Многоступенчатое моделирование биомолекул - Multi-state modeling of biomolecules
Многоступенчатое моделирование биомолекул относится к серии методов, используемых для представления и вычисления поведения биологические молекулы или же комплексы который может принимать большое количество возможных функциональных состояний.
Биологические системы сигнализации часто полагаются на комплексы биологических макромолекулы которые могут претерпевать несколько функционально значимых модификаций, взаимно совместимых. Таким образом, они могут находиться в очень большом количестве функционально различных состояний. Моделирование такие системы с несколькими состояниями создают две проблемы: проблему того, как описать и специфицировать систему с несколькими состояниями («проблема спецификации») и проблему того, как использовать компьютер для моделирования развития системы во времени (проблема « вычислительная задача »). Чтобы решить проблему спецификации, разработчики моделей в последние годы отошли от явной спецификации всех возможных состояний в пользу основанный на правилах формализмы, которые позволяют неявную спецификацию модели, включая κ-исчисление,[1] BioNetGen,[2][3][4][5] компилятор аллостерической сети[6] и другие.[7][8] Чтобы решить проблему вычислений, они обратились к методам на основе частиц, которые во многих случаях оказались более эффективными с точки зрения вычислений, чем методы на основе популяции, основанные на обыкновенные дифференциальные уравнения, уравнения в частных производных, или Алгоритм стохастического моделирования Гиллеспи.[9][10] Учитывая современные вычислительные технологии, методы, основанные на частицах, иногда являются единственно возможным вариантом. Симуляторы на основе частиц делятся на две категории:пространственный симуляторы, такие как StochSim,[11] DYNSTOC,[12] RuleMonkey,[9][13] и NFSim[14] и пространственные симуляторы, в том числе Meredys,[15] SRSim[16][17] и MCell.[18][19][20] Таким образом, разработчики моделей могут выбирать из множества инструментов; лучший выбор в зависимости от конкретной проблемы. Продолжается разработка более быстрых и мощных методов, обещающих возможность моделирования еще более сложных сигнальных процессов в будущем.
Вступление
Биомолекулы с несколькими состояниями в передаче сигналов
В жизни клетки, сигналы обрабатываются сетями белки которые могут действовать как сложные вычислительные устройства.[21] Эти сети полагаются на способность отдельных белков существовать во множестве функционально различных состояний, достигаемых с помощью множества механизмов, включая посттрансляционные модификации, связывание лиганда, конформационное изменение, или образование новых комплексы.[21][22][23][24] По аналогии, нуклеиновые кислоты может подвергаться множеству трансформаций, включая связывание с белками, связывание других нуклеиновых кислот, конформационные изменения и Метилирование ДНК.
Кроме того, могут сосуществовать несколько типов модификаций, оказывающих комбинированное влияние на биологическую макромолекулу в любой момент времени. Таким образом, биомолекула или комплекс биомолекул часто могут принимать очень большое количество функционально различных состояний. Количество состояний экспоненциально масштабируется с количеством возможных модификаций, явление, известное как "комбинаторный взрыв ".[24] Это вызывает беспокойство вычислительные биологи которые моделируют или моделируют такие биомолекулы, потому что это поднимает вопросы о том, как такое большое количество состояний может быть представлено и смоделировано.
Примеры комбинаторного взрыва
Биологические сети сигнализации включают в себя широкий спектр обратимых взаимодействия, посттрансляционные модификации и конформационные изменения. Кроме того, часто белок состоит из нескольких - идентичных или неидентичных - подразделения и для объединения нескольких видов белков и / или нуклеиновых кислот в более крупные комплексы. Следовательно, молекулярные частицы с некоторыми из этих особенностей могут существовать в большом количестве возможных состояний.
Например, было подсчитано, что дрожжи каркасный белок Ste5 может входить в состав 25666 уникальных белковых комплексов.[22] В Кишечная палочка, хемотаксис рецепторы четырех разных типов взаимодействуют в группах по три, и каждый индивидуальный рецептор может существовать как минимум в двух возможных конформациях и может иметь до восьми метилирование места,[23] что приводит к миллиардам потенциальных состояний. Протеин киназа CaMKII это додекамер из двенадцати каталитический подразделения,[25] расположены в двух гексамерный кольца.[26] Каждая субъединица может существовать как минимум в двух различных конформациях, и каждая субъединица имеет различные фосфорилирование и сайты связывания лигандов. Недавняя модель[27] инкорпорированные конформационные состояния, два фосфорилирование сайты и два режима привязки кальций / кальмодулин, всего около одного миллиарда возможных состояний на гексамерное кольцо. Модель сцепления Рецептор EGF к MAP киназа каскад, представленный Данос и его коллегами[28] аккаунты для различных молекулярных видов, но авторы отмечают несколько моментов, по которым модель может быть расширена. Более свежая модель ErbB передача сигналов рецептора даже составляет более одного гугол () различные молекулярные виды.[29] Проблема комбинаторного взрыва актуальна и для синтетическая биология, с недавней моделью относительно простой синтетической эукариотический генная цепь с 187 видами и 1165 реакции.[30]


Конечно, не все возможные состояния молекулы или комплекса с несколькими состояниями обязательно будут заселены. Действительно, в системах, где количество возможных состояний намного больше, чем у молекул в компартменте (например, клетке), они не могут быть такими. В некоторых случаях эмпирическая информация может использоваться для исключения определенных состояний, если, например, некоторые комбинации функций несовместимы. Однако при отсутствии такой информации необходимо учитывать все возможные состояния. априори. В таких случаях можно использовать вычислительное моделирование, чтобы выявить, в какой степени заселены различные состояния.
