Колмогоровская сложность - Kolmogorov complexity

В алгоритмическая теория информации (подполе Информатика и математика ), Колмогоровская сложность объекта, такого как кусок текста, - это длина самого короткого компьютерная программа (в заранее установленный язык программирования ), который производит объект в качестве вывода. Это мера вычислительный ресурсы, необходимые для указания объекта, также известный как алгоритмическая сложность, Сложность Соломонова – Колмогорова – Чайтина, программная сложность, описательная сложность, или же алгоритмическая энтропия. Он назван в честь Андрей Колмогоров, которые впервые опубликовали на эту тему в 1963 году.[1][2]
Понятие колмогоровской сложности можно использовать для формулировки и доказать невозможность результаты, похожие на Диагональный аргумент Кантора, Теорема Гёделя о неполноте, и Проблема остановки Тьюринга В частности, нет программы п вычисление нижняя граница для каждого текста колмогоровская сложность может возвращать значение существенно больше, чем псобственная длина (см. раздел § Теорема Чайтина о неполноте ); следовательно, ни одна программа не может вычислить точную сложность Колмогорова для бесконечного множества текстов.
Определение
Рассмотрим следующие два струны из 32 строчных букв и цифр:
ababababababababababababababababab, и4c1j5b2p0cv4w1x8rx2y39umgw5q85s7
Первая строка имеет краткое описание на английском языке, а именно "напишите ab 16 раз", который состоит из 17 символы. У второго нет очевидного простого описания (с использованием того же набора символов), кроме записи самой строки, т. Е. "напишите 4c1j5b2p0cv4w1x8rx2y39umgw5q85s7" у которого есть 38 символы. Следовательно, можно сказать, что операция записи первой строки «менее сложна», чем запись второй.
Более формально сложность строки - это длина кратчайшего возможного описания строки в некотором фиксированном универсальный язык описания (чувствительность сложности к выбору языка описания обсуждается ниже). Можно показать, что колмогоровская сложность любой строки не может быть больше, чем на несколько байтов, больше длины самой строки. Струны, подобные Abab приведенный выше пример, колмогоровская сложность которого мала по сравнению с размером строки, не считается сложным.
Сложность Колмогорова может быть определена для любого математического объекта, но для простоты объем данной статьи ограничен строками. Сначала мы должны указать язык описания для строк. Такой язык описания может быть основан на любом языке компьютерного программирования, например Лисп, Паскаль, или же Ява. Если п это программа, которая выводит строку Икс, тогда п это описание Икс. Длина описания равна длине п в виде строки символов, умноженной на количество бит в символе (например, 7 для ASCII ).
В качестве альтернативы мы могли бы выбрать кодировку для Машины Тьюринга, где кодирование - функция, которая ассоциируется с каждой машиной Тьюринга. M битовая строка <M>. Если M это машина Тьюринга, которая при вводе ш, выводит строку Икс, то объединенная строка <M> ш это описание Икс. Для теоретического анализа этот подход больше подходит для построения подробных формальных доказательств и обычно предпочитается в исследовательской литературе. В этой статье обсуждается неформальный подход.
Любая строка s имеет хотя бы одно описание. Например, вторая строка выше выводится программой:
функция GenerateString2 () возвращаться "4c1j5b2p0cv4w1x8rx2y39umgw5q85s7"
тогда как первая строка выводится (гораздо более коротким) псевдокодом:
функция GenerateString1 () возвращаться «ab» × 16
Если описание d(s) строки s имеет минимальную длину (т.е. использует наименьшее количество битов), он называется минимальное описание из s, а длина d(s) (то есть количество битов в минимальном описании) - это Колмогоровская сложность из s, написано K(s). Символично,
- K(s) = |d(s)|.
Длина самого короткого описания будет зависеть от выбора языка описания; но эффект изменения языков ограничен (результат, называемый теорема инвариантности).
