September 2009), "General suffix automaton construction algorithm and space bounds", Теоретическая информатика, 410 (37): 3553–3562, CiteSeerX 10.1.1.157.7443, Дои:10.1016/J.TCS.2009.03.034, ISSN 0304-3975, Викиданные Q90410808
- Simone Faro (2016), "Evaluation and Improvement of Fast Algorithms for Exact Matching on Genome Sequences", International Conference on Algorithms for Computational Biology, Конспект лекций по информатике: 145–157, Дои:10.1007/978-3-319-38827-4_12, ISBN 978-3-319-38827-4, Викиданные Q90412338
- Maxime Crochemore; Christophe Hancart (1997), "Automata for Matching Patterns", Handbook of Formal Languages, 2: 399–462, CiteSeerX 10.1.1.392.8637, Дои:10.1007/978-3-662-07675-0_9, ISBN 978-3-642-59136-5, Викиданные Q90413384
- Maxime Crochemore; Renaud Vérin (1997), "On compact directed acyclic word graphs", Structures in Logic and Computer Science, Конспект лекций по информатике: 192–211, CiteSeerX 10.1.1.13.6892, Дои:10.1007/3-540-63246-8_12, ISBN 978-3-540-69242-3, Викиданные Q90413885
- Maxime Crochemore; Costas S. Iliopoulos; Gonzalo Navarro; Yoan J. Pinzon (2003), "A Bit-Parallel Suffix Automaton Approach for (δ,γ)-Matching in Music Retrieval", International Symposium on String Processing and Information Retrieval: 211–223, CiteSeerX 10.1.1.8.533, Дои:10.1007/978-3-540-39984-1_16, ISBN 978-3-540-39984-1, Викиданные Q90414195
- John Edward Hopcroft; Jeffrey David Ullman (1979), Введение в теорию автоматов, языки и вычисления, Massachusetts: Эддисон-Уэсли, ISBN 81-7808-347-7, ПР 9082218M, Викиданные Q90418603
- Edward R. Fiala; Daniel H. Greene (1989), "Data compression with finite windows", Коммуникации ACM, 32 (4): 490–505, Дои:10.1145/63334.63341, ISSN 0001-0782, Викиданные Q90425560
- Martin Senft; Tomáš Dvořák (2008), "Sliding CDAWG Perfection", International Symposium on String Processing and Information Retrieval: 109–120, Дои:10.1007/978-3-540-89097-3_12, ISBN 978-3-540-89097-3, Викиданные Q90426624
- N. Jesper Larsson (1996), "Extended application of suffix trees to data compression", Data Compression Conference: 190–199, CiteSeerX 10.1.1.12.8623, Дои:10.1109/DCC.1996.488324, ISSN 1068-0314, Викиданные Q90427112
- Andrej Brodnik; Matevž Jekovec (2018), "Sliding Suffix Tree", Алгоритмы, 11 (8): 118, Дои:10.3390/A11080118, ISSN 1999-4893, Викиданные Q90431196
- Mikhail Rubinchik; Arseny M. Shur (February 2018), "Eertree" (PDF), European Journal of Combinatorics, 68: 249–265, arXiv:1506.04862, Дои:10.1016/J.EJC.2017.07.021, ISSN 0195-6698, Викиданные Q90726647
- Vladimir Serebryakov; Maksim Pavlovich Galochkin; Meran Gabibullaevich Furugian; Dmitriy Ruslanovich Gonchar (2006), Теория и реализация языков программирования (PDF) (in Russian), Moscow: MZ Press, ISBN 5-94073-094-9, Викиданные Q90432456
- Александр Александрович Рубцов (2019), Заметки и задачи о регулярных языках и конечных автоматах (PDF) (in Russian), Moscow: Московский физико-технический институт, ISBN 978-5-7417-0702-9, Викиданные Q90435728
- Дмитрий А. Паращенко (2007), Обработка строк на основе суффиксных автоматов (PDF) (in Russian), Saint Petersburg: ITMO University, Викиданные Q90436837
внешняя ссылка
 СМИ, связанные с Суффикс-автомат в Wikimedia Commons
СМИ, связанные с Суффикс-автомат в Wikimedia Commons- Суффикс-автомат article on E-Maxx Algorithms in English