Существование (или потенциальное существование) такого большого числа молекулярных разновидностей является проблемой. комбинаторный феномен: он возникает из относительно небольшого набора функций или модификаций (таких как посттрансляционная модификация или комплексное образование), которые в совокупности определяют состояние всей молекулы или комплекса, точно так же, как существование всего нескольких вариантов в а кофейный магазин (маленькие, средние или большие, с молоком или без, без кофеина или нет, дополнительный снимок эспрессо ) быстро приводит к большому количеству возможных напитков (в данном случае 24; каждый дополнительный двоичный выбор удваивает это число). Хотя нам трудно понять общее количество возможных комбинаций, обычно концептуально нетрудно понять (гораздо меньший) набор функций или модификаций и влияние каждой из них на функцию биомолекулы. Скорость, с которой молекула претерпевает определенную реакцию, обычно будет зависеть главным образом от одной особенности или небольшого подмножества характеристик. Именно наличие или отсутствие этих особенностей диктует скорость реакции. Скорость реакции одинакова для двух молекул, которые отличаются только особенностями, не влияющими на эту реакцию. Таким образом, количество параметров будет намного меньше количества реакций. (В примере с кофейней добавление дополнительной порции эспрессо будет стоить 40 центов, независимо от того, какого размера напиток и есть ли в нем молоко). Именно такие «местные правила» обычно обнаруживаются в лабораторных экспериментах. Таким образом, модель с несколькими состояниями может быть концептуализирована в терминах комбинаций модульных функций и местных правил. Это означает, что даже модель, которая может объяснить огромное количество молекулярных частиц и реакций, не обязательно является концептуально сложной.
Спецификация vs вычисление
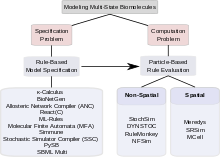
Комбинаторная сложность сигнальных систем с участием белков с несколькими состояниями создает проблемы двух типов. Первая проблема связана с тем, как можно определить такую систему; то есть, как разработчик моделей может определить все комплексы, все изменения, которым они подвергаются, и все параметры и условия, управляющие этими изменениями, надежным и эффективным способом. Эта проблема называется «проблемой спецификации». Вторая проблема касается вычисление. Он задает вопросы о том, является ли комбинаторно сложная модель, однажды заданная, вычислительно управляемой, учитывая большое количество состояний и еще большее количество возможных переходов между состояниями, можно ли ее сохранить в электронном виде и можно ли ее оценить в разумных пределах. количество вычислительного времени. Эта проблема называется «вычислительной проблемой». Среди подходов, которые были предложены для решения комбинаторной сложности в моделировании с несколькими состояниями, некоторые в основном связаны с решением проблемы спецификации, некоторые сосредоточены на поиске эффективных методов вычислений. Некоторые инструменты обращаются как к спецификации, так и к вычислениям. В разделах ниже обсуждаются основанные на правилах подходы к проблеме спецификации и основанные на частицах подходы к решению вычислительной проблемы. Существует широкий спектр вычислительных инструментов для моделирования с несколькими состояниями.[31]
Проблема спецификации
Явная спецификация
Самый наивный способ определения, например, белка в биологической модели - это явно указать каждое из его состояний и использовать каждое из них как молекулярный вид в биологической модели. симуляция структура, которая позволяет переходить из состояния в состояние. Например, если белок может быть лиганд -связанные или нет, существуют в двух конформационный состояния (например, открытое или закрытое) и располагаться в двух возможных субклеточных областях (например, цитозольный или же мембрана -bound), то восемь возможных результирующих состояний можно явно перечислить как:
- связанный, открытый, цитозоль
- связанный, открытый, мембранный
- связанный, закрытый, цитозоль
- связанный, закрытый, мембранный
- несвязанный, открытый, цитозоль
- несвязанный, открытый, мембранный
- несвязанный, закрытый, цитозоль
- несвязанный, закрытый, мембранный
Перечисление всех возможных состояний - длительный и потенциально подверженный ошибкам процесс. Для макромолекулярных комплексов, которые могут принимать несколько состояний, перечисление каждого состояния быстро становится утомительным, если не невозможным. Более того, добавление одной дополнительной модификации или функции к модели исследуемого комплекса удвоит количество возможных состояний (если модификация является бинарной) и более чем удвоит количество переходов, которые необходимо указать.
Спецификация модели на основе правил
Ясно, что подробное описание, в котором перечислены все возможные молекулярные разновидности (включая все их возможные состояния), все возможные реакции или переходы, которым могут подвергаться эти разновидности, и все параметры, управляющие этими реакциями, очень быстро становится громоздким, поскольку сложность биологической системы увеличивается. Поэтому разработчики моделей искали скрытый вместо явных способов определения биологической сигнальной системы. Неявное описание - это то, что группирует реакции и параметры, которые применяются ко многим типам молекул в одном шаблоне реакции. Он также может добавить набор условий, которые определяют параметры реакции, то есть вероятность или скорость, с которой реакция происходит, или происходит ли она вообще. Ясно упоминаются только те свойства молекулы или комплекса, которые имеют значение для данной реакции (влияющие на реакцию или на которые она влияет), а все другие свойства игнорируются в описании реакции.
Например, скорость лиганда диссоциация от белка может зависеть от конформационного состояния белка, но не от его субклеточной локализации. Таким образом, неявное описание будет перечислять два процесса диссоциации (с разными скоростями, в зависимости от конформационного состояния), но игнорировать атрибуты, относящиеся к субклеточной локализации, поскольку они не влияют на скорость диссоциации лиганда и не затрагиваются ею. Это правило спецификации было резюмировано как «Не волнуйтесь, не пишите».[28]
Поскольку она написана не в терминах реакций, а в терминах более общих «правил реакции», охватывающих наборы реакций, такой вид спецификации часто называют "основанный на правилах".[4] Это описание системы в терминах модульных правил основывается на предположении, что только подмножество функций или атрибутов актуально для конкретного правила реакции. Если это предположение верно, набор реакций может быть сведен в одно правило реакции. Это крупнозернистое зерно сохраняет важные свойства лежащих в основе реакций. Например, если реакции основаны на химической кинетике, правила вытекают из них.
Существует множество методов спецификации на основе правил. В общем, спецификация модели - это отдельная задача от выполнения моделирования. Следовательно, среди существующих систем спецификации моделей, основанных на правилах,[4] некоторые концентрируются только на спецификации модели, позволяя пользователю затем экспортировать указанную модель в специальный механизм моделирования. Однако многие решения проблемы спецификации также содержат метод интерпретации указанной модели.[3] Это достигается за счет предоставления метода моделирования модели или метода преобразования ее в форму, которая может использоваться для моделирования в других программах.