Теорема инвариантности
Неформальное обращение
Есть несколько языков описания, которые оптимальны в следующем смысле: при любом описании объекта на языке описания это описание может использоваться на оптимальном языке описания с постоянными накладными расходами. Константа зависит только от задействованных языков, а не от описания объекта или самого объекта.
Вот пример оптимального языка описания. Описание будет состоять из двух частей:
- Первая часть описывает другой язык описания.
- Вторая часть - это описание объекта на этом языке.
Говоря более техническим языком, первая часть описания - это компьютерная программа, а вторая часть является входом для той компьютерной программы, которая производит объект в качестве выходных данных.
Теорема инвариантности следующая: Учитывая любой язык описания L, оптимальный язык описания по крайней мере так же эффективен, как L, с некоторыми постоянными накладными расходами.
Доказательство: Любое описание D в L можно преобразовать в описание на оптимальном языке, предварительно описав L как компьютерная программа п (часть 1), а затем используя исходное описание D в качестве входных данных для этой программы (часть 2). Общая длина этого нового описания D ′ составляет (приблизительно):
- |D ′| = |п| + |D|
Длина п константа, не зависящая от D. Таким образом, независимо от описываемого объекта существуют постоянные накладные расходы. Следовательно, оптимальный язык универсален. вплоть до эта аддитивная постоянная.
Более формальное обращение
Теорема: Если K1 и K2 являются функциями сложности относительно Тьюринг завершен языки описания L1 и L2, то существует постоянная c - что зависит только от языков L1 и L2 выбранный - такой, что
- ∀s. −c ≤ K1(s) − K2(s) ≤ c.
Доказательство: В силу симметрии достаточно доказать, что существует некоторая постоянная c так что для всех струн s
- K1(s) ≤ K2(s) + c.
Теперь предположим, что есть программа на языке L1 который действует как устный переводчик за L2:
функция InterpretLanguage (нить п)
куда п это программа в L2. Интерпретатор характеризуется следующим свойством:
- Бег
Интерпретировать языкна входе п возвращает результат выполнения п.
Таким образом, если п это программа в L2 что является минимальным описанием s, тогда Интерпретировать язык(п) возвращает строку s. Длина этого описания s это сумма
- Продолжительность программы
Интерпретировать язык, которую можно принять за постоянную c. - Длина п который по определению K2(s).
Это доказывает желаемую верхнюю оценку.
История и контекст
Алгоритмическая теория информации область информатики, изучающая сложность Колмогорова и другие меры сложности на строках (или других структуры данных ).
Концепция и теория сложности Колмогорова основана на важной теореме, впервые открытой Рэй Соломонов, который опубликовал его в 1960 году, описав его в «Предварительном отчете по общей теории индуктивного вывода».[3] как часть его изобретения алгоритмическая вероятность. Он дал более полное описание в своих публикациях 1964 года «Формальная теория индуктивного вывода», часть 1 и часть 2 в Информация и контроль.[4][5]
Андрей Колмогоров позже независимо опубликованные эта теорема в Проблемы Информ. Передача инфекции[6] в 1965 г. Григорий Чайтин также представляет эту теорему в J. ACM - Статья Чайтина была представлена в октябре 1966 г. и отредактирована в декабре 1968 г. и цитирует статьи Соломонова и Колмогорова.[7]
Теорема гласит, что среди алгоритмов, декодирующих строки по их описаниям (кодам), существует оптимальный. Этот алгоритм для всех строк позволяет кодировать настолько короткие, насколько позволяет любой другой алгоритм, вплоть до аддитивной константы, которая зависит от алгоритмов, но не от самих строк. Соломонов использовал этот алгоритм и длины кода, которые он позволяет определить «универсальную вероятность» строки, на которой может быть основан индуктивный вывод последующих цифр строки. Колмогоров использовал эту теорему для определения нескольких функций строк, включая сложность, случайность и информацию.