Одним из первых методов спецификации, основанных на правилах, является κ-исчисление,[1] а алгебра процессов которые можно использовать для кодирования макромолекул с внутренними состояниями и сайтами связывания, а также для определения правил, по которым они взаимодействуют.[28] Κ-исчисление просто связано с предоставлением языка для кодирования моделей с несколькими состояниями, а не с интерпретацией самих моделей. Симулятор, совместимый с Kappa, - это KaSim.[32][33]
BioNetGen - это программный пакет, который обеспечивает как спецификации, так и возможности моделирования.[2][3][4][5] Основанные на правилах модели могут быть записаны с использованием заданного синтаксиса, языка BioNetGen (BNGL).[4] В основе концепции лежит представление биохимических систем в виде графики, где молекулы представлены в виде узлов (или совокупностей узлов), а химические связи - в виде ребер. Таким образом, правило реакции соответствует правилу перезаписи графа.[3] BNGL предоставляет синтаксис для определения этих графиков и связанных правил как структурированных строк.[4] Затем BioNetGen может использовать эти правила для создания обыкновенных дифференциальных уравнений (ОДУ) для описания каждой биохимической реакции. Кроме того, он может создать список всех возможных видов и реакций в SBML,[34][35] которые затем можно экспортировать в пакеты программного обеспечения для моделирования, которые могут читать SBML. Можно также использовать собственное программное обеспечение моделирования BioNetGen на основе ODE и его способность генерировать реакции на лету во время стохастического моделирования.[5] Кроме того, модель, указанная в BNGL, может быть прочитана другим программным обеспечением для моделирования, например DYNSTOC,[12] RuleMonkey,[13] и NFSim.[14]
Другой инструмент, который генерирует полные сети реакции из набора правил, - это компилятор аллостерических сетей (ANC).[6] Концептуально АНК рассматривает молекулы как аллостерические устройства с Monod-Wyman-Changeux (MWC) механизм регулирования типа,[36] чьи взаимодействия регулируются их внутренним состоянием, а также внешними модификациями. Очень полезной функцией ANC является то, что он автоматически вычисляет зависимые параметры, тем самым накладывая термодинамический правильность.[37]
Расширение κ-исчисления обеспечивается Реагировать (C).[38] Авторы React C показать, что он может выражать стохастическое π-исчисление.[39] Они также предоставляют алгоритм стохастического моделирования, основанный на стохастическом алгоритме Гиллеспи. [40] для моделей, указанных в Реагировать (C).[38]
ML-правила[41] аналогичен React (C), но обеспечивает дополнительную возможность вложения: компонентный вид модели со всеми его атрибутами может быть частью компонента более высокого порядка. Это позволяет ML-правилам захватывать многоуровневые модели, которые могут преодолеть разрыв между, например, серией биохимических процессов и макроскопическим поведением целой клетки или группы клеток. Например, доказательная модель клеточного деления в делящиеся дрожжи включает циклин /cdc2 привязка и активация, феромон секреция и диффузия, деление клеток и движение клеток.[41] Модели, указанные в правилах машинного обучения, можно моделировать с помощью среды моделирования Джеймса II.[42] Похожий вложенный язык для представления многоуровневых биологических систем был предложен Ори и Плоткиным.[43] Формализм спецификации, основанный на молекулярном конечные автоматы (MFA) framework затем может быть использован для создания и моделирования системы ODE или для стохастическое моделирование используя кинетический Монте-Карло алгоритм.[8]
Некоторые основанные на правилах системы спецификации и связанные с ними инструменты создания сетей и моделирования были разработаны с учетом пространственной неоднородности, чтобы обеспечить реалистичное моделирование взаимодействий внутри биологических компартментов. Например, проект Simmune[44][45] включает пространственный компонент: пользователи могут указывать свои биомолекулы с несколькими состояниями и взаимодействия внутри мембран или отсеков произвольной формы. Затем реакционный объем делится на сопрягающие воксели, и для каждого из этих подобъемов создается отдельная реакционная сеть.
Компилятор стохастического симулятора (SSC)[46] позволяет на основе правил модульную спецификацию взаимодействующих биомолекул в областях произвольно сложной геометрии. Опять же, система представлена в виде графиков с химическими взаимодействиями или диффузионными событиями, формализованными как правила перезаписи графов.[46] Затем компилятор генерирует всю реакционную сеть перед запуском стохастического алгоритма реакции-диффузии.
PySB использует другой подход,[47] где спецификация модели встроена в язык программирования Python. Модель (или часть модели) представлена в виде программы Python. Это позволяет пользователям хранить биохимические процессы более высокого порядка, такие как катализ или полимеризация как макросы и повторно используйте их по мере необходимости. Модели можно моделировать и анализировать с помощью библиотек Python, но модели PySB также можно экспортировать в BNGL,[4] каппа,[1] и SBML.[34]
Модели, включающие многокомпонентные и многокомпонентные виды, также могут быть указаны на уровне 3 языка разметки системной биологии (SBML). [34] используя мульти-пакет. Имеется черновик спецификации,[48] поддержка программного обеспечения находится в стадии разработки.
Таким образом, за счет рассмотрения только состояний и характеристик, важных для конкретной реакции, спецификация модели на основе правил устраняет необходимость в явном перечислении всех возможных молекулярных состояний, которые могут претерпевать подобную реакцию, и тем самым обеспечивает эффективную спецификацию.
Вычислительная проблема
При беге симуляции на биологической модели любое программное обеспечение для моделирования оценивает набор правил, начиная с определенного набора начальных условий, и обычно повторение через серию временных шагов до указанного времени окончания. Один из способов классификации алгоритмов моделирования - посмотреть на уровень анализа, на котором применяются правила: они могут быть основанными на совокупности, на основе отдельных частиц или гибридными.
Оценка правил на основе популяции
При оценке правил на основе совокупности правила применяются к совокупностям. Все молекулы того же самого разновидность в одном состоянии объединяются в пул. Применение определенного правила уменьшает или увеличивает размер одного из пулов, возможно, за счет другого.
Некоторые из наиболее известных классов подходов к моделированию в вычислительной биологии относятся к семейству популяционных методов, включая те, которые основаны на численном интегрировании обыкновенных уравнений и уравнений в частных производных и алгоритме стохастического моделирования Гиллеспи.
Дифференциальные уравнения детерминированным образом описывают изменения молекулярных концентраций во времени. Моделирование, основанное на дифференциальных уравнениях, обычно не пытается решить эти уравнения аналитически, но использует подходящие числовой решатель.
Стохастический алгоритм Гиллеспи изменяет состав пулов молекул через прогрессию случайность события реакции, вероятность из которых рассчитывается на основе скоростей реакций и количества молекул в соответствии со стохастическим главное уравнение.[40]
В популяционных подходах можно думать о моделируемой системе как о находящейся в заданном состоянии в любой заданный момент времени, где состояние определяется в соответствии с природой и размером заполненных пулов молекул. Это означает, что пространство всех возможных состояний может стать очень большим. При использовании некоторых методов моделирования, реализующих численное интегрирование обыкновенных уравнений и уравнений в частных производных или стохастического алгоритма Гиллеспи, все возможные пулы молекул и реакции, которым они подвергаются, определяются в начале моделирования, даже если они пусты. Такие методы "сначала сгенерировать"[4] плохо масштабируются с увеличением числа молекулярных состояний.[49] Например, недавно было подсчитано, что даже для простой модели CaMKII всего с 6 состояниями на субъединицы и 10 субъединицами потребуется 290 лет, чтобы сгенерировать всю реакционную сеть на процессоре Intel с тактовой частотой 2,54 ГГц. Xeon процессор.[50] Кроме того, этап генерации модели в методах генерации в первую очередь не обязательно заканчивается, например, когда модель включает сборку белков в комплексы произвольно большого размера, такие как актин нити. В этих случаях пользователь должен указать условие завершения.[3][5]
Даже если можно успешно сгенерировать большую систему реакции, ее моделирование с использованием оценки правил на основе популяции может привести к вычислительным ограничениям. В недавнем исследовании было показано, что мощный компьютер не может моделировать белок с более чем 8 фосфорилирование места ( состояния фосфорилирования) с использованием обыкновенных дифференциальных уравнений.[14]

Были предложены методы уменьшения размера пространства состояний. Один состоит в том, чтобы рассматривать только состояния, смежные с текущим состоянием (то есть состояния, которые могут быть достигнуты в течение следующей итерации) в каждый момент времени. Это избавляет от необходимости перечислять все возможные состояния в начале. Вместо этого реакции генерируются «на лету»[4] на каждой итерации. Эти методы доступны как для стохастических, так и для детерминированных алгоритмов. Эти методы по-прежнему основываются на определении (хотя и сокращенной) реакционной сети - в отличие от «бессетевых» методов, обсуждаемых ниже.
Даже при генерации сетей «на лету» сети, созданные для оценки правил на основе совокупности, могут стать довольно большими, и поэтому их сложно - если вообще возможно - обрабатывать в вычислительном отношении. Альтернативный подход - оценка правил на основе частиц.
Оценка правил на основе частиц

В моделировании на основе частиц (иногда называемых «агентным») белки, нуклеиновые кислоты, макромолекулярные комплексы или маленькие молекулы представлены в виде индивидуального программного обеспечения объекты, и их прогресс отслеживается на протяжении всего моделирования.[51] Поскольку оценка правил на основе частиц отслеживает отдельные частицы, а не совокупности, это требует более высоких вычислительных затрат при моделировании систем с большим общим числом частиц, но с небольшим количеством видов (или пулов) частиц.[51] Однако в случаях комбинаторной сложности моделирование отдельных частиц является преимуществом, поскольку в любой момент моделирования необходимо учитывать только существующие молекулы, их состояния и реакции, в которых они могут пройти. Оценка правил на основе частиц не требует создания полных или частичных сетей реакции в начале моделирования или в любой другой точке моделирования и поэтому называется «бессетевой».
Этот метод снижает сложность модели на этапе моделирования и тем самым экономит время и вычислительные мощности.[9][10] Моделирование следует за каждой частицей, и на каждом этапе моделирования частица «видит» только те реакции (или правила), которые к ней применяются. Это зависит от состояния частицы и, в некоторых случаях, от состояний ее соседей в холоферменте или комплексе. По мере продолжения моделирования состояния частиц обновляются в соответствии с установленными правилами.[10]
Некоторые пакеты моделирования на основе частиц используют специальный формализм для спецификации реагентов, параметров и правил. Другие могут читать файлы в признанном формате спецификации на основе правил, таком как BNGL.[4]
Непространственные методы на основе частиц
StochSim[11][52] основанный на частицах стохастический Симулятор используется в основном для моделирования химических реакций и других молекулярных переходов. Алгоритм, используемый в StochSim, отличается от более широко известного стохастического алгоритма Гиллеспи.[40] в том, что он работает с отдельными сущностями, а не с пулами сущностей, что делает его основанным на частицах, а не на популяции.
В StochSim каждый молекулярный вид может быть снабжен определенным количеством бинарных состояний. флаги представляющий конкретную модификацию. Реакции могут зависеть от набора флагов состояния, установленных на определенные значения. Кроме того, результатом реакции может быть изменение государственного флага. Кроме того, объекты могут быть расположены в геометрической форме. массивы (например, для голоферментов, состоящих из нескольких субъединиц), и реакции могут быть «чувствительными к соседям», то есть вероятность реакции для данного объекта зависит от значения флага состояния на соседнем объекте. Эти свойства делают StochSim идеально подходящим для моделирования молекул с несколькими состояниями, организованных в холоферменты или комплексы заданного размера. Действительно, StochSim использовался для моделирования кластеров бактериальный хемотаксический рецепторы,[53] и холоферменты CaMKII.[27]
Расширение StochSim включает симулятор на основе частиц DYNSTOC, который использует алгоритм, подобный StochSim, для имитации моделей, указанных на языке BioNetGen (BNGL),[4] и улучшает обращение с молекулами внутри макромолекулярные комплексы.[12]
Другой стохастический симулятор на основе частиц, который может читать входные файлы BNGL, - это RuleMonkey.[13] Его алгоритм моделирования[9] отличается от алгоритмов, лежащих в основе StochSim и DYNSTOC, тем, что временной шаг моделирования является переменным.
Сетевой стохастический симулятор (NFSim) отличается от описанных выше тем, что позволяет определять скорости реакции как произвольные математические или условные выражения и тем самым облегчает выборочную крупнозернистый моделей.[14] RuleMonkey и NFsim реализуют разные, но связанные алгоритмы моделирования. Подробный обзор и сравнение обоих инструментов даны Янгом и Хлавачеком.[54]
Легко представить себе биологическую систему, в которой некоторые компоненты представляют собой сложные молекулы с несколькими состояниями, тогда как другие имеют несколько возможных состояний (или даже только одно) и существуют в большом количестве. Для моделирования таких систем был предложен гибридный подход: в рамках гибридной частицы / популяции (HPP) пользователь может указать модель, основанную на правилах, но может указать некоторые виды, которые будут рассматриваться как популяции (а не частицы) в последующем. моделирование.[10] Этот метод сочетает в себе вычислительные преимущества моделирования на основе частиц для систем с несколькими состояниями с относительно низким числом молекул и моделирования на основе популяции для систем с высоким числом молекул и небольшим числом возможных состояний. Спецификация моделей ГЭС поддерживается BioNetGen,[4] а моделирование можно выполнять с помощью NFSim.[14]
Методы на основе пространственных частиц

Методы, основанные на пространственных частицах, отличаются от методов, описанных выше, явным представлением пространства.