Когда Колмогоров узнал о работе Соломонова, он признал приоритет Соломонова.[8] В течение нескольких лет работы Соломонова были лучше известны в Советском Союзе, чем в западном мире. Однако общее мнение в научном сообществе заключалось в том, чтобы связать этот тип сложности с Колмогоровым, который был озабочен случайностью последовательности, в то время как алгоритм алгоритмической вероятности стал ассоциироваться с Соломоновым, который сосредоточился на прогнозировании с использованием своего изобретения универсального априорного распределения вероятностей. . Более широкая область, охватывающая сложность описания и вероятность, часто называется сложностью Колмогорова. Ученый-компьютерщик Мин Ли считает это примером Эффект Мэтью: «… Всем, у кого будет больше, дадут…»[9]
Есть несколько других вариантов колмогоровской сложности или алгоритмической информации. Самый распространенный из них основан на программы с самоограничением, и в основном это связано с Леонид Левин (1974).
Аксиоматический подход к колмогоровской сложности, основанный на Аксиомы Блюма (Blum 1967) был представлен Марком Бургином в статье, представленной к публикации Андреем Колмогоровым.[10]
Основные результаты
В следующем обсуждении пусть K(s) - сложность строки s.
Нетрудно понять, что минимальное описание строки не может быть намного больше, чем сама строка - программа GenerateString2 над выходами s фиксированная сумма больше, чем s.
Теорема: Есть постоянная c такой, что
- ∀s. K(s) ≤ |s| + c.
Невычислимость колмогоровской сложности
Наивная попытка программы для вычисления K
На первый взгляд может показаться тривиальным написать программу, которая может вычислять K(s) для любого s, например:
функция Колмогоровская сложность (нить s) за я = 1 к бесконечность: для каждого строка p из длина ровно я если isValidProgram (p) и оценить (p) == s возвращаться я
Эта программа перебирает все возможные программы (перебирая все возможные строки и рассматривая только те, которые являются допустимыми программами), начиная с самой короткой. Каждая программа выполняется, чтобы найти результат, произведенный этой программой, сравнивая его с вводом. s. Если результат совпадает, возвращается длина программы.
Однако это не сработает, потому что некоторые программы п испытанный не будет прекращен, например если они содержат бесконечные циклы. Невозможно избежать всех этих программ, протестировав их каким-либо образом перед их выполнением из-за невычислимости проблема остановки.
Более того, никакая программа не может вычислить функцию K, будь он настолько сложным. Это подтверждается следующим.
Формальное доказательство невычислимости K
Теорема: Существуют строки сколь угодно большой колмогоровской сложности. Формально: для каждого п ∈ ℕ существует строка s с K(s) ≥ п.[примечание 1]
Доказательство: В противном случае все бесконечное число возможных конечных строк могло бы быть порождено конечным числом[заметка 2] программы со сложностью ниже п биты.
Теорема: K это не вычислимая функция. Другими словами, нет программы, которая принимает любую строку s в качестве ввода и производит целое число K(s) в качестве вывода.
Следующее косвенный доказательство использует простой Паскаль -подобный язык для обозначения программ; для простоты доказательства предположим его описание (т. е. устный переводчик ) иметь длину 1400000 биты. Допустим, что существует программа
функция Колмогоровская сложность (нить s)
который принимает на входе строку s и возвращается K(s). Все программы имеют конечную длину, поэтому для простоты доказательства предположим, что это 7000000000 бит. Теперь рассмотрим следующую программу длины 1288 биты:
функция GenerateComplexString () за я = 1 к бесконечность: для каждого строка s из длина ровно я если Колмогоров Сложность (ы) ≥ 8000000000 возвращаться s
С помощью КолмогоровСложность как подпрограмма, программа пробует каждую строку, начиная с самой короткой, пока не вернет строку с колмогоровской сложностью не менее 8000000000 биты[заметка 3] то есть строка, которая не может быть создана какой-либо программой короче, чем 8000000000 биты. Однако общая продолжительность вышеуказанной программы, которая произвела s только 7001401288 биты[примечание 4] что является противоречием. (Если код КолмогоровСложность короче, противоречие остается. Если он длиннее, константа, используемая в GenerateComplexString всегда можно изменить соответствующим образом.)[примечание 5]
В приведенном выше доказательстве используется противоречие, аналогичное противоречию Ягодный парадокс: "1В 2самый маленький 3положительный 4целое число 5который 6не можешь 7быть 8определенный 9в 10меньше 11чем 1220 13английский 14слова ". Также можно показать невычислимость K редукцией из невычислимости проблемы остановки ЧАС, поскольку K и ЧАС находятся Эквивалент Тьюринга.[11]
Есть следствие, шутливо названное "теорема о полной занятости "в сообществе языков программирования, заявляя, что не существует идеального оптимизирующего размер компилятора.