Одним из примеров имитатора на основе частиц, который позволяет представить клеточные компартменты, является SRSim.[16][17] SRSim интегрирован в симулятор молекулярной динамики LAMMPS.[56][57] и позволяет пользователю указать модель в BNGL.[4] SRSim позволяет пользователям указывать геометрию частиц в моделировании, а также сайты взаимодействия. Поэтому он особенно хорош при моделировании сборки и структуры сложных биомолекулярных комплексов, о чем свидетельствует недавняя модель внутреннего кинетохора.[58]
MCell[18][19][20][59] позволяет отслеживать отдельные молекулы в произвольно сложных геометрических средах, определяемых пользователем. Это позволяет моделировать биомолекулы в реалистичных реконструкциях живых клеток, включая клетки со сложной геометрией, такой как нейроны. Реакционный отсек - это реконструкция дендритного позвоночника.[55] Визуализации поддерживаются специальным плагином ("CellBlender") для программы с открытым исходным кодом Blender.[60]
MCell использует специальный формализм внутри самой MCell для определения модели с несколькими состояниями: в MCell можно назначать «слоты» любому молекулярные виды. Каждый слот обозначает конкретную модификацию, и любое количество слотов может быть назначено молекуле. Каждый слот может быть занят определенным состоянием. Состояния не обязательно бинарные. Например, слот, описывающий привязку определенного лиганд Интересующий белок может принимать состояния «несвязанный», «частично связанный» и «полностью связанный».
Синтаксис слотов и состояний в MCell также можно использовать для моделирования мультимерных белков или макромолекулярных комплексов. При таком использовании слот является заполнителем для субъединицы или молекулярного компонента сложный, а состояние слота будет указывать, присутствует ли конкретный белковый компонент в комплексе. Можно подумать об этом так: макромолекулы MCell могут иметь несколько размеры: «Измерение состояния» и одно или несколько «пространственных измерений». «Измерение состояния» используется для описания множества возможных состояний, составляющих белок с несколькими состояниями, в то время как пространственные измерения описывают топологический отношения между соседними субъединицами или членами макромолекулярного комплекса. Одним из недостатков этого метода представления белковых комплексов по сравнению с Meredys является то, что MCell не позволяет распространение комплексов и, следовательно, молекул с несколькими состояниями. В некоторых случаях этого можно обойти, регулируя константы диффузии лигандов, которые взаимодействуют с комплексом, используя функции контрольных точек или комбинируя моделирование на разных уровнях.
Примеры моделей с несколькими состояниями в биологии
В таблице ниже представлен (ни в коем случае не исчерпывающий) выбор моделей биологических систем, включающих молекулы с несколькими состояниями и использующих некоторые из обсуждаемых здесь инструментов.
| Биологическая система | Технические характеристики | Вычисление | Ссылка | |
|---|---|---|---|---|
| Сигнальный путь бактериального хемотаксиса | StochSim | StochSim | [61] | |
| Регламент CaMKII | StochSim | StochSim | [27] | |
| ЕРББ рецепторная сигнализация | BioNetGen | NFSim | [29] | |
| Цепи синтетических генов эукариот | BioNetGen, ПРОМОТ[62] | КОПАСИ[63] | [30] | |
| Передача сигналов РНК | Каппа | KaSim | [64] | |
| Сотрудничество аллостерических белков | Аллостерический сетевой компилятор (ANC) | MATLAB | [6] | |
| Chemosensing в Диктиостелиум | Simmune | Simmune | [44] | |
| Рецептор Т-клеток активация | SSC | SSC | [65] | |
| Митотическая кинетохора человека | BioNetGen | SRSim | [66] | |
| Клеточный цикл делящихся дрожжей | ML-правила | ДЖЕЙМС II[42] | [41] |
Смотрите также
Рекомендации
![]() Эта статья была адаптирована из следующего источника под CC BY 4.0 лицензия (2014 ) (отчеты рецензента ): «Многоступенчатое моделирование биомолекул», PLOS вычислительная биология, 10 (9): e1003844, сентябрь 2014 г., Дои:10.1371 / JOURNAL.PCBI.1003844, ISSN 1553-734X, ЧВК 4201162, PMID 25254957, Викиданные Q18145441
Эта статья была адаптирована из следующего источника под CC BY 4.0 лицензия (2014 ) (отчеты рецензента ): «Многоступенчатое моделирование биомолекул», PLOS вычислительная биология, 10 (9): e1003844, сентябрь 2014 г., Дои:10.1371 / JOURNAL.PCBI.1003844, ISSN 1553-734X, ЧВК 4201162, PMID 25254957, Викиданные Q18145441
- ^ а б c Данос, V; Ланев, С (2004). «Формальная молекулярная биология». Теоретическая информатика. 325: 69–110. Дои:10.1016 / j.tcs.2004.03.065.
- ^ а б Блинов, М.Л .; Faeder, J. R .; Гольдштейн, Б; Хлавачек, В. С. (2004). "Био Сеть Gen: Программное обеспечение для моделирования передачи сигналов на основе правил, основанных на взаимодействиях молекулярных доменов ». Биоинформатика. 20 (17): 3289–91. Дои:10.1093 / биоинформатика / bth378. PMID 15217809.
- ^ а б c d е Faeder, JR; Блинов, М.Л .; Гольдштейн, Б; Главачек, WS (2005). «Моделирование биохимических сетей на основе правил». Сложность. 10 (4): 22–41. Bibcode:2005Cmplx..10d..22F. Дои:10.1002 / cplx.20074. S2CID 9307441.
- ^ а б c d е ж грамм час я j k л м Hlavacek, W. S .; Faeder, J. R .; Блинов, М.Л .; Познер, Р. Г .; Hucka, M; Фонтана, Вт (2006). «Правила моделирования сигнально-трансдукционных систем». Научная сигнализация. 2006 (344): re6. CiteSeerX 10.1.1.83.1561. Дои:10.1126 / stke.3442006re6. PMID 16849649. S2CID 1816082.
- ^ а б c d Faeder, J. R .; Блинов, М.Л .; Хлавачек, В. С. (2009). Моделирование биохимических систем на основе правил с помощью Bio СетьGen. Методы молекулярной биологии. 500. С. 113–67. CiteSeerX 10.1.1.323.9577. Дои:10.1007/978-1-59745-525-1_5. ISBN 978-1-934115-64-0. PMID 19399430.
- ^ а б c Ollivier, J. F .; Shahrezaei, V; Суэйн, П. С. (2010). «Масштабируемое моделирование аллостерических белков и биохимических сетей на основе правил». PLOS вычислительная биология. 6 (11): e1000975. Bibcode:2010PLSCB ... 6E0975O. Дои:10.1371 / journal.pcbi.1000975. ЧВК 2973810. PMID 21079669.
- ^ Лок, L; Брент, Р. (2005). «Автоматическая генерация клеточных реакционных сетей с помощью Moleculizer 1.0». Природа Биотехнологии. 23 (1): 131–6. Дои:10.1038 / nbt1054. PMID 15637632. S2CID 23696958.
- ^ а б Ян, Дж; Meng, X; Главачек, В. С. (2010). «Моделирование биохимических систем с молекулярными конечными автоматами на основе правил». Системная биология ИЭПП. 4 (6): 453–66. arXiv:1007.1315. Дои:10.1049 / iet-syb.2010.0015. ЧВК 3070173. PMID 21073243.
- ^ а б c d Ян, Дж; Monine, M. I.; Faeder, J. R.; Hlavacek, W. S. (2008). "Kinetic Monte Carlo method for rule-based modeling of biochemical networks". Физический обзор E. 78 (3 Pt 1): 031910. arXiv:0712.3773. Bibcode:2008PhRvE..78c1910Y. Дои:10.1103/PhysRevE.78.031910. ЧВК 2652652. PMID 18851068.
- ^ а б c d Hogg, J. S., Harris, L. A., Stover, L. J., Nair, N. S., & Faeder, J. R. (2013). Exact hybrid particle/population simulation of rule-based models of biochemical systems. arXiv preprint arXiv:1301.6854.
- ^ а б Nov, Le; Shimizu, TS (2001). "STOCHSIM: modelling of stochastic biomolecular processes". Биоинформатика. 17 (6): 575–576. Дои:10.1093/bioinformatics/17.6.575. PMID 11395441.
- ^ а б c Colvin, J; Monine, M. I.; Faeder, J. R.; Hlavacek, W. S.; von Hoff, D. D.; Posner, R. G. (2009). "Simulation of large-scale rule-based models". Биоинформатика. 25 (7): 910–7. Дои:10.1093/bioinformatics/btp066. ЧВК 2660871. PMID 19213740.
- ^ а б c Colvin, J; Monine, M. I.; Gutenkunst, R. N .; Hlavacek, W. S.; von Hoff, D. D.; Posner, R. G. (2010). "Rule Обезьяна: Software for stochastic simulation of rule-based models". BMC Bioinformatics. 11: 404. Дои:10.1186/1471-2105-11-404. ЧВК 2921409. PMID 20673321.
- ^ а б c d е Sneddon, M. W.; Faeder, J. R.; Emonet, T (2011). "Efficient modeling, simulation and coarse-graining of biological complexity with NFsim". Методы природы. 8 (2): 177–83. Дои:10.1038/nmeth.1546. PMID 21186362. S2CID 5412795.
- ^ Tolle, D. P.; Le Novère, N (2010). "Meredys, a multi-compartment reaction-diffusion simulator using multistate realistic molecular complexes". BMC Systems Biology. 4: 24. Дои:10.1186/1752-0509-4-24. ЧВК 2848630. PMID 20233406.
- ^ а б Gruenert, G; Ibrahim, B; Lenser, T; Lohel, M; Hinze, T; Dittrich, P (2010). "Rule-based spatial modeling with diffusing, geometrically constrained molecules". BMC Bioinformatics. 11: 307. Дои:10.1186/1471-2105-11-307. ЧВК 2911456. PMID 20529264.
- ^ а б Grunert G, Dittrich P (2011) Using the SRSim Software for Spatial and Rule-Based Modeling of Combinatorially Complex Biochemical Reaction Systems. Membrane Computing - Lecture Notes in Computer Science 6501:240-256
- ^ а б Stiles, J. R.; Van Helden, D; Bartol Jr, T. M.; Salpeter, E. E.; Salpeter, M. M. (1996). "Miniature endplate current rise times less than 100 microseconds from improved dual recordings can be modeled with passive acetylcholine diffusion from a synaptic vesicle". Труды Национальной академии наук Соединенных Штатов Америки. 93 (12): 5747–52. Bibcode:1996PNAS...93.5747S. Дои:10.1073/pnas.93.12.5747. ЧВК 39132. PMID 8650164.
- ^ а б Stiles JR, Bartol TM (2001). Computational Neuroscience: Realistic Modeling for Experimentalists. In: De Schutter, E (ed). Computational Neuroscience: Realistic Modeling for Experimentalists. CRC Press, Бока-Ратон.
- ^ а б Kerr, R. A.; Bartol, T. M.; Kaminsky, B; Dittrich, M; Chang, J. C.; Baden, S. B.; Sejnowski, T. J.; Stiles, J. R. (2008). "Fast Monte Carlo Simulation Methods for Biological Reaction-Diffusion Systems in Solution and on Surfaces". Журнал SIAM по научным вычислениям. 30 (6): 3126–3149. Дои:10.1137/070692017. ЧВК 2819163. PMID 20151023.
- ^ а б Bray, D (1995). "Protein molecules as computational elements in living cells". Природа. 376 (6538): 307–12. Bibcode:1995Natur.376..307B. Дои:10.1038/376307a0. PMID 7630396. S2CID 4326068.
- ^ а б Endy, D.; Brent, R. (2001). "Modelling cellular behaviour". Природа. 409 (6818): 391–395. Bibcode:2001Natur.409..391E. Дои:10.1038/35053181. PMID 11201753. S2CID 480515.
- ^ а б Bray, D (2003). "Genomics. Molecular prodigality". Наука. 299 (5610): 1189–90. Дои:10.1126/science.1080010. PMID 12595679. S2CID 34035288.
- ^ а б Hlavacek, W. S.; Faeder, J. R.; Blinov, M. L.; Perelson, A. S.; Goldstein, B (2003). "The complexity of complexes in signal transduction". Биотехнологии и биоинженерия. 84 (7): 783–94. Дои:10.1002/bit.10842. PMID 14708119. S2CID 9092264.