Цепное правило для сложности Колмогорова
Цепное правило[12] для колмогоровской сложности утверждает, что
- K(Икс,Y) ≤ K(Икс) + K(Y|Икс) + О(бревно(K(Икс,Y))).
В нем говорится, что самая короткая программа, воспроизводящая Икс и Y является больше не надо чем логарифмический член больше, чем программа для воспроизведения Икс и программа для воспроизведения Y данный Икс. Используя это утверждение, можно определить аналог взаимной информации для колмогоровской сложности.
Сжатие
Вычислить верхние оценки для K(s) - просто компресс Струна s каким-либо методом реализовать соответствующий декомпрессор на выбранном языке, объединить декомпрессор со сжатой строкой и измерить длину результирующей строки - конкретно, размер самораспаковывающийся архив на данном языке.
Строка s сжимаемо числом c если у него есть описание, длина которого не превышает |s| − c биты. Это эквивалентно тому, что K(s) ≤ |s| − c. Иначе, s несжимаемо c. Строка, несжимаемая на 1, называется просто несжимаемый - посредством принцип голубятни, который применяется, потому что каждая сжатая строка отображается только на одну несжатую строку, несжимаемые струны должно существовать, так как есть 2п битовые строки длины п, а всего 2п - 1 струна короче, то есть струны длиной менее п, (т.е. длиной 0, 1, ..., п - 1).[примечание 6]
По той же причине большинство струн сложны в том смысле, что их нельзя значительно сжать - их K(s) не намного меньше |s|, длина s в битах. Чтобы сделать это точным, зафиксируйте значение п. Есть 2п битовые строки длины п. В униформа вероятность распределению в пространстве этих битовых цепочек присваивается точно равный вес 2−п к каждой строке длины п.
Теорема: С равномерным распределением вероятностей в пространстве цепочек битов длины п, вероятность несжимаемости струны на c не менее 1-2−c+1 + 2−п.
Для доказательства теоремы заметим, что количество описаний длины не более п − c дается геометрическим рядом:
- 1 + 2 + 22 + … + 2п − c = 2п−c+1 − 1.
Осталось не менее
- 2п − 2п−c+1 + 1
битовые строки длины п которые несжимаемы c. Чтобы определить вероятность, разделите на 2п.