- ^ Bennett, M. K.; Erondu, N. E.; Kennedy, M. B. (1983). "Purification and characterization of a calmodulin-dependent protein kinase that is highly concentrated in brain". Журнал биологической химии. 258 (20): 12735–44. PMID 6313675.
- ^ Rosenberg, O. S.; Deindl, S; Sung, R. J.; Nairn, A. C.; Kuriyan, J (2005). "Structure of the autoinhibited kinase domain of CaMKII and SAXS analysis of the holoenzyme". Клетка. 123 (5): 849–60. Дои:10.1016/j.cell.2005.10.029. PMID 16325579. S2CID 2654357.
- ^ а б c Stefan, M. I.; Marshall, D. P.; Le Novère, N (2012). "Structural analysis and stochastic modelling suggest a mechanism for calmodulin trapping by CaMKII". PLOS ONE. 7 (1): e29406. Bibcode:2012PLoSO...729406S. Дои:10.1371/journal.pone.0029406. ЧВК 3261145. PMID 22279535.
- ^ а б c Danos V, Feret J, Fontana W, Harmer R, Krivine J (2007). Rule-Based Modelling of Cellular Signalling. Proceedings of the Eighteenth International Conference on Concurrency Theory, CONCUR 2007, Lisbon, Portugal
- ^ а б Creamer, M. S.; Stites, E. C.; Aziz, M; Cahill, J. A .; Tan, C. W.; Berens, M. E.; Han, H; Bussey, K. J.; von Hoff, D. D.; Hlavacek, W. S.; Posner, R. G. (2012). "Specification, annotation, visualization and simulation of a large rule-based model for ERBB receptor signaling". BMC Systems Biology. 6: 107. Дои:10.1186/1752-0509-6-107. ЧВК 3485121. PMID 22913808.
- ^ а б Marchisio, M. A.; Colaiacovo, M; Whitehead, E; Stelling, J (2013). "Modular, rule-based modeling for the design of eukaryotic synthetic gene circuits". BMC Systems Biology. 7: 42. Дои:10.1186/1752-0509-7-42. ЧВК 3680069. PMID 23705868.
- ^ Chylek LA, Stites EC, Posner RG, Hlavacek WS (2013) Innovations of the rule-based modeling approach. In Systems Biology: Integrative Biology and Simulation Tools, Volume 1 (Prokop A, Csukás B, Editors), Springer.
- ^ Feret, J; Danos, V; Krivine, J; Harmer, R; Fontana, W (2009). "Internal coarse-graining of molecular systems". Труды Национальной академии наук. 106 (16): 6453–8. Bibcode:2009PNAS..106.6453F. Дои:10.1073/pnas.0809908106. ЧВК 2672529. PMID 19346467.
- ^ Доступны на https://github.com/jkrivine/KaSim
- ^ а б c Hucka, M.; Finney, A.; Sauro, H. M.; Bolouri, H.; Doyle, J. C.; Kitano, H.; Аркин, А.П .; Bornstein, A. P.; Bray, B. J.; Cornish-Bowden, D.; Cuellar, A.; Dronov, A. A.; Gilles, S.; Ginkel, E. D.; Gor, M.; Goryanin, V.; Hedley, I. I.; Hodgman, W. J.; Hofmeyr, T. C.; Hunter, J. -H.; Juty, P. J.; Kasberger, N. S.; Kremling, J. L.; Kummer, A.; Le Novère, U.; Loew, N.; Lucio, L. M.; Mendes, P.; Minch, P.; Mjolsness, E. (2003). "The systems biology markup language (SBML): A medium for representation and exchange of biochemical network models". Биоинформатика. 19 (4): 524–531. Дои:10.1093/bioinformatics/btg015. PMID 12611808.
- ^ Finney, A.; Hucka, M. (2003). "Systems biology markup language: Level 2 and beyond" (PDF). Сделки биохимического общества. 31 (Pt 6): 1472–1473. CiteSeerX 10.1.1.466.8001. Дои:10.1042/bst0311472. PMID 14641091.[постоянная мертвая ссылка ]
- ^ Monod, J.; Wyman, J .; Changeux, Дж. П. (1965). «О природе аллостерических переходов: правдоподобная модель». Журнал молекулярной биологии. 12: 88–118. Дои:10.1016 / S0022-2836 (65) 80285-6. PMID 14343300.
- ^ Colquhoun, D; Dowsland, K. A.; Beato, M; Plested, A. J. (2004). "How to impose microscopic reversibility in complex reaction mechanisms". Биофизический журнал. 86 (6): 3510–8. Bibcode:2004BpJ....86.3510C. Дои:10.1529/biophysj.103.038679. ЧВК 1304255. PMID 15189850.
- ^ а б John, M., Lhoussaine, C., Niehren, J., & Versari, C. (2011). Biochemical reaction rules with constraints. In Programming Languages and Systems (pp. 338-357). Springer Berlin Heidelberg.
- ^ Priami, C (1995). "Stochastic π-calculus". Компьютерный журнал. 38 (7): 578–589. Дои:10.1093/comjnl/38.7.578.
- ^ а б c Gillespie, DT (1977). "Exact Stochastic Simulation of Coupled Chemical Reactions". J Phys Chem. 81 (25): 2340–2361. CiteSeerX 10.1.1.704.7634. Дои:10.1021/j100540a008.
- ^ а б c Maus, C; Rybacki, S; Uhrmacher, A. M. (2011). "Rule-based multi-level modeling of cell biological systems". BMC Systems Biology. 5: 166. Дои:10.1186/1752-0509-5-166. ЧВК 3306009. PMID 22005019.
- ^ а б J. Himmelspach and A. M. Uhrmacher, "Plug'n simulate," Proceedings of the 40th Annual Simulation Symposium. IEEE Computer Society, 2007, pp. 137-143.
- ^ Oury, N.; Plotkin, G. (2013). "Multi-level modelling via stochastic multi-level multiset rewriting" (PDF). Математические структуры в компьютерных науках. 23 (2): 471–503. Дои:10.1017/s0960129512000199.
- ^ а б Meier-Schellersheim, M; Сюй, Х; Angermann, B; Kunkel, E. J.; Jin, T; Germain, R. N. (2006). "Key role of local regulation in chemosensing revealed by a new molecular interaction-based modeling method". PLOS вычислительная биология. 2 (7): e82. Bibcode:2006PLSCB...2...82M. Дои:10.1371/journal.pcbi.0020082. ЧВК 1513273. PMID 16854213.
- ^ Angermann, B. R.; Klauschen, F; Garcia, A. D.; Prustel, T; Zhang, F; Germain, R. N.; Meier-Schellersheim, M (2012). "Computational modeling of cellular signaling processes embedded into dynamic spatial contexts". Методы природы. 9 (3): 283–9. Дои:10.1038/nmeth.1861. ЧВК 3448286. PMID 22286385.
- ^ а б Lis, M; Artyomov, M. N.; Devadas, S; Chakraborty, A. K. (2009). "Efficient stochastic simulation of reaction-diffusion processes via direct compilation". Биоинформатика. 25 (17): 2289–91. Дои:10.1093/bioinformatics/btp387. ЧВК 2734316. PMID 19578038.
- ^ Lopez, C. F.; Muhlich, J. L.; Bachman, J. A.; Sorger, P. K. (2013). "Programming biological models in Python using PySB". Молекулярная системная биология. 9: 646. Дои:10.1038/msb.2013.1. ЧВК 3588907. PMID 23423320.
- ^ Zhang F, Meier-Schellersheim M (2013) SBML Level 3 Package Specification: Multistate, Multicomponent and Multicompartment Species Package for SBML Level 3 (Multi). Version 1, Release 01 (Draft, Rev 369). Доступны на http://sbml.org/Documents/Specifications/SBML_Level_3/Packages/multi
- ^ Tolle, DP; Nov, Le (2006). "Particle-Based Stochastic Simulation in Systems Biology". Curr. Bioinform. 1 (3): 315–320. Дои:10.2174/157489306777827964. S2CID 41366617.
- ^ Michalski, P. J.; Loew, L. M. (2012). "CaMKII activation and dynamics are independent of the holoenzyme structure: An infinite subunit holoenzyme approximation". Физическая биология. 9 (3): 036010. Bibcode:2012PhBio...9c6010M. Дои:10.1088/1478-3975/9/3/036010. ЧВК 3507550. PMID 22683827.
- ^ а б Mogilner, A; Allard, J; Wollman, R (2012). "Cell polarity: Quantitative modeling as a tool in cell biology". Наука. 336 (6078): 175–9. Bibcode:2012Sci...336..175M. Дои:10.1126/science.1216380. PMID 22499937. S2CID 10491696.
- ^ Доступны на http://sourceforge.net/projects/stochsim/
- ^ Levin, M. D.; Shimizu, T. S.; Bray, D (2002). "Binding and diffusion of CheR molecules within a cluster of membrane receptors". Биофизический журнал. 82 (4): 1809–17. Bibcode:2002BpJ....82.1809L. Дои:10.1016/S0006-3495(02)75531-8. ЧВК 1301978. PMID 11916840.
- ^ Ян, Дж; Hlavacek, W. S. (2011). "The efficiency of reactant site sampling in network-free simulation of rule-based models for biochemical systems". Физическая биология. 8 (5): 055009. Bibcode:2011PhBio...8e5009Y. Дои:10.1088/1478-3975/8/5/055009. ЧВК 3168694. PMID 21832806.
- ^ а б Kinney, J. P.; Спейсек, Дж; Bartol, T. M.; Bajaj, C. L.; Harris, K. M.; Sejnowski, T. J. (2013). "Extracellular sheets and tunnels modulate glutamate diffusion in hippocampal neuropil". Журнал сравнительной неврологии. 521 (2): 448–64. Дои:10.1002/cne.23181. ЧВК 3540825. PMID 22740128.
- ^ Plimpton S (1995) Fast Parallel Algorithms for Short-Range Molecular Dynamics. J Comput Phys 117:1-19
- ^ Доступны на http://lammps.sandia.gov
- ^ Tschernyschkow, S; Herda, S; Gruenert, G; Döring, V; Görlich, D; Hofmeister, A; Hoischen, C; Dittrich, P; Diekmann, S; Ibrahim, B (2013). "Rule-based modeling and simulations of the inner kinetochore structure". Прогресс в биофизике и молекулярной биологии. 113 (1): 33–45. Дои:10.1016/j.pbiomolbio.2013.03.010. PMID 23562479.
- ^ Доступны на http://www.mcell.org
- ^ Доступны на http://www.blender.org
- ^ Shimizu, T. S.; Aksenov, S. V.; Bray, D (2003). "A spatially extended stochastic model of the bacterial chemotaxis signalling pathway". Журнал молекулярной биологии. 329 (2): 291–309. Дои:10.1016/s0022-2836(03)00437-6. PMID 12758077.
- ^ Mirschel, S; Steinmetz, K; Rempel, M; Ginkel, M; Gilles, E. D. (2009). "PROMOT: Modular modeling for systems biology". Биоинформатика. 25 (5): 687–9. Дои:10.1093/bioinformatics/btp029. ЧВК 2647835. PMID 19147665.
- ^ Hoops, S.; Sahle, S.; Gauges, R.; Lee, C .; Pahle, J.; Simus, N.; Singhal, M.; Xu, L .; Mendes, P.; Kummer, U. (2006). "COPASI--a COmplex PAthway SImulator". Биоинформатика. 22 (24): 3067–3074. Дои:10.1093/bioinformatics/btl485. PMID 17032683.
- ^ Aitken, S; Alexander, R. D.; Beggs, J. D. (2013). "A rule-based kinetic model of RNA polymerase II C-terminal domain phosphorylation". Журнал интерфейса Королевского общества. 10 (86): 20130438. Дои:10.1098/rsif.2013.0438. ЧВК 3730697. PMID 23804443.
- ^ Artyomov, M. N.; Lis, M; Devadas, S; Дэвис, М. М .; Chakraborty, A. K. (2010). "CD4 and CD8 binding to MHC molecules primarily acts to enhance Lck delivery". Труды Национальной академии наук. 107 (39): 16916–21. Bibcode:2010PNAS..10716916A. Дои:10.1073/pnas.1010568107. ЧВК 2947881. PMID 20837541.
- ^ Ibrahim, B., Henze, R., Gruenert, G., Egbert, M., Huwald, J., & Dittrich, P. (2013) Spatial Rule-Based Modeling: A Method and Its Application to the Human Mitotic Kinetochore. Cells (2073-4409), 2(3).