Теорема Чайтина о неполноте
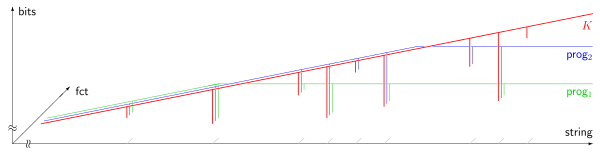
prog1 (s), prog2 (s). Горизонтальная ось (логарифмическая шкала ) перечисляет все струны s, упорядоченные по длине; вертикальная ось (линейная шкала ) измеряет колмогоровскую сложность в биты. Большинство струн несжимаемы, т.е. их колмогоровская сложность превышает их длину на постоянную величину. На рисунке показаны 9 сжимаемых струн, которые выглядят почти вертикальными склонами. Согласно теореме Чайтина о неполноте (1974 г.), результат любой программы, вычисляющей нижнюю границу колмогоровской сложности, не может превышать некоторый фиксированный предел, который не зависит от входной строки. s.По теореме выше (§ Сжатие ), большинство строк сложны в том смысле, что их нельзя описать каким-либо значительно «сжатым» способом. Однако оказывается, что тот факт, что конкретная строка является сложной, невозможно формально доказать, если сложность строки превышает определенный порог. Точная формализация следующая. Сначала исправьте конкретный аксиоматическая система S для натуральные числа. Аксиоматическая система должна быть достаточно мощной, чтобы в соответствии с некоторыми утверждениями А о сложности строк можно связать формулу FА в S. Эта ассоциация должна иметь следующее свойство:
Если FА можно доказать из аксиом S, то соответствующее утверждение А должно быть правдой. Эта «формализация» может быть достигнута на основе Гёделевская нумерация.
Теорема: Существует постоянная L (что зависит только от S и о выборе языка описания), что не существует строки s для чего заявление
- K(s) ≥ L (как оформлено в S)
может быть доказано в S.[13]:Thm.4.1b
Доказательство: Доказательство этого результата моделируется на самореферентной конструкции, используемой в Парадокс Берри.
Мы можем найти эффективное перечисление всех формальных доказательств в S какой-то процедурой
функция NthProof (int п)
который принимает в качестве входных данных п и выводит доказательства. Эта функция перечисляет все доказательства. Некоторые из них являются доказательствами формул, которые нас здесь не интересуют, поскольку все возможные доказательства на языке S производится для некоторых п. Некоторые из них представляют собой формулы сложности вида K(s) ≥ п куда s и п являются константами на языке S. Есть процедура
функция NthProofProvesComplexityFormula (int п)
который определяет, будет ли п-ое доказательство фактически доказывает формулу сложности K(s) ≥ L. Струны s, а целое число L в свою очередь, вычислимы с помощью процедуры:
функция StringNthProof (int п)
функция ComplexityLowerBoundNthProof (int п)
Рассмотрим следующую процедуру:
функция GenerateProvablyComplexString (int п) за i = от 1 до бесконечности: если NthProofProvesComplexityFormula (i) и ComplexityLowerBoundNthProof (i) ≥ п возвращаться StringNthProof (я)
Учитывая п, эта процедура пробует каждое доказательство, пока не найдет строку и доказательство в формальная система S формулы K(s) ≥ L для некоторых L ≥ п; если такого доказательства не существует, цикл будет бесконечным.
Наконец, рассмотрим программу, состоящую из всех этих определений процедур и главного вызова:
GenerateProvablyComplexString (п0)
где постоянная п0 будет определено позже. Общая продолжительность программы может быть выражена как U+ журнал2(п0), куда U это некоторая константа и журнал2(п0) представляет длину целочисленного значения п0, при разумном предположении, что оно закодировано в двоичных цифрах. Теперь рассмотрим функцию ж:[2,∞) → [1, ∞), определяемый формулой ж(Икс) = Икс - журнал2(Икс). это строго возрастающий на своей области определения и, следовательно, имеет обратный ж−1:[1,∞)→[2,∞).
Определять п0 = ж−1(U)+1.
Тогда никаких доказательств формы "K(s)≥L" с L≥п0 можно получить в S, как видно из косвенный аргумент:Если ComplexityLowerBoundNthProof (i) может вернуть значение ≥п0, затем цикл внутри GenerateProvablyComplexString в конечном итоге завершится, и эта процедура вернет строку s такой, что
| K(s) | |||
| ≥ | п0 | путем строительства GenerateProvablyComplexString | |
| > | U+ журнал2(п0) | поскольку п0 > ж−1(U) подразумевает п0 - журнал2(п0) = ж(п0) > U | |
| ≥ | K(s) | поскольку s описывалась программой такой длины |
Это противоречие, Q.E.D.
Как следствие, указанная выше программа с выбранным значением п0, должен повторяться навсегда.
Подобные идеи используются для доказательства свойств Постоянная Чайтина.
Минимальная длина сообщения
Принцип минимальной длины сообщения статистического и индуктивного вывода и машинного обучения был разработан К.С. Уоллес и Д. Бултоном в 1968 году. MML - это Байесовский (т.е. он включает в себя предыдущие убеждения) и теоретико-информационный. Он имеет желаемые свойства статистической инвариантности (то есть логический вывод преобразуется с повторной параметризацией, например, из полярных координат в декартовы координаты), статистической согласованности (т.е. даже для очень сложных задач MML сходится к любой базовой модели) и эффективности ( т.е. модель MML сходится к любой истинной базовой модели примерно так быстро, как это возможно). К.С. Уоллес, Д.Л. Доу (1999) показал формальную связь между MML и алгоритмической теорией информации (или колмогоровской сложностью).[14]
Колмогоровская случайность
Колмогоровская случайность определяет строку (обычно из биты ) как случайный если и только если он короче любого компьютерная программа который может произвести эту строку. Чтобы сделать это точным, универсальный компьютер (или универсальная машина Тьюринга) должна быть указана, так что «программа» означает программу для этой универсальной машины. Случайная строка в этом смысле «несжимаема» в том смысле, что невозможно «сжать» строку в программу, длина которой меньше длины самой строки. А подсчет аргумента используется, чтобы показать, что для любого универсального компьютера существует как минимум одна алгоритмически случайная строка каждой длины. Однако то, является ли какая-либо конкретная строка случайной, зависит от конкретного выбранного универсального компьютера.
Это определение можно расширить, чтобы определить понятие случайности для бесконечный последовательности из конечного алфавита. Эти алгоритмически случайные последовательности можно определить тремя эквивалентными способами. Один способ использует эффективный аналог теория меры; другой использует эффективный мартингалы. Третий способ определяет бесконечную последовательность как случайную, если безпрефиксная колмогоровская сложность ее начальных сегментов растет достаточно быстро - должна быть константа c такая, что сложность начального отрезка длины п всегда по крайней мере п−c. Это определение, в отличие от определения случайности для конечной строки, не зависит от того, какая универсальная машина используется для определения сложности Колмогорова без префиксов.[15]
Отношение к энтропии
Для динамических систем скорость энтропии и алгоритмическая сложность траекторий связаны теоремой Брудно о том, что равенство касается почти всех .[16]


Это можно показать[17] что для вывода Марковские источники информации, Колмогоровская сложность связана с энтропия источника информации. Точнее, колмогоровская сложность вывода марковского источника информации, нормированная на длину вывода, почти наверняка сходится (поскольку длина вывода стремится к бесконечности) к энтропия источника.
Условные версии
Эта секция нуждается в расширении. Вы можете помочь добавляя к этому. (Июль 2014 г.) |
Условная колмогоровская сложность двух струн грубо говоря, определяется как колмогоровская сложность Икс данный у в качестве вспомогательного входа в процедуру.[18][19]

Также существует сложность с условием длины , что является сложностью Икс учитывая длину Икс как известно / ввод.[20][21]

Смотрите также
- Важные публикации по алгоритмической теории информации
- Ягодный парадокс
- Код гольф
- Сжатие данных
- Демосцена, дисциплина компьютерного искусства, определенные отрасли которой сосредоточены вокруг создания самых маленьких программ, которые достигают определенных эффектов
- Описательная теория сложности
- Введение в грамматику
- Индуктивный вывод
- Структурная функция Колмогорова
- Расстояние Левенштейна
- Теория индуктивного вывода Соломонова
Примечания
- ^ Однако s с K(s) = п не обязательно существовать для каждого п. Например, если п не делится на 7 бит, нет ASCII программа может иметь длину ровно п биты.
- ^ Есть 1 + 2 + 22 + 23 + ... + 2п = 2п+1 - 1 различных программных текстов длиной до п биты; ср. геометрическая серия. Если длина программы должна быть кратна 7 битам, существует еще меньше текстов программы.
- ^ По предыдущей теореме такая строка существует, поэтому
зацикл в конечном итоге завершится. - ^ включая интерпретатор языка и код подпрограммы для
КолмогоровСложность - ^ Если
КолмогоровСложностьимеет длину п бит, константа м используется вGenerateComplexStringнеобходимо адаптировать для удовлетворения п + 1400000 + 1218 + 7 · журнал10(м) < м, что всегда возможно, так как м растет быстрее бревна10(м). - ^ Поскольку есть NL = 2L строки длины L, количество строк длины L = 0, 1, …, п − 1 является N0 + N1 + … + Nп−1 = 20 + 21 + … + 2п−1, который является конечным геометрическая серия с суммой 20 + 21 + … + 2п−1 = 20 × (1 − 2п) / (1 − 2) = 2п − 1
Рекомендации
- ^ Колмогоров Андрей (1963). «О таблицах случайных чисел». Sankhyā Ser. А. 25: 369–375. МИСТЕР 0178484.
- ^ Колмогоров Андрей (1998). «О таблицах случайных чисел». Теоретическая информатика. 207 (2): 387–395. Дои:10.1016 / S0304-3975 (98) 00075-9. МИСТЕР 1643414.
- ^ Соломонов, Луч (4 февраля 1960 г.). Предварительный отчет по общей теории индуктивного вывода (PDF). Репортаж V-131 (Отчет). Редакция опубликовано в ноябре 1960 г.
- ^ Соломонов, Рэй (март 1964 г.). "Формальная теория индуктивного вывода, часть I" (PDF). Информация и контроль. 7 (1): 1–22. Дои:10.1016 / S0019-9958 (64) 90223-2.
- ^ Соломонов, Рэй (июнь 1964 г.). "Формальная теория индуктивного вывода, часть II" (PDF). Информация и контроль. 7 (2): 224–254. Дои:10.1016 / S0019-9958 (64) 90131-7.
- ^ Колмогоров, А. (1965). «Три подхода к количественному определению информации». Проблемы Информ. Передача инфекции. 1 (1): 1–7. Архивировано из оригинал 28 сентября 2011 г.
- ^ Чайтин, Грегори Дж. (1969). «О простоте и скорости программ для вычисления бесконечных множеств натуральных чисел». Журнал ACM. 16 (3): 407–422. CiteSeerX 10.1.1.15.3821. Дои:10.1145/321526.321530.
- ^ Колмогоров, А. (1968). «Логические основы теории информации и теории вероятностей». IEEE Transactions по теории информации. 14 (5): 662–664. Дои:10.1109 / TIT.1968.1054210.
- ^ Ли, Мин; Витани, Пол (2008). «Отборочные». Введение в колмогоровскую сложность и ее приложения. Тексты по информатике. стр.1 –99. Дои:10.1007/978-0-387-49820-1_1. ISBN 978-0-387-33998-6.
- ^ Бургин, М. (1982), "Обобщенная колмогоровская сложность и двойственность в теории вычислений", Извещения Российской академии наук, т.25, № 3, стр. 19–23.
- ^ Заявлено без доказательства в: «Курсовые заметки по сжатию данных - колмогоровская сложность» В архиве 2009-09-09 на Wayback Machine, 2005, П. Б. Милтерсен, стр.7
- ^ Звонкин, А .; Л. Левин (1970). «Сложность конечных объектов и развитие понятий информации и случайности средствами теории алгоритмов» (PDF). Российские математические обзоры. 25 (6). С. 83–124.
- ^ Грегори Дж. Чайтин (июль 1974 г.). «Теоретико-информационные ограничения формальных систем» (PDF). Журнал ACM. 21 (3): 403–434. Дои:10.1145/321832.321839.
- ^ Wallace, C. S .; Доу, Д. Л. (1999). «Минимальная длина сообщения и колмогоровская сложность». Компьютерный журнал. 42 (4): 270–283. CiteSeerX 10.1.1.17.321. Дои:10.1093 / comjnl / 42.4.270.
- ^ Мартин-Лёф, Пер (1966). «Определение случайных последовательностей». Информация и контроль. 9 (6): 602–619. Дои:10.1016 / с0019-9958 (66) 80018-9.
- ^ Галатоло, Стефано; Хойруп, Матьё; Рохас, Кристобаль (2010). «Эффективная символическая динамика, случайные точки, статистическое поведение, сложность и энтропия» (PDF). Информация и вычисления. 208: 23–41. Дои:10.1016 / j.ic.2009.05.001.
- ^ Алексей Кальченко (2004). «Алгоритмы оценки информационного расстояния применительно к биоинформатике и лингвистике». arXiv:cs.CC/0404039.
- ^ Йорма Риссанен (2007). Информация и сложность статистического моделирования. Спрингер С. п.53. ISBN 978-0-387-68812-1.
- ^ Мин Ли; Пол М. Витани (2009). Введение в колмогоровскую сложность и ее приложения. Springer. стр.105 –106. ISBN 978-0-387-49820-1.
- ^ Мин Ли; Пол М. Витани (2009). Введение в колмогоровскую сложность и ее приложения. Springer. п.119. ISBN 978-0-387-49820-1.
- ^ Витани, Пол М. (2013). «Условная колмогоровская сложность и универсальная вероятность». Теоретическая информатика. 501: 93–100. arXiv:1206.0983. Дои:10.1016 / j.tcs.2013.07.009.
дальнейшее чтение
- Блюм, М. (1967). «О размерах машин». Информация и контроль. 11 (3): 257. Дои:10.1016 / S0019-9958 (67) 90546-3.
- Брудно, А. (1983). «Энтропия и сложность траекторий динамической системы». Труды Московского математического общества. 2: 127–151.
- Обложка, Томас М .; Томас, Джой А. (2006). Элементы теории информации (2-е изд.). Wiley-Interscience. ISBN 0-471-24195-4.
- Лайош, Роньяи; Габор, Иваниос; Река, Сабо (1999). Алгоритмусок. TypoTeX. ISBN 963-279-014-6.
- Ли, Мин; Витани, Пол (1997). Введение в колмогоровскую сложность и ее приложения. Springer. ISBN 978-0387339986.CS1 maint: ref = harv (связь)
- Ю., Манин (1977). Курс математической логики. Springer-Verlag. ISBN 978-0-7204-2844-5.
- Сипсер, Майкл (1997). Введение в теорию вычислений. PWS. ISBN 0-534-95097-3.
внешняя ссылка
- Наследие Андрея Николаевича Колмогорова
- Интернет-публикации Чайтина
- Страница IDSIA Соломонова
- Обобщения алгоритмической информации к Я. Шмидхубер
- "Обзор Ли Витани 1997".
- Тромп, Джон. "Лямбда-исчисление Джона и площадка для комбинаторной логики". Компьютерная модель лямбда-исчисления Тромпа предлагает конкретное определение K ()]
- Универсальный ИИ на основе колмогоровской сложности ISBN 3-540-22139-5 к М. Хаттер: ISBN 3-540-22139-5
- Дэвид Доу с Минимальная длина сообщения (MML) и бритва Оккама страниц.
- Grunwald, P .; Питт, М.А. (2005). Мён, И. Дж. (Ред.). Достижения в области минимальной длины описания: теория и приложения. MIT Press. ISBN 0-262-07262-9.
Сжатие данных методы | |||||||
|---|---|---|---|---|---|---|---|
| Без потерь |
| ||||||
| Потерянный |
| ||||||
| Аудио |
| ||||||
| Изображение |
| ||||||
| видео |
| ||||||
| Теория | |||||||
| |||||||